总结
线性多元回归动态模型将多元时间序列的图形表示与状态空间模型相结合,已被证明是一类很有前途的交通流数据预测模型。对英国曼彻斯特附近繁忙的高速公路十字路口的流量分析突出了两个重要的建模问题:根据一天中的时间调节不同水平的交通变化,以及调节由于数据收集错误导致的测量误差。本文扩展了线性多元回归动态模型来解决这些问题。此外,本文还研究了线性多元回归动态模型通常使用的近似预测极限与真实但不太容易获得的预测极限的接近程度。
1.简介
现在,许多道路的交通流量数据都是定期收集的。这些数据可作为交通管理系统的一部分,用于评估公路设施和性能,或用于实时交通控制,以防止和管理拥堵。这些数据还可以用作旅行者信息系统的一部分。良好的短期交通流预测模型对于交通管理和旅行者信息系统的成功至关重要。本文的重点是开发流量预测模型,该模型特别适用于评估公路设施和一段时间内的性能,或为旅行者提供高级交通信息。
交通流量数据是经过数据采集点的车辆计数的时间序列S公司(1),…,S公司(n个)网络上下游站点的流量S公司(我)是关于来自S公司(我). 为了利用这一点,一些人利用其他站点的滞后流量来帮助预测S公司(我) (泰巴尔迪等。2002年;Kamarianakis和Prastacos,2005年;Stathopoulos和Karlaftis,2003年),而其他人使用条件独立性,因此滞后流仅在邻近的站点S公司(我)是必需的(惠塔克等。, 1997;太阳等。, 2006). 然而,当车辆计数的时间间隔足够长,以至于车辆在网络中的多个站点注册时在同一时间段内如本文所述,其他站点滞后0的流量有助于预测S公司(我). 提出的模型是一个动态图形模型,称为线性多元回归动态模型(LMDM)(Queen and Smith,1993年),利用这一点并使用关于上游流量的信息t吨用于预测流量S公司(我)同时t(请参见第3节关于如何做到这一点)。
鉴于卡瓦略和韦斯特(2007)使用无向图表示多元时间序列协方差结构中的条件独立关系,LMDM表示任何条件独立关系与因果关系有关通过有向非循环图(DAG)跨越时间序列。该DAG用于将多元模型分解为简单的单变量组件,每个组件都是(有条件地)贝叶斯回归动态线性模型(DLM)(West和Harrison,1997年). 在交通预测方面,如太阳等。(2006)交通流的方向在系统中产生因果驱动,通过网络的可能路径用于定义跨越时间序列的条件独立结构。
LMDM中的每个单变量回归DLM都使用同期上游交通流作为回归因子。泰巴尔迪等。(2002)在对交通流建模时,也使用了回归DLM,上游交通流作为线性回归变量。然而,它们的回归因子是滞后流量,而不是同期流量,因为它们有1分钟的流量,所以与本文不同的是,在一个时间段内不计算多个站点的车辆。
本文为英国曼彻斯特附近繁忙的高速公路交叉口指定了DAG和相关的LMDM。尽管LMDM在交通预测方面的优势已经得到了广泛的探讨(惠特洛克和皇后乐队,2000年;女王等。, 2007;Queen and Albers,2009年),建模问题仍然存在,包括根据一天中的时间适应不同级别的交通变化(卡马里亚纳基斯等。,2005年)以及调节由于数据收集错误而可能发生的测量误差(比克尔等。, 2007). 本文提出的方法是为了解决这些重要的实际问题而开发的。此外,本文使用模拟将LMDM中通常使用的近似(易于计算)预测极限与真实(不易于计算)预测极限的估计值进行比较。
尽管本文侧重于在交通流预测中使用LMDM,但该模型可能适用于任何涉及流的应用,例如电力流、电信网络中的信号流、互联网上的包裹流和供应链中的货物流。它还可以应用于不同类型的多元时间序列问题,如销售预测(女王,1997年).法罗(2003)还通过使用类似于LMDM的模型来关注销售预测,而福森等。(2006)和郭和布朗(2001)采用与LMDM相似的思路,分别分析激素时间序列和肝硬化癌症患者。
本文结构如下。第2节描述了整篇论文中使用的数据。第3节简要回顾了LMDM,而在第4节为特定网络指定LMDM。第5节扩展了LMDM,使其能够适应通常交通流模式中的异方差,而第6节对提出的LMDM进行调整,以适应由于数据收集错误而经常出现的测量误差。第7节研究LMDM通常使用的近似预测极限与真实预测极限的接近程度。最后,第8节给出了一些结论,并讨论了未来研究的问题。
2.数据
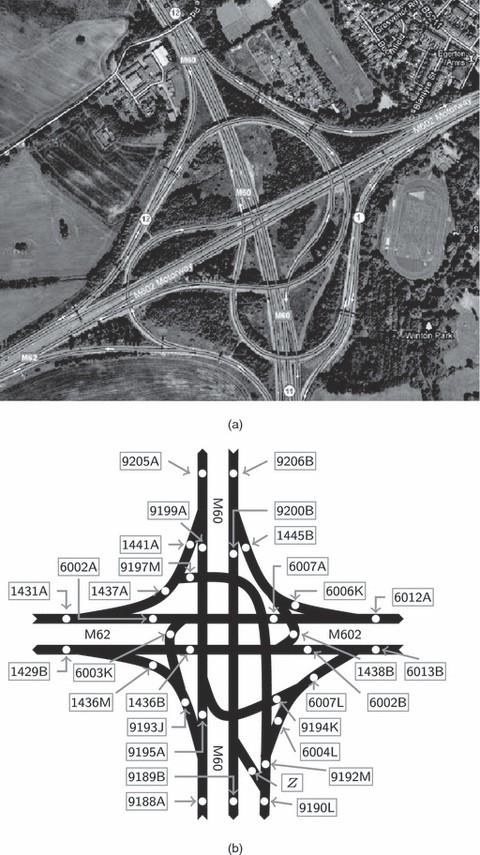
本文重点开发了一个模型,用于预测英国曼彻斯特西部M60、M62和M602三条高速公路交叉口的交通流量。图1(a)显示了网络的航空照片。
图1
曼彻斯特网络:(a)航空照片(©2012 DigitalGlobe,GeoEye,Infoterra Ltd&Bluesky,The GeoInformation Group;地图数据©2012谷歌);(b) 原理图
这些数据是网络中多个数据采集点通过路面下感应线圈的车辆数量。曼彻斯特网络的示意图反映了数据站点的布局,如所示图1(b)在这里,箭头表示行进方向,数据站点用圆圈标记和指示。本文中使用的数据是由英国公路局于2010年2月至11月间收集的(http://www.highways.gov.uk网站/).
