总结
在许多复杂的多重测试问题中,假设被分为多个系列。根据这些数据,我们选择了具有真实发现证据的家族,并对其中的假设进行了测试。无论是单独控制每个系列的错误率,还是同时控制所有假设的错误率都无法确保对所选系列中错误过滤的一定程度的信心。我们对选择推理的一般性、一类非常广泛的错误率和任何选择标准提出了这种担忧,并提出了对选定族内部测试水平的调整,以保持对选定族的预期平均误差的控制。
1.简介
在现代统计学的挑战中,我们经常会遇到一组假设家族,这些假设家族可能很大。在功能磁共振成像中,研究对象参与某项认知任务时激活的位置(体素)。大脑被分为几个区域(解剖或功能),关于每个区域位置的假设定义了一个家族(例如,参见Pacifico等. (2004)本杰米尼和海勒(2007)). 为了寻找差异表达的基因,这些基因通常被划分成由先前生物学知识定义的基因集。每个基因集定义了一系列假设(参见Subramanian等. (2005)和海勒等. (2009)). 在这些例子中,家族是感兴趣的单元簇:体素或基因。另一个具有类似结构的问题可以在多因素方差分析中确定,其中每个因素的兴趣在于该因素水平之间的成对比较系列。在更复杂的情况下,一组假设可以以不同的方式划分为家族:这类研究的一个例子是voxelwise全基因组关联研究(参见Stein等. (2010))其中,在740名老年受试者中探讨了448293个单核苷酸多态性(SNP)与31622个体素体积变化(共448293×31622个假设)之间的关系。我们可以将此问题视为每个基因的家族,或每个体素的家族。本示例在第节中详细讨论7.
在许多这样的案例中,调查人员往往首先根据手头的数据选择有希望的家庭,然后只在选定的家庭中寻找重要的发现。为了避免在选定的族中出现错误发现,通常在每个选定族中分别应用多次测试程序。在方差分析中,通常首先选择重要因素,然后执行事后(post-hoc)使用Tukey程序对每个选定因素进行测试(成对比较)。这控制了在不受预选约束的单个成对比较族中应用时,出现至少一个错误发现的概率。
不幸的是,该策略并不能保证对所选系列中的错误过滤有任何信心。让我们用一个简单的例子来证明这一点。
1.1. 示例1
面对每10个假设的家庭,其中一些家庭都是无效的,其他家庭包括两个非无效的假设,研究人员只选择包含第页-该值低于Bonferroni阈值0.05/10,并拒绝家族中的所有此类假设。让我们进一步假设第页-值是独立的,并且第页-非零假设的值是均匀累积分布函数的平方根。显然,如果选择了全空族,则发生I类错误的概率为1;如果选择了一个非全零族,拒绝该族中一个或多个真零假设的条件概率仍然很高:0.23(有关推导,请参阅附录A). 为了直观地解释第页-比如说,真零假设的值低于阈值x个考虑到最小值第页-家庭价值,低于一,请注意
(1)
对于任何x个⩽一,其中不等式是严格的,如果根据此选择方案第页-选定族中null下的值随机小于区间[0上的一致值,一].
我们解决了一类错误率的选择性推理问题。当面临多重性时,以不同的方式量化错误发现的膨胀,这些错误率包括每个家庭的错误率E(V(V)),其中V(V)是I类错误的数量家庭错误率转发:,,的错误发现率财务总监=E类(FDP),其中FDP=V(V)/R(右)是所有发现中错误发现的比例R(右),如果没有发现,则定义为0(本杰米尼和霍克伯格,1995)错误发现超越对于一些预先指定的γ(见范德拉恩等. (2004)吉诺维塞和瓦瑟曼(2006))和广义错误率k-FWER,即。(见van der Laan等. (2004)莱曼和罗曼诺(2005))和k-财务总监(萨尔卡,2007). 虽然我们在这篇文章中强调了FDR和FWER,但它解决了所有上述错误率以及其他可以写为对执行的错误进行一些(随机)测量它没有解决贝叶斯FDR,FDR=E类(V(V))/E类(R(右))(Efron和Tibshirani,2002)和阳性FDR,pFDR=E类(V(V)/R(右)|R(右)>0)(楼层,2003)不能写为参见法科梅尼(2008)为了很好地回顾多错误标准,它们之间的关系和不同的多测试程序。
当只对选定的系列感兴趣时,我们可能希望确保对选定系列内的发现有一定程度的信心。一个自然的要求可能是控制某些误差度量的期望值在每个选定的族中我,即控制已选中)。我们已经通过示例1展示了,其中,在某些情况下,应用每个选定家庭中的控制程序分别导致选择)=1。一般来说,对于选择规则和测试程序的任何组合以及真实零假设的任何配置,这种条件控制的目标都很难实现。
我们提出了一个关于所选系列中错误的更适度的目标:控制超过挑选出来的族,如果未选择族,则平均值为0。在示例1中,其中的预期平均值在选定的族中,至少有一个错误拒绝的族所占的预期比例。
正式地,让是一套第页-家庭价值观我,我= 1,…,米,其中族是预先指定的。让P(P)是这些集合的集合:.让是一个选择过程,使用第页-值P(P),确定选定族的索引。定义,选定族的数量。我们感兴趣的错误标准是
(2)
什么时候?也就是说,当实际上没有选择并且所有系列都进行了测试时,
(3)
因此应用每个(选定的)家庭在级别上的控制程序q个担保。很容易看出,在不依赖用于测试的数据的情况下选择族也是如此。然而,如示例1所示,当选择取决于手头的数据时,可能会恶化。以下示例演示了选择范围如何影响选定族的预期平均误差度量。
1.2. 示例2
一个家族n个相应的假设第页-如果最小值为第页-其中的值小于0.05。通过使用Bonferroni程序对每个选定的家族进行水平测试α= 0.05. 进一步假设我们米这样的族,所有的零假设都是正确的(具有均匀分布的独立第页-值)。显然,平均值的期望值当对所有家庭取平均值时进行控制。平均值的期望值只接管选定的家族,即(以下为FWER平均值)见表1对于的各种值米和n个(有关推导,请参见附录B).
