摘要
1简介
缩略语替代了完全扩展的术语(例如。计算机断层扫描)通过使用缩短的术语表(例如。计算机断层扫描). 在生物医药文献中,缩写用于各种重要术语,包括:基因、蛋白质、疾病和化学名称(Federiuk,1999). 我们的实验结果(第3.2节)显示32.0%的UniProt条目在描述和基因名称字段中包含缩写。鹪鹩等。(2005)据报道,缩略语的使用频率高于扩展形式。
缩略语对生物医学文本挖掘提出了两大挑战:术语变异和歧义。我们考虑使用一个信息检索系统来收集有关聚合酶链反应.因为聚合酶链反应可以缩写为聚合酶链反应,系统应检索其中的文档聚合酶链反应出现。同时,缩写词也不明确:同一个缩写词可能指的是不同的概念(Ananiadou等。,2006; 埃哈特等。,2006). 因为聚合酶链反应指除聚合酶链反应,系统应该能够执行缩写消歧,以判断聚合酶链反应实际上是指聚合酶链反应或不是(麦克雷和谢霆锋,2003; Sehgal和Srinivasan,2006). 一般来说,缩写比普通术语更加模糊。线路接口单元等。(2002年b)报告显示,统一医学语言系统(UMLS)中81.2%的缩写具有歧义,平均16.6种意义。
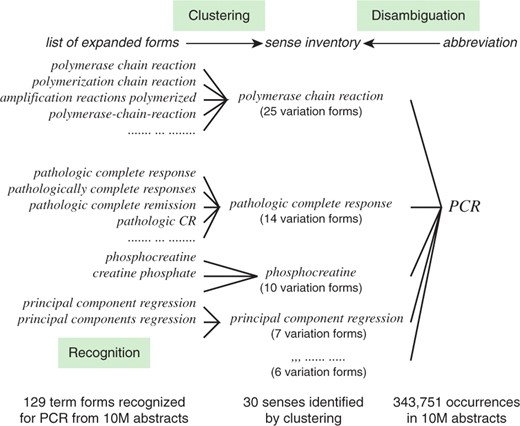
图1提出了缩略语的术语变异和歧义问题。总共为缩写提取了129种不同的扩展形式聚合酶链反应来自所有MEDLINE摘要,包括聚合酶链反应,聚合链式反应和聚合放大反应缩写识别是一项收集缩写扩展形式的任务。已经使用各种方法对其进行了广泛的探索:通过使用启发式和/或评分规则(Adar,2004; 帕克和伯德,2001; 普斯特约夫斯基等。,2001; 施瓦茨和赫斯特,2003)、机器学习(Chang和Schütze,2006; 纳多和特纳,2005; 冈崎等。,2008)和共现统计(Liu和Friedman,2003; 冈崎和阿纳尼亚杜,2006; 周等。,2006). 中的129个扩展形式图1使用缩写识别方法(Okazaki和Ananiadou,2006),这是基于共现统计。如所示图1,缩写识别提取的扩展形式是概念/意义及其术语变体的混合物。缩写聚合酶链反应有129种扩展形式,可以合并为30种感官(例如。聚合酶链反应,病理完全反应和磷酸肌酸). 一般来说,一个单一的感官有不止一种表面形式(即变体)。感觉病理完全反应例如,MEDLINE摘要中的14种变体形式(例如。病理完全反应和病理完全反应). 将扩展形式聚类为一组不同的意义,从而为给定缩写创建意义目录,是消除缩写歧义的关键步骤。缩略语消歧的研究不如缩略语识别深入,部分原因是聚类可以为许多对缩略语及其表面扩展形式创建意义清单。
如本文所述,我们首先将创建感官目录的任务形式化为一项独立的聚类任务,在该任务中,缩写的类似扩展形式被聚集到一个集群(sense)中。由于意义清单的质量对缩略语消歧的性能有显著影响,我们开发了一种新的有监督的扩展形式聚类方法。我们为该方法构建了一个数据集并测量了其性能。还定量评估了聚类对缩略语消歧的影响。本文的主要贡献有三个方面。
意义目录是对缩写进行稳健管理的关键,因为它为消除与生物医学实体和概念相对应的歧义提供了目标意义。因此,我们提出了一种有监督的方法来聚类扩展形式,并评估感官清单的质量。实验结果报告了聚类扩展形式的0.915F1得分。
我们调查了蛋白质和基因名称与缩写词冲突的可能性,以评估缩写词消歧的重要性。结果表明,32.0%的UniProt记录中包含缩写词,16.7%的记录中包含具有多重定义的模糊缩写词。
我们对感官量表进行了缩略语消歧实验,其质量由贡献(i)来证明。该系统在从所有MEDLINE获取的数据集上达到0.984的精度。
2方法
就缩写词消歧而言,必须明确区分地方的和全球的缩写(高丹语等。,2005). 按照惯例,在文档中首次出现时,会附带一个本地缩写。因为缩写定义在一个文档中基本上是一致的,即。单义全搜索假设(雅罗斯基,1995),我们可以通过重用缩写识别方法来识别本地缩写的定义(Yu等。,2006). 相反,全局缩写出现在文档中,没有明确说明扩展形式。有必要根据文档中的上下文估计未定义的全局缩写的定义。这项任务类似于自然语言处理中的词义消歧(WSD),即从几个预定义的意义中选择一个模糊术语的意义。本文的其余部分将具体描述MEDLINE数据库中全局缩写词的消歧。
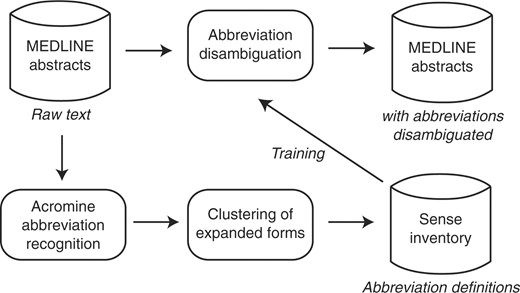
图2显示了缩写管理的工作流程。系统首先从MEDLINE摘要中提取缩写定义。因为扩展形式包括变化(例如。聚合酶链反应和聚合链式反应对于聚合酶链反应),我们应用聚类方法来编制感官清单。使用包括缩写定义的句子集合,我们为每个缩写训练一个分类器,该分类器预测缩写出现的意义。最后,该系统预测MEDLINE摘要中全局缩写的含义。
2.1从MEDLINE收集缩写定义
缩写词消歧的第一步是收集缩写词的可能扩展形式。我们使用最先进的方法识别MEDLINE摘要中的缩写定义(Okazaki和Ananiadou,2006). 该算法假设括号表达式以以下格式引入缩写定义:对于插入表达式的每个内部表达式,该算法枚举以任何非功能词(例如。,一,和,属于)并以插入语前的任何单词结尾。 为每个缩写选择正确的展开形式一,算法计算分数LH一(c(c))对于扩展形式的候选人c(c),在方程式中(2),使用以下变量:一是缩写;c(c)是缩写词的扩展形式的候选者一; 频率(一,c(c))表示候选人的共现频率c(c)用缩写一; 和T型c(c)是一组嵌套的候选词,每个候选词由前一个单词和后一个候选词组成c(c)。我们编制了一份扩展形式的候选人名单,按照每个缩写词的得分降序排序。该算法从排序列表中逐个提取候选对象。如果以下所有条件均成立,则认为扩展形式有效:分数>2.0;展开形式的单词可以重新排列,以便缩写中的所有字母数字字母以相同的顺序出现;它不是嵌套的,也不是先前选择的扩展形式的扩展。 2.2合并缩写定义中的术语变化
缩写定义列表阐明了术语变异和歧义现象。例如,缩写计算机断层扫描代表各种概念和实体,例如计算机断层扫描,降钙素和霍乱毒素,但它也有多种形式,包括:计算机断层扫描,计算机断层扫描,计算机断层扫描和计算机断层扫描。要从扩展形式列表中编译缩写的有意义清单,我们必须将引用同一概念的术语变体合并为一个具有代表性的形式。我们将这项任务形式化为一个聚类问题,在该问题中,类似的扩展形式构成一个聚类。
