摘要
验收人:Phil Scarf
本文研究了足球比赛中抛投的最佳目标位置。跟踪数据的使用为调查提供了便利,该数据提供了球员的位置,以频繁的间隔(即每秒10次)进行测量。调查方法必然具有因果关系,因为有一些混杂的变量会影响入站位置和入站结果。一个简单的因果分析表明,平均而言,向后入站是有益的,并且每100次入站会多出两次。我们还观察到,长抛投有一个好处,即平均每100次抛投可以多投4次。这些结果得到了更复杂的因果分析的证实,该分析依赖于throw-ins的空间结构。
1.简介
因果关系的研究是科学和社会科学的一个基本研究课题。传统上,因果关系是通过实验来研究的,其中随机性是调查的主要技术工具。
在体育运动中,因果关系也很重要。例如,团队和个人想要知道特定的战术是否是有效的获胜策略。然而,在体育运动中,数据通常不是通过随机实验得出的。相反,数据通常是在非周边环境中从比赛中收集的。
幸运的是,因果方法的发展(珍珠,2009)提供了在非实验环境中研究因果关系的机会。虽然相关混杂变量的识别和测量是因果方法中一个必要且具有挑战性的组成部分,但在体育运动中,障碍似乎不那么引人注目。在体育运动中,目标通常是明确的(例如比对手多进球),比赛在合理的时间范围内结束(例如通常2-4小时),规则也很明确。最重要的是,随着详细的球员追踪数据(例如时空数据)的出现,我们的运动直觉通常允许识别和测量相关的混淆变量。
运动员追踪数据辅助的运动因果推断是一个相对较新但可能富有成果的研究领域。吴等。(2021)为足球比赛中的此类分析提供了一个模板,其中研究了传球的益处。在本次调查中,响应变量|年美元$|(结果)是二元的,治疗|X美元$|(交叉)是二进制的。吴等。(2021)得出的结论与现有的一些文献相矛盾,它们表明交叉是一种有价值的策略。Epasinghee Dona&Swartz(2023年)在这些观点的基础上,对足球比赛节奏进行了因果分析。在本次调查中,响应变量|Y美元$|(过量注射)是离散的,治疗|X美元$|(步速)是双变量和连续的。Epasinghee Dona&Swartz(2023年)确立了以速度比赛是一种有价值的策略,这一结论以前在足球界是没有的。
本文扩展了对吴等。(2021)和Epasinghee Dona&Swartz(2023年)我们的分析调查了足球比赛中掷界外球的最佳位置。在本次调查中,响应变量|Y美元$|(合成镜头)是二进制的,处理|X美元$|(直通接收位置)是空间的。石头等。(2021)此前,他们利用英超联赛的数据研究了投篮问题,在那里他们得到了一个令人惊讶的结果,即后向投篮在投篮创造方面更为成功。尤其是,石头等。(2021)没有访问玩家跟踪数据的权限。如果没有跟踪数据,就不可能评估直销对象的开放程度。与我们的论文不同,石头等。(2021)没有进行因果分析。
如前所述,球员追踪数据的可用性为深入分析足球中的抛投提供了机会。有了球员跟踪数据,球场上每个球员的位置坐标都会被频繁记录下来(例如,足球比赛中每秒10次)。有了如此详细的数据,探索体育领域新问题的机会前所未有。与球员追踪相关的大量数据集也带来了数据管理问题,需要开发超越传统统计分析的现代数据科学方法。Gudmundsson和Horton(2017)回顾了在有球员追踪数据的入侵运动中使用的时空分析。
在第2节中,我们描述了玩家跟踪数据并讨论了相关挑战。然后,我们描述了如何从跟踪数据构建一次性数据集。一次性数据集是用于因果分析的源文件。还提供了一些探索性数据分析。在第3节中,我们讨论了倾向得分在因果调查中的使用。倾向性评分描述了治疗的概率|X美元$|(throw-in的空间位置)给定的潜在协变量|美元(W)$|在第4节中,我们对掷骰子相对于球场位置的最佳位置进行了因果分析。这有三种方式。前两种方法很简单,因为它们基于定义与后向/前向throw-in相对应的二进制变量和(2)定义与短/长向throw-in相对应该的二进制变量。然后,我们考虑基于完整空间处理的更复杂的分析|X美元$|分析的主要结果是,后抛和长抛都能带来竞争优势。我们在第5节中提供了一些结论性意见。
除了战术之外,最近在与足球相关的文献中也有许多调查。不同主题的示例包括比赛定势(Forrest&McHale,2019年)、及格评价(高地等。,2020),竞争平衡(马纳西斯等。2022)以及比赛结果的预测(中心阿克等。2022).
2.数据
对于这项调查,我们有一个大数据问题,即2019赛季中超联赛(CSL)237场常规赛(缺少3场比赛)的事件数据和球员跟踪数据都可用。时间表是平衡的,16支球队中的每一支都会与每个对手进行两次比赛,一次在主场,另一次在客场。
事件数据和跟踪数据是独立收集的,其中事件数据由铲球和传球等事件组成,无论何时发生“事件”,这些数据都会与辅助信息一起记录。这些事件由观看电影的技术人员手动记录。事件数据和跟踪数据都有时间戳,因此可以比较这两个文件的内部一致性。收集跟踪数据的方式多种多样。一种方法是使用射频识别技术,每个球员和球都有标签,可以准确跟踪物体。在CSL数据集中,跟踪数据是通过视频和光学识别软件获得的。跟踪数据由七个变量测得的每场比赛大约130万行组成,每十分之一秒记录一次数据。每一行对应于给定时刻的特定玩家。尽管通过我们的分析得出的推论是针对中超联赛的,但我们建议这些方法适用于任何收集跟踪数据的足球联赛。
2.1内置数据集
我们对CSL跟踪和事件数据进行了预处理。最初,数据是在xml文件中提供的,我们使用读取_xml函数XML格式使用R软件打包。结果跟踪和事件数据被写入csv文件格式。