| 米 | n个 | | |
| 20 | 100 | 0.99 | 0.049 |
| 100 | 20 | 0.64 | 0.076 |
| 100 | 10 | 0.40 | 0.122 |
| 100 | 2 | 0.1 | 0.506 |
| 米 | n个 | | |
| 20 | 100 | 0.99 | 0.049 |
| 100 | 20 | 0.64 | 0.076 |
| 100 | 10 | 0.40 | 0.122 |
| 100 | 2 | 0.1 | 0.506 |
| 米 | n个 | | |
| 20 | 100 | 0.99 | 0.049 |
| 100 | 20 | 0.64 | 0.076 |
| 100 | 10 | 0.40 | 0.122 |
| 100 | 2 | 0.1 | 0.506 |
| 米 | n个 | | |
| 20 | 100 | 0.99 | 0.049 |
| 100 | 20 | 0.64 | 0.076 |
| 100 | 10 | 0.40 | 0.122 |
| 100 | 2 | 0.1 | 0.506 |
我们可以从表的最后一列立即观察到1在本例中,所选家庭的平均FWER可以攀升到0.5以上,而如果没有选择,则水平应为0.05。同样明显的是,当选择范围(如第三列所示)变得更加极端时,选定族的平均FWER会增加。注意,在本例中,平均FWER等于,其中平均PFER也观察到类似的结果(对于)而不是平均FWER。
本文的主要结果是,为了确保对,我们应该控制在每个选定的族中我更严格的水平:名义水平q个应乘以所选族在所有族中的比例。在某些限制条件下,这个结果是第节中定理1的重点三定理2中给出了相同性质的一般结果,包括更复杂的选择规则,例如使用插件估计器的多重比较过程。
2.选择性推理
对选定家庭的平均控制是Benjamini和Yekutieli发展出的选择性推理思想的一种表现(2005). 在选定参数的置信区间范围内,他们在对多个参数进行推理时,区分了同时目标和选择性目标。当需要控制至少一个置信区间不覆盖其参数的概率时,同步推断是相关的。因此,同步控件也适用于任何选定的子集。然而,当仅为一组选定参数建立置信区间时,目标不必那么严格,Benjamini和Yekutieli(2005)建议了一个更自由的属性:控制所选参数中未被其置信区间覆盖的参数的预期比例,如果未选择参数,则比例为0(错误覆盖率FCR)。为多个族的测试设定选择性推理目标并在方程中采用误差度量(2)因此类似于FCR的目标。因此,当前的工作可以被视为以两种方式概括选择性推理:
我们现在将详细讨论这两点。
我们首先说明了对假设家族的选择性推理和对个别假设的选择性推理之间的区别。如果我们获得多个假设家族,将这些假设家族的联合视为一个简单的假设巨家族,并对组合的发现集进行全局FDR控制,则是对组合的单个假设集进行选择性推理的表现。控制所选假设家族的预期平均FDP是对假设家族的选择性推理的表现。控制一方并不意味着控制另一方。
假设选择了40个假设家族。有36个家庭中每个家庭都有一个被拒绝的家庭,这些家庭中没有错误的发现。在剩下的四个家族中,每个家族都有10个被拒绝,其中五个是虚假发现。因此,在36个选定的族中,FDP=0,而在其余四个族中FDP=0.5。选定家庭的平均FDP为4×0.5/40=0.05。发现的总数是76个,其中20个是错误的发现。因此,组合发现集的FDP为20/76=0.26。因此,对选定系列的预期平均FDP的控制并不意味着对组合发现集的FDR的控制。
对综合发现集FDR的控制也不能保证对所选系列的预期平均FDP的控制。假设有20个选定的家庭,每个家庭都有一个错误和一个正确的拒绝,而在其他20个家庭中,每个家庭有18个拒绝,所有这些都是正确的。发现总数为400个,其中20个是错误发现。因此,综合发现集的FDP为20/400=0.05。然而,选定家庭的平均FDP为20×0.5/40=0.25。
我们现在将展示如何选择误差度量在选定的族中反映,对于以下两种最常见的选择.何时,此误差度量是所有选定族中至少有一个I类错误的族的预期比例。在这种情况下,它类似于Heller中定义的总错误发现率等. (2009)用于微阵列分析(参见第节5). 什么时候?,方程(2)中的误差度量变得不那么严格:它是所选族的预期平均FDP。平均FDP与至少有一个I类错误的家庭比例之间的差异可能非常大。如果选择三个家庭,错误发现比例分别为0.04、0.05和0.06,平均FDP为0.05,而至少有一种I类错误家庭的比例为1。这两种错误率之间的选择应以应用程序为指导。如果我们可以在选定的族中容忍一些错误的发现,只要选定族的平均FDP很小,那么对预期平均FDP的控制就足够了。或者,如果我们希望在选定的家族中避免一个错误发现,那么控制至少有一个I型错误的家族的预期比例是合适的。