聚类成功的关键在于扩展形式之间距离(相似性)度量的准确性。各种相似性度量,包括余弦相似性、Levenshtein距离(Levenshtien,1966)Jaro–Winkler相似性(Winkler,1999)和SoftTFIDF(科恩等。,2003)已应用于术语聚类。然而,我们不确定这些度量用于识别术语变异的最佳选择、组合和阈值。因此,我们使用机器学习技术通过组合各种特征来获取相似性度量。更具体地说,我们构建了一个二进制分类器,当给定两个术语时秒和t吨,决定条款是否秒和t吨提出术语变化(第页=+1)或不(第页= −1).
虽然支持向量机(SVM)是一种常用的二值分类方法,但我们对条件概率进行了建模对(第页|秒,t吨)用logistic回归,希望概率对(第页|秒,t吨)反映了两者之间的距离秒和t吨.概率分布对(第页|秒,t吨)表示为在方程式中(三),如果= {(f)1,…,(f)K(K)}表示特征函数向量:K(K)是特征函数的数量;和w个= {w个1,…,w个K(K)}给出了特征函数的权重向量。我们使用最大后验估计来拟合特征权重w个培训集包括N个实例,𝒟 = ((秒(1),t吨(1),第页(1)),…, (秒(N个),t吨(N个),第页(N个))). 我们用L(左)2权向量范数w个,在这里,第一项表示训练集模型对数似然的否定,‖w个‖2表示L(左)2权向量范数w个σ是控制L(左)2正规化。方程式(4)使用有限记忆Broyden–Fletcher–Goldfarb–Shanno方法(Nocedal,1980). 表1给出了为向量设计的特征函数列表的摘要如果(秒,t吨)以及为字符串对计算的实际特征值X射线光电子能谱和X射线光电子能谱.功能函数#1–#5计算九种类型1两种展开形式的正交相似性x个和年。功能#1–#3衡量秒和t吨具有n个-gram cosine相似性、归一化Levenshtein距离和Jaro–Winkler相似性。功能#4–#5计算组成词的相似性2在里面秒和t吨具有n个-gram cosine相似性和SoftTFIDF。特征#6对应于偏差项,它调整分类的决策边界。中的“重量”列表1显示为训练数据调整的最佳特征权重(第3.1节).
| #. | 功能. | 类型. | 说明. | 例子. | 重量(w个). |
|---|
| 1 | 字符n个-克相似性 | 真实 | 字母余弦相似性n个-克术语秒和t吨(n个=1, 2, 3). | (0.954、0.953、0.951) | (1.037, 3.838, 9.043) |
| 2 | 归一化Levenshtein距离 | 真实 | 将一个术语转换为另一个术语所需的最少插入、删除和替换操作次数(Levenshtein,1966),除以较长的字符数。 | 0.061 | 2.742 |
| 三 | Jaro–Winkler相似性(Winkler,1999) | 真实 | 这个度量考虑了共享字母的数量和两个术语之间的换位;该指标还包含一个公式,以支持两个从一开始就匹配的术语。 | 0.979 | −0.536 |
| 4 | 单词n个-克相似性 | 真实 | 词的余弦相似性n个-克术语秒和t吨(n个=1, 2, 3). | (0.750, 0.667, 0.500) | (0.457, −2.439, 0.523) |
| 5 | SoftTFIDF(科恩等。,2003) | 真实 | 该度量使用阈值为0.9的Jaro–Winkler相似性在两个字符串之间对齐标记,并计算对齐对的相似性得分之和;相似性得分基于TFIDF得分。 | 1.883 | 0.946 |
| 6 | 偏差 | 真实 | 此功能始终产生1。 | 1 | −9.340 |
| #. | 功能. | 类型. | 说明. | 例子. | 重量(w个). |
|---|
| 1 | 字符n个-克相似性 | 真实 | 字母余弦相似度n个-克术语秒和t吨(n个=1, 2, 3). | (0.954, 0.953, 0.951) | (1.037, 3.838, 9.043) |
| 2 | 归一化Levenshtein距离 | 真实 | 将一个术语转换为另一个术语所需的最少插入、删除和替换操作次数(Levenshtein,1966),除以较长的字符数。 | 0.061 | 2.742 |
| 三 | Jaro–Winkler相似性(Winkler,1999) | 真实 | 该指标考虑了两个术语之间共享字母和换位的数量;该指标还包含一个公式,以支持两个从一开始就匹配的术语。 | 0.979 | −0.536 |
| 4 | 单词n个-克相似性 | 真实 | 词的余弦相似性n个-术语克数秒和t吨(n个=1, 2, 3). | (0.750, 0.667, 0.500) | (0.457, −2.439, 0.523) |
| 5 | SoftTFIDF(科恩等。,2003) | 真实 | 该度量使用阈值为0.9的Jaro–Winkler相似性在两个字符串之间对齐标记,并计算对齐对的相似性得分之和;相似性得分基于TFIDF得分。 | 1.883 | 0.946 |
| 6 | 偏差 | 真实 | 此功能始终产生1。 | 1 | −9.340 |
| #. | 功能. | 类型. | 说明. | 例子. | 重量(w个). |
|---|
| 1 | 字符n个-克相似性 | 真实 | 字母余弦相似性n个-克术语秒和t吨(n个=1, 2, 3). | (0.954, 0.953, 0.951) | (1.037, 3.838, 9.043) |
| 2 | 归一化Levenshtein距离 | 真实 | 将一个术语转换为另一个术语所需的最少插入、删除和替换操作次数(Levenshtein,1966),除以较长的字符数。 | 0.061 | 2.742 |
| 三 | Jaro–Winkler相似性(Winkler,1999) | 真实 | 这个度量考虑了共享字母的数量和两个术语之间的换位;该指标还包含一个公式,以支持两个从一开始就匹配的术语。 | 0.979 | −0.536 |
| 4 | 单词n个-克相似性 | 真实 | 词的余弦相似性n个-克术语秒和t吨(n个=1, 2, 3). | (0.750, 0.667, 0.500) | (0.457, −2.439, 0.523) |
| 5 | SoftTFIDF(科恩等。,2003) | 真实 | 该度量使用阈值为0.9的Jaro–Winkler相似性在两个字符串之间对齐标记,并计算对齐对的相似性得分之和;相似性得分基于TFIDF得分。 | 1.883 | 0.946 |
| 6 | 偏差 | 真实 | 此功能始终产生1。 | 1 | −9.340 |
| #. | 功能. | 类型. | 说明. | 例子. | 重量(w个). |
|---|