数据采用分钟计数的形式。对于用于评估公路设施的交通管理系统公路通行能力手册(运输研究委员会,2010年)建议将数据聚合为15分钟的时间间隔。15分钟的时间间隔也适用于旅行者信息系统,因为旅行者的决定会受到路线系统沿线的预期条件的影响(弗拉霍吉安尼等。, 2004). 因此,在本文中,数据被聚合为15分钟的时间间隔。使模型适应更短的时间段将是未来研究的重点。
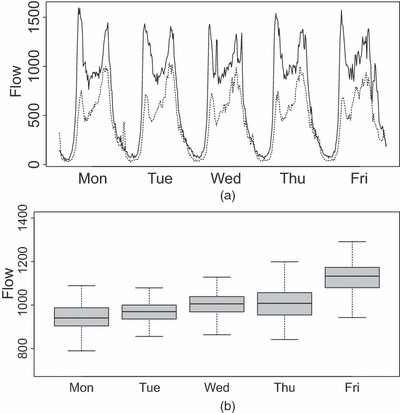
图2(a)显示了站点1431A(完整曲线)和6013B(断裂曲线)典型一周15分钟流量的时间序列图。这两个站点的每日模式相似,高峰出现在上午和下午的高峰时段。所有站点的流量都呈现出类似的每日模式。
图2
(a) 1431A现场15分钟流量( )和现场6013B(
)和现场6013B( )2010年6月7日至11日,以及(b)利用2010年3月至11月观测到的1431A现场2.00 p.m.至2.59 p.m.期间的流量,按工作日绘制箱线图
)2010年6月7日至11日,以及(b)利用2010年3月至11月观测到的1431A现场2.00 p.m.至2.59 p.m.期间的流量,按工作日绘制箱线图
图2(b)显示了2010年3月至11月期间每个工作日在1431A站点2.00 p.m至2.59 p.m期间的流量箱线图。这些明显显示了流量水平和可变性的每日差异。这些每日差异可以纳入模型中,但为了表达清晰,本文将仅使用周三的流量(这不会导致不连续性问题,因为午夜前后的流量非常低,变化很小)。
车辆通过网络只需几分钟。因此,对于15分钟的数据,通常在同一时间段内在多个数据站点对车辆进行计数。LMDM利用与特定站点上游站点流量相关的信息对此进行调节S公司(我)帮助预测流量S公司(我)在同一时间段内。
3.线性多元回归动态模型
本节简要概述了LMDM(请参见Queen and Smith(1993)详细信息)。
考虑一个多元时间序列具有与因果关系相关的条件独立结构,因此,对于每个我= 2,…,n个每次t吨,以变量为条件,Y(Y)t吨(我)独立于(其中“∖”表示“排除”)。集合pa中的每个变量{Y(Y)t吨(我)}是一个起源属于Y(Y)t吨(我)和Y(Y)t吨(我)是一个小孩每个变量的pa{Y(Y)t吨(我)}. 变量Y(Y)t吨(我)是一个根节点如果pa{Y(Y)t吨(我)}=Ø. 时间序列Y(Y)t吨然后每次都可以用DAG表示t吨带有指向的弧Y(Y)t吨(我)来自pa的父母{Y(Y)t吨(我)}.
LMDM使用DAG对多元时间序列建模n个单独的回归DLM:每个用于Y(Y)t吨(1) 和,我= 2,…,n个每个时间序列都有其父项作为线性回归变量,而根节点则由任何合适的DLM建模。因此,LMDM计算简单,DLM技术可以很容易地应用(例如,请参见,Queen和Albers(2009)).
正式表示所有可用信息t吨−1由天t吨− 1,LMDM定义如下:
这个米我-量纲向量F类t吨(我)包含父pa的任意但已知的函数{Y(Y)t吨(我)}以及可能的其他已知变量,θt吨(我)是米我-维度参数向量Y(Y)t吨(我)和是标量观测方差,米t吨− 1和C类t吨− 1是的(后)力矩θt吨− 1,矩阵G公司t吨,W公司t吨和C类t吨− 1是块对角线,、和和是独立错误的独立序列。
给定分布(3)由表达式(2)获得。每个预测分布Y(Y)t吨(我)以pa为条件{Y(Y)t吨(我)}然后通过表达式(1)分别找到。然而,作为Y(Y)t吨(我)和pa{Y(Y)t吨(我)}都是同时观察到的t吨,的边缘的每个的预测Y(Y)t吨(我)是必需的。虽然边际预测分布通常无法通过分析计算,但可以通过使用E类(X(X))=E类{E类(X(X)|Y(Y))}和V(V)(X(X))=E类{V(V)(X(X)|Y(Y))}+V(V){E类(X(X)|Y(Y))}。本质上,在LMDM中Y(Y)t吨(我)用于获取以下各项的边际预测矩Y(Y)t吨(我),进而用于找到Y(Y)t吨(我)的孩子,等等(请参见女王与史密斯(1993)和女王等。(2008)). 最后,由于LMDM的结构年t吨,每个的分布θt吨(我)可以在(条件)DLM中单独更新(以封闭形式).
本文中开发的一些方法直接影响预测方差。为了评估这些方法的预测性能,使用了联合对数预测似然(LPL),而不是仅基于预测误差的度量。观察后,LMDM的LPL计算如下
由于预测方差直接影响预测极限,因此比较预测性能的另一种决策理论原则方法是通过平均区间得分(MIS),它是每个观测值的预测区间极限的函数,当观测值位于间隔之外时,会受到惩罚(有关详细信息,请参阅Gneiting和Raftery(2007)). 然后对时间序列中的所有观测值计算MIS。通过简单计算每个时间序列所有观测值的MIS,可以将此思想扩展到多元LMDM设置。
4.建立曼彻斯特网络的线性多元回归动态模型
4.1. 叉和连接
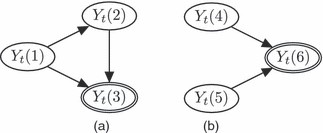
交通网络基本上是两种类型的一系列交叉点:分叉和连接。一个叉车,在叉车中,来自单个站点的车辆S公司(1) 移动到两个站点S公司(2) 和S公司(3) ,如所示图3(a)一个连接,其中来自两个站点的流量,S公司(4) 和S公司(5) ,合并到单个网站S公司(6) ,如所示图3(b).