在许多应用中,控制所选系列的预期平均误差测量值,与控制组合发现集的全局误差率相比,只是更适合于解释结果的误差测量,因为它对所选系列内的发现有一定的信心。第节中的应用程序说明了这一重要点7即使在没有选择的问题上,埃夫隆(2008)认为应该分别控制每个家庭的错误率,这意味着平均控制(所有家庭)。进行选择时,平均控制(对选定族的控制)变得更加重要。最后,在某些情况下,可以通过控制平均错误率而不是综合发现集的全球错误率来获得权力,尽管这并不是我们强调对所选系列进行平均控制的动机。
3.家庭选择调整测试
当以概率1选择所有系列时,不应对测试水平进行调整,因为所选系列的平均值是总体平均值。由于选择规则更加严格,往往选择较少的家庭,因此调整应该更加严格。我们从简单选择规则的调整开始,然后转向一般情况。
定义1
(简单选择规则)。对于每个选定的族,选择规则称为简单规则我,当第页-不属于家庭的价值观我是固定的,并且第页-族内的值我只要有家人就可以改变我则选定族的数量保持不变。
Benjamini和Yekutieli也定义了类似的概念(2005)在基于数据的参数选择上下文中。许多选择规则确实很简单。仅根据族自身选择族的任何规则第页-values是一个简单的选择规则,例如示例1中使用的规则。在节中5我们表明,当使用假设检验进行族的选择时,广泛使用的递增和递减多重检验程序提供了简单的选择规则,尽管是否选择族取决于第页-属于其他家族的价值观。
以下简单的选择调整程序(程序1)为族的简单选择规则提供选择调整。
定理1
对于任何错误率这样的话取可数集合中的值,假设我们有一个可以控制在任何期望的水平α在依赖结构下第页-家庭中的价值观。如果第页-每个家族的价值观都独立于第页-任何其他族中的值,然后针对任何简单选择规则选择调整程序保证.
备注1
出于所有实际目的是计数或计数比率,因此值上的条件takes表示满意。
备注2
选择效果的调整取决于选择的范围。随着选定家庭的比例越来越小,调整也越来越严格。当所有家族都被测试时,即实际上没有选择时,数量Rq(请求)/米等于q个得出不需要调整的结论,正如我们在第节中所示1这一调整背后的直觉与示例2的结果一致,我们在示例2中看到了这一点随着所选家庭的预期比例变小而增加。
3.1. 定理1的证明
证明的思想类似于Benjamini和Yekutieli中定理1的证明(2005). 对于每个错误标准,让得到了无数的支持。由于选择规则很简单,我们可以在所有第页-不属于家庭的价值观我:如果是家庭我被选中,k选择的族包括族我。通过表示此事件。对于任何简单的选择规则
(4)
请注意,简单的选择-调整程序不会拒绝任何未被选择的家庭的假设。因此每个家庭我未选中的。因此,对于此过程,我们获得
(5)
(6)
平等(5)源于和一套第页-不属于家庭的价值观我,每个我= 1,…,米在表达式(6)中,对于每个k和我,是随机变量的值在家里我,当有效控制程序应用于级别千卡/米在每个选定的族中。由于在未选择的家庭中没有拒绝,这里取0,所以对于每个我= 1,…,米现在,利用这个不等式和对于每个我= 1,…,米,我们获得
(7)
结果(6)和(7)完成了证明。
备注3
根据定理1的证明,我们实际上可以在每个族中使用不同的调整。给定重量,我=1,…,米,它不依赖手头的数据并满足我们可以申请水平控制程序在每个家庭中.如果有先验的知道某个家族比其他家族包含更多的假零假设,我们可以将这个家族与更高的权重联系起来然后,这个家庭的调整将比其他选定家庭的调整宽松,从而获得权力。
定理1给出了每个选定族中测试水平的调整,这足以控制我们现在将说明,在某些特殊情况下,这种调整是必要的,我们将改编本杰米尼和叶库蒂利的例子6(2005)满足我们的需求。
3.2. 示例3
假设所有测试的家庭规模相等n个,所有零假设均为真,所有第页-值是联合独立且均匀分布的。让我们按最少的数量来排列这些家庭第页-值。简单的选择规则是选择k最小的家庭第页-值。假设每个选定的系列都在水平上使用Bonferroni程序进行测试在这种情况下,选定系列的平均错误率为
至少有一次错误拒绝的家庭是最小的家庭第页-很容易看出,如果米/k不大于1(比如k= 3米/4) ,我们获得
和调整是确保.
