现在可以按项目元数据搜索存档的源代码。
浏览Software Heritage存档的大量源代码可能会让人望而却步,我们正在努力提供适当的工具来搜索其中的内容。作为朝着这个方向迈出的第一步,我们已经为您提供了在源代码来源的数千万个URL中进行搜索的可能性。这已经很有用了,因为这些URL通常包含项目名称和托管组织的名称,但我们需要更多。
下一步是使软件元数据也可搜索。此元数据是从打包信息中提取的(如package.json、pom.xml等),特别有趣,因为它是由软件作者管理的,并通过伪造或存储库与源代码一起分发。
我们很高兴地宣布,基于元数据的搜索现在可用于Software Heritage。
这里有一个例子:假设我们正在寻找朱利安·丹茹参与的项目。现在我们可以去软件遗产的搜索页面,在搜索栏中键入名称,勾选“在元数据中搜索”框,按Enter键,我们将找到要查找的内容:
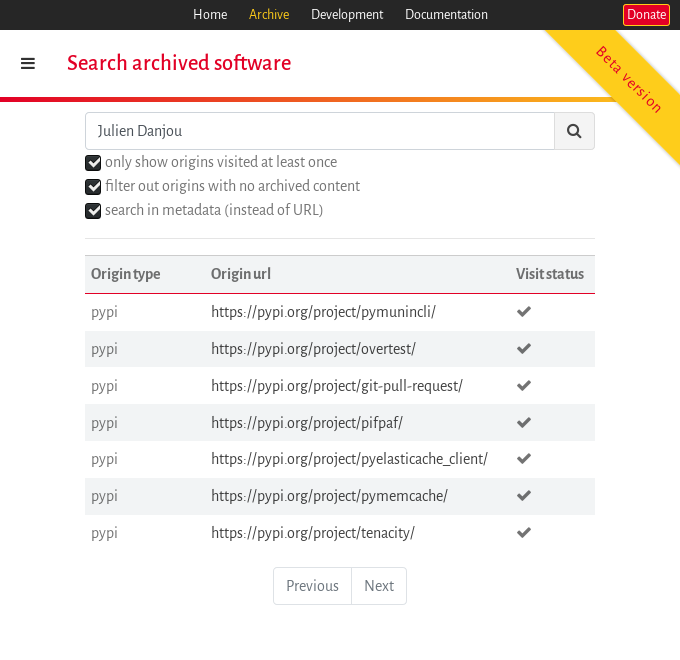
应对元数据异构挑战。
看起来很容易,对吧?但这实际上相当复杂,因为软件本体论和元数据标准的前景相当广阔。不同的社区产生了不同的本体论和词汇表来描述软件和软件源代码,不同的打包系统倾向于使用不同的本体和词汇表。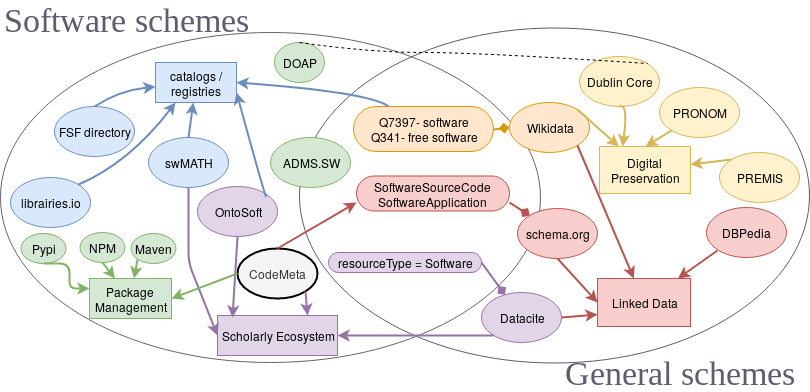
由于软件遗产中存档的源代码的异质性,我们需要一个通用词汇表,该词汇表包含了存档中可以找到的尽可能多的软件元数据,我们希望避免引入另一个词汇表。
幸运的是,CodeMeta倡议已经解决了这个问题人行横道桌子是一种罗塞塔石碑,用于将软件元数据术语来回转换为单个词汇表,这是对类SoftwareApplication和SoftwareSourceCode,为链接数据和语义web提供了方便的桥梁。
发动机罩下面
对于那些对技术实现感兴趣的人,这里是对所有这些工作原理的概述。我们已经创建了一个异步元数据索引机制,该机制在整个存档中筛选出可以转换为CodeMeta格式的元数据。
对于存档中的每个软件源,我们都会对其进行最近的访问,并查找其“HEAD”版本的根目录。如果有一个文件的名称指示它是元数据文件(根据可以随时间扩展的基于文件名的启发式),我们将获取它,并将其提供给适当的元数据转换器。生成的(CodeMeta)元数据存储在数据库中,然后可以在搜索时进行查询。
每个元数据转换器将输入文件作为字典进行读取,根据CodeMeta项目提供的对照表翻译关键名称,并对结果进行规范化。
例如净现值法元数据应用以下步骤:
- 读取
package.json包文件
- 将JSON解码为Python字典
- 使用NPM人行横道表
- 将NPM特定格式中的值解析/规范化为CodeMeta期望的结构
- 将获取的字典转换为CodeMeta对象
只有步骤4特定于NPM,其他步骤在所有元数据转换器之间共享。规范化每个字段的代码通常很短,因为它已经被设计为机器可读的。除去注释,NPM元数据转换器只有75行代码长,其中一半以上的代码用于处理漏洞和作者字段,这些字段需要更复杂的处理,因为它们允许更灵活的格式。
当前支持的元数据格式如下:Maven的pom.xml、NPM的package.json、Python的PKG-INFO和Ruby的gemspec。
这只是一个起点,我们欢迎为支持其他元数据格式做出贡献。我们已经提供了关于如何添加对其他元数据格式的支持的教程。由于CodeMeta人行横道表,实际上您不需要做什么就可以添加对首选格式的支持;NPM翻译人员的核心看起来是这样的:
类NpmMapping(DictMapping,SingleFileMapping):#加载NodeJS的人行横道表:mapping=CROSSWALK_TABLE[“节点JS”]#定义要查找的文件名:filename=b'包.json'#定义要读取的字段:string_fields=[“名称”,“版本”,“主页”,“描述”,“电子邮件”]定义转换(self,raw_content):#将输入字节解码为文本字符串:raw_content=原始内容解码()#将文本字符串加载为JSON对象/字典:content_dict=json.loads(原始内容)#将JSON对象/字典转换为CodeMeta:返回自我_翻译字典(内容字典)
为软件遗产开发工作做出贡献通过添加对其他元数据格式的支持!
-作者:莫兰·格伦彼得和瓦伦丁·洛伦茨