图3
(a) 分叉和连接:在每个图中,箭头表示行进方向,圆圈表示位置
让Y(Y)t吨(我)是通过现场的车辆数量S公司(我)15分钟内t吨.以下女王等。(2007),方程式(1)在LMDM中和Y(Y)t吨(3) 、和和Y(Y)t吨(6) 可以诱使其具有形式
因此,上游流量用于下游流量的模型中。
在表达式(4)中μt吨(·)是级别参数,而参数αt吨表示来自S公司(1) 至S公司(2) 、和v(v)t吨(·)是正常的误差项。在女王等。(2007)误差的正态性v(v)t吨(·)通过对大平均值的正态性采用泊松近似进行证明。虽然本文中的数据不能被视为泊松或正态第5节,方差作为平均值的函数增加。West和Harrison(1997)建议在正常DLM中使用方差法来建模此类非正常数据。因此,为了利用LMDM的计算简单性和已建立的DLM技术可以容易地并入模型中的优点,将正常误差用于v(v)t吨(·)和,英寸第5节LMDM将被扩展为包含方差法,以适应数据的非正态性。请注意,数据可以通过使用非正态误差通过被称为多元回归动态模型的LMDM泛化进行建模(Queen and Smith,1993年),但这将更加复杂。数据也可以转换为正常值,尽管这将失去模型的可解释性。
遵循WinBUGS软件的术语(http://www.mrcbsu.cam.ac.uk/bugs/),Y(Y)t吨(3) 和Y(Y)t吨(6) 被建模为逻辑变量。这是因为所有来自S公司(1) 必须流向S公司(2) 和S公司(3) ,而所有来自S公司(4) 和S公司(5) 流向S公司(6). 当然,这些逻辑关系并不完全正确,因为在这段时间的开始和结束时,一些车辆将在站点之间。然而,该误差应足够小,以使该模型适用。
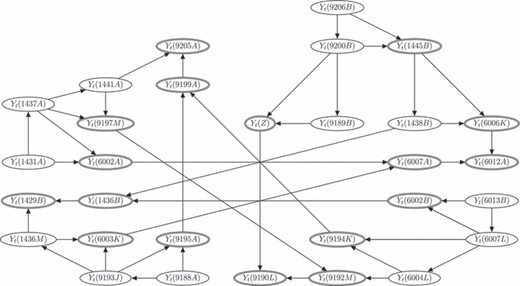
中给出了表示fork和join的DAG图4。因为的模型Y(Y)t吨(2) 取决于Y(Y)t吨(1),Y(Y)t吨(1) 是的家长Y(Y)t吨(2) ,因此从Y(Y)t吨(1) 至Y(Y)t吨(2) 逻辑变量在DAG中用双椭圆表示。连接单个分叉和连接的DAG提供了一种通用方法,用于获取整个网络的DAG和相关LMDM。图5显示了曼彻斯特网络的完整DAG。
图4
表示(a)fork和(b)join的DAG: ,逻辑变量
,逻辑变量
4.2。模型参数
虽然每个观测方程Y(Y)t吨(1),Y(Y)t吨(4) 和Y(Y)t吨(5) 在表达式(4)中,每次代数上是相同的t吨,实际参数,μt吨(1),μt吨(4) 和μt吨(5) ,将呈现一个日循环,如图所示图2(a)该日循环可通过季节因子DLM建模(West和Harrison,1997年),其中每天每15分钟有一个平均流量水平参数(如中所述Queen和Albers(2009)),或通过傅里叶形式的DLM(West和Harrison(1997)第8.6节)或通过考虑样条来表示一天中的平滑流动趋势(如泰巴尔迪等。(2002)). 季节因素模型的优点是其可解释性,如Queen和Albers(2009),在通过干预进行建模更改时特别有用(干预技术允许将时间序列中有关更改的信息输入到模型中,以保持预测性能West和Harrison(1997)第11.2节)。当流量数据聚合到较小的时间间隔(如5分钟)时,由于可能不同尺度上的大量参数,季节因子模型可能会导致卡尔曼滤波计算的数值不稳定问题。在这种情况下,傅里叶模型或平滑趋势模型更适合于节约。然而,对于15分钟的数据,季节因子模型不存在此类问题,并且计算速度快且效率高。
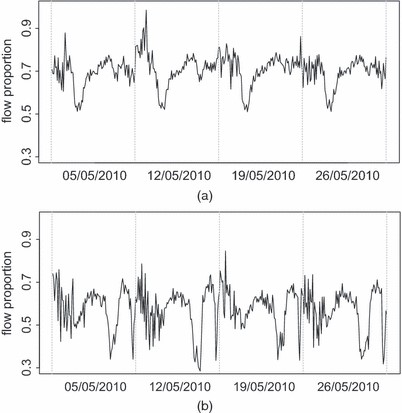
参数αt吨表达式(4)中表示从父级流向子级的流量比例,如图6,可以在一天的不同时间系统地变化。参数显示的昼间模式αt吨也可以通过季节因子模型进行建模,如Queen和Albers(2009).