备注4
示例3表明,在某些情况下,如果所有零假设都为真,则有必要在程序1的步骤2中调整测试水平。然而,当存在仅由假零假设组成的族时,可以对程序1进行改进。自在只包含假零假设的族中,方程中的第一个和(3)可以接管包含一个或多个真零假设的族的指数。因此,从定理1的证明可以得出,如果每个选定的家族都在水平上进行测试,则相同的结果成立哪里是仅包含假零假设的族数。可以考虑过程1的自适应版本,其中参数通过使用数据进行估计,然后在该过程的步骤2插入测试水平。然而,我们认为在大多数应用中; 因此,这一改进并不显著。
并非所有的选择规则都很简单:如第节所述,示例是自适应多重测试程序5仍然是一个非常类似的程序,即选择调整程序(程序2),即使有点复杂,也可以为任何选择规则提供选择调整。当选择规则很简单时,此过程简化为过程1。
定理2
对于任何错误率这样的话取可数集合中的值,假设我们有一个可以控制在任何期望的水平α在依赖结构下第页-家庭中的价值观。如果第页-每个家族的价值观都独立于第页-任何其他族中的值,然后针对任何选择规则选择调整程序保证.
证据见附录C.
备注5
我们可以通过将此要求明确添加到选择规则中来保证每个选定的族中至少有一个被拒绝:“选择最大数量的族,以便在水平应用选择性推理调整时,所有选定的族都会被拒绝q个’. 有趣的是,当每个家族仅由一个假设组成时,所选家族中的每个假设都会被拒绝α如果是第页-值小于α,选择调整后的程序相当于Benjamini和Hochberg的程序(1995)(BH程序)应用于第页-值。
4.家庭平均控制依赖性
我们现在考虑这样的情况第页-值是正回归,取决于真零假设的子集(PRDS),定义如下。
首先回忆一下D类在里面是增加还是减少,如果x个∈D类和分别年⩾x个或年⩽x个意味着年∈D类.
定义2
(本杰米尼和叶库蒂利,2001). 向量XPRDS是否打开如果,对于任何增加集D类以及每个,在中非递减x个.
此外,我们要求选择规则是一致的,如Benjamini和Yekutieli中所定义的(2005).
定义3
(本杰米尼和叶库蒂利,2005). 选择规则是一致的,如果我= 1,…,米和k=1,…,米,是一个递减集。
很容易看出,许多选择规则是一致的。两者都选择其最小值的每个族第页-值小于q个并选择k最小值的族第页-值是一致的选择规则。当通过假设测试进行选择时,任何升压或降压程序都是一致的。
定理3
如果所有第页-值是PRDS的子集第页-与真零假设相对应的值,选择规则是一致的,用于测试每个选定家族的程序是
则选择调整后的程序保证了情况(a)
以及情况(b)
证据见附录D.
5.通过多重假设检验选择家庭
正如在实践中经常遇到的那样,选定的家庭可能会被视为科学发现,因此,适当的做法是解决家庭的错误选择,并控制选择过程中的一些错误率。海勒也是等. (2009)用于选择微阵列分析中的基因集以及Sun和Wei(2011)用于分析时间进程实验。然后,我们可以将每个家族与其全局零(交集)假设联系起来,即我们在该家族中所观察到的全部都是纯噪声,并结合了家族内部第页-值来构造有效的第页-此交叉假设的值。(参见Loughin(2004)以系统比较可用于此目的的组合函数。)对这些组合使用多重测试程序第页-价值观,并相应地选择家庭,是一种自然的方法。
多重测试程序的选择应以我们希望在系列级别控制的错误率和组合测试程序之间的依赖性为指导第页-值。例如,为了在家族层面上实现对FDR的控制(即所选家族中所有空家族的预期比例),我们可以对组合第页-值,如果组合第页-值是组合的子集上的PRDS第页-对应于全空族的值。对于在同一依赖结构下的族水平上的FWER控制(即控制选择一个或多个全零族的概率),我们可以使用Hochberg程序,或者如果依赖性更一般,则返回Bonferroni程序。也可以使用其他测试程序:任何升压或降压程序都定义了一个简单的选择规则(参见附录E)并可用于步骤1。对于其他程序,例如自适应FDR-和FWER程序(Benjamini和Hochberg,2000; 故事等.,2004; 本杰米尼等.,2006; 布兰查德和罗奎恩,2009; 萨卡等.,2012)这不是简单的步骤2。
在某些情况下,平均控制通过选择调整程序,可以在家族层面控制FDR,从而不仅可以控制每个家族内部的错误发现,还可以控制家族选择的第一阶段。当选择规则和测试程序使每个选定的系列中至少有一个被拒绝,并且错误度量时,就会发生这种情况在全空系列中进行一次或多次拒绝时(例如错误率为FWER、FDX或FDR)。要看到这一点,请注意,如果是全空族的索引集是包含一个或多个假零假设的族的指数集,
从上述条件可以看出,对于每个,; 因此
这是罗斯福在家族层面上的表现。因此,如果保证在每个选定的系列中至少进行一次拒绝,并且用于测试选定系列的程序是FWER、FDR或FDX控制程序在第一个定理1的条件下,在第二个定理2和3的条件下。
我们现在将说明,对于程序1步骤2中使用的任何测试程序集合,我们都可以找到一个选择规则,确保每个选定的系列中至少有一个被拒绝。为了那个出租最小调整值第页-家庭内的价值我,根据用于控制对于我= 1,…,米。选择其中的族哪里R(右)是选定族的数量。很容易看出,在最小调整值集上应用BH程序第页-值,并选择调整最小值的家庭第页-值被拒绝定义了一个满足上述属性的选择规则,附加条件是R(右)被选中。因此,我们建议在最小调整值集上使用BH程序第页-值作为过程1的步骤1中的选择规则。
海勒等. (2009)解决了微阵列分析中跨假设家族推断的类似问题。他们首先选择有希望的基因集,然后在这些基因集中寻找差异表达的基因。他们定义了一个集合的错误发现,如果一个集合被选择,而该集合中没有基因被差异表达,或者如果它被适当地选择,但该集合中的一个基因被错误地发现。他们将总体错误发现率标准定义为所有选定基因集中“错误”发现基因集的预期比例。该误差标准相当于对于当用于测试所选家族的选择标准和程序确保每个家族(基因集)至少发生一次排斥反应时。这一条件并不总是满足的。例如,当家族中的信号较弱时,可能会看到证据表明该家族中至少有一个信号,但无法指出该信号的位置。在这些情况下,我们的标准与总体错误发现率不一致。要查看它,假设选择了一个全空族,并且该族中没有拒绝。这个家庭对然而,正如海勒所定义的那样,这将对所有选定基因集中错误发现基因集的比例产生影响等. (2009).