最终,我们为每个匹配构建了插入数据帧。这些是全面的数据集,使我们能够调查与一次性使用相关的各种有趣问题。throw-in数据帧是一个矩阵,其中的行对应于throw-in。每一个投掷都经过了翻译和标准化,使得投掷角度和下场距离根据球队的进攻方向保持一致。这些列包括以下基本变量:初选队的识别、对手队的识别,初选球员的识别和二进制变量|Y美元$|这取决于被淘汰队的控球权是否会导致淘汰队射门。变量|Y美元$|作为一个反应变量,用于指示与投掷相关的成功。当对手获得控球权、出现哨声、比赛暂停或球出界时,投掷队的控球结束。虽然进球是衡量成功的更直接指标,但我们注意到,在大多数职业联赛中,进球在足球比赛中是罕见的,平均每场比赛进球不到三个。我们还记录了相对空间位置|$X=(r,θ)$|通过相对空间位置,我们指的是在球场上接球点的位置给定的接球点长度及其半径角。测量是相对于发生吞吐量的现场一侧进行标准化的。使用极坐标,半径臂|美元$|是投掷的长度,以米为单位|$\θ$|是以度为单位测量的扔进角度。例如,|X美元=(10,90)$|描述了一个长度为10米,垂直于接触线抛出的抛出物。
对于第3节中描述的倾向得分,我们希望关联协变量|美元(W)$|对相对空间位置有潜在影响|X美元$|这些变量来源于我们的足球直觉,在因果分析中被视为混淆变量。在提出协变量时|美元(W)$|,我们从广阔的角度出发,引入一些变量,这些变量甚至可能会影响throw-in的空间位置。我们引入了其他列变量|$W=(t,d,f,o,b,r)$|到插入数据帧,其中
在(1)中,我们定义了时间变量|$t(美元)$|这样,上半场加时赛中出现的抛球被设置为|$t=45$|.对于下半场加时赛中发生的掷界外球,我们设置|$t=90$|.因此|$t(美元)$|是一个混合变量(连续和离散)。
得分差异|d(吨)美元$|是一个离散变量,表示初学者团队的领导。例如,|d(t)美元=-2$|这表明新加入的球队正在输掉两个进球。
字段位置变量|f(t)美元$|已按间隔标准化|$(0,100)$|计算不同长度的字段。例如,|f(t)=50.0美元$|对应于从中场进行的掷界外球。
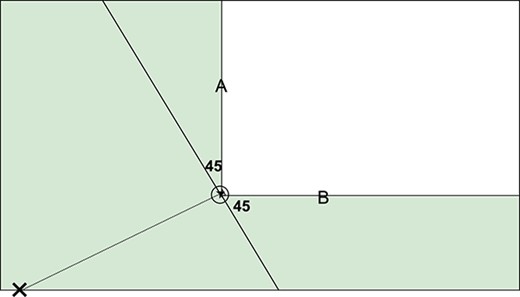
开放性变量|o(吨)美元$|在(1)中描述了直通接收器的打开程度。开放式接收机更有可能成为一次性目标|o(吨)美元$|,我们首先考虑图中的阴影区域1在这种情况下,只有这一地区的防守方会构成拦截投掷物的威胁。这种想法是,防守方在接球方后面的防守方可以被接球方“围住”,而不参与其中。我们的经验是,背上有防守队员的接球手将向球移动,能够将防守队员挡在后面并获得控球权。因此,这样的防守球员不会对控球构成威胁。如果防守者位于从引入位置到接收器的垂直线45度范围内,我们将其定义为“封闭”。诚然,45度角有点随意。变量|o(吨)美元$|然后通过取阴影区域中最近的防御者到接收器的距离来计算。这样,距离越长,接收器的开放性就越大。如果切入被拦截,|o(t)=0.0$|开放性与更复杂的球场控制或场地所有权概念有关。首次采用Voronoi细分(Voronoi1907,Kim,2004年). 有关现场所有权的更高级指标,请参阅Wu&Swartz(2022).
图。1
该图描绘了投掷者(X)和接收器(开放点)之间的线,以及标记的两条射线|美元$|和|十亿美元$|与垂直线成45度角。由此形成的阴影区域对应于防御者被假定会对拦截投掷物构成威胁的区域。
对于第五个变量|十亿美元$|在(1)中,我们访问了网站上提供的赛前投注赔率https://www.oddsportal.com/soccer/china/super-league-2019/results/。下注赔率(以十进制格式报告,也称为欧洲赔率)为我们提供了两支球队的相对实力。为了简单起见,我们暂时忽略了庄家强加的活力。1在这种情况下,赌博赔率的解释|十亿美元$|对于一支球队来说,球队有赛前概率|1美元/b$|赢得比赛。因此|十亿美元$|略大于1.0表示非常喜欢,而较大的值|十亿美元$|表示一个失败者.为了更好地理解下注赔率,考虑公平赔率|十亿美元$|,下注|x美元$|美元和概率|美元$|赢得赌注。这样的赌注的预期利润是|$-x^\ast(1-p)+(xb-x)^\ast p$|并将其设置为零|$p=1/b$|我们的运动直觉是,实力较强的球队可能会与实力较弱的球队有不同的一次性策略。一般来说,实力较强的球队往往与实力较弱的球队踢得不同(例如,Silva&Swartz(2016)). 图2描述了上面描述的一些变量。
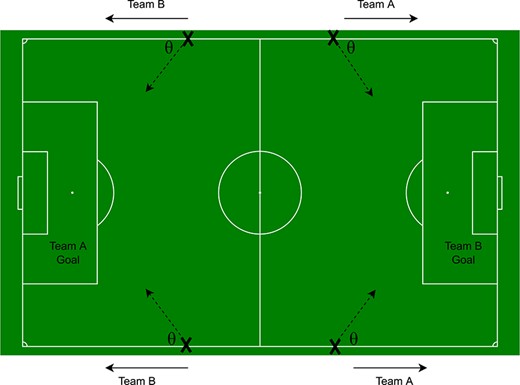
图。2
该图说明了与throw-in相对应的一些关键变量。描述了四个切入点,其中角度|$\θ$|是对场地边线和进攻方向的标准化解释。四个输入分别对应于|r=15美元$|米和|$f(t)=60.0$|.
最后一个变量|美元$|是二元的,并根据初选团队是否具有人力优势进行设置。在这种情况下,人们可能会期望防守球队表现不同(例如,更多球员排在球后)。
为了创建一次性数据帧,我们在跟踪数据中逐帧循环,使用事件数据匹配事件和时间。该过程需要对所有237个匹配进行大约15分钟的计算。
说明倾向得分变量|美元(W)$|由(1)给出,考虑一场比分为1-0的比赛。在第70分钟,各队都是全队,领先队在中场进行一次淘汰赛,他们是最受欢迎的球队,赛前的赔率为十进制|b美元=1.5$|(去掉了活力)。此外,假设距离接球员最近的防守队员站在距离接球员8米的边线上。在这种情况下,|$W=(t,d,f,o,b,r)=(70,1,50,8.0,1.5,0)$|.
