从启动我们的技术预览一年前新的和改进的代码搜索体验公开测试版去年11月,我们在GitHub Universe上发布了一篇文章,围绕着我们作为开发人员如何查找、阅读和导航代码,GitHup的一些核心产品经历经历了一系列创新和巨大变化。
我们听到的关于新代码搜索体验的一个问题是,“它是如何工作的?”我在GitHub Universe的演讲,本文对这个问题给出了一个高层次的答案,并提供了一个了解该产品的系统架构和技术基础的小窗口。
那么,如何做它有效吗?简而言之,我们在Rust中从头开始构建了自己的搜索引擎,专门用于代码搜索领域。我们称这个搜索引擎为Blackbird,但在我解释它的工作原理之前,我认为它有助于稍微了解我们的动机。乍一看,从头开始构建搜索引擎似乎是一个值得怀疑的决定。你为什么要这样做?现在已经有很多现有的开源解决方案了吗?为什么要建造新的东西?
公平地说,在GitHub的整个历史中,我们一直在尝试使用现有的解决方案来解决这个问题。你可以在Pavel Avgustinov的帖子中阅读更多关于我们旅程的信息,GitHub的代码搜索简史,但有一点值得注意:我们在使用通用文本搜索产品时运气不佳代码搜索。用户体验很差,索引很慢,而且托管成本很高。现在有一些更新的、特定于代码的开放源码项目,但它们绝对不能在GitHub的规模下工作。因此,了解了所有这些,我们有动力通过三件事创建自己的解决方案:
- 我们有一个全新用户体验的愿景,即能够通过迭代搜索、浏览、导航和阅读代码来提出代码问题并获得答案。
- 我们理解这一点代码搜索与一般文本搜索有着独特的区别。代码已经被设计成可以被机器理解,我们应该能够利用这种结构和相关性。搜索代码也有独特的要求:我们要搜索标点符号(例如,句点或左括号);我们不想堵塞;我们不希望从查询中删除停止词;我们想用正则表达式进行搜索。
- GitHub的规模确实是一个独特的挑战。当我们第一次部署Elasticsearch时,花费了数月时间为GitHub上的所有代码编制索引(当时大约有800万个存储库)。今天,这个数字超过了2亿,而且代码不是静态的:它在不断变化,这对搜索引擎来说是一个相当大的挑战。对于beta版,您目前可以搜索近4500万个存储库,代表115 TB的代码和155亿个文档。
最终,货架上没有任何东西能满足我们的需求,所以我们从头开始做了一些事情。
只使用grep?
不过,首先让我们探讨一下暴力解决问题的方法。我们经常会遇到这样的问题:“你为什么不直接使用grep?”为了回答这个问题,让我们用撕裂115 TB的内容。在具有八核Intel CPU的机器上,ripgrep可以运行详尽的正则表达式查询在内存中缓存的13 GB文件上,只需2.769秒,或大约0.6 GB/sec/core。
我们很快就能看到,对于我们拥有的大量数据来说,这确实行不通。代码搜索在64核、32台机器集群上运行。即使我们成功地将115 TB的代码放在内存中,并假设我们可以完美地并行处理工作,我们也会让2048个CPU内核饱和96秒,以满足单个查询!只能运行一个查询。其他人都得排队。这将产生每秒0.01个查询(QPS),祝您好运,将QPS翻倍,这将是与领导就基础设施账单进行的有趣对话。
没有一种经济高效的方法可以将这种方法扩展到GitHub的所有代码和所有GitHup用户。即使我们在这个问题上投入了大量资金,它仍然无法满足我们的用户体验目标。
你可以看到这是怎么回事:我们需要建立一个索引。
搜索索引入门
只有以索引的形式预先计算一组信息,我们才能快速进行查询,您可以将其视为从关键字到出现关键字的文档ID排序列表(称为“发布列表”)的映射。例如,这里有一个编程语言的小索引。我们扫描每个文档以检测它是用什么编程语言编写的,分配一个文档ID,然后创建一个反向索引,其中语言是关键,值是文档ID的发布列表。
远期指数
| 单据ID
|
内容
|
| 1 |
定义界限
放入“mit”
结束 |
| 2 |
fn限制(){ |
| 三 |
函数mits(){ |
反转索引
| 语言
|
文件ID(过帐)
|
| JavaScript脚本 |
3, 8, 12, … |
| 红宝石 |
1, 10, 13, … |
| 生锈 |
2, 5, 11, … |
对于代码搜索,我们需要一种特殊类型的反向索引,称为ngram索引,这对于查找内容的子字符串很有用。安国家地理信息管理局是长度为的字符序列n个例如,如果我们选择n=3(三角图),则构成内容“极限”的ngram为林,亚胺,麻省理工学院,它的。根据我们上面的文档,这些三角图的索引如下所示:
| 国家地理信息管理局
|
单据ID(过账)
|
| 林 |
1、2、… |
| 亚胺 |
2, … |
| 麻省理工学院 |
1, 2, 3, … |
| 它的 |
2, 3, … |
为了执行搜索,我们将多个查找的结果相交,以提供字符串出现的文档列表。使用三角索引,您需要四次查找:林,亚胺,麻省理工学院、和它的为了完成查询限制.