在海勒等. (2009)问题决定了将假设划分为系列。在许多应用中,每个假设都带有两个“标签”,即假设具有双向结构,在这种结构中,可以通过沿任一维度合并来构建家庭。在这些情况下,研究人员应该通过最重要的推理维度来定义家庭。在节中7我们展示了这样一个应用程序的示例。
6.解决建议方法的威力
在这项工作中,我们重点关注错误标准并表明它可能是应用中的相关误差度量。尽管我们的目标不是获得权力,并且比较控制不同错误率的程序的权力总是有问题的,但我们想概述与控制预期平均FDP的方法和应用于控制FDR的组合假设集的BH程序之间的这种比较相关的问题。
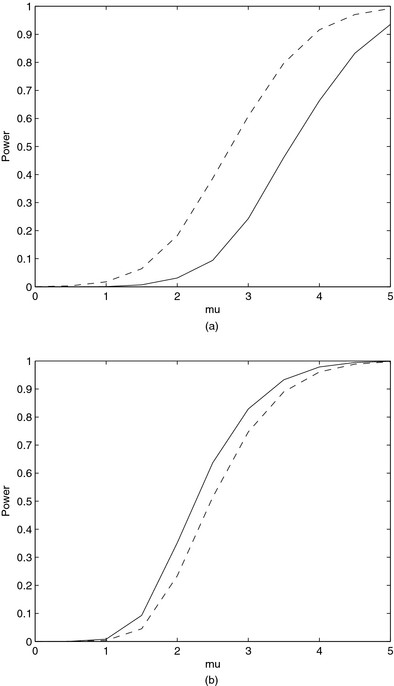
我们将BH程序应用于组合假设集(组合BH程序)的威力与程序1的威力进行了比较,其中组合第页-值是使用Simes方法构造的,BH程序利用了这些第页-值是选择规则,BH程序用于测试每个系列中的假设(表示为(BH−q个,制动马力-Rq(请求)/米)程序)。在模拟中,测试统计数据是正态分布的,标准偏差为1,真零假设的平均值为0,共同平均值为μ>0表示假零假设。在图中。1我们将估计的平均功率表示为替代假设下共同期望的函数。我们证明了两种情况下的功效:1、九个包含100个假设的全零族和一个包含5个假设的族,其中所有的零假设都是假的;2、5个5级全零家族,以及5个包含100个假设的家族,其中一半的假设是错误的。
图1
程序1的估计平均功率,其中在Simes上使用0.05级的BH程序选择系列第页-族交集假设的值,并使用BH程序在水平上测试选定的族R(右)/米×005,其中R(右)/米是选定家庭的比例( ),以及在005级应用于以下组合集的BH过程的估计平均功率第页-值(
),以及在005级应用于以下组合集的BH过程的估计平均功率第页-值( ):(a)设置1,九个包含100个假设的全零家族和一个包含5个假设的家族,其中所有的零假设都是假的;(b) 设置2,五个大小为5的全空家族和五个包含100个假设的家族,其中一半的假设是错误的
):(a)设置1,九个包含100个假设的全零家族和一个包含5个假设的家族,其中所有的零假设都是假的;(b) 设置2,五个大小为5的全空家族和五个包含100个假设的家族,其中一半的假设是错误的
在设置1中,(BH−q个,BH−型Rq(请求)/米)程序高于组合BH程序的功率;参见图。1(a) 。在设置2中,(BH−q个,BH−型Rq(请求)/米)程序低于组合BH程序的功率;参见图。1(b) ●●●●。我们证明,我们可以通过控制预期的平均FDP而不是总体FDR来获得或失去权力。当家族内部存在同质性时,即每个家族要么几乎只由真零假设组成,要么几乎只包含假零假设,并且大多数假零假设都聚集在小家族中,权力就会增加。
7.单核苷酸多态性与脑容量的关联
我们希望通过使用Stein的研究来展示我们的方法与体丝全基因组关联研究的相关性等. (2010)如第节所述1。我们首先概述了他们进行的分析,并试图理解他们在陈述和讨论结果的方式中反映出的担忧。鉴于这种理解,我们建议使用本文中提出的方法。不用说,由于本文提出的方法是新颖的,我们绝不批评原始分析:它提出了一个非常合理的计算折衷方案,同时尝试使用当时可用的工具解决选择性推理问题。
7.1. Stein等人的分析(2010)
斯坦因等. (2010)研究了740名老年受试者(包括阿尔茨海默病患者、轻度认知障碍患者和阿尔茨海默氏病神经成像计划健康老年对照组)的448293个SNP和31622个体素之间的关系。感兴趣的表型是每个体素相对于样本特异性模板的体积差异百分比,在每个SNP进行回归,以表型为因变量,次要等位基因数量、年龄和性别为自变量(假设为加性遗传模型)。在对每个体素的原始分析中,仅保留了最显著相关的SNP以供进一步使用。它第页-当并没有SNP和该体素关联时,调整该值以获得均匀分布。BH程序适用于此类调整第页-值。在0.05水平上未发现显著的SNP。在0.5水平上仅发现两个SNP。斯坦因等. (2010)我们仍然对最重要的五个SNP感兴趣,并对每一个SNP关联度最高的体素进行了映射。
7.2. 使用平均控制进行分析
根据Stein的结果介绍等. (2010)他们希望找到与大脑中某些区域相关的SNP,然后能够根据每个选定的SNP绘制这些区域的地图。采用这个目标,我们将每个家族定义为所有体素和特定SNP之间的一组关联假设。这样,族的选择将等同于选择具有至少一个非空关联的SNP,然后可以搜索与所选SNP关联的体素。
下一个实际问题是在这个问题中应该控制什么错误率?很明显,研究人员不希望强调发现关联的每个体素-SNP对;因此,无需在发现的所有对的组合集上控制全局错误率。重点是选定的SNP和大脑中可能受这些SNP影响的区域。因此,这是合理的