向量|$W=(t,d,f,o,b,r)$|这与我们的足球直觉相符,因为它是淘汰决定的推动者。我们确实考虑了其他没有显著影响的变量。例如,考虑了目标接收器的速度,这是通过将玩家在投掷前两帧和投掷前二帧的欧几里德距离计算出来的。我们还对红牌变量进行了实验|美元$|在对应于人力优势、无优势和人力劣势的分类设置中。然而,只有人力优势被证明是显著的,因此它被简化为一个二元变量。
2.2数据管理
随着数据科学中越来越复杂和庞大的数据集,数据完整性的重要性再怎么强调也不为过。没有准确的数据,就无法进行可靠的推断。在这个应用程序中,我们根据事件和跟踪数据构建了一次性数据集,其中以下问题提出了挑战。
一些投掷被确定为超短(即长度为0米)。这些是罚球(59次)的结果,并从数据集中删除。
一些掷界外球被认定为不可能长(即长度超过40米)。这是投掷过程中发生的一个事件的结果,该事件使投掷无效(例如犯规),并且下一个事件发生在非自由投掷位置。这些事件很少发生(13次),已从数据集中删除。
在我们的事件数据集中,throw-In是在throw-In发生之前标记的,因此我们应该考虑下一个事件,以获取接收throw-In的位置。在入场前会发生球员换人、红牌/黄牌等事件。因此,在计算入场长度之前,我们必须仔细消除这些事件|美元$|和角度|$\θ$|.
有两次投掷,目标接收器未被识别。
从比赛中最初发生的8467次淘汰赛中,有8393次可用于数据分析。
2.3勘探数据分析
探索性数据分析通常指导正式统计模型的开发。我们提出了几个与我们的调查有关的阴谋。
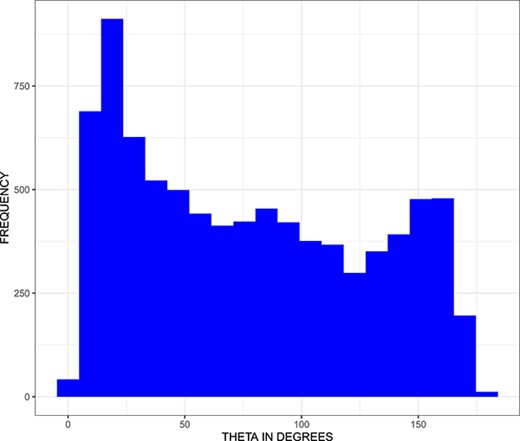
在图中。三,我们提供了方向变量的直方图|$\θ$|与数据集中的所有throw-in关联。我们观察到有更多的前投(即。|$θ<90$|)而不是向后推出(即。|$θ>90$|). 这与我们的直觉相符,因为进攻队通常希望将球推进到更具威胁性的得分位置。我们在大约|$θ=22.5$|和|$θ=157.5$|都很有趣。这些一次性产品离接触线很近。
图。三。
变量的直方图|$\θ$|描述了球队进攻方向上相对于边线的投掷角度。
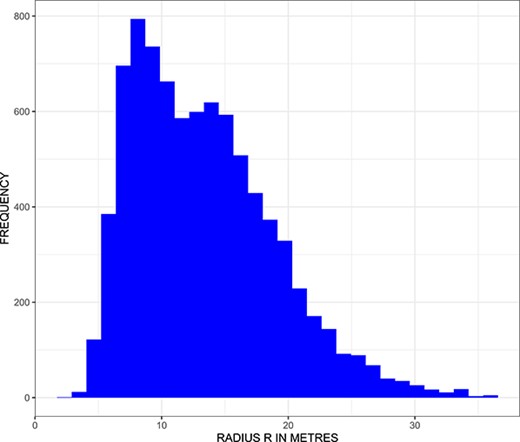
在图中。4,我们提供了半径臂的直方图|美元$|(或者简单地说长度)与数据集中的所有throw-in关联。我们观察到一个右倾直方图,其中模态插入长度约为10米。有几个长度接近40米的长插入。虽然这样的抛入距离看起来不太可能,但这些抛入可能是由于一个球最初没有被接住,并且有一段时间没有被传球。
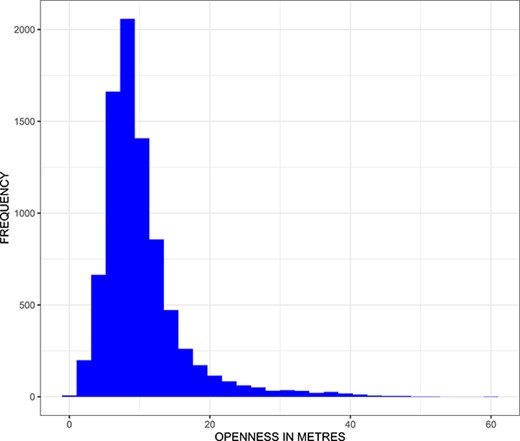
在图中。5,我们提供了开放性变量的直方图|0美元$|它给出了从接收器到位于图中阴影区域的接收器最近的对手的距离。1我们观察到中间距离约为10 m,直方图向右倾斜。从实践的角度来看,一名球员在以下情况下表现良好:|o美元=10$|m或|o美元=30$|m、 例如。注意,在一次性数据集中有126个案例,阴影区域没有对手(见图。1). 这些观察结果没有反映在图中。5,尽管保留了它们进行因果分析。
图。5
开放性变量的直方图|0美元$|描述了接收者的开放程度(见第2.1节中的正式定义)。
3.倾向得分
暂时想象一下,一次性问题是作为随机实验设计的。对于每个导入,我们将随机化位置|$X=(r,θ)$|然后我们会讲述|Y美元$|(无论完成控球是否导致射门)|X美元$|。这将使我们能够确定最佳|X美元$|。通过随机化,我们的想法是,导致|X美元$|在不同的实现中几乎是一致的|X美元$|.
当然通过匹配数据,|X美元$|不是随机的。很可能不仅如此|X美元$|取决于协变量|美元(W)$|在(1)中,而且|Y美元$|取决于|美元(W)$|换句话说,|美元(W)$|在调查两者之间的关系时,是一个混淆变量|Y美元$|和|X美元$|.
因此,我们希望获得倾向得分|$\mathrm{P}(X\mid W)$|描述了治疗的可能性|X美元$|(即吞吐量的相对空间位置)与混杂变量有关|美元(W)$|。如果我们能够做到这一点,那么通过匹配,我们可以进行比较|$Y_{1}$|正在接受治疗|$X_{1}$|相对于|$Y_{2}$|正在接受治疗|$X_{2}$|如果|$X_{1}$|和|$X_{2}$|有相似的倾向得分。这是因果方法的基本逻辑,其中倾向得分被用作随机化的替代。
虽然我们使用了倾向得分匹配(PSM)方法,但也可以基于加权倾向得分(PSW)进行分析。后者的优点是可以在分析中使用所有观察结果。成田、特纳和德托托(2023)提供关于使用倾向得分分析的有见地的教程,特别注意PSW分析。
在第4节中,我们考虑了三种因果分析:(1)向后传入与向前传入,(2)长传入与短传入,以及(3)基于完整空间变量的综合分析|$X=(r,θ)$|在这三种分析中,我们使用的倾向得分模型分别是logistic、logistic和随机森林。
4.原因分析
我们回到主要问题,即涉及一次性入住的最佳位置。在第3节中,我们开发了一个倾向评分模型,该模型可以得出分数|$\mathrm{P}(X\mid W)$|我们现在的目标是调查二进制响应变量之间的因果关系|Y美元$|(直接控球是否会导致射门)和空间处理变量|$X=(r,\θ)$|.
