总结
我们基于竞争模型之间的差异度量,为假设检验和模型选择引入了客观合理的先验分布;我们叫他们基于分歧的(DB)之前。DB先验具有简单的形式和理想的属性,如信息(有限样本)一致性,通常与其他现有建议类似,如内在先验。此外,在正常的线性模型场景中,他们精确地再现了杰弗里斯-泽尔纳-西奥的先验。最重要的是,在不规则模型和混合模型等具有挑战性的场景中,DB优先级定义明确且非常合理,而备选方案则不然。我们推导了DB先验函数的近似值以及马尔可夫链蒙特卡罗和相关贝叶斯因子的渐近表达式。
1.简介
对于数据年,具有密度,我们考虑假设检验问题
(1)
哪里是已知值。这相当于在模型之间进行选择的模型选择问题:
(2)
其中符号反映了以下事实和通常表示每个模型中的不同数量。在杰弗里斯的场景中(杰弗里斯(1961),第5章),和含义相同;他打过电话θ这个新参数、和和这个通用参数(也称为干扰参数)。我们在第4节.
我们的目标是客观贝叶斯这个模型选择问题的解决方案,即不需要先验分布的主观规范。对于模型不确定性问题,贝叶斯方法,特别是客观贝叶斯算法的优点的一个很好的解释是伯杰和佩里奇(2001).
的常用贝叶斯解决方案损失函数(伯杰,1985年)对于问题(1)(或等价地,对于问题(2)),基于后验概率:
哪里,是假设的先验概率,以及是贝叶斯因子对于反对:
(3)
哪里是前一个和之前的under,即。是模型的边际(平均)可能性的比率。
客观贝叶斯方法通常集中于贝叶斯因子的推导,将先验模型概率(以及后验概率的推导)的最终选择(无论是客观的还是主观的)留给用户。贝叶斯因子被广泛用于杰弗里斯(1961)作为支持模型的证据度量(另请参见伯杰(1985),Berger和Delampady(1987)和伯杰和塞尔克(1987));卡斯和拉弗瑞(1995)是审查和应用的良好参考。贝叶斯因子也是模型平均方法的关键要素(参见克莱德(1999)和休庭等。(1999)). 在本文的其余部分中,我们集中于推导计算贝叶斯因子的客观先验。
推导客观贝叶斯因子的一个主要问题是:和用于方程式(3)众所周知,(在固定模型下)估计问题常见的不恰当客观先验(或非信息先验)在存在模型不确定性时通常严重不足,通常会产生任意答案。(研究了有趣的例外情况伯杰等。(1998)当然,当不能使用不恰当的先验信息时,使用任意模糊(但适当的)先验信息并不能解决问题,通常情况下甚至更糟。在实践中经常遇到的另一个糟糕的解决方案是使用明显“无害”、无害但武断的适当先验,因为它可以以意料之外的方式严重控制可能性(并且无法针对高维问题进行调查)。
当没有足够的信息可用于可靠的主观评估时,有两种计算贝叶斯因子的基本方法和一种非常成功的方法是直接推导客观贝叶斯因子本身,通常通过各种“训练”和校准从通常的客观不适当先验中获得的未标度贝叶斯因数(参见伯杰和佩里奇(2001)供审查和参考)。然而,所有这些客观的贝叶斯因子最终都应进行检查,以对应(近似)从合理先验中导出的真实贝叶斯因素。另一种方法是寻找“形式规则”来构建“客观”但适当的先验,这些先验具有良好的性质,适合用于模型选择;然后根据这些客观固有先验值计算贝叶斯因子。然后,可以根据所使用的先验信息的充分性直接判断这些贝叶斯因子是否合适。
模型不确定性场景中先验分布的选择在很大程度上仍是一个悬而未决的问题,只有部分答案是已知的。已经提出了几种用于一般场景的方法:算术内在先验(伯杰和佩里奇,1996年;莫雷诺等。, 1998); 分数阶内禀先验函数(O'Hagan,1995年;De Santis和Spezzaferri,1999年;伯杰和莫特拉,1999年); 预期后验(佩雷斯和伯杰,2002年); 单位信息优先级(Kass和Wasserman,1995年)和预测匹配的先验值(易卜拉欣和劳德,1994年;劳德和易卜拉欣,1995年;伯杰等。, 1998;伯杰和佩里奇,2001年). 在线性模型的特定上下文中,Jeffreys–Zellner–Siow(JZS)prior是广泛使用的具有良好属性的prior(杰弗里斯,1961年;Zellner和Siow,1980年、1984年;巴亚里和加西亚-多纳托,2007年). 一个有趣的概括是克-前科(梁等。, 2008).