| 1 | 字符n个-克相似性 | 真实 | 字母余弦相似性n个-克术语秒和t吨(n个=1, 2, 3). | (0.954, 0.953, 0.951) | (1.037, 3.838, 9.043) |
| 2 | 归一化Levenshtein距离 | 真实 | 将一个术语转换为另一个术语所需的插入、删除和替换操作的最小数量(Levenstein,1966),除以较长的字符数。 | 0.061 | 2.742 |
| 三 | Jaro–Winkler相似性(Winkler,1999) | 真实 | 该指标考虑了两个术语之间共享字母和换位的数量;该指标还包含一个公式,以支持两个从一开始就匹配的术语。 | 0.979 | −0.536 |
| 4 | 单词n个-克相似性 | 真实 | 词的余弦相似性n个-克术语秒和t吨(n个=1, 2, 3). | (0.750, 0.667, 0.500) | (0.457, −2.439, 0.523) |
| 5 | SoftTFIDF(科恩等。,2003) | 真实 | 该度量使用阈值为0.9的Jaro–Winkler相似性在两个字符串之间对齐标记,并计算对齐对的相似性得分之和;相似性得分基于TFIDF得分。 | 1.883 | 0.946 |
| 6 | 偏差 | 真实 | 此功能始终产生1。 | 1 | −9.340 |
最后,我们应用层次聚类算法(Lance和Williams,1967)相似度度量。我们定义距离度量d日(秒,t吨)=1 −对(+1|秒,t吨)即使条件概率对(+1|秒,t吨)不具有距离度量的属性。在第3.1节比较了单链接、完全链接、质心和组平均聚类算法。
2.3缩略语消歧是WSD的一个问题
我们将缩写词消歧形式化如下:给定缩写词的出现x个以及一系列可能的感觉Y(Y)x个= {年1,年2,…,年n个}对应于x个,选择最合适的感觉年*∈Y(Y)x个表示缩写出现。这是一个分配标签的分类问题年*∈Y(Y)x个适合输入的x个在各种监督机器学习技术中,如朴素贝叶斯和支持向量机,本研究采用了最大熵建模(Berger等。,1996)以提高多类分类的效率。
表2显示了用于生成特征的特征模板(规则)的摘要。表中的规则生成与意义关联的布尔特征年在区域(窗口)中发生观察事件(单粒度或双粒度)。例如,给定句子,佩里普拉金,蛋白质plakin家族的一员,最近以互补脱氧核糖核酸(cDNA)克隆为特征,和相应的基因,…
以及缩写词的训练实例x个在句子中,那么局部特征的区域是从该区域中提取了六个单粒度和五个双粒度特征。局部和句子上下文的特征根据目标缩写词周围的单词出现情况以及考虑到抽象中全局主题的抽象上下文的特征估计扩展形式三。
| 功能类型. | 单位. | 有效区域(窗口). |
|---|
| 邻居上下文 | 联合国 | 缩写的前一个单词和后一个单词x个 |
| 本地上下文 | uni、bi | 缩写前后三个单词x个 |
| 句子上下文 | uni、bi | 同一句子中的单词x个 |
| 抽象上下文 | uni、bi | 同一摘要中的单词x个 |
| 功能类型. | 单位. | 有效区域(窗口). |
|---|
| 邻居上下文 | 联合国 | 缩写的前一个单词和后一个单词x个 |
| 本地上下文 | uni、bi | 缩写前后三个单词x个 |
| 句子上下文 | uni、bi | 同一句子中的单词x个 |
| 抽象上下文 | uni、bi | 同一摘要中的单词x个 |
| 功能类型. | 单位. | 有效区域(窗口). |
|---|
| 邻居上下文 | 联合国 | 缩写的前一个单词和后一个单词x个 |
| 本地上下文 | uni、bi | 缩写前后三个单词x个 |
| 句子上下文 | uni、bi | 同一句子中的单词x个 |
| 抽象上下文 | uni、bi | 同一摘要中的单词x个 |
| 功能类型. | 单位. | 有效区域(窗口). |
|---|
| 邻居上下文 | 联合国 | 缩写的前一个单词和后一个单词x个 |
| 本地上下文 | uni、bi | 缩写前后三个单词x个 |
| 句子上下文 | 单,双 | 同一句子中的单词x个 |
| 抽象上下文 | uni、bi | 同一摘要中的单词x个 |
3结果和讨论
我们将所提出的方法应用于MEDLINE摘要(截至2009年3月,共有9 635 599篇摘要)。缩写识别(第2.1节)识别了467402个68 007个缩写的不同定义。我们将单链接聚类应用于467 402个扩展形式,距离阈值为0.2,并获得了68 007个缩写的146 651个感官的感官清单4换言之,聚类方法确定了每个意义3.19个术语变化。缩写词平均有2.16个意思。
3.1扩展形式的聚类
训练中描述的相似性度量第2.2节,我们对从缩写定义中随机抽取的400个缩写的4158个扩展形式进行了分组。我们请一位人类专家合并扩展形式,如果它们涉及几乎相同的概念。通过这种方式,我们获得了一个由2563个簇(感官)组成的数据集,其中包含400个缩写的4158种扩展形式。图3描述了缩写词簇的摘录TTX公司和玻璃钢:缩写TTX公司已识别五种扩展形式;展开的形式被分组为三个集群。
假设每个缩写的扩展形式的内部簇对为正(第页=+1)并假设簇间对为负(第页=−1),我们为相似性度量获得了3678个阳性和19296个阴性训练数据实例5例如,两个正面的例子,〈破伤风毒素,破伤风类毒素〉和〈河豚毒素,河豚毒素〉,并为生成八个否定实例(其他扩展形式对)TTX公司在里面图3。
表3报告使用对训练数据的10倍交叉验证测量的相似性度量的准确性(A)、精确性(P)、召回率(R)和F1(F1)得分。“Full”行显示了当第2.2节使用;所有特征均获得最佳性能(0.892 F1得分)。特征集的前半部分仅使用特定特征来训练相似性度量。例如,“Sim(ch)”仅显示字符时的性能n个-使用gram相似性。最后一半的特征集(前缀为“-”)从完整的特征集中删除特定的特征,例如“-Sim(ch+wd)”显示字符和单词的特征时的性能n个-删除了gram相似性。我们可以推断,如果在缺少特征的情况下性能降低,则特征对相似性度量的贡献很大。表3显示了这个角色n个-gram相似性是预测术语变化最有效的特征之一。此外表3表明其他特征,如Levenshtein距离、Jaro–Winkler距离和SoftTFIDF对性能没有贡献,包括n个-gram相似性特征。
| 特征. | A类. | 对. | R(右). | 一层楼. | ΔF1. |
|---|
| 模拟(ch) | 0.963 | 0.879 | 0.895 | 0.887 | |
| 模拟(wd) | 0.937 | 0.844 | 0.747 | 0.793 | |