我们提出了三个分析,其中前两个分析解决了以下简单问题:(1)前向淘汰比后向淘汰更可取吗?(2) 长入职比短入职好吗?对于第三种分析,我们使用更复杂的方法来调查整个空间变量的影响|$X=(r,θ)$|在|Y美元$|.
为了进行第4.1和4.2节中的简单因果分析,我们对混淆变量进行了一些调整|$W=(t,d,f,o,b,r)$|如方程式(1)所示。首先,我们离散化时间变量|$t(美元)$|根据这两类|$t<45$|最小值和|$t>45$|min.之所以这样做,是因为我们怀疑相应的响应变量相对于|$t(美元)$|我们认为,比赛的两半反映了不同的比赛风格。我们还将分数差异分类为|$d(t)=-2,-1,0,1,2$|哪里|d(t)美元=-2$|表明新加入的团队正在以大幅度亏损(两个或更多目标),并且|d(t)美元=2$|表示新加入的球队以大比分获胜(两个或多个进球)。关于目标差异,我们尝试将类别扩展到|$d(t)=-3,-2,-1,0,1,2,3$|然而,我们观察到一些无关紧要的影响,我们认为这是由于与细胞对应的观察很少|$d=-3$|和|d美元=3$|。我们离散化字段位置变量|$f美元$|根据|$f<67美元$|和|$f\geq 67美元$|因为在球场的最后三分之一有战术上的差异。第三,我们截断了开放性变量|0美元$|这样|$o>10$|m是根据|o美元=10$|这样做是因为我们认为|$o=1$|米和|$o=2$|m、 例如。然而,对于|$o>10$|,所有直通式接收器均有效打开。我们用不同的开放性阈值进行了实验(例如。|$o>12$|m) 但发现这在因果分析中几乎没有什么不同。
4.1基于投入方向的原因分析
我们简化了涉及空间因果变量的问题|$X=(r,θ)$|到二进制上下文,以便控件|0美元<θ<90$|对应于前向淘汰和治疗|90美元<θ<180$|对应于后向淘汰。因此,相应的倾向得分变为|$P(90<θ<180 \mid W)$|我们使用logistic回归进行拟合。在这个框架中,有|$n_{0}=5023$|控制观测和|$n_{1}=3370$|治疗观察。当然,可能还有其他类别的人对直入方向感兴趣(例如侧向直入);第4.3节分析了传入方向的全谱。
在表中1,我们提供了基于变量的逻辑回归结果|$W=(t,d,f,o,b,r)$|如第2.1节所述。我们观察到|$t(美元)$|随着时间的推移,越来越多的新人倒退,这场比赛意义重大。这可能是球队疲劳和不太愿意在球场上前进的结果。净胜球|d美元$|在我们观察到更大的潜在客户与向前推进相关的情况下,这一点非常重要。这可能是因为领导团队踢得更好,更有信心和精力,从而更频繁地下场。一次性位置变量|$f美元$|非常重要。随着投掷位置移到进攻第三位,由于边线的限制,有更多的向后投掷。开放性变量|0美元$|这与我们的直觉是一致的。随着球队捍卫自己的进球,我们希望通过后插能更加开放。下注赔率变量|十亿美元$|非常显著,表明实力较弱的球队往往有更多的前插球员。这是一个有趣的结果,可以解释为这些球队信心不足,可能觉得他们取得成功的唯一途径是向前迈进。相反,实力更强的球队通常对球更舒服,愿意通过结构化的传球和控球来加强比赛,因此更有可能向后投球。关于红牌变量,我们观察到新加入的团队(具有人力优势)往往有更多落后的新加入。这可能是因为防守球队的风格更加谨慎,防守队员更多。
表1第4.1节中逻辑回归的结果,确定倾向得分|$P(90°\tθ\t 180°\m W)$|.
| 变量. | 估算. | 标准误差. | p值. |
|---|
| 截距 | −0.184 | 0.134 | 0.171 |
| 时间|$t\mathrm{(45,90)}$| | 0.108 | 0.050 | 0.030* |
| 目标差异|$d\mathrm{(-1)}$| | −0.208年 | 0.091 | 0.021* |
| 目标差异|$d\mathrm{(0)}$| | −0.575 | 0.088 | 第5页至第11页*** |
| 目标差异|$d\mathrm{(1)}$| | −1.185 | 0.101 | 2e-16号机组*** |
| 目标差异|$d\mathrm{(2)}$| | −1.250 | 0.122 | 2e-16号机组*** |
| 现场位置|$f(\geq 67)$| | 0.706 | 0.047 | 2e-16号机组*** |
| 开放|0美元$| | 0.026 | 0.011 | 0.018* |
| 下注赔率|十亿美元$| | −0.050 | 0.008 | 5e-10号*** |
| 红牌|美元$| | 0.641 | 0.176 | 3e-04号*** |
| 变量. | 估算. | 标准误差. | p值. |
|---|
| 截距 | −0.184 | 0.134 | 0.171 |
| 时间|$t\mathrm{(45,90)}$| | 0.108 | 0.050 | 0.030* |
| 目标差异|$d\mathrm{(-1)}$| | −0.208 | 0.091 | 0.021* |
| 目标差异|$d\mathrm{(0)}$| | −0.575 | 0.088 | 5e-11号*** |
| 目标差异|$d\mathrm{(1)}$| | −1.185 | 0.101 | 2e-16号机组*** |
| 目标差异|$d\mathrm{(2)}$| | −1.250 | 0.122 | 2e-16号机组*** |
| 现场位置|$f(\geq 67)$| | 0.706 | 0.047 | 2e-16号机组*** |
| 开放|0美元$| | 0.026 | 0.011 | 0.018* |
| 下注赔率|十亿美元$| | −0.050 | 0.008 | 5e-10号*** |
| 红牌|美元$| | 0.641 | 0.176 | 3e-04号*** |
表1第4.1节中确定倾向得分的逻辑回归结果|$P(90°\tθ\t 180°\m W)$|.
