总结
我们提出了一种用于二元平滑的快速惩罚样条方法。单变量P(P)-样条曲线平滑器沿两个坐标同时应用。新的平滑器有一个三明治形状,向裁判建议“三明治平滑器”的名称。三明治平滑器具有张量积结构,简化了渐近分析,并且可以快速计算。通过证明三明治平滑器渐近等价于具有乘积核的二元核回归估计量,我们导出了三明治平滑器的局部中心极限定理,并给出了渐近偏差和方差的简单表达式。据我们所知,这是任何类型的二元样条估计量的第一个中心极限定理。我们的仿真研究表明,即使使用快速广义线性阵列模型算法计算二元样条平滑器,三明治平滑器的计算速度也比其他二元样条平滑器快几个数量级,并且在平均积分平方误差方面与之相当。我们将三明治平滑器扩展到更高维的阵列数据,其中广义线性阵列模型算法提高了三明治平滑器的计算速度。三明治平滑器的一个重要应用是在函数数据分析中估计协方差函数。在这个应用中,我们的数值结果表明,三明治平滑器比局部线性回归快几个数量级。三明治公式的速度很重要,因为函数数据集变得相当大。
1.简介
本文介绍了一种用于二元平滑的快速惩罚样条方法。给出了二元样条光滑器的第一个局部中心极限定理。假设有一个回归函数μ(x个,z)带有。最初我们假设,其中s独立于和和设计要点具有确定性;因此,数据点的总数为数据位于矩形网格上。第节4我们将设计假设放宽到固定的设计点而不是规则网格和随机设计点。使用矩形网格上的数据,可以将其组织为矩阵Y(Y)。我们建议在Y(Y)所以拟合值矩阵满足
哪里和是更平滑的矩阵x个和z分别是。所以,固定一个协变量,我们沿着另一个协变数平滑,反之亦然,尽管这两个平滑是同时的,正如方程所示(1).估价师(1)在形式上类似于协方差矩阵的三明治公式,它向裁判建议了“三明治平滑器”的名称。我们采用了这个术语。
三明治平滑器的张量积结构允许快速计算,特别是选择平滑参数的广义交叉验证(GCV)标准;参见第节2.2Dierckx公司(1982)提出了一种与估计器结构相同的平滑器(1),但我们的渐近分析和三明治平滑器的快速实现是新的。为了平滑二维直方图,Eilers和Goeman(2004)研究了一种简化的三明治平滑器,它具有特殊的平滑器矩阵,可以为非负数据提供非负平滑器。三明治平滑器的快速方法可以应用于他们的方法。
对于二元样条平滑,有两个著名的估计量:二元P(P)-样条曲线(Eilers和Marx,2003; 马克思和艾勒斯,2005)和薄板样条,例如薄板回归样条(Wood,2003). 为了方便起见,Eilers–Marx和Wood估计值将分别用E–M和TPRS表示。我们使用E–M,没有说明如何计算估计器。
惩罚样条曲线近年来越来越受欢迎,因为它们使用的节点更少,在更高的维度上比平滑样条曲线或薄板样条曲线需要更少的计算。参见Ruppert等. (2003)或木材(2006)用于方法开发和应用。然而,缺陷样条的理论研究一直是一个挑战。最近才实现了对单变量惩罚样条函数的渐近研究(Hall和Opsomer,2005; Li和Ruppert,2008; 克莱斯肯斯等.,2009; 考尔曼等.,2009; 王等.,2011). 相比之下,光滑样条的渐近收敛速度已经得到了很好的确定;见顾(2002)以获取全面的参考列表。
高维惩罚样条函数的理论研究更具挑战性。据我们所知,文献中不包含中心极限定理或渐近平均和协方差矩阵的显式表达式对于任何类型的二元样条估计。三明治平滑器具有简化渐近分析的张量积结构,我们证明了三明治平滑器与具有乘积核的核估计量渐近等价。利用这个结果,我们得到了三明治平滑器的中心极限定理以及渐近偏差和方差的简单表达式。
为了平滑阵列数据,Currie的广义线性阵列模型(GLAM)等. (2006)利用模型矩阵和数据的数组结构,给出了一种低存储、高速的算法。E-M估计器可以用GLAM算法实现(用E-M-GLAM表示)。三明治平滑器还可以扩展到任意维的数组数据,其中GLAM算法可以提高三明治平滑器的速度;参见第节7.由于章节中的快速方法2.2对于计算GCV标准,GLAM算法用于计算夹层时比用于计算E–M估计器时更快。在第5节表2中。2,我们看到,在广泛的样本大小和节数范围内,三明治平滑器比E–M–GLAM估计器快许多数量级。
本文的其余部分组织如下。在节中2,我们提供了关于三明治平滑器的详细信息。在节中三通过证明三明治平滑器与具有乘积核的二元核估计量的渐近等价,我们建立了三明治平滑器的渐近理论。在节中4,我们考虑不规则间隔的数据。在节中5,我们报告了一项模拟研究。在节中6为了估计函数数据的协方差函数,我们比较了三明治平滑器和局部线性平滑器。我们发现三明治平滑器比局部线性平滑器快许多数量级,并且它们具有相似的平均积分平方误差(MISE)。在节中7,我们将三明治平滑地扩展到维数大于2的数组数据。
用于分析数据的程序可以从http://www.blackwellpublishing.com/rss
2.三明治更光滑