然而,与哈希图不同的是,这些索引太大,内存无法容纳,因此,我们为需要访问的每个索引构建迭代器。这些延迟返回已排序的文档ID(ID是根据每个文档的排名分配的),我们对迭代器进行交叉和合并(根据特定查询的要求),读取的距离仅足以获取所需数量的结果。这样,我们就不必将整个发帖列表保存在内存中。
索引4500万个存储库
我们面临的下一个问题是如何在合理的时间内构建该索引(记住,这在我们的第一次迭代中花费了数月时间)。与通常情况一样,这里的技巧是确定对我们正在使用的特定数据的一些见解,以指导我们的方法。在我们的例子中,有两件事:Git使用内容寻址散列事实上,GitHub上有很多重复的内容。这两个见解引导我们做出以下决定:
- 按Git blob对象ID划分碎片这为我们提供了一种在碎片之间均匀分布文档的好方法,同时避免了任何重复。由于特殊的存储库,不会有任何热服务器,我们可以根据需要轻松扩展碎片的数量。
- 将索引建模为树并使用增量编码来减少爬行量并优化索引中的元数据。对我们来说,元数据是指文档出现的位置列表(路径、分支和存储库)以及有关这些对象的信息(存储库名称、所有者、可见性等)。对于流行内容,此数据可能相当大。
我们还设计了该系统,使查询结果在承诺级别上保持一致。如果您在团队成员推送代码时搜索存储库,则在系统完全处理新提交的文档之前,您的结果不应包括新提交的文件。事实上,当您从存储库范围的查询中返回结果时,其他人可能会分页查看全局结果,并查看不同的、先前的但仍然是一致的索引的状态。这对于其他搜索引擎来说很难做到。Blackbird将此级别的查询一致性作为其设计的核心部分。
让我们建立一个索引
有了这些见解,让我们将注意力转向使用Blackbird构建索引。此图表示系统的接收和索引端的高级概述。
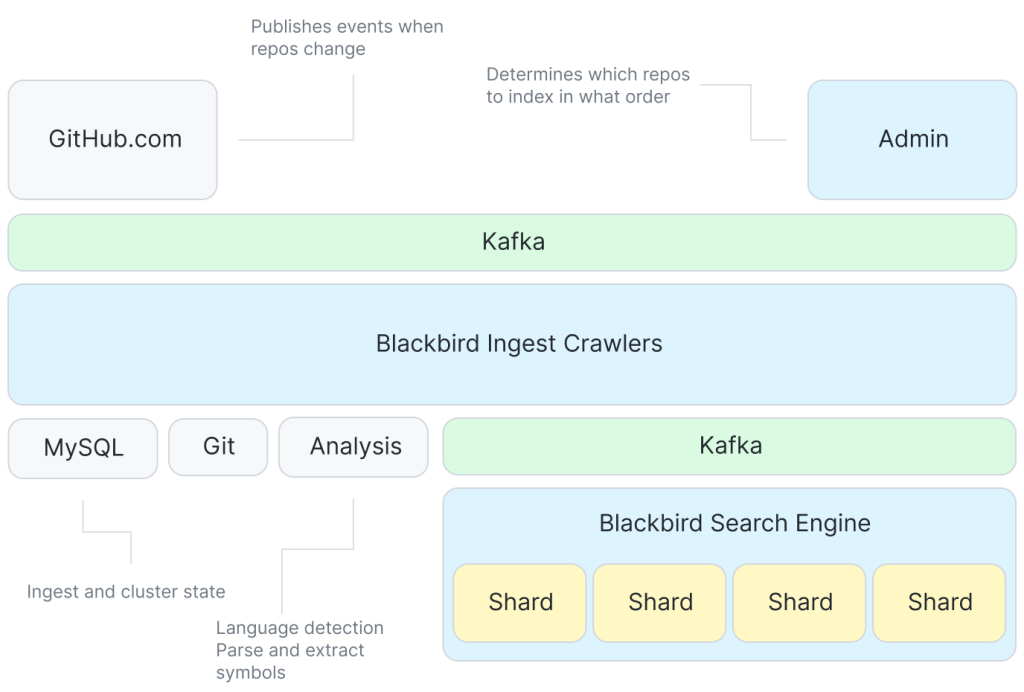
卡夫卡提供了一些事件,告诉我们去索引一些东西。有一群爬虫与Git交互,还有一个从代码中提取符号的服务,然后我们再次使用Kafka,允许每个碎片以自己的速度使用文档进行索引。
尽管系统通常只对以下事件做出响应git推送为了抓取更改的内容,我们需要做一些工作来首次接收所有存储库。该系统的一个关键特性是,我们优化了进行初始摄取的顺序,以充分利用增量编码。我们使用一种表示存储库相似性的新概率数据结构,并通过从最小生成树存储库相似性图的.