| 变量. | 估算. | 标准误差. | p值. |
|---|
| 截距 | −0.184 | 0.134 | 0.171 |
| 时间|$t\mathrm{(45,90)}$| | 0.108 | 0.050 | 0.030* |
| 目标差异|$d\mathrm{(-1)}$| | −0.208 | 0.091 | 0.021* |
| 目标差异|$d\mathrm{(0)}$| | −0.575 | 0.088 | 5e-11号*** |
| 目标差异|$d\mathrm{(1)}$| | −1.185 | 0.101 | 2e-16号机组*** |
| 目标差异|$d\mathrm{(2)}$| | −1.250 | 0.122 | 2e-16号机组*** |
| 现场位置|$f(\geq 67)$| | 0.706 | 0.047 | 2e-16号机组*** |
| 开放|0美元$| | 0.026 | 0.011 | 0.018* |
| 下注赔率|十亿美元$| | −0.050 | 0.008 | 5e-10号*** |
| 红牌|美元$| | 0.641 | 0.176 | 3e-04号*** |
| 变量. | 估算. | 标准误差. | p值. |
|---|
| 截距 | −0.184 | 0.134 | 0.171 |
| 时间|$t\mathrm{(45,90)}$| | 0.108 | 0.050 | 0.030* |
| 目标差异|$d\mathrm{(-1)}$| | −0.208 | 0.091 | 0.021* |
| 目标差异|$d\mathrm{(0)}$| | −0.575 | 0.088 | 5e-11号*** |
| 目标差异|$d\mathrm{(1)}$| | −1.185 | 0.101 | 2e-16号机组*** |
| 目标差异|$d\mathrm{(2)}$| | −1.250 | 0.122 | 2e-16号机组*** |
| 现场位置|$f(\geq 67)$| | 0.706 | 0.047 | 2e-16号机组*** |
| 开放|美元$| | 0.026 | 0.011 | 0.018* |
| 下注赔率|十亿美元$| | −0.050 | 0.008 | 5e-10号*** |
| 红牌|美元$| | 0.641 | 0.176 | 3e-04号*** |
自|$n_{1}<n_{0}$|、匹配概念(奥斯汀,2011;Imbens,2004年)是我们尝试匹配每个|$n_{1}$|用相应的对照病例治疗病例,使每对患者根据潜在的匹配情况有相似的估计倾向得分|美元(W)$|然后,目的是得出的两组(对照组和治疗组)在匹配特征上相似,并且两组之间的差异可以归因于治疗(即反向导入)。有很多方法可以进行倾向得分的匹配(斯图亚特,2010年). 例如,匹配可以在有替换或没有替换的情况下进行。匹配也可能是贪婪的(每个治疗病例与最接近的合格对照病例相匹配),或者是为了优化某些全局标准而执行的。此外,可以在匹配过程中引入随机化,以便评估匹配引起的灵敏度。PSM有一些缺点(Guo(郭)等。2020). 例如,对于不平等的治疗组和对照组,匹配会导致数据丢失。此外,PSM将协变量向量的维数降为单个维数。
在我们的应用程序中,我们从|$n_{1}$|在throw-in向后的情况下,我们使用最近邻方法来选择throw-In向前的匹配情况。具体来说,我们使用匹配包装(Sekhon,2011年)在统计编程语言R中,随机选择(替换)处于治疗病例倾向评分规定公差范围内的对照病例。与没有替换的采样相比,替换的采样往往会提高匹配的质量。与确定性匹配程序不同,最近邻程序的随机方面允许我们重复分析,以检查推断的敏感性。我们将分析重复了1000次。为了获得匹配的感觉,对于1000个分析中的每一个,我们记录了倾向得分的最大绝对差异。然后在1000次分析中对该数量进行平均,得出差异0.0048。
我们测试了协变量分布的平衡性|$W=(t,d,f,o,b,r)$|使用双样本t检验对配对治疗组和对照组进行检验(罗森鲍姆和鲁宾,1985年). 对于特定匹配(随机选择),对应于|t、d、f、o、b、r美元$|分别为0.222、0.396、0.116、0.962、0.190和0.640。缺乏显著性表明,在混杂变量之间的匹配中存在平衡。
在实施匹配程序后,我们计算了平均治疗效果|$\mathrm{ATE}=\bar{Y}(1)-\bar{Y}(0)$|,其中|$\bar{Y}(1)$|是后向投篮的平均投篮次数|$\bar{Y}(0)$|是向前投篮的平均投篮次数。我们得到|$\mathrm{ATE}=0.018$|标准误差|$0.006$|导致p值|$0.001$|。这是基于匹配过程的1000次迭代,使用|$n_{1}=3370$|配对。结果是显著的,表明后向投掷是有益的。这证实了石头等。(2021)具体地说,我们的因果分析表明,从100次向后抛投中,大约比向前抛投多出两次投篮。就获得竞争优势而言,这是一个有意义的结果。
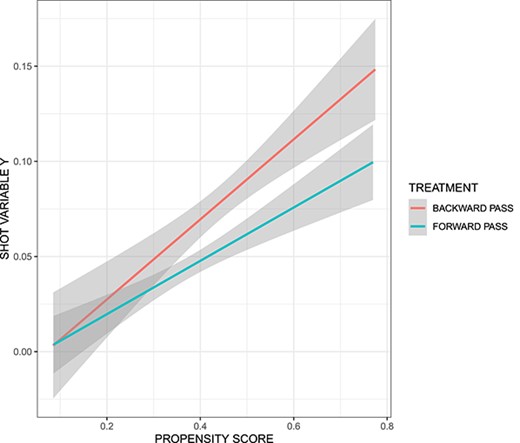
在图中。6,我们对涉及匹配的随机选择案例的情况提出了更精细的观点。对于每个组(治疗组和对照组),我们平滑变量|Y美元$|关于倾向得分。平均而言,根据我们模型的规范,我们观察到执行正向试射没有任何好处。随着倾向得分的增加(即条件更有利于进行反向试射),与进行正向试射相比,反向试射的好处(就投篮而言)增加。这意味着玩家倾向于对掷骰子的方向做出正确的决定。随着向后抛入的可能性越来越大,向后抛入成功的概率也越来越高。
图。6
放炮变量的平滑图|年美元$|关于向后抛入(治疗红色)和向前抛入(对照蓝色)的倾向得分。
4.2基于投入长度的原因分析
在本节中,我们考虑第二个推理问题,涉及throw-In的长度。近年来,“长期”试穿在职业足球中越来越受欢迎,我们希望调查长期试穿是否具有优势。我们再次简化了涉及因果变量的问题|$X=(r,θ)$|转换为二进制上下文。在这种情况下,我们将长期淘汰的处理定义为|r>15美元$|m和|60美元<θ<120$|.施加双重条件,使长抛入与沿边线抛入不对应(即。|$\θ$|接近0或180)。相反,我们的兴趣主要集中在球场中部的长时间抛投。这样长时间的投掷似乎是一种越来越常见的策略。因此,相应的倾向得分变为|$P((r>15)\cap(60<θ<120)\mid W)$|我们使用logistic回归进行拟合。在这个框架中|$n_{0}=7831$|控制观测和|$n_{1}=562$|治疗观察。
在表中2,我们提供了基于变量的logistic回归结果|$W=(t,d,f,o,b)$|。请注意,红牌变量|美元$|不包括在表的分析中2因为它在统计上不显著。在本分析中,我们没有表中那么多具有统计意义的术语1然而,我们确实注意到,系数估计值通常与我们的足球直觉相对应。例如,我们预计下半场会有更长的比赛时间,其中一支球队可能会不顾一切,需要进球。在目标差异方面也出现了同样的模式,落后一个目标(绝望)的团队更有可能长期淘汰。|$d=0,1,2$|),他们不太可能进行长期试穿|$f美元$|这也是明智的,因为在进攻第三方,长距离投篮更常见。开放性变量|0美元$|高度显著;为了在直通电话上保持占有率,长直通电话要求接收器比短直通电话更开放是合理的。
表2第4.2节中逻辑回归的结果决定了倾向得分|$P((r\gt 15)\上限(60\lt\θ\lt 120)$|.