让vec是将矩阵的列堆叠成向量的操作。定义年=vec(Y(Y))和应用张量乘积的一个众所周知的恒等式(Seber(2007),第240页)发送给估计器(1)给予
身份(2)证明了整体光滑矩阵是两个单变量光滑矩阵的张量积。由于平滑矩阵的分解,我们说我们的模型具有张量积结构。我们将使用P(P)-样条曲线(Eilers和Marx,1996)构造单变量平滑矩阵,即。
哪里和是的模型矩阵x个和z使用B-样条基(稍后定义),以及和是差分阶的差分矩阵和分别是。然后,可以使用张量积的恒等式(Seber(2007),第235-239页),
第二等式中的逆矩阵(4)显示了我们的模型使用带有惩罚的张量积样条(稍后定义)
关于系数矩阵。二元张量积样条(Dierckx(1995),第2章)的定义
哪里和是B-样条基函数x个和z分别是,和是一元样条函数的基函数数是系数矩阵。我们使用B-度的样条曲线和对于x个和z分别和使用和分别为等距内部节点。然后和。因此,模型为
哪里,和ε是一个矩阵,带有(我,j个)第个条目.让θ=vec(Θ). 然后估计θ通过最小化给出,其中规范是Frobenius规范P(P)在方程式中定义(5)因此,系数矩阵的估计满足,其中,对于我= 1,2,或者,同等地,满足
那么我们受到惩罚的估计是
使用等式(5),很容易证明满足方程(1)这证实了所提出的方法使用具有特定惩罚的张量积样条。
2.1. 与E-M估计值的比较
三明治平滑器和E–M估计器之间的唯一区别(Eilers和Marx,2003; 马克思和艾勒斯,2005)就是惩罚。让表示E–M估计量的惩罚矩阵;然后.二元第一、二罚项P(P)-样条线惩罚Θ分别被称为列惩罚和行惩罚。可以看出,方程中的第一个惩罚项(5),,比如,是“列”惩罚,但它惩罚而不是Θ。我们称之为修改列惩罚。从更仔细的模型中可以看出此修改列惩罚的含义(6).根据模型(6)作为一个模型B-花键底座和系数,型号(6)变系数模型(Hastie和Tibshirani,1993)在x个系数取决于z因此,我们可以将修改后的列惩罚解释为对单变量的惩罚P(P)-沿x个-轴。同样,罚款期限对于三明治来说,更平滑的三明治会减少可以解释为对单变量的惩罚P(P)-沿z-轴。等式中的第三个惩罚(4)对应于两个单变量平滑器的交互。
2.2. 快速实施
通过显示如何通过GCV的快速计算来选择平滑参数,我们导出了三明治平滑器的快速实现。GCV需要计算以及整个平滑矩阵的轨迹。我们需要一些初始计算。首先,我们需要奇异值分解
哪里是特征向量矩阵是特征值的向量。对于我=1,2,让; 然后和。由此可见我= 1,2,具有.
我们首先计算.替换对于在方程式中(1)我们获得
哪里.让; 然后
我们将对向量使用以下运算:一是仅包含正元素的向量,表示的元素平方根一和1/一表示一。我们可以推导出
哪里对于我=1.2和是长度为1s的向量。请参阅附录A用于方程推导(11).方程式的右侧(11)显示了每对平滑参数的计算只是长度向量的两个内积和术语只需对所有平滑参数进行一次计算。
接下来,可以首先使用张量积的另一个恒等式(Seber(2007),第235页),
然后使用跟踪标识tr(实验室)=tr(文学士)(如果尺寸兼容)(Seber(2007),第55页),以及,
哪里是κ的第个元素.
总而言之,通过方程式(11),(12)和(13)我们得到了一个计算GCV的快速实现,它使我们能够有效地选择平滑参数。由于实现速度快,三明治平滑器可以比E-M-GLAM算法快得多;参见第节5.2进行实证比较。对于E–M–GLAM估计量,维数矩阵的逆每对都需要,而对于三明治更平滑,除了表达式中的初始计算(9),不需要矩阵求逆。
3.渐近理论
在本节中,我们导出了三明治平滑器的渐近分布,并证明了它与具有乘积核的二元核回归估计量渐近等价。此外,我们还证明了当两阶差分惩罚相同时,三明治平滑器具有最佳收敛速度。
我们将使用最初用于研究平滑样条线的等效核方法(Silverman,1984)也有助于研究P(P)-样条(Li和Ruppert,2008; 王等.,2011). 非参数点估计通常是所有数据点的加权平均值,其权重取决于所使用的点和方法。等效核方法表明,对于某个核函数(等效核)和某个带宽(等效带宽),权重是核回归估计量的渐近权重。首先,我们定义了一个单变量核函数
哪里米是一个正整数s是米复根有积极的现实部分。在这里是一元惩罚样条函数的等效核(Wang等.,2011). 通过引理1 in附录B,为2阶米注意,核的阶决定了核估计的收敛速度。见Wand和Jones(1995)了解更多详细信息。具有乘积核的二元核回归估计形式为
哪里和是带宽。在适当的假设下,三明治平滑器与上述核估计量渐近等价(命题1)。因为核回归估计量的渐近理论已经建立(Wand和Jones,1995),可以类似地为三明治平滑器建立渐近理论。为了方便记法,一∼b条意味着一/b条收敛到1。
提议1.假设满足以下条件。
- (a)
有一个常数δ>0,这样.