图6
2010年5月的四个星期三,从(a)父母1431A到孩子1437A和(b)父母6013B到孩子6007L的流量比例
4.3. 父子之间的线性关系
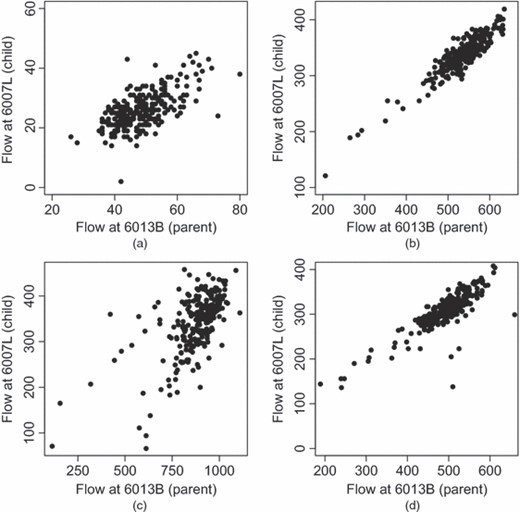
LMDM方程Y(Y)t吨(2) 在表达式(4)中,假设父项和子项之间存在线性关系。图7,显示了家长15分钟流量的典型图与孩子在一天中的不同时间,说明了为什么这是一个现实的假设。线性关系可以解释每个图中父母和孩子之间的大多数差异,尽管这种关系在一天中并不相同。这只是比例参数日循环的结果αt吨,如所示图6注意,在下午5点15分至5点29分的图中,似乎有两种不同的状态。这是由于一些不寻常的流量需要在母站点进行干预造成的。
图7
母体6013B的15分钟流量图与其子6007L在一天中的某些时段的15分钟流量(图的比例不同):(a)上午4.15–凌晨4.29。;(b) 上午11点15分至11点29分。;(c) 下午5点15分至5点29分。;(d) 下午7点15分至7点29分。
4.4. 作为回归因子的同期流量
LMDM使用具有同期流量的单变量回归DLM作为线性回归变量。但是,如果使用具有滞后流的单变量DLM作为回归变量(例如,在泰巴尔迪等。(2002))?
为了回答这个问题,这两个模型都用于预测2010年5月9206B和9200B站点上午7点到晚上8.59点之间的15分钟流量(忽略安静的夜间时段)。计算每个模型的中位数误差MedianSE和LPL(由于交通数据中可能存在大量离群值,因此使用了中位数误差而不是平均误差)女王等。(2007)). LMDM(MedianSE=1154,LPL=−1288)确实比单变量DLM表现更好,将滞后流作为回归变量(Median SE=2876,LPL=−7198)。在预测这些站点的5分钟流量时,也观察到了这一结果(LMDM MedianSE=232,LPL=−3404,滞后流量MedianSE=914,LPL=−3834)。
5.流量异方差建模
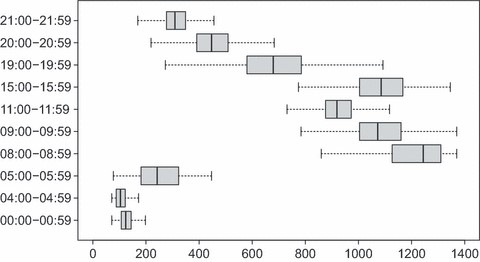
在LMDM中,遵循DLM的标准方差学习方法(请参见West和Harrison(1997),第4.5节),关于未知、假设常数、观测方差的推断V(V)t吨(我)=V(V)(我)英寸方程式(1)基于相关精度的共轭分析φ(我)=V(V)(我)−1然而,从中显示的流量箱线图可以看出图8,这里假设观测方差不变是不现实的。
图8
2010年3月至11月的所有星期三,现场1431A每天不同时间的流量箱线图
当将LMDM用于其他应用时,常数方差的假设也可能不合理。例如,由于一年中的节假日和季节,要在连锁超市中分配的商品的流动可变性可能会受到季节性影响。例如,这些季节性影响也可能导致居民区电力流量分布的非恒定变化。
第4.1节建议扩展LMDM以纳入方差定律,使均值与方差相关的非正态数据能够由LMDM建模。这样的方差定律也将适应一个非常数V(V)t吨(我). 由于LMDM使用简单的正常DLMLMDM可以很容易地扩展到在每个条件DLM中包含方差定律,从而产生一种新的方法来容纳非正常数据和非恒定数据V(V)t吨(我)在多元状态空间模型中。
在方差定律模型中,写出观测值在时间上的方差t吨作为,其中μt吨(我)和V(V)(我)分别是序列的基础水平和观测方差Y(Y)t吨(我)、和k{μt吨(我)}表示与μt吨(我),这取决于数据的上下文和性质(米贡等。, 2005).
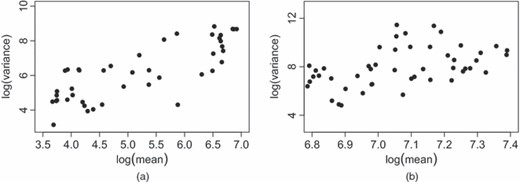
图9显示了9206B站点流量对数-均值和对数-方差之间的(不同的)大致线性关系,时间段为晚上7点至早上6点59分和早上7点至下午6点59秒。在其他站点也可以观察到类似的关系。这些经验关系表明,对于每个时期,
哪里β对于两个不同的时段采用不同的值。
图9
流量平均值与9206B现场的流量变化(对数刻度,使用2010年所有星期三计算):(a)下午7点至上午6点59分的48个15分钟周期。;(b) 上午7点至下午6点59分的48个15分钟周期(图的比例不同)
正如所指出的West和Harrison(1997),重要的是k{μt吨(我)}“随着流量水平的显著变化而显著变化”,而不是确定k{μt吨(我)}. 因此,经验流量平均值-方差关系建议对与水位相关的观测方差变化进行建模μt吨(我)由
具有不同的β-7.00 p.m.–6.59 a.m.和7.00 a.m.–659 p.m.这两个时段的值(另一种选择是在方程式(5),但这并不能提高模型性能。)
参数μt吨(我)是未知的平均值Y(Y)t吨(我). 在道路安全研究的相关应用中考虑DLM中的类似方差建模问题时,双层等。(2010)将观测值本身用作未知平均值的代理。在本文中,重点是预测,μt吨(我)由其预测进行估计,表示为(f)t吨(我),从LMDM获得。这激发了方差定律,其中V(V)t吨(我)英寸方程式(1)被替换为
潜在的观测方差V(V)(我)当使用常用的方差学习技术观察数据时,可以在线动态估计数据(参见West和Harrison(1997),第4.5节),而β可以使用历史数据从流量平均值和方差估计β-7.00 p.m.–6.59 a.m.和7.00 a.m.–659 p.m.这两个时段的值。
除了使用方差定律外,还可以进一步调整LMDM,以允许观测方差随时间动态演变。以下是为单变量DLM开发的方法,假设可以随时间变化,因此,考虑到后部
优先于φt吨(我)由提供
虽然之前的平均值φt吨(我)与后验平均值相同φt吨− 1(我),的先验方差φt吨(我)大于的后验方差φt吨− 1(我)所以,观察之后年t吨− 1,关于φt吨(我)比φt吨− 1(我). 较小的值δ与较大的值相比,不确定性增加得更多。因此,较小的值δ当观测方差随时间不稳定时适用,而当观测方差更为静态时,更大的值适用。更新方程以获得φt吨(我)很简单,如所示West和Harrison(1997)。这个想法也可以与方差定律一起使用,因此,在表达式(6)中,V(V)(我)也可以动态演化。