然后,使用我们优化的摄取顺序,通过将每个存储库与我们构建的增量树中的父存储库进行比较,对其进行爬网。这意味着我们只需要对该存储库(而不是整个存储库)特有的blob进行爬网。爬网包括从Git中获取blob内容,对其进行分析以提取符号,以及创建将作为索引输入的文档。
然后,这些文件被发布到另一个卡夫卡主题。这是我们划分的地方碎片之间的数据。每个碎片在主题中使用一个Kafka分区。通过使用Kafka,索引与爬行是解耦的,而Kafka中消息的排序是我们获得查询一致性的方法。
然后,索引器分片获取这些文档并构建其索引:标记化以构建ngram索引(用于内容、符号和路径)和其他有用的索引(语言、所有者、存储库等)。
最后,碎片会进行压缩,将较小的索引折叠成更大的索引,这样查询效率更高,移动更容易(例如,到读取副本或进行备份)。压实k-合并发布按分数列出,因此相关文档具有较低的ID,并将首先由惰性迭代器返回。在初始摄取期间,我们延迟了压缩,并在最后执行了一次大的运行,但随着索引跟上增量更改,我们以更短的间隔运行压缩,因为这是我们处理文档删除之类的事情的地方。
查询的生命周期
现在我们有了一个索引,在系统中跟踪查询很有趣。我们将遵循的查询是一个限定于Rails组织查找用Ruby编程语言编写的代码:/参数?/org:rails-lang:Ruby。查询路径的高级体系结构看起来有点像这样:
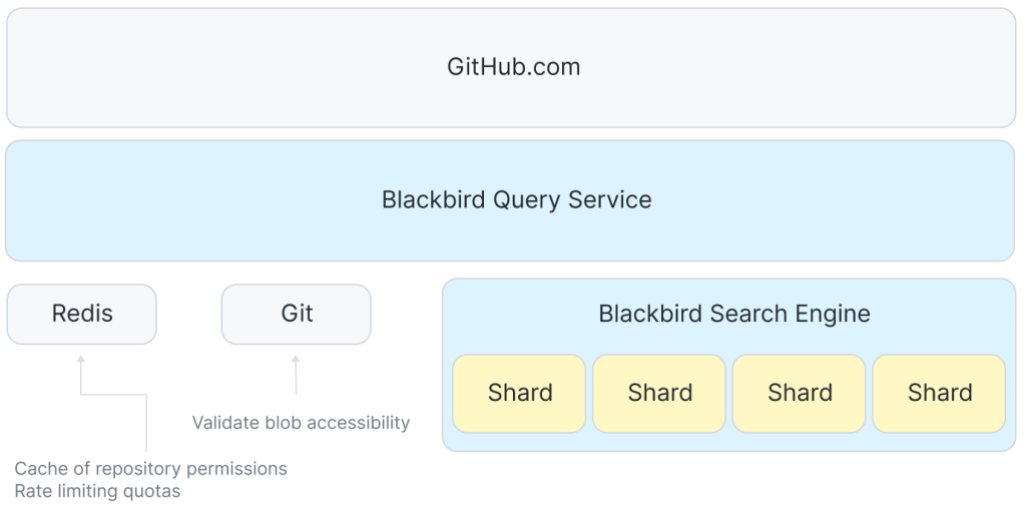
在GitHub.com和碎片之间是一个服务,它协调用户查询和向搜索集群中的每个主机扇出请求。我们使用Redis来管理配额和缓存一些访问控制数据。
前端接受用户查询并将其传递给Blackbird查询服务,在那里我们将查询解析为抽象语法树,然后重写它,将语言等内容解析为其规范语言学家语言ID和权限和作用域的额外子句上的标记。在这种情况下,您可以看到重写是如何确保我从公共存储库或我可以访问的任何私有存储库中获得结果的。
而且(业主(“轨道”),语言ID(326),Regex(“参数?”),或者(回购ID(…),PublicRepo(),),)
接下来,我们扇出并发送n个并发请求:搜索集群中的每个碎片一个。由于我们的分片策略,必须向集群中的每个分片发送查询请求。
然后,在每个单独的碎片上,我们进一步转换查询,以便在索引中查找信息。在这里,您可以看到regex被转换为ngram索引上的一系列子字符串查询。