跨系列测试程序的选择应以所选SNP的期望错误率为指导(参见第节5). 由于建议对选定的SNP进行进一步研究,因此在SNP水平上进行FDR控制似乎是合适的。定理1和2提供在选定SNP上平均控制错误识别的体素的方法。根据这些定理,磁共振成像研究中任何常用的方法都可以在调整后的水平上分别应用于每个选定SNP的体素:重采样或随机场理论FWER控制方法,用所有选定SNP中至少一个错误发现的体素来控制预期数量的SNP,或BH FDR控制程序,用于控制选定SNP上错误发现的体素的预期平均比例。定理1和2然而,假设SNP之间具有独立性。定理3表明,如果对每个选定的SNP在调整后的水平上跨体素应用BH过程,则在某种类型的正相关性(PRDS)下,结果仍然正确。由于可以合理假设体素之间和SNP之间的正相关性第页-价值观似乎是合理的。
鉴于此讨论,我们建议采用以下方法。
- 第1步
:对于每个SNP,计算第页-SNP和每个体素体积之间的关联值,控制年龄和性别。
- 步骤2
:通过组合所有31622来计算每个SNP的交集假设第页-通过使用交叉假设的Simes检验计算出该SNP在第1阶段的值。
- 步骤3
:使用BH程序在0.05级使用第页-第2阶段计算的值。让R(右)是被拒绝的交叉假设的数量。
- 步骤4
:选择R(右)交叉假设在第3阶段被拒绝的SNP。对于每个选定的SNP,在级别上应用BH程序R(右)所有31622上的×0.05/448293第页-第1阶段计算的值。
假设所有第页-根据Benjamini和Heller的模拟研究,我们预计第1-3阶段将保证在SNP家族水平上进行FDR控制(2008)关于BH程序在Simes公司的应用第页-正相关性下的值。此外,根据定理3,我们得到了阶段1-4保证了对所选SNP的期望平均错误发现比例的控制。
最初的分析也可以用我们目前的观点来描述:每个家族都被体素标记——每个SNP与特定体素关联的假设——校正后的第页-每个体素的值是第页-检验家庭交集假设的价值。如果在每个选定的体素中继续测试并适当校准,我们可以获得对选定体素的平均控制。因此,应报告选定的体素,每个体素都有其相关的SNP。在这项研究中,有一个明显的偏好,即用SNP标记家庭,这是Stein等. (2010)选择展示他们的结果。在其他涉及不止一种划分族的方法的情况下,根据所需的解释,可能有理由选择任何一种分析模式。
7.3. 结果
这个第页-使用Plink程序计算第1阶段的值。鉴于Stein等. (2010)计算出最小值第页-每个体素的值,结果为31622第页-值,我们必须计算所有31622×448293≈140亿第页-值。因为不可能保留所有第页-值,大于0.1的值被丢弃,但考虑到它们被检查的事实:使用它们的值时,就像它们被增加到1一样。在第2阶段第页-交叉假设的值计算如下。假设k是的数字第页-对于一些SNP小于0.1的值。然后我们计算,其中是j个第十大第页-家庭价值我。此值始终大于或等于Simes的第页-值,相当于将大于1的值替换为1,从而生成有效的第页-交叉假设的值。在此基础上应用步骤3和步骤4第页-值时,我们获得的结果与使用原始Simes时的结果相同第页-值,因为假设第页-BH程序不得在0.05级拒绝大于0.1的值。
在第3阶段选择的SNP数量为11个。对于每个选定的SNP,通过在第页-值测试该SNP与每个体素在级别上的关联对于一个SNP,发现197个体素相关,而对于其他10个,发现相关的体素少于57个。总体中位数为12个体素,其中最小的三个区域分别包含两个体素。我们打算与参与原始分析的生物团队合作,调查结果的生物学意义。
我们强调,在这一新的分析中,我们的目标不是获得权力。在SNP水平和所选SNP内的体素水平上控制的错误率确保了结果的生物学意义(以生物学家感兴趣的方式)是有效的。
我们可以使用这些结果来证明对选定错误率的平均控制和对错误率的总体控制之间的差异,我们认为总体FDR并不能对结果提供有意义的解释。我们发现了11个区域,其中最大的区域由197个体素组成,三个最小的区域各由两个体素组成。假设发现了三个错误的关联。如果这些错误出现在包含197个体素的区域中,而不是出现在包含两个体素每个区域都有一个错误的情况下,我们将对发现的区域的结构更有信心。在后一种情况下,我们对11个地区中的3个地区的信心很低,而在第一种情况下我们对所有发现的地区都有很高的信心。这种差异反映在我们使用的误差度量中:当三个误差位于较大区域时,平均FDP为而当包含两个体素的每个区域有一个误差时,平均FDP要高得多:0.5×3/11=0.136。然而,这两种情况之间的差异并没有反映在总体FDP中:这两种情形都低于0.015。
8.讨论