| 模拟(ch+wd) | 0.962 | 0.877 | 0.890 | 0.884 | |
| 莱文斯坦 | 0.939 | 0.849 | 0.754 | 0.799 | |
| 贾罗-温克勒 | 0.918 | 0.920 | 0.534 | 0.676 | |
| SoftTFIDF软件 | 0.921 | 0.817 | 0.656 | 0.728 | |
|
| 完全 | 0.965 | 0.883 | 0.900 | 0.892 | |
|
| -模拟(ch) | 0.947 | 0.855 | 0.808 | 0.831 | −0.061 |
| -模拟(wd) | 0.965 | 0.885 | 0.898 | 0.891 | −0.001 |
| -模拟(ch+wd) | 0.950 | 0.868 | 0.810 | 0.838 | −0.054 |
| -莱文施泰因 | 0.965 | 0.882 | 0.898 | 0.890 | −0.002 |
| -贾罗-温克勒 | 0.965 | 0.882 | 0.899 | 0.891 | −0.001 |
| -SoftTFIDF软件 | 0.965 | 0.882 | 0.901 | 0.892 | −0.000 |
| 特征. | A类. | 对. | R(右). | 一层楼. | ΔF1. |
|---|
| 模拟(ch) | 0.963 | 0.879 | 0.895 | 0.887 | |
| 模拟(wd) | 0.937 | 0.844 | 0.747 | 0.793 | |
| 模拟(ch+wd) | 0.962 | 0.877 | 0.890 | 0.884 | |
| 莱文斯坦 | 0.939 | 0.849 | 0.754 | 0.799 | |
| 贾罗-温克勒 | 0.918 | 0.920 | 0.534 | 0.676 | |
| SoftTFIDF软件 | 0.921 | 0.817 | 0.656 | 0.728 | |
|
| 完全 | 0.965 | 0.883 | 0.900 | 0.892 | |
|
| -模拟(ch) | 0.947 | 0.855 | 0.808 | 0.831 | −0.061 |
| -模拟(wd) | 0.965 | 0.885 | 0.898 | 0.891 | −0.001 |
| -模拟(ch+wd) | 0.950 | 0.868 | 0.810 | 0.838 | −0.054 |
| -列文斯坦 | 0.965 | 0.882 | 0.898 | 0.890 | −0.002 |
| -贾罗-温克勒 | 0.965 | 0.882 | 0.899 | 0.891 | −0.001 |
| -SoftTFIDF软件 | 0.965 | 0.882 | 0.901 | 0.892 | −0.000 |
| 特征. | A类. | 对. | R(右). | 一层楼. | ΔF1. |
|---|
| 模拟(ch) | 0.963 | 0.879 | 0.895 | 0.887 | |
| 模拟(wd) | 0.937 | 0.844 | 0.747 | 0.793 | |
| 模拟(ch+wd) | 0.962 | 0.877 | 0.890 | 0.884 | |
| 莱文斯坦 | 0.939 | 0.849 | 0.754 | 0.799 | |
| 贾罗-温克勒 | 0.918 | 0.920 | 0.534 | 0.676 | |
| SoftTFIDF软件 | 0.921 | 0.817 | 0.656 | 0.728 | |
|
| 完全 | 0.965 | 0.883 | 0.900 | 0.892 | |
|
| -模拟(ch) | 0.947 | 0.855 | 0.808 | 0.831 | −0.061 |
| -模拟(wd) | 0.965 | 0.885 | 0.898 | 0.891 | −0.001 |
| -模拟(ch+wd) | 0.950 | 0.868 | 0.810 | 0.838 | −0.054 |
| -列文斯坦 | 0.965 | 0.882 | 0.898 | 0.890 | −0.002 |
| -贾罗-温克勒 | 0.965 | 0.882 | 0.899 | 0.891 | −0.001 |
| -SoftTFIDF软件 | 0.965 | 0.882 | 0.901 | 0.892 | −0.000 |
| 特征. | A类. | 对. | R(右). | 一层楼. | ΔF1. |
|---|
| 模拟(ch) | 0.963 | 0.879 | 0.895 | 0.887 | |
| 模拟(wd) | 0.937 | 0.844 | 0.747 | 0.793 | |
| 模拟(ch+wd) | 0.962 | 0.877 | 0.890 | 0.884 | |
| 莱文斯坦 | 0.939 | 0.849 | 0.754 | 0.799 | |
| 贾罗-温克勒 | 0.918 | 0.920 | 0.534 | 0.676 | |
| SoftTFIDF软件 | 0.921 | 0.817 | 0.656 | 0.728 | |
|
| 完全 | 0.965 | 0.883 | 0.900 | 0.892 | |
|
| -模拟(ch) | 0.947 | 0.855 | 0.808 | 0.831 | −0.061 |
| -模拟(wd) | 0.965 | 0.885 | 0.898 | 0.891 | −0.001 |
| -模拟(ch+wd) | 0.950 | 0.868 | 0.810 | 0.838 | −0.054 |
| -列文斯坦 | 0.965 | 0.882 | 0.898 | 0.890 | −0.002 |
| -贾罗-温克勒 | 0.965 | 0.882 | 0.899 | 0.891 | −0.001 |
| -SoftTFIDF软件 | 0.965 | 0.882 | 0.901 | 0.892 | −0.000 |
我们检查了818个经过训练的相似性度量的错误实例。442个假阳性主要是由字母/单词的意外匹配引起的n个-克,例如。立场声明和极化状态缩写标准操作程序一些假阳性包括字母的细微差异,例如。腺嘌呤二磷酸和二磷酸腺苷缩写ADP公司。当前模型可能很难处理这些误报,因为模型必须根据几种相似性值(特征)进行确定。我们应该添加更多能够明确捕捉单词语义差异的特征(例如。腺嘌呤和腺苷)和语素(例如。di(数字)和三个).