| 变量 | 估算 | 标准误差 | p值 |
| 截距 | −3.613 | 0.274 | 2e-16号机组*** |
| 时间|$t\mathrm{(45,90)}$| | 0.355 | 0.095 | 2004年2月*** |
| 目标差异|$d\mathrm{(-1)}$| | 0.116 | 0.161 | 0.472 |
| 目标差异|$d\mathrm{(0)}$| | −0.113 | 0.160 | 0.477 |
| 目标差异|$d\mathrm{(1)}$| | −0.602 | 0.194 | 0.002** |
| 目标差异|$d\mathrm{(2)}$| | −0.444 | 0.228 | 0.052 |
| 现场位置|$f(\geq 67)$| | 0.212 | 0.089 | 0.017* |
| 开放性|0美元$| | 0.111 | 0.023 | 2006年2月*** |
| 下注赔率|十亿美元$| | −0.024 | 0.015 | 0.135 |
| 变量 | 估算 | 标准误差 | p值 |
| 截距 | −3.613 | 0.274 | 2e-16号机组*** |
| 时间|$t\mathrm{(45,90)}$| | 0.355 | 0.095 | 2004年2月*** |
| 目标差异|$d\mathrm{(-1)}$| | 0.116 | 0.161 | 0.472 |
| 目标差异|$d\mathrm{(0)}$| | −0.113 | 0.160 | 0.477 |
| 目标差异|$d\mathrm{(1)}$| | −0.602 | 0.194 | 0.002** |
| 目标差异|$d\mathrm{(2)}$| | −0.444 | 0.228 | 0.052 |
| 现场位置|$f(\geq 67)$| | 0.212 | 0.089 | 0.017* |
| 开放|0美元$| | 0.111 | 0.023 | 2006年2月*** |
| 投注赔率|十亿美元$| | −0.024 | 0.015 | 0.135 |
表2第4.2节中逻辑回归的结果决定了倾向得分|$P((r\gt 15)\cap(60\lt\theta\lt 120))$|.
| 变量 | 估算 | 标准误差 | p值 |
| 截距 | −3.613 | 0.274 | 2e-16号机组*** |
| 时间|$t\mathrm{(45,90)}$| | 0.355 | 0.095 | 2004年2月*** |
| 目标差异|$d\mathrm{(-1)}$| | 0.116 | 0.161 | 0.472 |
| 目标差异|$d\mathrm{(0)}$| | −0.113 | 0.160 | 0.477 |
| 目标差异|$d\mathrm{(1)}$| | −0.602 | 0.194 | 0.002** |
| 目标差异|$d\mathrm{(2)}$| | −0.444 | 0.228 | 0.052 |
| 现场位置|$f(\geq 67)$| | 0.212 | 0.089 | 0.017* |
| 开放|美元$| | 0.111 | 0.023 | 2006年2月*** |
| 下注赔率|十亿美元$| | −0.024 | 0.015 | 0.135 |
| 变量 | 估算 | 标准误差 | p值 |
| 截距 | −3.613 | 0.274 | 2e-16号机组*** |
| 时间|$t\mathrm{(45,90)}$| | 0.355 | 0.095 | 2004年2月*** |
| 净胜球|$d\mathrm{(-1)}$| | 0.116 | 0.161 | 0.472 |
| 目标差异|$d\mathrm{(0)}$| | −0.113 | 0.160 | 0.477 |
| 目标差异|$d\mathrm{(1)}$| | −0.602 | 0.194 | 0.002** |
| 目标差异|$d\mathrm{(2)}$| | −0.444 | 0.228 | 0.052 |
| 现场位置|$f(\geq 67)$| | 0.212 | 0.089 | 0.017* |
| 开放|0美元$| | 0.111 | 0.023 | 2006年2月*** |
| 下注赔率|十亿美元$| | −0.024 | 0.015 | 0.135 |
我们执行第4.1节所述的匹配程序。为了检验推论的敏感性,我们重复了1000次分析。对于1000次分析中的每一次,我们都记录了倾向得分的最大绝对差异。然后在1000次分析中对该数量进行平均,得出差异0.0002。然后我们得到了平均的治疗效果|$\mathrm{ATE}=\bar{Y}(1)-\bar{Y}(0)=0.042$|标准误差|$0.016$|和相应的p值|$0.004$|。这是基于匹配过程的1000次迭代,使用|$n_{1}=562$|配对。在这里,|$\bar{Y}(1)$|是长时间投篮的平均投篮次数|$\bar{Y}(0)$|否则为结果放炮的平均次数。结果表明,长距离投篮是有益的,因为每100次投篮可以多投4次。在该分析中,p值大于第4.1节中的值,但仍很重要。我们注意到,与第4.1节中的方向分析相比,此处所述的距离分析所涉及的观测更少。结果表明,最近涉及更多长投的趋势是一种合理的策略。
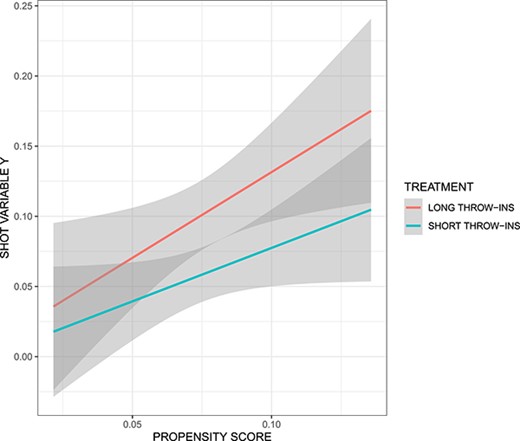