很少有作品(海勒之外等. (2009)这在第节中进行了讨论5)这正式解决了跨家族推理的问题。我们提到了埃夫隆(2008)在第节中2。处理这个问题的其他工作是胡等. (2010)孙和伟(2011). 这两个问题都没有解决在选择性推理框架内对多个假设家族的测试,这是我们工作中关注的问题。单独测试每个家族,同时关注每个被测试家族中的一些错误率控制,有一个明显的优势,即控制是在家族之间平均实现的。然而,一旦根据相同的数据仅选择了一些族,并且仅对选定的族进行推断或报告,即使是跨族的简单平均错误率也会恶化。在本文中,我们指出了这一危险,制定了它,并提供了简单的解决方法,即使不是最佳的解决方法。在备注4中,我们提到了通过估计仅包含虚假零假设的家庭数量来改进程序1的能力。程序1的优点在于,它提供了一种足以控制用于所使用的任何选择规则。研究人员甚至可能不知道这些家庭是如何被选中的;所需信息仅是所选族的数量以及选择规则简单的事实。然而,对于给定的特定选择规则,可能会有一个不那么严格的调整来控制
有时,面临的情况需要更严格的控制。当利益在于确保同时控制各个家庭的错误率,而不仅仅是选定家庭的平均错误率时,情况就是这样。对选定族中推理同时性的关注可以通过以下公式表达例如,在案例中这是至少一个家族中错误发现比例大于γ。很容易看出控制在水平面q个/米在里面每个家庭保证控制这个错误标准。然而,在当前复杂的应用程序中,兴趣很少集中在所有系列中,而是集中在有前途的系列中。因此,我们在这项工作中只涉及选择性目标。
有时,在选定的家庭中可能没有拒绝。例如,当家族中的信号较弱时,可能有足够的证据证明这个家族中至少有一个信号,但不可能指出信号在哪里。一些调查人员可能会声称,在这种情况下,对结果的解释是不直观的;因此,他们希望在每个选定的家庭中至少有一次被拒绝。我们表明,对于家庭中使用的任何测试程序,在最小调整值上使用BH程序时第页-选择族的值,然后根据选择进行调整,可以保证在每个选定的族中至少进行一次拒绝。
仅测试选定系列的框架与Yekutieli开发的分层测试框架类似等. (2006),他以以下方式定义了假设树的分层测试:
叶库铁利等. (2006)在假设树上定义了不同的FDR类型。每种FDR类型实际上是限制在研究人员感兴趣的一组假设中的错误发现率。
叶库铁利(2008)证明了,当所有第页-树的值是联合独立的,这是一种分层测试程序,其中每个家族都在某个级别上使用BH程序进行测试在级别上控制完整树和外部节点FDRq个但并不总是控制水平我罗斯福。
从这个层次结构的观点来看,我们的结构是一个两级树,其中每个家族的父假设是其交集假设,而第二级FDR是家族内所有发现的全局FDR。然而,这两种方法之间有两个主要区别。
在本文中,我们主要讨论了控制所选家族的预期平均误差度量的目标。其他类型的错误标准也可能相关。研究人员可能希望控制所有家庭的合并发现集的错误率。这似乎是埃夫隆唯一关心的问题(2008)和胡等. (2010). 如果选定的家族被认为是科学发现,这是在大型测试问题中经常遇到的情况,那么适当的做法是解决家族的错误选择,并控制选择过程中的一些错误率,例如海勒建议的那样等. (2009)在微阵列分析和孙伟的背景下(2011)在时间进程实验的背景下。研究人员可能对多种错误度量感兴趣。例如,人们可能希望控制每个基因集内的FDR,平均控制选定的基因集,全局控制所有基因集内发现的基因集合。因此,一个有趣的研究方向可能是开发同时控制研究人员感兴趣的几个错误度量的程序。
致谢
我们感谢Stein博士和Thompson教授为我们提供了SNP研究的预处理数据,感谢Jonathan Rosenblatt解决了由于测试了大量假设而导致的计算难题。导致这些结果的研究得到了欧洲研究委员会(EC-EP7)欧洲研究委员会拨款PSARPS-297519和美国国防部拨款W81XWH-11-2-008的资助。
工具书类
附录A:示例1的条件概率计算
我们考虑一个族,其中八个假设是一致的真零假设第页-值和两个假设是假零假设,每个都有一个第页-其累积分布函数是均匀累积分布函数平方根的值。在不失一般性的情况下,让和成为第页-与假零假设相对应的值,以及成为第页-对应于真零假设的值。让做最小的第页-家庭价值和出租V(V)是族中I类错误的数量。那么,族内至少存在一个I类错误的条件概率为
附录B:E(C)的公式S公司)在示例2中
在示例2中是
(9)
证明如下。在这种情况下
家庭我如果是最小值,则选择第页-值小于q个.每个选定的家庭都要使用Bonferroni程序在水平上进行测试q个.由于所有的零假设都是正确的,因此在家庭中至少存在一个I类错误我如果是最小值第页-值小于q个/n个因此,如果对Bonferroni进行测试,则选择至少出现一个I类错误的每个系列。现在我们获得
让我们定义随机变量很容易看出
(10)
使用Benjamini引理1的证明等. (2006)我们获得
(11)
代入方程(11)在方程式中(10)我们得到了公式(9).