在376个假否定中,167个实例涉及嵌套缩写。例如,EGF受体和上皮生长因子受体是缩写的扩展形式表皮生长因子-R,但前者的扩展形式包括缩写表皮生长因子,应该扩展到上皮生长因子。我们能够通过将缩写递归替换为扩展形式来纠正这些错误实例。尽管如此,我们还是发现了一些棘手的例子,例如。1-脱氨基-8-D-AVP和1-脱氨基-[D-Arg8]-加压素作为缩写的扩展形式DDAVP公司; 扩展子字符串并不简单8-D-AVP进入之内[D-Arg8]-血管加压素相似性度量无法识别29个同义扩展形式的实例,例如。护理学士和护理学士学位缩写英国标准编号。合并同义词词典的功能也可能有效。
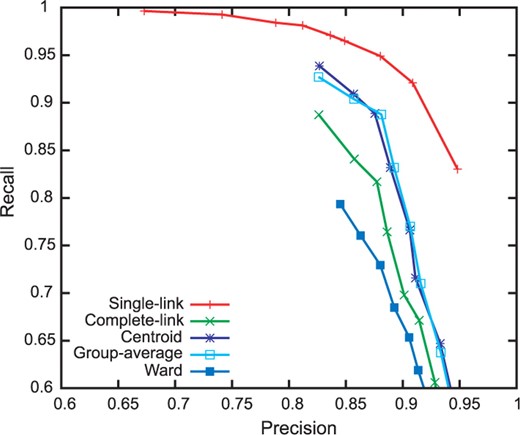
图4对同一数据集上不同距离阈值的聚类算法进行了性能比较。在这次评估中,我们测量了成对的精确度和召回率。对于每一对展开形式,一个真正数被定义为一对正确位于相同簇中的展开形式。假阳性、真阴性和假阴性的定义类似。我们通过绘制每种聚类算法在距离阈值范围从0.1(高精度和低召回率;右下角)到0.9(低精度和高召回率;左上角)时的性能来绘制精度-召回率曲线。
在图4单链路算法获得F1峰值得分(0.915),距离阈值为0.2(红色轨迹右侧第二个点)。此参数相当于合并两个扩展表单秒和t吨只有当项变化的概率对(+1|秒,t吨)大于0.8。我们可以解释为,最佳参数将决策边界从0.5–0.2的中性阈值拉紧,以减轻算法的连锁效应6特别有趣的是,其他聚类算法无法超越单链接算法;特别是,这些算法的召回率很低。在这些算法中,两个相似的展开形式不能仅仅根据它们的距离进行合并。例如,完全链接算法拒绝与集群中大多数扩展形式类似但与集群中扩展形式不同的扩展形式。其他聚类算法可能不太愿意形成一个聚类,但单链接算法信任经过训练的相似性度量,在这项任务中表现最佳。
3.2实体名称与缩写冲突
一些研究人员认为基因符号通常与模棱两可的缩写相同(高丹等。,2005; 于等。,2006). 例如,SCT公司代表人类基因的官方基因符号分泌素,但它也代表干细胞移植,鲑鱼降钙素,骶尾部畸胎瘤等(埃哈特等。,2006). 有多少蛋白质和基因名称与缩写冲突?为了检验缩写词消歧的重要性,我们从数据库中提取了实体名称,并将其与语义目录进行了比较。我们在以下资源中使用了实体名称:UniProtKB/Swiss-Prot数据库中的描述(DE)和基因名称(GE)字段(截至2009年7月7日);UMLS中具有“基因或基因组”类型的概念名称(2009年4月20日发布的2009AA);以及UMLS中“氨基酸、肽或蛋白质”类型的概念名称。我们假设数据库记录可能冲突如果记录中包含的名称也出现在缩写列表中,则使用缩写。当感官目录中包含名称作为具有多个感官的缩写时,冲突名称是模糊的。
表4显示数据库记录的数量,包括缩写,至少k个感官中的感官清单。第一排(k个≥0)表示每个数据库中的记录总数。结果显示,466 739条UniProt记录中,149 537条(32.0%)的名称也出现在缩写列表中(k个≥1)。在UniProt记录中,77 833(16.7%)有多义的模糊缩写(k个≥2); 同样,UMLS中13.2%的基因名称和6.4%的酸/肽/蛋白质名称可能与模糊缩写冲突(k个≥2). 此外,有4841条UniProt记录(1.0%)在缩略语词典中具有高度歧义,至少有30种意义。这些事实表明,仅仅通过将文本表达式与数据库记录相匹配来识别基因或蛋白质名称是不够的。
表4。数据库记录数,包括与缩写冲突的名称,至少k个感官。
| k个. | UniProt、,n个(%). | UMLS基因,n个(%). | UMLS酸,n个(%). |
|---|
| ≥0 | 466 739 ( 100) | 29 194 ( 100) | 116 011 ( 100) |
| ≥1 | 149 537 (32.0) | 7525 (25.8) | 17 854 (15.4) |
| ≥2 | 77 833 (16.7) | 3852 (13.2) | 7424(6.4) |
| ≥3 | 56 430 (12.1) | 2982 (10.2) | 5277 (4.5) |
| … | … | … | |
| ≥30 | 4841 (1.0) | 426 ( 1.5) | 507 ( 0.4) |
| k个. | UniProt、,n个(%). | UMLS基因,n个(%). | UMLS酸,n个(%). |
|---|
| ≥0 | 466 739 ( 100) | 29 194 ( 100) | 116 011(100) |
| ≥1 | 149 537 (32.0) | 7525 (25.8) | 17 854 (15.4) |
| ≥2 | 77 833 (16.7) | 3852(13.2) | 7424 ( 6.4) |
| ≥3 | 56 430 (12.1) | 2982 (10.2) | 5277 (4.5) |
| … | … | … | |
| ≥30 | 4841 (1.0) | 426 ( 1.5) | 507 ( 0.4) |
表4。数据库记录数,包括与缩写冲突的名称,至少k个感官。
| k个. | UniProt、,n个(%). | UMLS基因,n个(%). | UMLS酸,n个(%). |
|---|
| ≥0 | 466 739 ( 100) | 29 194 ( 100) | 116 011 ( 100) |
| ≥1 | 149 537 (32.0) | 7525 (25.8) | 17 854 (15.4) |
| ≥2 | 77 833 (16.7) | 3852 (13.2) | 7424 ( 6.4) |
| ≥3 | 56 430 (12.1) | 2982 (10.2) | 5277(4.5) |
| … | … | … | |
| ≥30 | 4841 (1.0) | 426 ( 1.5) | 507 ( 0.4) |
| k个. | UniProt、,n个(%). | UMLS基因,n个(%). | UMLS酸,n个(%). |
|---|
| ≥0 | 466 739 ( 100) | 29 194 ( 100) | 116 011 ( 100) |
| ≥1 | 149 537 (32.0) | 7525 (25.8) | 17 854 (15.4) |