- (b)
回归函数μ(x个,z)具有连续2米四阶导数,其中.
- (c)
方差函数是连续的。
- (d)
协变量满足.
- (e)
哪里c(c)是一个常量。
让,和.假设和对于某些常数也假设和.让使用th-和四阶差分惩罚和分别和度B-上的样条曲线x个-轴和z-轴分别具有等间距的节点。修复(x个,z) ∈ (0,1)×(0,1). 让
然后
所有证明均在附录B.
定理1在命题1中使用相同的符号,并假设命题1中的所有条件和假设都得到满足。为了简化符号,让我们此外,假设和具有,和对于正常数和。那么,对于任何(x个,z)∈(0,1)×(0,1),我们得到
作为分发和,其中
备注1.案例非常重要。估计量的收敛速度变为.石头(1980)得到了非参数估计的最优收敛速度。对于二元光滑函数μ(x个,z)连续2米th导数,估计的相应最优收敛速度μ(x个,z)单位正方形的任何内部点为因此,当,三明治平滑器达到最佳收敛速度。注意,具有乘积核的二元核估计收敛速度也为.
备注2.对于单变量情况P(P)-带有米四阶差分惩罚为(见王等. (2011))。因此,二元情形的收敛速度较慢,这表明了“维数诅咒”的影响。
备注3定理1表明,只要足够快,节数的发散率不会影响渐近分布。为了实际使用,我们建议和,以便每个箱子至少有四个数据点。对于单变量P(P)-样条曲线,最小值{n个/Ruppert建议4,35}节(2002).
4.不规则间隔的数据
假设设计点是随机的,我们使用模型,即。,和现在只有一个索引,而不是i、 j个和以前一样。假设设计点独立并从分布中取样F类(x个,z)在。三明治平滑器不能直接应用于不规则间隔的数据。这个问题的解决方案是先将数据装箱。我们划分变成等尺寸矩形箱的网格和let成为所有人的中庸使得位于(κ,我)第th个bin。如果(κ,我)第th个仓,是任意定义的,例如由最近邻估计量(见下文)。假设是位于的数据点,位于(κ,我)th bin,我们将三明治平滑器应用于网格数据以获得
哪里。那么我们的惩罚估计被定义为
4.1. 实际实施
为了使上述估算程序与第节中的快速实施协同工作2.2,我们需要处理由于采样变化而导致某些箱子中没有数据的问题。如果中没有数据(κ,我)一个解决方案是定义为相邻垃圾箱中的平均值。这样做对渐近没有影响,因为箱子最终会有数据。对于小样本,以这种方式填充空单元格可以更平滑地计算三明治,但可能会将空箱子附近的估计值标记为不可靠。
另一种解决方案是使用在数据和平滑参数之间迭代的算法,如下所示。最初,我们让如果(κ,我)th bin没有数据点。另一种可能性是对一些人来说是M(M)>0,是M(M)的值年带有(x个,z)最靠近中心的坐标(κ,我)确定平滑参数为了最小化GCV,我们只计算有数据的箱子的平方误差之和,而忽略没有数据的箱子。这为我们提供了一对初始平滑参数。然后,对于没有数据的箱子,我们替换s乘以这对平滑参数的估计值。现在,通过更新数据,我们可以获得另一对平滑参数。我们重复上述步骤,直到达到某种收敛。
4.2. 渐近理论
如前所述,我们将单位间隔划分为网格和出租是箱子的数量。
定理2.假设满足以下条件。
- (a)
有一个常数δ>0,这样.
- (b)
回归函数μ(x个,z)具有连续2米阶导数,其中.
- (c)
设计要点独立并从分布中取样F类(x个,z)具有密度函数(f)(x个,z)和(f)(x个,z)是肯定的并具有连续的一阶导数。
- (d)
条件启用,随机误差,与均值0和条件方差无关.
- (e)
方差函数是两倍连续可微的。
- (f)
和对于某些常数和.
修复然后,使用与定理1相同的符号和假设,我们得到了
作为分发n个→∞ 哪里在方程式中定义(16)和五(x个,z)在方程式中定义(17).