5.1. 一些结果
曼彻斯特网络中使用了四种不同的LMDM进行预测:
- (a)
模型A假设一个常数V(V)(我)并使用已建立的方差学习技术进行估计V(V)(我)在线动态观察数据;
- (b)
模型B假设时间变化V(V)t吨(我)使用方差定律(6)和动态演变的基本方差V(V)(我)如表达式(7)和(8)所示;
- (c)
模型C假设时间变化V(V)t吨(我)使用方差定律(6)和动态演变的基本方差V(V)(我)如表达式(7)和(8)中下午7点至早上6点59分的时间段,同时使用动态演变的基本方差V(V)(我)如表达式(7)和(8)所示,但上午7点至下午6点59分期间无方差定律(因为该期间的均值-方差关系较弱);
- (d)
模型D假设时间变化V(V)t吨(我)仅使用方差定律(6)。
2010年2月至4月的历史数据用于估算β在表达式(6)中,分别针对下午7点至6点59分和上午7点至5点59分这两个时段,在缺乏专家信息的情况下,也用于引出先验信息。然后获得了2010年5月和6月周三流量的在线一步预测。
作为使用模型A–D预测父级和子级绩效的示例,表1显示了预测四个父根节点及其关联(非逻辑变量)子节点时的LPL和MIS值。对于型号B和Cδ每个系列都需要。以下West和Harrison(1997),LPL可以用作选择δ这为这些数据提供了最佳的预测性能。然而,LPL可以对异常值敏感,因此δ被选择来最小化MIS。(模型A–D都具有相同的预测方法,因此只需要评估预测极限。)中引用的LPL和MIS表1对于B型和C型的每个系列,使用δ使该系列和模型的MIS最小化。尽管模型A在LPL方面表现最好表1模型B在这些系列的MIS方面表现最好,在所有其他情况下,表现最好的模型是模型B,它使用方差定律,也允许潜在方差V(V)(我)动态演变。
| 系列. | 以下型号的LPL:. | 以下型号的MIS:. |
|---|
| A类. | B. | C类. | 天. | A类. | B. | C类. | 天. |
|---|
| (9206B、9200B) | −10001 | −10040 | −10230 | −10266 | 691 | 498 | 541 | 635 |
| (9188A、9193J) | −8010 | −7710 | −7852个 | −8394 | 407 | 294 | 336 | 396 |
| (1431A、1437A) | −9615 | −9077磅 | −9140 | −9158 | 595 | 414 | 453 | 487 |
| (6013B、6007L) | −9137 | −8466 | −8724 | −9157 | 441 | 272 | 347 | 385 |
| 系列. | 以下型号的LPL:. | 以下型号的MIS:. |
|---|
| A类. | B. | C类. | 天. | A类. | B. | C类. | 天. |
|---|
| (9206B、9200B) | −10001 | −10040 | −10230 | −10266 | 691 | 498 | 541 | 635 |
| (9188A、9193J) | −8010 | −7710 | −7852 | −8394 | 407 | 294 | 336 | 396 |
| (1431A、1437A) | −9615 | −9077 | −9140 | −9158 | 595 | 414 | 453 | 487 |
| (6013B、6007L) | −9137 | −8466 | −8724 | −9157 | 441 | 272 | 347 | 385 |
| 系列. | 以下型号的LPL:. | 以下型号的MIS:. |
|---|
| A类. | B. | C类. | 天. | A类. | B. | C类. | 天. |
|---|
| (9206B、9200B) | −10001 | −10040个 | −10230 | −10266 | 691 | 498 | 541 | 635 |
| (9188A、9193J) | −8010 | −7710 | −7852 | −8394 | 407 | 294 | 336 | 396 |
| (1431A、1437A) | −9615 | −9077 | −9140 | −9158 | 595 | 414 | 453 | 487 |
| (6013B、6007L) | −9137 | −8466 | −8724 | −9157 | 441 | 272 | 347 | 385 |
| 系列. | 以下型号的LPL:. | 以下型号的MIS:. |
|---|
| A类. | B. | C类. | 天. | A类. | B. | C类. | 天. |
|---|
| (9206B、9200B) | −10001 | −10040 | −10230 | −10266 | 691 | 498 | 541 | 635 |
| (9188A、9193J) | −8010 | −7710 | −7852 | −8394 | 407 | 294 | 336 | 396 |
| (1431A、1437A) | −9615 | −9077 | −9140 | −9158 | 595 | 414 | 453 | 487 |
| (6013B、6007L) | −9137 | −8466 | −8724 | −9157 | 441 | 272 | 347 | 385 |