| ≥2 | 77 833 (16.7) | 3852 (13.2) | 7424 ( 6.4) |
| ≥3 | 56 430 (12.1) | 2982 (10.2) | 5277(4.5) |
| … | … | … | |
| ≥30 | 4841 (1.0) | 426 ( 1.5) | 507 ( 0.4) |
3.3缩略语消歧
我们实现了一个系统,该系统使用感官目录解析缩写的定义。为了有效地处理所有MEDLINE摘要,在C++中实现了WSD训练和分类算法。此外,我们使用了网格计算环境,将整个MEDLINE划分为多个抽象集。一组作业分散在21个集群节点上,每个节点都运行在四个Intel Xeon 5140(2.33 GHz)处理器上,主内存为8 GB。在集群环境中完成10倍的交叉验证工作大约需要6-16小时。
使用带有缩略语定义的句子作为训练数据进行缩略语消歧。对于句子中缩写的每个定义,我们假设扩展形式是缩写的正确含义,并从句子中删除扩展形式:训练WSD分类器来预测缩写的“屏蔽”扩展形式。我们应用了10倍交叉验证来评估系统性能。系统性能通过精度、宏观平均精度、召回率和F1测量来衡量。我们计算每个缩写词和词义的准确度、准确度、召回率和F1分数,并将这些分数与每个缩写词及其词义进行平均。
表5显示了系统性能。在本次评估中,我们没有包括MEDLINE中定义的小于40倍的扩展形式,以加快交叉验证7; 通过这种截断操作,数据集中实例、缩写和意义的总数分别减少到5521074、11262和17613。这些实例占总培训实例(6547124)的84.3%。使用中所有特征的建议方法表2获得了0.984的准确度和0.986的F1分数。这些分数比基线系统(“多数”)的分数(准确度为0.789,F1分数为0.636)要好得多,该系统选择了最常使用缩写定义的扩展形式。我们还测量了省略合并类似扩展表单(“w/o集群”)的步骤时的性能。没有聚类的消歧效果更差(0.830 F1得分)。无论如何,没有聚类的感官用处不大。
| 特征. | A类. | 对. | R(右). | 一层楼. |
|---|
| 多数 | 0.789 | 0.621 | 0.663 | 0.636 |
| 多数(无集群) | 0.760 | 0.571 | 0.619 | 0.588 |
| 提出 | 0.984 | 0.992 | 0.984 | 0.986 |
| 建议(不带集群) | 0.801 | 0.854 | 0.831 | 0.830 |
| +邻居 | 0.925 | 0.961 | 0.929 | 0.934 |
| +本地 | 0.952 | 0.980 | 0.955 | 0.961 |
| +句子 | 0.967 | 0.987 | 0.967 | 0.973 |
| +摘要 | 0.982 | 0.992 | 0.983 | 0.986 |
| -摘要 | 0.968 | 0.988 | 0.968 | 0.974 |
| -摘要-邻居 | 0.968 | 0.988 | 0.968 | 0.974 |
| -摘要-本地 | 0.968 | 0.987 | 0.968 | 0.973 |
| -摘要-句子 | 0.953 | 0.980 | 0.956 | 0.962 |
| 特征. | A类. | 对. | R(右). | 一层楼. |
|---|
| 多数 | 0.789 | 0.621 | 0.663 | 0.636 |
| 多数(无集群) | 0.760 | 0.571 | 0.619 | 0.588 |
| 提出 | 0.984 | 0.992 | 0.984 | 0.986 |
| 建议(无集群) | 0.801 | 0.854 | 0.831 | 0.830 |
| +邻居 | 0.925 | 0.961 | 0.929 | 0.934 |
| +本地 | 0.952 | 0.980 | 0.955 | 0.961 |
| +句子 | 0.967 | 0.987 | 0.967 | 0.973 |
| +摘要 | 0.982 | 0.992 | 0.983 | 0.986 |
| -摘要 | 0.968 | 0.988 | 0.968 | 0.974 |
| -摘要-邻居 | 0.968 | 0.988 | 0.968 | 0.974 |
| -摘要-本地 | 0.968 | 0.987 | 0.968 | 0.973 |
| -摘要-句子 | 0.953 | 0.980 | 0.956 | 0.962 |
| 特征. | A类. | 对. | R(右). | 一层楼. |
|---|
| 多数 | 0.789 | 0.621 | 0.663 | 0.636 |
| 多数(无集群) | 0.760 | 0.571 | 0.619 | 0.588 |
| 提出 | 0.984 | 0.992 | 0.984 | 0.986 |
| 建议(无集群) | 0.801 | 0.854 | 0.831 | 0.830 |
| +邻居 | 0.925 | 0.961 | 0.929 | 0.934 |
| +本地 | 0.952 | 0.980 | 0.955 | 0.961 |
| +句子 | 0.967 | 0.987 | 0.967 | 0.973 |
| +摘要 | 0.982 | 0.992 | 0.983 | 0.986 |
| -摘要 | 0.968 | 0.988 | 0.968 | 0.974 |
| -摘要-邻居 | 0.968 | 0.988 | 0.968 | 0.974 |
| -摘要-本地 | 0.968 | 0.987 | 0.968 | 0.973 |
| -摘要-句子 | 0.953 | 0.980 | 0.956 | 0.962 |
| 特征. | A类. | 对. | R(右). | 一层楼. |
|---|
| 多数 | 0.789 | 0.621 | 0.663 | 0.636 |
| 多数(无集群) | 0.760 | 0.571 | 0.619 | 0.588 |
| 提出 | 0.984 | 0.992 | 0.984 | 0.986 |
| 建议(无集群) | 0.801 | 0.854 | 0.831 | 0.830 |
| +邻居 | 0.925 | 0.961 | 0.929 | 0.934 |
| +本地 | 0.952 | 0.980 | 0.955 | 0.961 |