备注4.我们在定理2中假设随机设计点。对于固定的设计点,如果我们将条件(c)替换为哪里是(κ,我)th bin和(f)(x个,z)是一个连续的正函数。
5.仿真研究
本节比较了艾勒和马克思的三明治P(P)-在MISE和计算速度方面,使用GLAM算法(E–M–GLAM)和Wood的薄板回归样条(TPRS)实现的样条。章节5.1结果表明,三明治平滑器的MISE和E–M–GLAM方法大致相当,且小于TPRS方法,而第5.2说明了三明治平滑器相对于其他平滑器的计算优势。
5.1. 回归函数估计
模拟研究中使用了两种测试功能:和
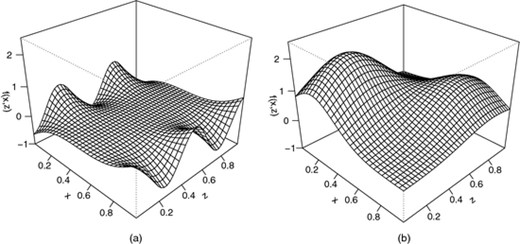
哪里和。请注意用于木材(2003). 两个真实表面如所示图1.
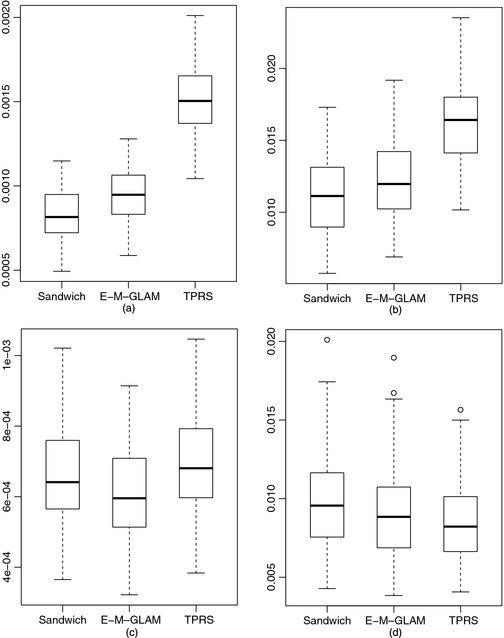
在两个样本大小下评估了三种平滑器的性能。在较小的样本研究中,每个测试函数都是在单位正方形上的20×30规则网格上采样的,随机误差是独立的,且分布相同具有σ等于0.1和0.5。在每种情况下,生成100个重复数据集,对于每个重复数据,由三个估计器拟合测试函数,并计算积分平方误差(ISE)。对于样条基和节点设置,根据备注3中的建议,10和15个等距节点用于x个-以及z-两个轴P(P)-样条估计。因此,总共使用了150节来建造B-样条曲线基础。立方(Cubic)B-样条曲线使用二阶差分惩罚。对于薄板回归估计器TPRS,我们使用R包mgcv(Wood,2006). 在本研究中,TPRS的等级为150(即基本维度为150)。对于所有三个估计量,平滑参数由GCV选择。MISE评估了这三种估计器的性能(表1)以及ISE的箱线图(图2).
| σ. | 以下估算结果:. |
|---|
| 三明治平滑器. | E–M–GLAM公司. | TPRS公司. |
|---|
|
| 0.1 | | | |
| 0.5 | | | |
|
| 0.1 | | | |
| 0.5 | | | |
| σ. | 以下估算结果:. |
|---|
| 三明治平滑器. | E–M–GLAM公司. | TPRS公司. |
|---|
|
| 0.1 | | | |
| 0.5 | | | |
|
| 0.1 | | | |
| 0.5 | | | |
| σ. | 以下估算结果:. |
|---|
| 三明治平滑器. | E–M–GLAM公司. | TPRS公司. |
|---|
|
| 0.1 | | | |
| 0.5 | | | |
|
| 0.1 | | | |
| 0.5 | | | |
| σ. | 以下估算结果:. |
|---|
| 三明治平滑器. | E–M–GLAM公司. | 第三方程序. |
|---|
|
| 0.1 | | | |
| 0.5 | | | |
|
| 0.1 | | | |
| 0.5 | | | |
发件人表1我们可以看到,在估计方面,三明治平滑器比E–M–GLAM做得更好而E–M–GLAM更适合评估中的箱线图图2显示这两个P(P)-样条方法基本上是可比较的。与二者相比P(P)-样条方法,TPRS给出了较大的MISE,只有一例除外。TPRS估算性能相对较差的一种解释TPRS是各向同性的,只有一个平滑参数,因此在两个方向上应用相同数量的平滑,这可能不适合作为非常平滑x个并且变化迅速z(请参见图1).