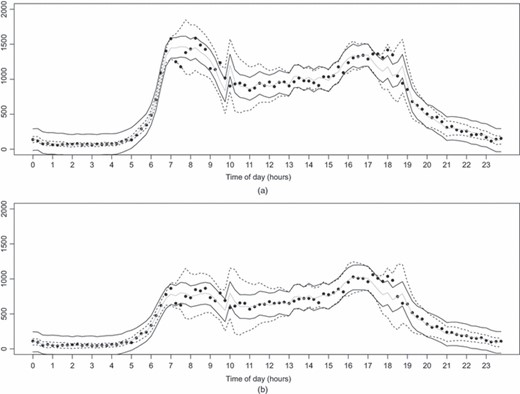
作为预测表现的另一个例子,图10显示了根节点1431A及其子节点1437A在特定日期的观测流量及其一步预测方法(f)t吨(我)和一步到位预测限额定义为。由于模型B在时变模型中表现最佳,因此考虑模型A和B计算预测。方差定律和动态变化的潜在方差的影响在这两个地点都是显而易见的:例如,模型B给出的预测极限范围比模型A在午夜至上午6.59点给出的范围小得多。
在图10中,在上午和下午的高峰期观察到一些流量,这些流量超出了基于模型A的预测限值,但处于里面模型B提供的预测限值作为时间t吨在方差法模型中,增加观测方差估计具有预测误差的指数加权移动平均值的形式(West和Harrison(1997),第363页),因此最近的预测误差比过去观察到的预测误差具有更大的权重。结果是,由于预测分布的方差按模型B将比模型A更快地适应,以纠正较大的预测误差。这意味着方差法模型会自动增加预测中的不确定性,这在可能需要干预但无法获得专家信息时非常有用。
在图10,预测极限有时相当宽,大多数观测值都在其范围内。然而,对于一个校准良好的模型,大约只有95%的观测值应在预测范围内。在整个预测期内,模型B实际上对根节点进行了很好的校准,大约95%的观测结果都在每个系列的预测范围内:图10(a)是由于特定日期的意外观测导致预测不确定性增加的结果。相反,对于每个根节点,模型A低估了预测的不确定性,其覆盖率大约只有89%。
然而,在预测子变量时,模型B高估了预测的不确定性,大约98%的观测值都在每个序列的预测范围内,而这次模型A的覆盖率大约为95%,经过了很好的校准。这表明,对于子变量,有一些影响变化的因素在模型B中没有考虑。模型B中可能缺少的一个元素是使用其他影响流量的交通变量的数据。阿纳克利托等。(2012)探索模型B的适应性,也关注曼彻斯特网络,该网络在预测流量时使用这些额外变量,实际上,该模型的校正效果更好,四个子变量的覆盖率约为95%,四个子模型的覆盖率大约为96%。
6.调节测量误差
6.1. 测量误差
为fork和join构建DAG和MDM时第4.1节,Y(Y)t吨(3) 和Y(Y)t吨(6) 都被建模为逻辑变量,没有错误。然而,正如数据在各种应用中的常见情况一样,回路检测器数据容易因设备故障而产生测量误差(参见陈等。(2003)和比克尔等。(2007))所以建模Y(Y)t吨(3) 和Y(Y)t吨(6) 因为逻辑变量在实践中可能不是一个现实的假设。
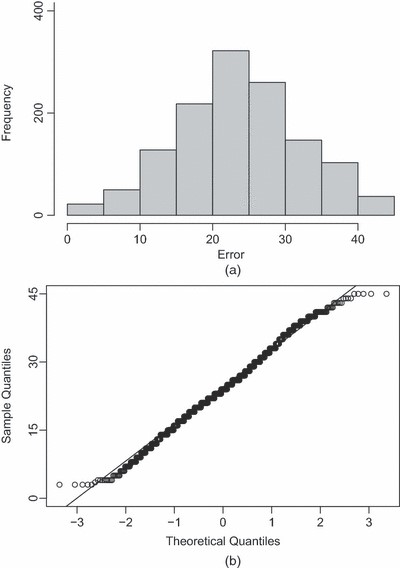
为了进行说明,考虑由1431A、1437A和6002A位组成的分叉图1(b)。如中所述第4节,这是不切实际的Y(Y)t吨(6002A)精确等于因为时间滞后效应。然而,在检查错误时很明显,建模Y(Y)t吨(6002A)作为逻辑变量确实过于简单。图11显示直方图和问–问-2010年9.00 p.m.至10.59 p.m.期间观察到的这些误差的曲线图,其中5%的极端误差被排除在曲线图之外。(删除了最极端的错误,因为这些错误将通过使用干预措施来保持预测性能来处理,因此在图中包含这些极端错误会给出错误的不切实际的图片。)图11(a)很明显,误差几乎都是正的,有一些显著的可变性,而问–问-在中打印图11(b)表明正态分布测量误差的假设对于95%的数据似乎是合理的,值得作为一个简单的模型考虑。
图11
(a) 直方图和(b)q–q-误差图在2010年晚上9点至10点59分期间(不包括5%的极端误差)
6.2. 调节测量误差
考虑一下图3(a).英寸第4.1节,站点布局和交通流方向表明可以很简单。一种可容纳测量误差的替代模型的形式如下
哪里是测量误差的水平,对于一些V(V)t吨(3). 作为来自的车辆S公司(1) 只能去S公司(2) 或S公司(3) ,为设置之前的平均值为1,先验方差较小。注意S公司(1) 和S公司(2) 通过模型参数和观测方差自动考虑V(V)t吨(1) 和V(V)t吨(2). 代表此新模型的DAG与图4(a)除了双椭圆(代表一个逻辑变量)现在是一个普通的单椭圆。
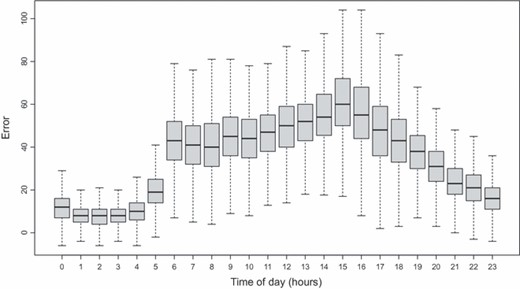
曼彻斯特网络中的误差分布实际上随时间而不同,如所示图12误差平均值遵循白天观察到的流量的通常模式(参见图2(a)). 为了说明这一点,可以使用季节因子模型与模拟μt吨(我)英寸第4.2节.图12还显示了一天中误差的变化。事实上,对于曼彻斯特网络,与流量本身一样,在7.00 p.m–6.59 a.m.和7.00 a.m.–6.59 p.m.期间,误差的平均值和方差的对数之间大致呈线性关系。因此V(V)t吨(3) 可以通过使用如表达式(6)所示的方差法则LMDM,结合动态演变的基础方差来调节V(V)(3) 如表达式(7)和(8)所示。
图12
错误方框图2010年
可以定义一个类似的模型,以允许连接中的测量误差。
6.3. 预测性能
使用模型(9)和无误差项的逻辑模型(如表达式(4)所示),对作为逻辑变量的根节点的四个子节点进行一步预测图5,即Y(Y)t吨(6002A),Y(Y)t吨(1445B),Y(Y)t吨(6002B)和Y(Y)t吨(9195A)。如中所述的方差定律和动态演化观测方差第5节用于每个模型。如前一节所述,2010年2月至4月的历史数据用于估计β-方差法模型的参数和用于获取先验信息的参数,而在线一步预测是针对2010年5月和6月的周三流量获得的。
使用这两种模型时,每个系列的中值SE显示在表2(LPL和MIS都不适合在此进行模型比较:如果没有错误,就无法计算模型的LPL,并且MIS不适合,因为错误模型自然具有更大的预测限制。)表2还显示了每个系列(在第四列和第五列中)相对测量误差的平均值和标准偏差(即100(当时观察到的测量误差t吨)/Y(Y)t吨(我)).