所有这些方法都很有见地,提供了许多有趣和有用的想法,并且在许多测试和模型选择问题中表现得很好。尽管如此,除了非常具体的线性模型场景外,似乎没有人研究杰弗里斯(1961)开创性的提议(见结尾第2节). 事实上,他是第一个对假设检验的客观先验进行一般推导的人,旨在概括他关于检验正态均值的建议。鉴于线性模型之前Jeffreys测试的推广成功(Zellner和Siow,1980年、1984年;巴亚里和加西亚-多纳托,2007年)令人惊讶的是,他的一般性建议没有被采纳。我们认为进行这项调查具有重要的历史意义,我们在本文中就是这样做的。
具体来说,我们推广了Jeffreys的开创性建议,并使用竞争模型之间的差异度量来推导所需(适当)的先验。我们称这些为院长基于分歧的(DB)之前。主要动机是将有用的JZS先验推广到除正常线性模型以外的场景中,同时扩展Jeffreys的一般建议。我们将证明,在线性模型上下文中,DB先验确实是JZS先验;它们也与其他流行的建议(算术内禀、分数内禀或预期后验先验)一样容易推导(而且往往比它们更容易),在许多情况下与它们非常相似;最有趣的是,在所有其他提案都失败的某些情况下,它们都得到了很好的定义。然而,正如这里所定义的,我们的建议仅适用于嵌套模型(如问题(2)),而其他建议(如分数和内在方法)则没有此限制。
为了表达的清晰,我们首先考虑没有干扰参数的情况。一般情况的发展要等到第4节,一旦引入了基本思想,并在这个简单得多的场景中研究了DB prior的行为附录A.
2.基于差异的先验知识
首先假设问题没有干扰参数:
(4)
即更简单的模型不涉及未知参数;因此,仅为θ在下面需要。我们删除了上一节中的子索引,并通过以下简单方式表示这样的先验;很明显,必须正确。
我们的DB建议书θ将根据竞争模型之间的差异度量和基于Kullback–Leibler(KL)定向发散
(5)
(假设连续年简单起见)。当然,还可以探索其他分歧衡量标准。我们的特定选择不仅受其理想属性的指导,还因为它导致了Jeffreys测试先验的推广。
我们不直接使用KL发散来定义DB先验,因为它的参数不对称,因此可能会导致非对称先验;然而,对称的散度度量可以通过求和(这是Jeffreys的选择)或KL散度的极小值来导出。我们定义
(6)
和
(7)
我们将定义中的最小值乘以2使这两项措施的规模相同;事实上,在一些对称模型中(比如在正常情况下)方程式(7)和方程式(6)重合。KL的推广,和要包含边际参数,请参见第4节。请注意即使其中一个定向KL发散点不存在,也会得到很好的定义,这就是竞争模型具有不同支持的情况。除了这些不正常的情况,定义明确,推导起来比。要遵循的大多数派生和属性对两者都是通用的和。为了避免冗长的重复,我们只需使用D类指代其中任何一个。我们只在必要时使用上标S或M。
我们的建议是基于分歧的统一度量,,我们认为是D类除以有效样本数 ,在简单的单变量独立同分布(IID)数据中,有效样本大小等于标量数据点的数量,但通常不需要这样。事实上,在复杂的情况下,这可能是一个困难的概念;尽管文献中已经有多次尝试将其形式化(参见示例保勒(1998),保勒等。(1999)和伯杰等。(2008)),似乎没有公认的定义。在本文的所有示例中,很明显应该是这样的,所以对于这个介绍性分析,我们依赖于简单直观的解释。