在图中。7,我们考虑一个随机选择的涉及匹配的情况。我们平滑变量|Y美元$|关于各组(治疗组和对照组)的倾向得分。我们再次看到,职业足球运动员正在做出正确的决定。随着执行更长时间的试用期的可能性增加,这样做的好处也会增加。通过检查倾向得分,我们观察到长投相对罕见。这表明团队可能会考虑增加长时间投掷的频率。
图。7
放炮变量的平滑图|Y美元$|关于涉及长入组的治疗组(红色)和对照组(蓝色)的倾向性得分。
4.3基于投掷物全空间位置的因果分析
在本节中,我们使用了完整的空间变量|$X=(r,θ)$|深入了解两者之间的因果关系|X美元$|和shot变量|Y美元$|.Gelman&Meng(2004)考虑简单二进制以外的结构|X美元$|如第4.1节和第4.2节所分析。在这里,我们使用机器学习方法来获得倾向得分。
机器学习方法在预测中的一个基本原理是,复杂现象通常很难明确建模。这里,我们有一个二维空间响应变量|$X=(r,θ)$|和解释向量|美元(W)$|如(1)所述。我们对两者之间的关系没有多少先验知识|X美元$|和|美元(W)$|例如,关系可能只涉及变量的子集|美元(W)$|,的组件|美元(W)$|可能是相关的,最重要的是|$X\约g(W)$|涉及未知且可能复杂的函数|$克$|此外,关系的随机方面通常是未知的。
对于此应用程序,我们使用随机森林作为所选的机器学习算法。随机森林(Genuer和Poggi,2020年)使用随机森林包装(Liaw&Wiener,2002年)在R编程语言中。其基本思想是,随机森林是许多决策树的集合,其中预测结果在树上聚合。使用多棵树可以提高预测能力,并减少推理对单个树的依赖。树中的分裂适应非线性关系,终端节点提供离散值的估计概率|X美元$|.
随机森林程序的一个特点是|美元(W)$|(确定树中的节点)通过该算法得到最优解。随机森林程序为我们提供了倾向得分|$P(X \mid W)$|用于数据|美元(X,W)$|这是空间因果分析的必要组成部分。在此分析中,|$P(X \mid W)$|是在空间位置收到球的概率|$X=(r,θ)$|考虑到比赛情况|美元(W)$|.
在选择随机森林过程的调整参数时,我们的目标是提高预测精度。我们使用网格搜索方法获得随机森林模型的优化超参数。由此,我们得到entrees=300,mtry=1,nodesize=2。所有其他超参数都设置为默认值。为了评估模型性能,我们使用了10倍交叉验证。
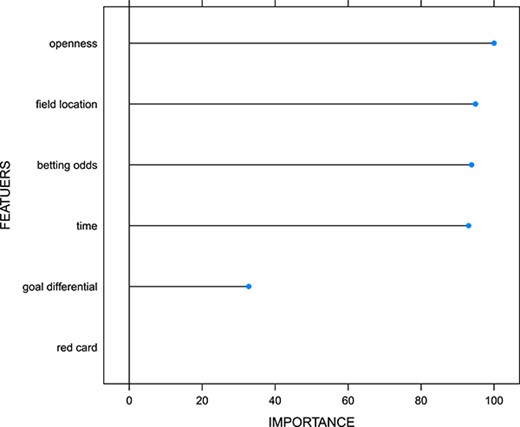
在图中。8,我们给出了变量的特征重要性图|$W=(t,d,f,o,b,r)$|用于随机森林过程。该地块作为随机森林包裹。如第4.1节和第4.2节所述,我们发现变量|t、d、f、o、b美元$|都很重要。特别地,|t、f、o、b美元$|与目标差异的重要性大致相同|$d美元$|稍微不那么重要。红牌变量|美元$|在完整的空间分析中并不重要。
我们的因果研究从离散二维空间开始|X美元$|其中可能会收到throw-in。该区域被截断,因此我们仅包括从直通位置垂直延伸18 m,从直通地点水平延伸20 m的观测值(左右两侧)。因此,该地区的面积为720平方米(即18米乘以40米)。然后将该区域划分为尺寸为4m(水平)×2m(垂直)的矩形。这导致720/(2*4) =90个矩形。基于|$n=7704$|截断区域中的抛出,我们可以预期|7704/90美元\约85美元$|每个矩形的平均吞吐量。当一个矩形中的观察数小于30时,我们合并相邻的矩形。共有19个矩形,少于30个观察值。在加入观察不足的矩形后,剩下71个矩形。对于收到的每一个throw-in,都有一个倾向得分|$P(X \mid W)$|使用基于随机森林的机器学习方法获得。
之前在第4.1节和第4.2节的二进制分析中使用的匹配思想现在扩展到网格结构。我们首先随机选择一个一次性产品并记录其倾向得分|$p=p(X \mid W)$|在剩下的70个矩形中,我们选择倾向得分最接近的throw-in|美元$|; 这些是匹配的观察结果。
重复上一段中的过程|M美元=30$|次。这意味着在给定的矩形内有30个观测值,每个观测值都与其余70个矩形中的每个观测值相匹配。对于每个矩形,我们计算平均拍摄次数|$\bar{Y}$|由矩形内的throw-in生成。
由于初始|百万美元=30$|随机选择的观察结果。因此,使用|$\bar{Y}$|对于100次迭代中平均的每个矩形。我们通过计算两组之间倾向得分的最大绝对差异来研究倾向得分的匹配|$(^{71}_{\ 2})$|对。然后在|M美元=30$|观察值和100次迭代得出的值为|$0.003$|因此,微小的差异表明匹配是成功的。
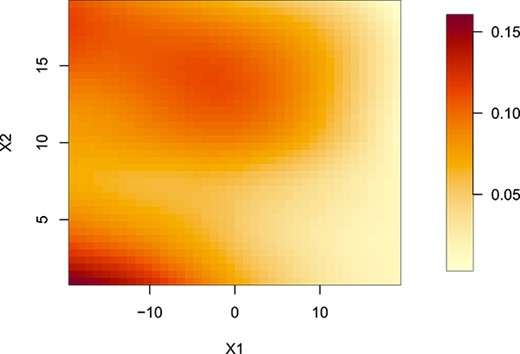
调查|$X美元$|在|Y美元$|,我们生成平均处理效果的平滑热图|$\bar{Y}$|。在图中。9,使用函数平滑热图interp.loess公司在R包中三峡工程我们观察到较暗区域(即较大区域|$\bar{Y})$|向左(向后推入)不太长(即向外小于5m)。我们还观察到顶部附近较暗的区域(从大约10米到17米的长抛投)。这证实了我们在第4.1节和第4.2节中的发现。
图。9
平均处理效果的平滑热图|$\bar{Y}$|根据第4.3节的算法,在throw-in接收位置的网格上。重点|$(X1,X2)=(0,0)$|指一次性位置。
我们对与匹配程序相关的可变性的调查包括计算标准偏差|$(\bar{Y})$|对于每个矩形。对于特定矩形,我们得到|美元\bar{Y}(Y)_{我}$|对于|1美元$|-第次迭代,|$i=1,\ldots,100$|.数量|$(\bar{Y})$|是对应于|美元\bar{Y}(Y)_{我}$|值。然后|%s(\bar{Y})$|在我们得到的71个矩形上取平均值|$\bar{s}(\bar{Y})=0.064$|从图中的颜色编码图例。9很明显,由于匹配引起的可变性并不会导致地图出现有意义的颜色差异。