表2误差模型(9)和无误差项的逻辑模型的中值SE,以及相对测量误差的平均值和标准偏差
| 系列. | 以下型号的MedianSE:. | 相对测量误差. |
|---|
| 错误模型. | 逻辑模型. | 平均值. | 标准脱毛. |
|---|
| Y(Y)t吨(6002安) | 142 | 882 | 31.2 | 27.6 |
| Y(Y)t吨(1445B) | 969 | 1211 | 9 | 59.8 |
| Y(Y)t吨(6002B) | 180 | 159 | −1.2 | 8.1 |
| Y(Y)t吨(9195A) | 618 | 616 | 0.4 | 3.3 |
| 系列. | 以下型号的MedianSE:. | 相对测量误差. |
|---|
| 错误模型. | 逻辑模型. | 平均值. | 标准脱毛. |
|---|
| Y(Y)t吨(6002A) | 142 | 882 | 31.2 | 27.6 |
| Y(Y)t吨(1445B) | 969 | 1211 | 9 | 59.8 |
| Y(Y)t吨(6002B) | 180 | 159 | −1.2 | 8.1 |
| Y(Y)t吨(9195A) | 618 | 616 | 0.4 | 3.3 |
表2误差模型(9)和没有误差项的逻辑模型的MedianSE,以及相对测量误差的平均值和标准偏差
| 系列. | 以下型号的MedianSE:. | 相对测量误差. |
|---|
| 错误模型. | 逻辑模型. | 平均值. | 标准脱毛. |
|---|
| Y(Y)t吨(6002安) | 142 | 882 | 31.2 | 27.6 |
| Y(Y)t吨(1445B) | 969 | 1211 | 9 | 59.8 |
| Y(Y)t吨(6002B) | 180 | 159 | −1.2 | 8.1 |
| Y(Y)t吨(9195A) | 618 | 616 | 0.4 | 3.3 |
| 系列. | 以下型号的MedianSE:. | 相对测量误差. |
|---|
| 错误模型. | 逻辑模型. | 平均值. | 标准脱毛. |
|---|
| Y(Y)t吨(6002安) | 142 | 882 | 31.2 | 27.6 |
| Y(Y)t吨(1445B) | 969 | 1211 | 9 | 59.8 |
| Y(Y)t吨(6002B) | 180 | 159 | −1.2 | 8.1 |
| Y(Y)t吨(9195A) | 618 | 616 | 0.4 | 3.3 |
如图所示表2就MedianSE而言,就其中两个系列而言,错误模型的表现明显优于逻辑模型,而其他两个系列的表现稍差。与逻辑模型相比,误差模型使用方面改进最大的系列是相对测量误差较高的系列。然而,尽管当相对测量误差高时,误差模型在预测性能上给出了更大的改进,但高的相对测量误差也意味着结果预测的不确定性的增加,这意味着相对测量误差高的序列的预测极限比相对测量误差低的序列更宽。虽然在分叉处选择两个孩子中的哪一个应该被视为逻辑变量是任意的,但在做出决定时应该考虑每个孩子的相对测量误差。
与时变方差模型一样第5节,中每个(子)序列的预测限制表2高估了预测的不确定性,使用逻辑模型时每个序列的覆盖率约为97%,使用误差模型时每个序列的覆盖率约为99%。同样,这表明有一些因素(如额外的交通变量)影响了模型没有捕捉到的可变性。
当然,此处用于建模测量误差的正态模型只是一个简单的模型,其他分布可能更合适:例如,混合分布可能很好。然而,旅行者信息系统和一些交通管理系统需要实时预测,因此必须仔细考虑考虑其他错误建模方法的计算成本。
7.线性多元回归动态模型中的预测极限
当考虑预测图和观测值时,通常包括与预测相关的不确定性指示。本文将预测极限视为边际预测平均值±2×边际预测标准差。预测的不确定性通常由以这种方式计算的预测限表示。
对于正态分布的预测分布,大约95%的观测值应在这些预测限内,预测限约为95%(等尾)的预测区间。然而,LMDM中的边际预测分布不是正态的,而且通常无法进行分析计算。尽管马尔可夫链蒙特卡罗和序贯蒙特卡罗技术的最新进展可以实时模拟真实预测极限的估计,但基于边际预测矩的近似方法要简单得多,速度更快。但是,如果使用LMDM中的边际预测矩计算预测极限,那么剩下的一个问题是,与真实95%预测极限的近似值有多接近?
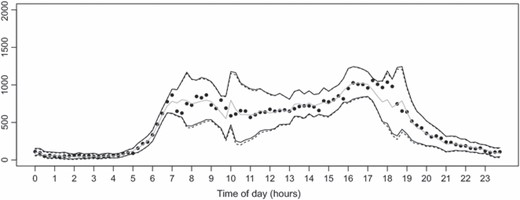
为了回答这个问题,再次考虑通过这个近似值获得的站点1437A的预测极限(如图10). 1437A场址边际预测分布的“真实”95%预测限为边际预测分布2.5%和97.5%的百分位。每次都可以估计t吨通过模拟:通过模拟母公司的联合预测分布来模拟边际预测分布的样本Y(Y)t吨(1431A)和儿童Y(Y)t吨(1437A)通过正态预测分布Y(Y)t吨(1431A)和条件正态预测分布Y(Y)t吨(1437A)|Y(Y)t吨(1431A)。
图13显示了基于边际矩的1437A场址的近似预测极限,以及基于模拟的估计真实预测极限。图13显示的日期与中考虑的日期相同图10其中存在一些不寻常的交通流,造成了高度的流量不确定性。可以看出,即使在预测存在很大不确定性的情况下,基于边际矩的预测极限实际上也接近模拟的真实极限——考虑到计算的简单性和速度,这无疑是一个非常好的近似值。当考虑中考虑的所有流量系列时表1,两个模型提供的预测间隔也具有类似的MIS。
8.最后备注
本文开发了多变量道路交通流数据预测模型,并将所提出的方法应用于特定网络中的预测问题。
引出了代表曼彻斯特交通网络的DAG和LMDM。开发了新的方法,允许多元时间序列中的时变观测方差,扩展了LMDM以纳入方差定律,并引入了允许个别方差动态演化的方法。还开发了一些方法,用于调节回路检测器数据中经常出现的不可忽略的测量误差。此外,该论文使用模拟来证实,通过使用(容易获得的)边际预测矩来近似的预测极限实际上接近于根据边际预测分布计算的(不那么容易获得的)真实预测极限的估计。
进一步研究的一个领域是开发使用额外交通变量的方法,这些变量与流量数据一起定期收集,例如平均速度、车头时距和占用率,以改进流量预测。虽然当前的多元交通预测模型通常不使用这些变量的附加信息,事实上,LMDM将多元模型分解为一组回归DLM,这意味着将这些变量合并到这个特定的多元模型中(使用交通变量和数据驱动方法之间的理论已知关系的组合)更简单。发展这些想法的研究可以在阿纳克利托等。(2012).
