该图显示了使用基于示例的方法为X语言创建短语手册的过程,在我们的案例中,无论是丹麦语、荷兰语、德语还是挪威语,我们都必须使用与语法学家不同的母语者进行的知情开发和测试。
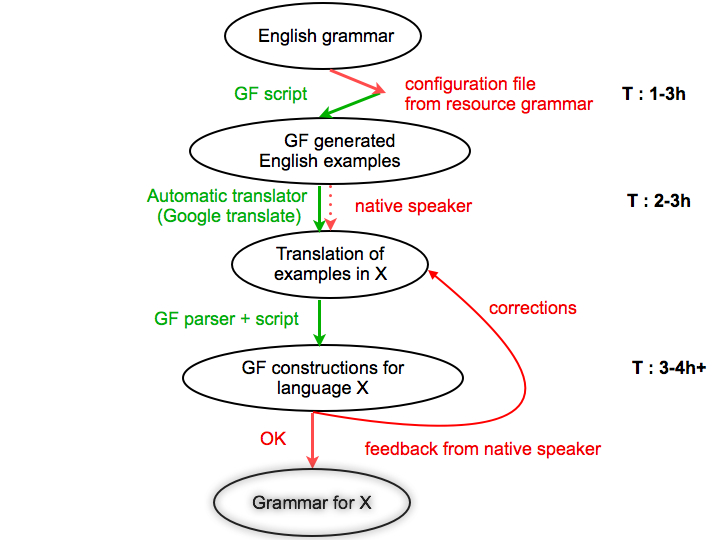
评论:箭头表示流程的主要步骤,而圆圈表示流程每个步骤后的初始和最终结果。红色箭头表示手动工作,绿色箭头表示自动操作。虚线箭头表示可选步骤。对于每一步,都会给出估计的时间。这是可变的,受目标语言的特点和短语的语义复杂性的影响很大,只适用于短语手册语法。
初始资源:
- 英语短语手册
- X的资源语法
- 用于生成单词屈折形式的脚本,以及X语言短语手册中词汇条目的相应线性化。例如,就国籍而言,因为我们对国家名称、语言以及人和地方的公民身份感兴趣,我们会生成“我是英国人。我来自英国。我说英语。我去一家英国餐馆”这样的结构,从翻译的结果中我们会推断出每个特征的正确形式。在英语中,在大多数情况下,语言名称与人和地方的公民身份之间存在歧义,但在其他语言中,这三种语言可能有完全不同的形式。这就是为什么在例子中明确上下文很重要,这样翻译才更有可能成功。正确的示例测试设计依赖于语言,并假设对资源语法进行分析。例如,在某些语言中,我们只需要名词的单数和复数形式来构建其GF表示,而在其他语言(如德语)中,在最坏的情况下,我们需要从示例中正确呈现6种形式。
- 用于生成涵盖语法中所有结构的随机测试用例的脚本。它基于抽象语法的当前状态,为每个抽象函数生成一些随机参数,并显示英语和X语言中结构的线性化,以及生成的抽象语法树。
- 第一步:目标语法分析
-
第一步假设对资源语法进行分析,并提取构建新词汇条目的函数所需的信息。建立了一个模型,以便能够呈现单词的正确形式,并可以推断出其他信息,例如性别。脚本将这些规则应用于我们要翻译成目标语言的每个条目,然后获得一组结构。
- 步骤2:用目标语言生成示例
-
生成的结构被提供给外部翻译工具(谷歌翻译)或母语人士进行翻译。即使翻译人员是人,也需要配置文件,因为不需要语法的正式知识。
- 步骤3:使用GF解析和解码示例
-
为了首先建立类别的线性化,对接收到的信息进行解码,对翻译成目标语言的译文进行了进一步处理。此外,有了词典中的单词,就可以用GF解析器解析函数的翻译并从中进行概括。
- 第4步:评估和纠正生成的语法
-
生成的语法在测试脚本的帮助下进行测试,该脚本生成涵盖语法中所有功能和类别的结构,以及一些其他在某些语言中被证明有问题的结构。母语为英语的人会评估结果,如果需要更正,算法会使用新的示例再次运行。根据语法编写者的语言技能,可以直接在GF文件中进行更改,并且本地信息提供者给出的正确示例仅用于验证结果。只要需要修正,就会重复该算法。
将来不需要为语法准备配置文件所需的时间,因为这些文件可用于其他应用程序。如果使用像谷歌翻译这样的自动工具,第二步可以节省时间。这只有在形态和语法更简单的语言中才可能实现,并且可以使用大型语料库。通过谷歌翻译,德语和荷兰语获得了不错的结果,但对于罗马尼亚语或波兰语这样既复杂又缺乏足够资源的语言,结果令人失望。
如果统计预言器运行良好,那么唯一需要人工翻译的步骤就是评估和反馈步骤。我们进行实验的语言平均每轮需要4小时,平均需要2轮。对于更复杂的语言,可能需要付出更多的努力。
将进一步开展工作,建立一个更全面的语法测试和评估工具,并将分析从英语到各种目标语言的机器翻译外部工具的影响,以便该过程能够在更高程度上实现自动化,以便今后的语法工作。