2.1动机:标量位置参数
假设年是来自单变量位置族的随机样本.有人争论过(Berger和Delampady,1987年;伯杰和塞尔克,1987年)在对称问题中,客观测试之前在下面应为单峰且对称;这些先验信息防止了对。因此,我们寻找合适的在这个简单的场景中,它具有这些理想的特性,并且很容易推广到其他情况。
如前所述,让成为单一的对称发散。我们对测试优先级的基本建议是,其中小时是一个适当选择的递减函数。我们建议使用对于特定的选择q个,即
(8)
因此,,我们建议在此位置问题之前使用DB
(9)
其中规范化常数定义良好。向量值的推广θ是微不足道的。请注意直接定义小时不能保证产生正确的先验。我们的具体建议和用于添加到,被选为在正常语境中重现之前的著名JZS;此外,这些选择会导致具有重尾的密度,这是测试先验的理想特性。
它很容易从D类那个是单峰的,周围对称,从而在这些位置问题中获得所需的属性。
2.2一般参数
假设更一般的问题(4),并让成为客观的(通常是不恰当的)“估计”先验(例如参考、不变量、Jeffreys或统一先验)θ,并让ξ是这样一种转变对于。然后我们可以在θ通过考虑ξ作为“位置参数”,应用定义(9),并转换回θ。此转换最初由提出杰弗里斯(1961),第3章。伯纳多(2005)将其与之前的引用一起使用对于标量θ并指出ξ渐进地表现为位置参数。我们稍后将说明,我们不需要显式推导它。
给ξ位置参数之前的数据库导致
(10)
如前所述,表示之间的“单位”(对称)差异和、和.由于在重新参数化下θ是
(11)
只要在变换下也是不变的;是相应的雅可比矩阵。我们现在可以正式定义提议的DB优先级。我们首先对它们进行一般性定义,然后针对我们建议的特定选择进行定义。
定义1(一般DB之前)。 对于模型选择问题(4),让是之间分歧的统一度量和。也让是一个客观(可能不恰当)的估计θ在复杂模型下,并让是一个递减函数,由.定义
如果,让并在下定义数据库作为
(12)
注意,根据定义,DB prior要么不存在,要么是正确的(因此它们不涉及任意常量)。还要注意转换的显式派生ξ这样的话是不需要定义数据库优先级。
定义1非常通用,因为,和可以探索(以及不同的选择在里面。我们给出了一些具体的选择,这些选择在一定程度上是基于先前的探索和结果的期望属性然而,我们的具体选择主要是为了在正常情况下重现JZS先验,因此我们对DB先验的建议可以作为JZS优先于非正常情况的扩展来考虑。在以下内容中,我们采用D类要么是在里面方程式(6)或在里面方程式(7)、和.
定义2(之前的总金额和最低DB)。 之前的总和DB以及之前的最小DB是定义1中给出的DB优先级和D类分别是(请参见方程式(6))和(请参见方程式(7)).
可以很容易地表明,对于常规问题(其中),存在意味着反之亦然。一般来说,我们建议使用sum DB优先当它存在时,不仅因为它比之前的最小DB更容易计算但也因为它有更好的行为。有关更完整的参数,请参见巴亚里和加西亚·多纳托(2008).
总和和最小DB优先级的定义基于两者的特定选择
- (a)
“目标优先”估计问题和
- (b)
等效样本量.