附录C:定理证明2
对于每个错误标准,让是随机变量的支持如本杰米尼和叶库蒂利(2005),我们定义了以下一系列事件:
(12)
根据的定义(见方程式(13)在第节中三),对于的每个值和,使得,因此,
(13)
表达式(13)与定理1证明中的表达式(4)相同,但这里不同。在定理1的证明中,我们只使用事件在空间上定义而且,对于每个我= 1,…,米,对于表达式(12)中定义的一系列事件,这些事实仍然成立。因此,在获得方程后,定理1的证明中使用的论点(4)可以在此处应用。
附录D:定理证明3
定理3的证明使用了Benjamini和Yekutieli开发的技术(2001,2005). 案例(b)中的证据比案例(a)中的要复杂得多。
第1条。案例证明(a)
对于每个我= 1,…,米,让是家庭中假设的数量我和是家庭中真零假设的数量我.让和,假设和第页-家庭价值观我,我= 1,…,米.我们将使用一系列事件,定义于附录C,表达式(12)。
我们将证明
(14)
(15)
(16)
不等式(14)是通过去掉条件得到的.不平等(15)是真的,因为第页-与真零假设相对应的值具有统一(或随机更大)的分布。我们现在将证明,对于任何我= 1,…,米和,
(17)
由于选择规则是一致的,可以写为,是一个递增集。的子集上的PRDS属性第页-与真零假设相对应的值意味着,对于任何我= 1,…,米和,
对于任何现在,我们为任何k= 1,…,米−1
(18)
重复应用不等式(18)k= 1,…,米−1,并利用以下事实,我们获得
(19)
使用表达式(16)和(19),我们得到
D.2。案例证明(b)
让是一套第页-与族对应的值我.对于每个,让表示剩余的一组第页-下降后的值。让我们定义以下一系列事件的范围.适用于家庭我,让表示事件,如果被BH程序拒绝千卡/米,假设(包括)和它一起被拒绝。我们将再次使用这一系列事件,定义于附录C,表达式(12)。利用以下事实第页-与真零假设相对应的值具有统一(或随机更大)的分布,我们得到
现在事实是将情况(b)简化为不等式
(20)
哪里我=1,…,米和.
对于每个我= 1,…,米和,让我们定义组
显然,是一个有限集。请注意
因此,不等式(20)可以写成
(21)
对于每个家庭我及其假设,我= 1,…,米,,让我们定义
证明不等式(21)的关键陈述是以下命题。
提议1
对于任何,我= 1,…,米,,我们有不平等
(22)
我们证明了这个命题意味着不等式(21)。请注意
现在,不等式(22)的一个后续应用导致不平等
这意味着不平等(21)。
D.2.1、。命题1的证明
我们证明了这一点是一个递增集。让
和
哪里是的有序集第页-范围内的值很容易看出
显然,两者都是和正在增加集合。增加集的并集和交集也是增加集;因此是一个递增集。的子集上的PRDS属性第页-对应于真零假设的值意味着,对于每一个我= 1,…,米,以及任何,
(23)
很明显,对于,套和是不相交的。因此,对于,和也是不相交的。现在我们为任何α
(24)
使用表达式(23)和(24),我们可以得到,对于任何,
命题1如下。
附录E:证明升压和降压程序定义了简单的选择规则
让是给定过程的临界值。让是某种被拒绝的假设是它的第页-价值。我们需要证明,当所有第页-值,不包括是固定的,并且只要更改如果被拒绝,则拒绝的总数保持不变。
假设这是一个升级过程。让是的有序集合第页-值,不包括.如果,拒绝数量为k对于任何值这保证了被拒绝,即。.
现在假设这是一个逐步下降的过程。让是的有序集合第页-值。假设拒绝次数为k也就是说.自被拒绝,对一些人来说j个⩽k.让我们修复所有第页-值,不包括并更改的值以便仍被拒绝。假设是的有序序列第页-值后面的值已更改。现在和,自被拒绝,对于每个.如果很明显,拒绝数量保持不变。我们现在将分别处理两个案例:和.
- (a)
假设.然后; 因此,仍需证明对于和。请注意对于。对于秒>j个,; 因此,现在很明显,被拒人数保持不变。
- (b)
假设。我们现在将展示.假设注意,对于每个,特别是,,反驳了.在我们证明了这一点之后,结果立即出现,因为对于.
©2013皇家统计学会







{kind=link}