| +句子 | 0.967 | 0.987 | 0.967 | 0.973 |
| +摘要 | 0.982 | 0.992 | 0.983 | 0.986 |
| -摘要 | 0.968 | 0.988 | 0.968 | 0.974 |
| -摘要-邻居 | 0.968 | 0.988 | 0.968 | 0.974 |
| -摘要-本地 | 0.968 | 0.987 | 0.968 | 0.973 |
| -摘要-句子 | 0.953 | 0.980 | 0.956 | 0.962 |
以“+”开头的行仅在分类器中使用相应特征时才显示性能。使用相邻上下文(“+neighbor”)的分类器获得0.929准确度和0.934 F1分数。最有效的特征是从抽象层次的上下文中获得的,准确率为0.982,F1得分为0.986;这与使用所有功能时的性能非常接近。以“-”开头的行报告从完整功能集中删除相应功能时的性能。例如,未使用抽象和句子上下文(“-抽象-句子”)训练的分类器达到了0.953的准确率和0.962的F1分数。这些结果很有趣,因为在消除缩略语歧义方面,更广泛的上下文(例如摘要和句子)比本地上下文(例如相邻词)更有用。这与单义全搜索假设(雅罗斯基,1995)这在WSD中很常见。
在表5,我们使用了聚类方法(第3.1节)获得缩略语消歧的意义清单。此实验设置已被之前的工作(高丹等。,2005),但由于我们没有考虑感官清单中错误的影响,因此该评估可能较为宽松。也就是说,如果聚类方法建立了一个感官数量较少的感官目录,消除歧义任务可能会变得不那么复杂。这可能会导致这样的情况,即消歧器似乎只会产生良好的性能值,因为感官清单是粗糙的,即合并了具有不同含义的扩展形式。虽然我们已经在第3.1节分析了感官清单中误差的影响。
表6报告了对手动构建感官清单的400个缩写进行消歧的性能第3.1节第一行和第二行显示了当我们使用手动(金标准)和聚类方法(自动)构建的语义清单训练和评估消歧系统时的消歧性能。第三行展示了当我们使用由聚类方法(自动)构建的语义清单训练消歧系统时的性能,并在手动构建的语义簇上测量消歧结果的正确性(金标准)。我们可以推断表5是合理的,因为使用手动和自动聚类的感官清单在表6.第四排表6显示了当我们训练一个没有意义清单的消歧系统时的性能,即预测最初的扩展形式。我们采用了一个宽松的评估标准:如果消歧系统预测的扩展形式与原始形式不同,但在手动构建的感官清单的同一集群中,我们认为这是一个正确的预测。虽然这个实验设置是不现实的,但第四行和其他行之间的比较证实了感官清单对精炼缩略语消歧训练数据有积极作用。
| 群集. | 评估. | A类. | 对. | R(右). | 一层楼. |
|---|
| 金标准 | 金标准 | 0.992 | 0.989 | 0.979 | 0.982 |
| 自动 | 自动 | 0.993 | 0.991 | 0.980 | 0.983 |
| 自动 | 金标准 | 0.993 | 0.991 | 0.978 | 0.982 |
| 不 | 金标准 | 0.984 | 0.980 | 0.963 | 0.968 |
| 群集. | 评估. | A类. | 对. | R(右). | 一层楼. |
|---|
| 金标准 | 金标准 | 0.992 | 0.989 | 0.979 | 0.982 |
| 自动 | 自动 | 0.993 | 0.991 | 0.980 | 0.983 |
| 自动 | 金标准 | 0.993 | 0.991 | 0.978 | 0.982 |
| 不 | 金标准 | 0.984 | 0.980 | 0.963 | 0.968 |
| 群集. | 评估. | A类. | 对. | R(右). | 一层楼. |
|---|
| 金标准 | 金标准 | 0.992 | 0.989 | 0.979 | 0.982 |
| 自动 | 自动 | 0.993 | 0.991 | 0.980 | 0.983 |
| 自动 | 金标准 | 0.993 | 0.991 | 0.978 | 0.982 |
| 不 | 金标准 | 0.984 | 0.980 | 0.963 | 0.968 |
| 群集. | 评估. | A类. | 对. | R(右). | 一层楼. |
|---|
| 金标准 | 金标准 | 0.992 | 0.989 | 0.979 | 0.982 |
| 自动 | 自动 | 0.993 | 0.991 | 0.980 | 0.983 |
| 自动 | 金标准 | 0.993 | 0.991 | 0.978 | 0.982 |
| 不 | 金标准 | 0.984 | 0.980 | 0.963 | 0.968 |
4相关工作
线路接口单元等。(2001,2002年a)使用UMLS Metathesaurus作为缩写词消歧的意义清单。帕霍莫夫等。(2005)通过在梅奥诊所的临床笔记中注释八种缩写的意义,编制了缩写消歧的意义清单。这些研究涉及人工编制感官清单和消除歧义的训练数据,其方法无法跟上缩略语和出版物数量不断增加的步伐。于等。(2006)应用了他们的AbbRE算法(Yu等。,2002)以获得缩写词典。他们对MEDLINE中60种缩写的消歧准确率为95%,覆盖率为82%。史蒂文森等。(2009)使用缩写识别方法从MEDLINE摘要中提取训练数据(Schwartz和Hearst,2003). 他们报告了99.0%的缩略语消歧准确率,但实验仅限于21种缩略语。
最相似的作品是高丹等。(2005). 他们没有实现自己的缩写识别,而是使用了简单健壮的缩写字典(Adar,2004),它是根据MEDLINE摘要自动构建的。他们使用两种不同类型的相似性对扩展形式进行聚类。一个是字母三粒度的余弦相似性。另一个是扩展形式的上下文词(周围词)的骰子相似性。虽然它要简单得多,但前者旨在以与我们的聚类方法相同的方式捕获扩展形式的相似性。后者旨在捕捉出现扩展形式的上下文的相似性。正如我们稍后讨论的那样,这将在缩写消歧的性能评估中产生一个问题。用于缩写词消歧的WSD分类器使用带线性核的SVM建模。分类器的特征由多词表达式组成。他们从评估集中排除了出现次数小于40次的缩写定义。他们报告了7806个多义缩写词的准确度0.985,准确度0.989,召回率0.982,F1得分0.985,平均意义1.57。该性能与本研究相当(表5).