当然,文献中对这些概念中的任何一个都没有一个单一的定义达成一致(可能永远不会)。我们认为,任何明智的建议都会产生良好的结果,但这需要进一步调查。我们建议在可能的情况下使用参考优先权(伯杰和伯纳多,1992年)和同等样本量伯杰等。(2008)(我们一般不建议常规使用naive除非没有更好的选项。)
现在,我们使用符号研究一般DB prior的一些吸引人的属性涵盖定义2中规定的两种类型的优先权。
2.2.1基于分歧的先验信息的局部行为
假设θ是k个维度的。很容易检查,当(就像什么时候一样θ是位置参数),则模式为是(所以以最简单的模型为中心)。我们还可以利用KL散度和Fisher信息之间的以下(众所周知的)近似关系(参见库尔贝克(1968),第2章):针对θ在…附近,
哪里预期费希尔信息矩阵的评估因此,在,数据库先前的行为大致类似于k个多元学生分布,以,按比例缩放和自由度,即。,其中此外,根据,上面的值通常接近于1,那么DB先验值将近似为柯西分布。如中所示第4.3.2节,上述近似值在正常情况下完全适用因此,DB之前准确复制了JZS提案。
2.2.2一对一变换下的不变性
一个重要的问题是,在对问题进行重新参数化时,DB优先级是否不变。假设是一对一单调映射.模型选择问题(4)现在变成
(13)
哪里和下一个结果显示,如果在重新参数化下是不变的DB之前的版本也是如此。
提议1。让和分别表示原始(4)和重新参数化(13)问题的DB优先级。如果,其中是转换的雅可比矩阵,那么.
在命题1的条件下,从DB先验值计算的Bayes因子不受重新参数化的影响。值得注意的是,DB先验的不变性是所用散度测度不变性和.一些客观先验在重新参数化下不变的是Jeffreys先验和(部分)参考先验。
2.2.3与充分统计的兼容性
DB prior有时通过足够的统计数据与数据缩减兼容。其他客观贝叶斯方法(如固有贝叶斯因子)不具备这一吸引人的特性(尽管如果贝叶斯因素直接从固有先验中导出,则该特性成立)。
提议2。让是足够的统计数据θ在里面带分发.假设和在定义的问题中保持不变;然后是之前的DB对于原始问题(4),与减少(通过充分性)测试问题之前的DB相同
(14)
这个证明很容易,而且被省略了。
2.2.4基于差异的先验和Jeffreys的一般规则
杰弗里斯(1961)提出了测试非正态均值情况的客观正确先验。具体来说,当年是大小的随机样本n个,对于单变量θ,他之前提出了以下模型测试:
(15)
当杰弗里斯的柯西建议θ是正常平均值。此外,当很小,可以近似为,其中是Jeffreys(估计)的先验(即预期Fisher信息的平方根)。
请注意可能会导致不正确的先验,并且可能不适用于多变量参数。然而,上述近似值是DB prior定义的主要灵感,它们之间有明显的相似性。
3.比较示例:简单零模型
本着伯杰和佩里奇(2001)在本节中,我们研究了DB prior在一系列情况下的性能,这些情况被选为更广泛类别的统计问题的代表。我们还明确推导了贝叶斯假设测试中客观先验的成熟备选方案,并将其性能与DB先验进行了比较。我们表明,在简单的标准情况下,DB prior具有非常好的属性,并产生与这些备选方案类似的结果。更有趣的是,在这些建议失败的更复杂的情况下(具有不规则渐近或不适当可能性的模型),DB先验是定义良好且非常合理的。
我们计算并比较了用DB先验函数导出的贝叶斯因子,以及用两个最常用的通用客观先验函数推导的贝叶斯模型选择贝叶斯系数,即
在IID样本情况下,产生算术固有贝叶斯因子(伯杰和佩里奇,1996年)、和这个分数贝叶斯因子(O'Hagan,1995年)如果似然指数为对于固定米(请参见De Santis和Spezaferri(1999)). 根据的建议伯杰和佩里奇(2001),我们采取米最小训练样本的大小.