和(owners_iter(“轨道”),languages_iter(326),或(和(content_grams_iter(“arg”),content_grams_ ter(“rgu”),content_grams_iter(“口香糖”),或(和(content_grams_iter(“ume”),content_grams_iter(“门”))content_grams_iter(“文档”),)),或(paths_grams_iter…)或(symbols_grams_iter…)), …)
如果您想了解有关将正则表达式转换为子字符串查询的方法的更多信息,请参阅Russ-Cox关于与三角索引匹配的正则表达式。我们使用不同的算法和动态克大小来代替三角图(见下文). 在这种情况下,发动机使用以下克数:参数,rgu公司,口香糖,然后要么乌梅和文件,或6克文书.
运行每个子句的迭代器:和表示相交,或指工会。结果是一个文档列表。在评分、排序和返回所需数量的结果之前,我们仍然需要对每个文档进行双重检查(以验证匹配并检测其范围)。
回到查询服务中,我们聚合所有碎片的结果,按分数重新排序,过滤(双重检查权限),并返回前100个。GitHub.com前端仍然需要进行语法高亮显示、术语高亮显示、分页,最后我们可以将结果呈现给页面。
单个碎片的p99响应时间约为100ms,但由于聚合响应、检查权限和语法高亮等原因,总响应时间稍长。一个查询将索引服务器上的一个CPU内核占用100毫秒,因此我们的64核主机每秒有大约640个查询。与grep方法(0.01QPS)相比,这一方法速度极快,同时为用户查询和未来增长提供了足够的空间。
总之
现在我们已经看到了完整的系统,让我们重新审视一下问题的规模。我们的接收管道每秒可以发布大约120000个文档,因此处理155亿个文档大约需要36个小时。但是,增量索引将我们必须爬行的文档数量减少了50%以上,这允许我们在大约18小时内重新索引整个语料库。
指数的规模也取得了一些重大胜利。请记住,我们首先要搜索115 TB的内容。内容重复数据消除和增量索引使其减少到约28 TB独特的内容。索引本身的时钟输入量只有25 TB,这不仅包括所有索引(包括ngram),还包括所有独特内容的压缩副本。这意味着包括内容在内的总索引大小大约是原始数据大小的四分之一!
如果你还没有报名,我们很乐意你报名加入我们的测试版并尝试新的代码搜索体验。让我们知道你的想法!我们正在积极添加更多存储库,并根据像您这样的人的反馈修复粗糙的边缘。
笔记