图2
小样本三种估计量的ISE的箱线图:(a),σ= 0.1; (b),σ= 0.5; (c),σ= 0.1; (d),σ= 0.5
更大样本的模拟研究和也完成了。对于这两个人P(P)-样条估计,节点数为和薄板回归样条的秩为1050,这是两个样条中使用的节点总数P(P)-样条估计。所有其他设置与较小样本研究中的设置相同。得出的MISE和箱线图得出了与小样本研究相同的结论。为了简单起见,我们这里不显示结果。
5.2. 计算速度
三种样条平滑器的平滑计算速度使用不同数量的数据点进行评估。为了简单起见,我们让并考虑了这个案子σ= 0.1. 我们为两者选择了结数P(P)-样条平滑器遵循备注3中的建议。我们将TPRS的等级固定为P(P)-样条曲线平滑器。对于两人P(P)-样条平滑器,报告的计算时间是在20×20对数尺度网格上搜索最优平滑参数的情况下.更精细的网格还使用了网格点。计算是在运行Windows的2.83-GHz计算机上进行的,该计算机具有3 GB的随机访问内存。表2总结了结果,并表明三明治平滑器是迄今为止最快的方法。请注意,括号中的值是使用更精细网格的计算时间。
| n个. | . | 以下估算值的时间:. |
|---|
| 三明治平滑器. | E–M–GLAM公司. | TPRS公司. |
|---|
| | 0.06 (0.24) | 4.09 (19.74) | 0.53 |
| | 0.08 (0.30) | 94.76 (344.13) | 19.50 |
| | 0.13 (0.45) | 1379.21 (5487.33) | 1032.07 |
| | 0.18 (0.58) | 3798.23 (15192.92) | — |
| | 0.32 (0.89) | 21023.44 (84093.76) | — |
| n个. | . | 以下估算值的时间:. |
|---|
| 三明治平滑器. | E–M–GLAM公司. | TPRS公司. |
|---|
| | 0.06 (0.24) | 4.09 (19.74) | 0.53 |
| | 0.08 (0.30) | 94.76 (344.13) | 19.50 |
| | 0.13 (0.45) | 1379.21 (5487.33) | 1032.07 |
| | 0.18(0.58) | 3798.23 (15192.92) | — |
| | 0.32 (0.89) | 21023.44(84093.76) | — |
| n个. | . | 以下估算值的时间:. |
|---|
| 三明治平滑器. | E–M–GLAM公司. | TPRS公司. |
|---|
| | 0.06 (0.24) | 4.09 (19.74) | 0.53 |
| | 0.08 (0.30) | 94.76 (344.13) | 19.50 |
| | 0.13 (0.45) | 1379.21 (5487.33) | 1032.07 |
| | 0.18 (0.58) | 3798.23 (15192.92) | — |
| | 0.32 (0.89) | 21023.44 (84093.76) | — |
| n个. | . | 以下估算值的时间:. |
|---|
| 三明治平滑器. | E–M–GLAM公司. | TPRS公司. |
|---|
| | 0.06 (0.24) | 4.09 (19.74) | 0.53 |
| | 0.08 (0.30) | 94.76 (344.13) | 19.50 |
| | 0.13 (0.45) | 1379.21 (5487.33) | 1032.07 |
| | 0.18 (0.58) | 3798.23 (15192.92) | — |
| | 0.32 (0.89) | 21023.44(84093.76) | — |
为了进一步说明其计算能力,将三明治平滑器应用于大小为和.对于立方B-样条函数与二阶差分惩罚耦合,定理1建议选择和.所以我们让具有接近在仿真中。我们还评估了E-M-GLAM的速度。为了节省时间,仅对25对平滑参数运行E–M–GLAM,并将计算时间乘以16或64,以分别在粗网格或细网格上与三明治平滑器的计算时间相比较表2这表明三明治平滑器可以在个人电脑上快速处理大数据,而E-M-GLAM要慢得多。薄板回归样条不适用于这些大数据,因为它需要比计算机提供的更多的内存空间。
总之,这里的模拟研究以及第节中的快速实现2.2显示三明治比其他两个估计值更平滑的优势。因此,当考虑到计算时间时,最好使用三明治平滑器。
6.应用:协方差函数估计
由于函数数据分析已成为一个主要的研究领域,协方差函数的估计已成为二元平滑的一个重要应用。由于函数数据集可能非常大,因此在函数数据分析中,快速计算二元平滑是必不可少的,尤其是在使用bootstrap进行推理时。局部多项式平滑是估计协方差函数的常用方法(参见示例Yao等. (2005)或者姚明和李(2006))而其他平滑方法,如核(Staniswalis和Lee,1998)和惩罚样条(Di等.,2009)也已使用。在本节中,通过模拟研究,我们比较了在固定网格上观察或测量数据时,三明治平滑器和局部多项式用于估计协方差函数的性能。