5.结论
对于寻求竞争优势的球队来说,战术评估是一个困难而重要的问题。本文使用跟踪数据促进的因果方法来调查足球中的掷骰子。我们的结果表明,令人惊讶的结果是,向后抛入比向前抛入更有效。令人惊讶的是,一个倒退的接受者在球场上处于一个威胁较小的进攻位置。我们还证明了长期使用的好处,这一策略的使用似乎在增加,但其好处此前尚未量化。
我们将这项工作视为在运动中使用因果方法评估战术的模板。当然,因果方法的局限性在于混淆变量的潜伏期|美元(W)$|影响战术的因素|X美元$|以及响应|Y美元$|我们工作的一个基本前提是,运动专项知识和跟踪数据允许识别重要的混淆变量。
有一个重要而实际的问题与我们的工作有关|$W^{\ast}=(t,d,f,o,b,r)$|,应该如何执行throw-in|X美元$|优化|Y美元$|? 假设所有混杂变量都已确定。那么我们希望比较一下一次性策略|$X_{0}$|对抗一次性战术|$X_{1}$|两者都发生在|$W^{\ast}$|.会有|$n_{0}$|观测值|$X_{0}$|和|$n_{1}$|观测值|$X_{1}$|不幸的是,|$n_{0}$|和|$n_{1}$|将很小(可能为0或1),因此无法进行有意义的比较。也许有办法解决这个问题,也许通过分类|$W^{\ast}$|,|$X_{0}$|和|$X_{1}$|进入更大的兴趣阶层。随着更多数据的提供,这可能是未来的研究方向。
虽然与定位球有关的战术可能是最容易想到的,也是最先想到的调查,但我们也希望继续对更复杂的场景和各种运动的战术进行分析。
工具书类
奥斯丁
,第页。
(
2011
)减少观察性研究中混杂效应的倾向评分方法简介
.多元行为。物件。
,46
,399
–424
. 伊帕辛格·多纳
,N。
&斯瓦茨
,T.B.公司。
(
2023
)足球比赛节奏的因果关系研究
.统计应用——意大利应用统计杂志
,35
,第6条。 福雷斯特
,D。
&麦克海尔
,I.G.公司。
(
2019
)利用统计学检测体育比赛中的假球
.IMA J.管理。数学。
,30
,431
–449
. 盖尔曼
,答:。
&孟
,X-L。
(编辑)(
2004
)应用贝叶斯建模和不完全数据视角的因果推断
.纽约
:威利
. 格努尔
,R。
&波吉
,J.-M.公司。
(
2020
)带R的随机森林
.纽约
:施普林格
. 格维兹门松
,J。
&霍顿
,M。
(
2017
)团队运动的时空分析
.ACM计算。Surv公司。
,50
,第二十二条
. Guo(郭)
,美国。
,弗雷泽
,M。
&陈
,问:。
(
2020
)倾向得分分析:最近的辩论和讨论
.J.Soc.社会工作研究。
,11
,463
–482
. 高地
,电子显微镜。
,Salte Wiig公司
,答:。
,圣勒哈内
,M。
&Hvattum公司
,L.M.公司。
(
2020
)联合足球中传球能力的评价
.IMA J.管理。数学。
,31
,91
–116
. 中心阿克
,O。
,什乌雷克
,G.公司。
&钇锌
,L.M.公司。
(
2022
)基于分数的足球比赛结果预测40年的实验回顾
.IMA J.马纳格。数学。
,33
,1
–18
. 伊姆本斯
,G.W.公司。
(
2004
)异质性下平均治疗效果的非参数估计:综述
.经济收益率。斯达。
,86
,4
–29
. 基姆
,美国。
(
2004
)一场足球比赛的沃罗诺伊分析
.非线性分析。模型。控制
,9
,233
–240
. Liaw公司
,答:。
&维纳
,M。
(
2002
)基于randomForest的分类和回归
.R新闻,R项目的新闻稿
,2
,18
–22
. 马纳西斯
,五、。
,Ntzoufras公司
,一、。
&阅读
,J·J。
(
2022
)欧洲足球比赛平衡测度与结果假设的不确定性
.IMA J.管理。数学。
,33
,19
–52
. 珍珠
,J。
(
2009
)因果关系:模型、推理和推理
,第二版。剑桥大学出版社
:剑桥
. 罗森鲍姆
,中华人民共和国。
&鲁宾
,D.B.博士。
(
1985
)使用包含倾向得分的多元匹配抽样方法构建对照组
.美国统计局。
,39
,33
–38
. Sekhon公司
,J.S.公司。
(
2011
)具有自动平衡优化的多元和倾向评分匹配软件:R的匹配包
.J.统计软件。
,42
,1
–52
. 席尔瓦
,R。
&斯瓦茨
,T.B.公司。
(
2016
)足球比赛中的换人次数分析
.J.数量。分析。体育
,12
,113
–122
. 石头
,J.A.公司。
,史密斯
,答:。
&巴里
,答:。
(
2021
)被低估的定位球:2018-2019赛季英超足球赛投篮分析
.国际体育科学杂志。教练。
,16
,830
–839
. 斯图亚特
,欧洲航空公司。
(
2010
)因果推理的匹配方法。回顾与展望
.统计科学。
,25
,1
–21
. 吴
,年。
&斯瓦茨
,T.B.公司。
(
2022
)基于直观运动模型的俯仰控制新度量
. 吴
,年。
,丹尼尔森
,答:。
,胡
,J。
&斯瓦茨
,T.B.公司。
(
2021
)足球比赛中传球的语境分析
.J.数量。分析。体育
,17
,57
–66
.
作者注释
©作者2023。牛津大学出版社代表数学及其应用研究所出版。保留所有权利。







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}