在本节的示例中,年是IID样本n个从并且除非另有规定,表示有效样本量)。我们让表示有利于使用计算(见定义2);和定义类似。
为了进行比较,我们研究了贝叶斯因子的一个理想属性,当使用共轭先验计算它们时,这些属性通常会失败(参见伯杰和佩里奇(2001)). 很自然,对于任何给定的样本量,作为反对更简单模型的证据变得势不可挡。当这个属性成立时,我们说贝叶斯因子是证据一致(或有限样本一致)。我们还调查了不同贝叶斯因子的行为,作为支持生长。
3.1比例参数(示例1)
我们首先考虑一个测试比例参数的简单示例。具体来说,我们认为这些数据是IID指数,平均值为μ,即。对于和,我们想测试 与 .在这里,且DB优先级计算为
哪里
引理1给出了内在先验(证明很简单,省略了)。
引理1。算术和分数固有先验是
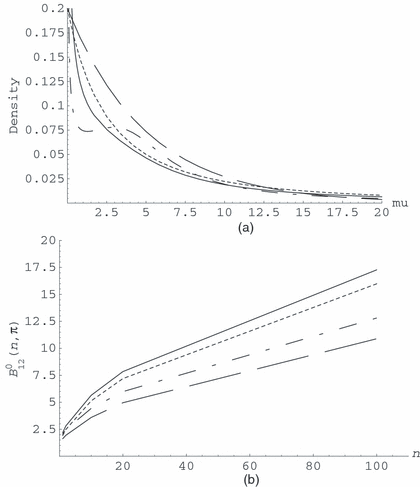
四个优先项如所示图1测试时它们都有相似的形状。(适当的)DB先验具有0的渐近线,这对于尺度参数的客观先验很常见;有点不寻常的形状是由于特定的参数化(使用生成更熟悉的形状)。
图1。
(a),,和用于指数测试和(b)上限贝叶斯因子的函数n个对于之前的,,和
一些有趣的特性值得注意(记住,没有力矩和重尾是测试先验的理想特性)。
- (a)
在对数刻度中和周围对称(单峰);这符合Berger和Delampady(1987)和伯杰和塞尔克(1987)提案,自是(渐近地)一个位置参数。
- (b)
所有四个前题都是正确的。
- (c)
算术内禀和DB先验都没有矩;分数包含所有的矩。
- (d)
尾巴最重最薄的。尾巴比.
- (e)
所有四个先验值都“居中”于空值;的确,是DB之前和,这是(指数密度)。
在巴亚里和加西亚·多纳托(2008),相应的贝叶斯因子针对各种情况进行计算。我们发现四个前驱的结果非常相似和为模型提供稍微更多的支持比和当数据与兼容时.
我们调查证据一致性下一步。很容易证明,如果,然后,无论使用什么先验来计算贝叶斯因子。以下引理为什么时候。证据出现在附录A.
引理2。让是使用计算的贝叶斯因子作为,对于所有人当且仅当
(16)
由此可见,所有四个优先考虑生产证据一致所有人的贝叶斯因素顺便说一句,有趣的是,如果我们使用具有在定义1中,不会有一致的证据.
最后,我们研究了作为支持模型的证据增长(即). 对于这个例子,很容易看出,当,增长到一个常数,比如说,这只取决于n个以及先前使用的。在图1我们展示对于所考虑的四个优先事项。可以看出是产生最大值的先验值对于的所有值n个,与那些紧跟其后。(当然,作为.)
3.2位置-比例(示例2)
通常为向量参数定义DB优先级θ作为一个例子,我们接下来考虑一个更常见的例子,即正态分布;这里是二维的θ有两个不同性质的组件(位置和规模)。具体来说,假设,我们想测试 与 .
为了计算DB优先级,我们使用引用优先级;我们获得之前的总DB,其中
其中Ca表示柯西密度。在本例中,最小DB优先不存在。可以检查到周围对称,它是中的位置参数是中的比例参数.