让{X(X)(t吨):t吨∈[0,1]}是具有连续协方差函数的随机过程K(K)(秒,t吨)=覆盖{X(X)(秒),X(X)(t吨)}. 为了简单起见,我们假设E类{X(X)(t吨)}=0,t吨∈ [0,1]. 假设是上述随机过程的独立实现的集合,我们观察到随机函数在具有测量误差的离散设计点,
哪里J型是每条曲线的测量次数,n个是曲线的总数是独立且同分布的测量误差,平均值为0且方差有限,且与随机函数无关.让。可以通过平滑样本协方差矩阵来获得协方差函数的估计通过二元平滑器。因为我们要平滑对称矩阵,所以对于三明治平滑器,我们使用两个相同的单变量平滑器矩阵,所以只有一个平滑参数可供选择。我们使用常用的局部线性平滑器(Yao等.,2005; 霍尔等.,2006)用于比较,并且通过留出一条曲线进行交叉验证来选择带宽。我们编写了Yao使用的估计器的R实现等. (2005),因为他们的代码在MATLAB中。
我们让其中特征值,k个=1,2,3,4和是情况1中任一情况的本征函数,
或情况2,
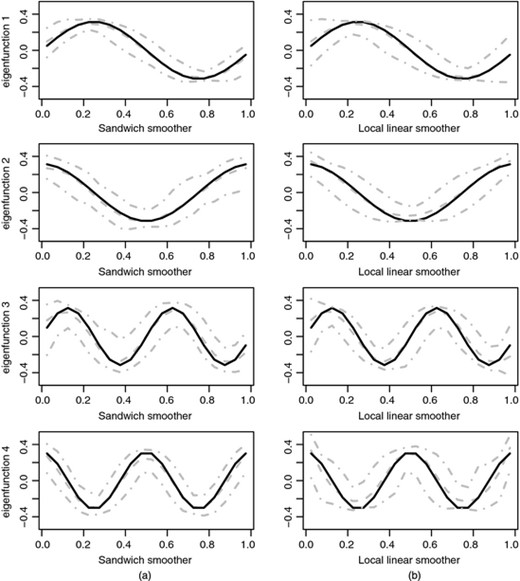
这两组特征函数用于Di等. (2009)、格雷文等. (2010)和Zipunniknov等. (2011). 我们让σ= 0.5. 我们模拟了100个数据集,并根据MISE评估了两个双变量平滑器。结果见表3。来源表3,对于带有的情况1(n个,J型)=(25,20)局部线性平滑器稍好,ISE的平均值和标准偏差较小,对于其他情况,两个平滑器的结果相近。情形1中两个平滑器估计的特征函数(n个,J型)=(25,20)如所示图3这表明这两种平滑器都能很好地估计特征函数。我们发现了类似的结果(n个,J型)=(100,40)(结果未显示)。
| (n,J). | 案例. | 三明治更加光滑. | 局部线性平滑器的结果. |
|---|
| (25, 20) | 1 | 0.053 (0.035) | 0.050 (0.026) |
| 2 | 0.199 (0.139) | 0.204 (0.144) |
| (100, 40) | 1 | 0.014 (0.008) | 0.013 (0.008) |
| 2 | 0.050 (0.034) | 0.050 (0.036) |
| (n,J). | 案例. | 三明治更光滑的效果. | 局部线性平滑器的结果. |
|---|
| (25, 20) | 1 | 0.053(0.035) | 0.050(0.026) |
| 2 | 0.199 (0.139) | 0.204 (0.144) |
| (100, 40) | 1 | 0.014 (0.008) | 0.013 (0.008) |
| 2 | 0.050 (0.034) | 0.050 (0.036) |
| (n,J). | 案例. | 三明治更加光滑. | 局部线性平滑器的结果. |
|---|
| (25, 20) | 1 | 0.053 (0.035) | 0.050 (0.026) |
| 2 | 0.199 (0.139) | 0.204 (0.144) |
| (100, 40) | 1 | 0.014 (0.008) | 0.013 (0.008) |
| 2 | 0.050 (0.034) | 0.050 (0.036) |
| (n,J). | 案例. | 三明治更加光滑. | 局部线性平滑器的结果. |
|---|
| (25, 20) | 1 | 0.053 (0.035) | 0.050 (0.026) |
| 2 | 0.199 (0.139) | 0.204 (0.144) |
| (100, 40) | 1 | 0.014 (0.008) | 0.013 (0.008) |
| 2 | 0.050(0.034) | 0.050 (0.036) |
真实和估计的特征函数用(n个,J型)=(25,20)对于情况1(噪声方差为0.25)(---,真本征函数; ,逐点中值估计特征函数;
,逐点中值估计特征函数; 第5和第95百分位曲线):(a)三明治更平滑;(b) 局部线性平滑器
第5和第95百分位曲线):(a)三明治更平滑;(b) 局部线性平滑器
我们还通过使用案例1比较了两个平滑器的计算时间J型。对于三明治平滑器,我们搜索了20多个平滑参数。对于局部线性平滑器,我们固定了带宽。请注意,通过保留一条曲线进行交叉验证来选择带宽意味着局部线性平滑器的计算时间将乘以带宽数和曲线数。表4结果表明,即使在协方差函数估计的带宽固定的情况下,三明治平滑器的计算速度也比局部线性平滑器快得多。
| J型. | 三明治平滑器的计算时间(s). | 局部线性平滑器的计算时间. |
|---|
| 40 | 0.02 | 2.98 |
| 80 | 0.03 | 50.04 |
| 160 | 0.05 | 961.42 |
| 320 | 0.16 | 13854.40 |
| J型. | 三明治平滑器的计算时间(s). | 局部线性平滑器的计算时间. |