他们的工作中提出了两个问题,应该仔细审查。一是他们的工作缺乏对聚类的独立评价。他们可能认为聚类的性能可以通过缩写词消歧的性能间接衡量。这种间接评价的问题与他们工作中的另一个问题密切相关。也就是说,他们对扩展形式的聚类利用了出现扩展形式的上下文的相似性。他们声称上下文相似性可以检测同义词替代。然而,由于上下文相似性也用于缩写消歧,这可能会隐藏聚类中的错误。换句话说,他们的实验设置可能会隐藏缩写消歧的困难实例,因为聚类方法可能会合并共享相似上下文的缩写的不同含义。相比之下,本文中描述的扩展形式的聚类仅基于扩展形式之间的相似性,与字母三粒度相比,其相似性度量更加精细。本研究独立于缩写词消歧,评估了聚类方法的性能。
作为参考,我们实现了他们的聚类方法。他们的相似性度量(使用文章中描述的阈值参数)在第3.1节(准确度0.890,准确度0.977,召回率0.311,F1得分0.471);该聚类方法的准确率为0.971,召回率为0.562,F1得分为0.712。在我们将字母三元相似性的阈值从0.8(原始参数)调整到0.45后,他们的聚类方法达到了0.881 F1分数的峰值性能,这仍然低于我们的聚类方法(0.915 F1分数)。因此,我们认为,尽管这两个系统在缩略语消歧方面的表现相似,但它们的语义清单中包含的错误比我们的多。我们还认为,感官清单的错误隐藏在他们对缩略语消歧的评估中。
5结论
在这篇文章中,我们描述了一种构建缩略语意义清单的方法。结果表明,基于ML相似性测度的单链聚类有助于缩略语消歧。该方法在MEDLINE获得的训练集和测试集上获得了0.984的准确度和0.986的F1分数。虽然缩写词消歧的性能数字与之前的工作大致相当,但我们特别演示了将缩写词消岐为概念或意义的意义清单的质量。结果还表明,在缩写消歧方面,更广泛的上下文(如摘要和句子)比局部上下文(如相邻词)更有用。本研究的未来方向是将MEDLINE摘要的缩写管理方法应用于全文文章。由于所提出的方法能够处理缩写词的变异和歧义问题,我们计划探讨缩写词消歧对其他文本挖掘任务的影响,例如信息检索、命名实体识别和共同参考解决。
基金:英国联合信息系统委员会(JISC)(国家文本挖掘中心);生物技术和生物科学研究委员会(批准BB/E004431/1)和JISC,国家文本挖掘中心项目。
利益冲突:未声明。
参考文献
. SaRAD:一个简单而强大的缩写词典
, 生物信息学
, 2004
,体积。 20
(第527
-533
) 等文本挖掘及其在系统生物学中的潜在应用
, 生物技术趋势。
, 2006
,卷。 24
(第571
-579
) 等自然语言处理的最大熵方法
, 计算。语言学家。
, 1996
,卷。 22
(第39
-71
) , . , . 生物医学文本中的缩写
, 生物和生物医学中的文本挖掘
, 2006
马萨诸塞州,美国
Artech House公司。
(第99
-119
) 等名称匹配任务字符串距离度量的比较
, IJCAI-2003网络信息集成研讨会论文集(IIWeb-03)。
, 2003
(第73
-78
) 等文本挖掘技术在生物医学文本中的应用现状
, 药物研发。今天
, 2006
,卷。 11
(第315
-325
) . 缩写对MEDLINE搜索的影响
, 阿卡德。急救医学。
, 1999
,体积。 6
(第292
-296
) 等在MEDLINE中解析缩略语的含义
, 生物信息学
, 2005
,卷。 21
(第3658
-3664
) , . 分类排序策略的一般理论。1.层次系统
, 计算。J。
, 1967
,卷。 9
(第373
-380
) . 能够纠正删除、插入和反转的二进制代码
, 苏联。物理学。多克。
, 1966
,卷。 10
(第707
-710
) , . 大型生物医学语料库中术语知识的挖掘
, 第八届太平洋生物计算研讨会(PSB 2003)。
, 2003
(第415
-426
) 等消除生物医学叙事文本中模糊生物医学术语的歧义:一种无监督方法
, 计算。生物识别。物件。
, 2001
,卷。 34
(第249
-261
) 等基于机器学习和UMLS中概念关系的歧义词自动消解
, 《美国医学杂志》。协会。
, 2002
,卷。 9
(第621
-636
) 等MEDLINE摘要中缩略语的研究
, AMIA研讨会会议记录。
, 2002
(第464
-468
) , . 了解消费者健康信息系统中的搜索失败
, AMIA年度研讨会会议记录。
, 2003
(第430
-434
) , . 首字母缩写词识别的监督学习方法
, 第八届加拿大人工智能会议(AI’2005)(LNAI 3501)
, 2005
柏林/海德堡
施普林格
第页10
. 用有限存储更新拟牛顿矩阵
, 数学。计算。
, 1980
,卷。 35
(第773
-782
) , . 使用术语识别方法构建缩写词典
, 生物信息学
, 2006
,卷。 22
(第3089
-3095
) 等一种用于缩略语识别的判别对齐模型
, 第22届国际计算语言学会议论文集(Coling 2008)。
, 2008
(第657
-664
) 等临床语篇中的缩略语和缩略语消歧
, 美国医学信息学协会(AMIA)年度研讨会论文集(AMIA-2005)。
, 2005
, . 用于查找缩写及其定义的混合文本挖掘
, 2001年自然语言处理经验方法会议(EMNLP)。
, 2001
(第126
-133
) 等从MEDLINE数据库中自动提取首字母缩写词意义对
, MEDINFO 2001年。
, 2001
(第371
-375
) , . 一种识别生物医学文本中缩写定义的简单算法
, 太平洋生物计算研讨会(PSB 2003)。
, 2003
8
(第451
-462
) , . 基因查询检索
, BMC生物信息学
, 2006
,体积。 7
第页。 220
等生物医学缩略语的消歧
, 2009年BioNLP研讨会论文集。
, 2009
(第71
-79
) . 记录联动的现状及当前研究问题
, 技术报告R99/04,收入部门统计
, 1999
美国华盛顿
美国国税局出版物
等生物医学术语映射数据库
, 核酸研究。
, 2005
,卷。 33
(第D289型
-D293型
) . 无监督词义消歧与有监督方法的比较
, 第33届计算语言学协会年会论文集(ACL 1995)。
, 1995
(第189
-196
) 等将生物医学文章中的缩写映射为完整形式
, 《美国医学杂志》。协会。
, 2002
,卷。 9
(第262
-272
) 等一种大规模、基于实体的方法,用于自动消除生物医学缩写词的歧义
, ACM事务处理。通知。系统。
, 2006
,卷。 24
(第380
-404
) 等ADAM:MEDLINE中的另一个缩写数据库
, 生物信息学
, 2006
,卷。 22
(第2813
-2818
)
作者注释
©作者2010。牛津大学出版社出版。
这是一篇根据知识共享署名非商业许可条款发布的开放存取文章(http://creativecommons.org/licenses/by-nc/2.5)它允许在任何媒体上无限制地进行非商业性使用、分发和复制,前提是正确引用了原始作品。







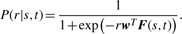
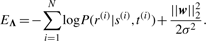
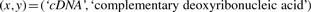



{kind=link}
{kind=link}
{kind=link}
{kind=link}