致谢
作者感谢公路局提供了本文中使用的数据,也感谢莫特·麦克唐纳的莱斯·莱曼对初步数据分析的宝贵讨论。作者还感谢联合编辑和一位裁判对该论文早期版本的建设性和有益评论。
工具书类
比克尔
,第页。
,陈
,C、。
,Kwon(千瓦)
,J。
,大米
,J。
,范·兹维特
,E.公司。
和瓦莱亚
,第页。
(
2007
)测量交通量
.统计师。科学。
,22
,581
–597
.双层
,F、。
,科芒德尔
,J。
,科普曼
,S.J.公司。
和范·蒙福特
,英国。
(
2010
)道路安全研究中暴露和风险的多元非线性时间序列建模
.申请。统计师。
,59
,145
–161
.卡瓦略
C.M.公司。
和西部
,米。
(
2007
)动态矩阵变量图形模型
.Baysn分析。
,2
,69
–98
.陈
,C、。
,Kwon(千瓦)
,J。
,大米
,J。
,斯卡巴多尼斯
,答:。
和瓦莱亚
,第页。
(
2003
)单回路监视系统的错误检测和缺失数据输入
.Transprtn资源回收。
,1855
,160
–167
.法罗
,米。
(
2003
)大型复杂系统主观协方差结构的实际构建
.统计员
,52
,553
–573
.福森
,J。
,弗金斯塔德
,E.公司。
,博根
,二、。
和阿伦
,订单。
(
2006
)动态路径分析——一种分析时间相关协变量的新方法
.利夫蒂姆。数据分析。
,12
,143
–167
.格奈廷
,T。
和拉夫特里
,答:E。
(
2007
)严格正确的评分规则、预测和评估
.《美国统计杂志》。助理。
,102
,359
–378
.郭
,西。
和棕色
,医学学士。
(
2001
)交叉相关结构时间序列模型
.统计师。罪。
,11
,961
–979
.卡马里亚纳基斯
,年。
,喀纳斯语
,答:。
和普拉斯塔科斯
,第页。
(
2005
)城市网络交通流波动动力学建模
.运输Res.Rec。
,1923
,18
–27
.卡马里亚纳基斯
,年。
和普拉斯塔科斯
,第页。
(
2005
)交通流的时空建模
.计算。地质科学。
,31
,119
–133
.米贡
,H.S.公司。
,加梅尔曼
,D。
,洛佩斯
,高频。
和费雷拉
,机械工程师。
(
2005
)动态模型。在统计手册
(编辑D。
戴伊
和C.R.公司。
饶
),第页。553
–588
阿姆斯特丹:爱思唯尔。女王
,C.M.公司。
(
1997
)竞争市场中的模型启发。在贝叶斯分析的实践
(编辑美国。
法语
和J·Q。
史密斯
),第页。229
–243
.伦敦
:阿诺德
.女王
,C、。 米。
和阿尔伯斯
,C、。 J。
(
2009
)干预和因果关系:使用动态贝叶斯网络预测交通流量
.《美国统计杂志》。助理。
,104
,669
–681
.女王
,C.M.公司。
和史密斯
,J·Q。
(
1993
)多元回归动态模型。J.R.统计。Soc.B公司
,55
,849
–870
.女王
,C、。 米。
,赖特
,B。 J。
和阿尔伯斯
,C、。 J。
(
2007
)为交通网络中车辆计数的多变量时间序列推导有向非循环图
.澳大利亚。新西兰。J.统计。
,49
,221
–239
.女王
,C.M.公司。
,赖特
,B.J.公司。
和阿尔伯斯
,C.J.公司。
(
2008
)线性多元回归动态模型中的协方差预测
.J.预测。
,27
,175
–191
.斯塔索普洛斯
,答:。
和卡拉夫提斯
,G.公司。 米。
(
2003
)城市交通流建模与预测的多元状态空间方法
.运输研究中心
,11
,121
–135
.太阳
,S.L.公司。
,张
,C.S.公司。
和于
,总质量。
(
2006
)交通流预测的贝叶斯网络方法
.IEEE传输。智力。运输系统。
,7
,124
–132
.泰巴尔迪
,C、。
,西部
,米。
和卡尔
,答:K。
(
2002
)高速公路交通流量的统计分析
.J.预测。
,21
,39
–68
.运输研究委员会
(2000
)公路通行能力手册
.华盛顿特区
:国家研究委员会
.弗拉霍吉安尼
,E.I.公司。
,戈利亚
,J.C.公司。
和卡拉夫提斯
,M.G.公司。
(
2004
)短期交通预测:目标和方法概述
.运输版次。
,24
,533
–557
.西部
,米。
和哈里森
,P.J.公司。
(
1997
)贝叶斯预测与动态模型
,第2版。纽约
:施普林格
.惠特洛克
,机械工程师。
和女王
,C.M.公司。
(
2000
)用缺失数据建模交通网络
.J.预测。
,19
,561
–574
.惠塔克
,J。
,Garside公司
,美国。
和林德维尔德
,英国。
(
1997
)跟踪和预测网络流量过程
.国际期刊预测。
,13
,51
–61
.
©2012皇家统计学会
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}