|---|
| 40 | 0.02 | 2.98 |
| 80 | 0.03 | 50.04 |
| 160 | 0.05 | 961.42 |
| 320 | 0.16 | 13854.40 |
| J型. | 三明治平滑器的计算时间(s). | 局部线性平滑器的计算时间. |
|---|
| 40 | 0.02 | 2.98 |
| 80 | 0.03 | 50.04 |
| 160 | 0.05 | 961.42 |
| 320 | 0.16 | 13854.40 |
| J型. | 三明治平滑器的计算时间(s). | 局部线性平滑器的计算时间. |
|---|
| 40 | 0.02 | 2.98 |
| 80 | 0.03 | 50.04 |
| 160 | 0.05 | 961.42 |
| 320 | 0.16 | 13854.40 |
总之,模拟研究表明,对于协方差函数估计,当功能数据在固定网格上测量时,三明治平滑器在MISE方面与局部线性平滑器相当。三明治平滑器的计算速度比局部线性平滑器快得多。
7.多元P(P)-样条曲线
我们将三明治平滑地扩展到维度大于2的数组数据。假设我们有一个非参数回归模型d日≥3个协变量
因此数据收集在d日-维度网格。为了简单起见,假设协变量在。在双变量情况下,我们对d日-变量函数按张量积B-的样条曲线d日变量哪里是B-样条基函数。我们同时平滑所有协变量,以便拟合值和数据满足
哪里是更平滑的矩阵我使用th协变量P(P)-表达式中的样条线(3),年数据向量首先由,然后通过,依此类推,以及组织方式与年类似于方程式(7),系数的估计满足
被处罚的估计是
7.1. 多元的实现P(P)-样条曲线
在多维网格上平滑数据会出现两个计算问题。第一个问题是,除非s都很小将具有挑战性。第二个问题是平滑参数的选择。由于涉及大量的平滑参数,很难找到使一些模型选择标准(如GCV)最小化的平滑参数。
柯里的GLAM等. (2006)通过利用模型矩阵的数组结构和数据,为第一个问题提供了一个优雅的解决方案。更平滑的矩阵多元平滑具有张量积结构;因此在方程式中(18)可以通过上的一系列嵌套操作高效计算年通过GLAM算法。例如,考虑d日= 3. 然后可以用一行R代码高效计算:#函数“RH”是矩阵对数组的旋转变换
#参见Currie等人(2006)
yhat=矢量(右侧(S3,右侧(S2,右侧,S1,Y)))
我们编写了RH函数的R版本。
第二个问题可以很容易地处理多元快速P(P)-样条曲线。由于平滑矩阵的张量积结构2.2可以推广到多元情况。作为一个例子,我们展示了如何计算平滑矩阵的轨迹所以这个表达式(13)为所有人保留我= 1,…,d日; 然后通过以下公式计算平滑矩阵的轨迹
在表达式中使用标识(12)重复。请注意与表达式中的表达式类似(13)为所有人我.
三明治平滑器没有广义线性模型权重矩阵,当它用于二元平滑时,不需要旋转数组,因此我们不认为二元三明治平滑器是GLAM算法。然而,我们对双变量三明治平滑器的实现使用张量积结构来简化计算,与GLAM类似。
7.2. 一个例子
使用由平滑参数组成的网格,三明治平滑器在运行Macintosh软件和4GB随机访问内存的2.4GHz计算机上大约需要20秒。我们还没有找到其他平滑器的计算时间,但我们可以给出一个粗略的下限。我们看到了表2E–M–GLAM在在20×20网格上搜索平滑参数的二维网格。在20×20x20网格上搜索以选择平滑参数,GCV计算次数现在增加了20倍。此外,对于每个GCV计算,E–M–GLAM将需要更多的时间来平滑大小为128×128×24的数据,这要大得多。因此,对于计算GCV效率不如三明治平滑器的算法,E–M–GLAM估计器平滑128×128×24数据的计算时间将为数小时。
致谢
这项研究得到了美国国家科学基金会DMS-0805975和美国国立卫生研究院R01-NS060910的部分资助。罗晓的研究得到了国家研究资源中心资助UL1-RR024996的部分支持。李英星的研究得到了国家自然科学基金11201390的部分资助。我们感谢Iain Currie教授对GLAM算法的有益讨论。我们感谢两位审稿人和一位副编辑提出的最有帮助的意见和建议,这些意见和建议极大地改进了本文。我们非常感谢裁判建议使用“三明治平滑剂”这个名字。
工具书类
首先我们有
可以用公式表示(10)那个
在这个推导中,|·|表示倒数第二个等式中的欧几里得范数;我们使用的事实是而且两者都是和是对角矩阵。类似地,我们得到
从而建立方程(11).
附录B:定理证明
引理1.单变量核函数在表达式中定义(14)满足
因此为2阶米.
证明。我们需要计算两种类型的积分:和这些不定积分由Gradshteyn和Ryzhik第230页的结果3和4给出(2007). 然后进行例行计算,得出预期结果。部分引理在Wang中导出等. (2011). 推导的详细信息可以在Xiao中找到等. (2012).
在证明命题1之前,我们需要以下引理。
引理2.使用与命题1中相同的符号,并假设命题1中的所有条件和假设均已满足。对于(x个,z)∈(0,1)×(0,1),有一个常数C类>0,这样
哪里.
证明.通过方程式(8),。我们只需要考虑对于其中和都是非零的。因此假设κ和我满足和.让和。表示方式这个j个第列,共列和这个j个第列,共列.如肖所示等. (2012)李和鲁珀特(2008),有向量和一个常数这样,对于,和,用于或,.在这里如果j个=κ和否则。同样,也有向量和一个常数这样,对于,、和,用于或,.让和; 然后
哪里.通过方程式(7),
出租成为第页的第个元素和类似的这个秒的第个元素,我们快递作为双倍总和
使用方程式(8)和(19)和(20),我们有
哪里.
B.1、。命题1的证明
让和.根据肖的命题5.1等. (2012),有一些常量使得
在这里如果和否则;其他的δ-术语的定义类似。同样,也有一些常量使得
让
从引理2可以得出.因此和.
为了简化符号,表示通过ξ.我们证明了这一点通过展示是O(运行)(ξ). 根据引理2,.自和,因此为了简单起见,我们只展示
我们在以下情况下使用案例作为一个例子。因为
和,平等(23)已被证明。情况发生时以及期望的结果,包括可以得到类似的证明。
接下来我们展示一下,即。。请注意可以扩展为单个术语的总和。与之前的分析类似,双倍总和我,j个是其中之一或、或的顺序较小。
B.2节。定理1的证明
命题1表明三明治平滑器渐近等价于具有乘积核的核回归估计量为了确定核估计量的渐近偏差和方差,我们对多元核密度估计量进行了类似于Wand和Jones中的分析(1995). 根据命题1,
我们继续使用符号.让
方程式右侧的第一项(25)是的Riemann有限和在网格上,而第二项是相同函数的积分,以及计算这两个术语之间的差异。不是随机的,下面的引理4表明.现在等式(24)成为
对于方程中的二重积分(26),我们首先采用泰勒级数展开在(x个,z)直到关于的th偏导数x个和关于的th偏导数z然后我们抵消那些被引理1消失的积分。由此可以得到渐近平均值的显式表达式:
对于任意两个随机变量X(X)和Y(Y),如果var(Y(Y)) =o个{变量(X(X))},然后是var(X(X)+Y(Y))=变量(X(X))+o个{变量(X(X))}. 因此,通过让和,我们可以通过命题1得到
为了获得最佳收敛速度,让和收敛到一些常数。然后我们有
对于一些正常数和(回忆一下.)我们需要选择和以便因此,对于某些正常数和同样,对于某些正常数和。很容易验证.
引理3.让G公司(x个)是[0,1]中具有连续二阶导数的实函数。让对于我= 1,…,n个.假设小时=o个(1) 以及作为n个→∞. 然后
哪里在表达式中定义(14).
证明首先要注意对称且以1为界。阿尔索在(−∞,0]上是无穷可微的,并且所有导数都有界米超过(-∞,0]。让对于我= 1,…,n个.假设在不失一般性的情况下.我们有
和
在不等式的推导中(28),术语以下为
和
术语来自
自从当两者同时存在时u个和在中注意,我们使用了等式在上面的推导中,我们稍后也将使用它。组合不等式(27)和(28),我们有
为了简单起见,用表示和的一阶和二阶导数分别是。类似地,表示为和的右导数位于0。如果,然后因此
如果x个<(我−1)/n个,然后.让
然后.我们有
我们同样可以证明不等式(31)在以下情况下保持x个>我/n个现在,有了不平等(30)和(31),
完成了引理。
引理4.术语在方程式中定义(25)是.
证明。为了简化符号,让
和
然后是通过引理3。请注意由以下项之和限定
和
因为是,表达式(32)也是.根据Durrett附录中的定理9.1(2005),存在并且等于.因此连续且有界。引理3表示(33)是,这就完成了我们的证明。
B.3节。定理2的证明
表示设计要点由(x个,z). 引理2和命题1的证明在装箱数据中的应用具有和替换为和,我们获得
哪里
和定义类似于在命题1的证明中和替换为和.让是中的数据点数量(κ,我)第个箱子。然后
所以是条件方差函数的Nadaraya–Watson核回归估计量在类似地,我们可以证明是的核密度估计器(f)(x个,z)在根据核密度估计量和Nadaraya–Watson核回归估计量的一致收敛理论(例如,参见Hansen(2008)),
和
根据以上两个等式
对于任何连续函数,通过与命题1的证明类似的论点克(x个,z)超过,我们可以推导出
然后,通过等式(35)和(37),
通过出租在方程式中(38),我们从方程中导出(39)那个
哪里五(x个,z)在方程式中定义(17).我们可以写作为
平等(36)意味着每个箱子都是非空的,所以通过泰勒级数展开在我们从上面的方程中得出
其次是平等(34)那个
很容易证明
哪里在方程式中定义(16).根据平等原则(41)假设具有,
使用方程式(40)和(42),我们可以证明
分配和
平等(43)和(44)一起证明定理2。
©2013皇家统计学会







{kind=link}
{kind=link}
{kind=link}