接下来导出了形式更简单、尾部更薄的固有先验函数(省略了证明)。
引理3。算术内在先验是,使用
在分数阶固有先验下和σ是独立的先验的有边缘的
哪里表示截断为正实线的法向密度。
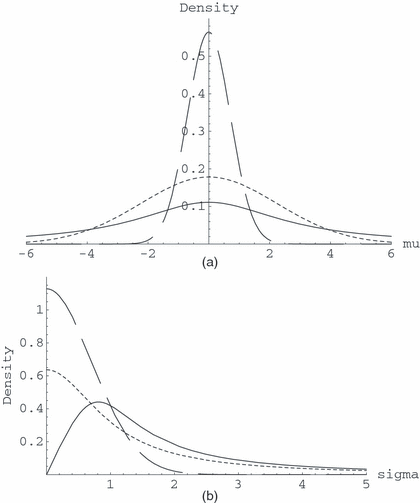
两个内在先验都是适当的;此外,与之前的总和DB一样,和是的位置和比例参数和σ分别是。分数先验的尾部是最薄的(这种差异对于先验特别显著σ). 中探讨的示例巴亚里和加西亚·多纳托(2008)产生相应的贝叶斯因子和非常相似,然而在某些情况下可能会有明显的不同。
之前的三次,在图2我们显示了σ(图2(b))和的条件分布μ鉴于σ(图2(a)). 可以清楚地看到尾巴比和。此外,的所有条件优先级μ围绕其模式对称,使用有最重的尾巴。注意,算术内禀和DB先验是最相似的;这种行为发生在我们所探索的大多数例子中。
图2。
测试前条件分布( ),和属于μ鉴于σ=3和(b)边际分布(),和属于σ(这些边缘的对(模式、中位数)为(0.81、1.56)对于和(0,0.48)用于)
),和属于μ鉴于σ=3和(b)边际分布(),和属于σ(这些边缘的对(模式、中位数)为(0.81、1.56)对于和(0,0.48)用于)
关于贝叶斯因子的证据一致性,很容易证明,当或(针对模型的证据非常强壮),那么,,以及所考虑的三个先验。当证据支持模型时是最大的(即。可以看出,贝叶斯因素有利于增长到一定的常数,它仅是的函数n个和之前使用的。图3说明了其速率作为可以清楚地看到,DB和算术内在先验的行为非常相似,对支持模型的证据更加敏感比分数优先,除非n个非常小。
图3。
上限贝叶斯因子的函数n个对于之前的,和
3.3不规则模型(示例3)
有一类重要的模型,其参数空间受数据约束。这些模型没有规则的渐近性,因此基于渐近理论的解决方案(如贝叶斯信息准则BIC)不适用。此外,这些模型对内在方法非常具有挑战性;事实上,正如伯杰和佩里奇(2001),分数贝叶斯因子是完全不合理的(因此分数固有先验是无用的),而算术固有先验(仅针对单边问题推导)是“一种推测”(伯杰和佩里奇(2001),逐字记录). 这里我们采用最简单的此类模型,即位置未知的指数分布。因此,假设,并且我们想要测试 与 。据我们所知,文献中没有针对该测试问题提出客观的先验。
在这些情况下,和对称的KL散度是∞,所以我们必须使用最小值。可以检查一下这是一个定义明确的分歧。也,自从θ是位置参数。最小DB先验值由下式给出
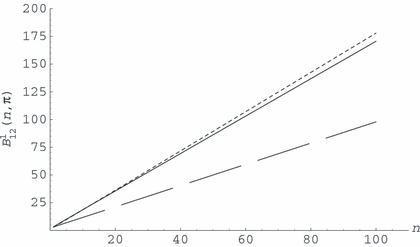
相对于(正如预期,因为θ是位置参数);也,没有片刻。图4(a)显示什么时候.
图4。
(a) 不规则示例用于双面测试和(b)案件的不规则单边测试问题
接下来我们将调查任何n个。足够的统计数据是。事实上,作为对于任何(适当的)先前(事实上,对于). 下一个引理提供了产生证据一致性之前的充分条件,何时;证明如下附录A.
引理4。让(在模型上)是任何适当的先验)和是相应的贝叶斯因子。如果是某个整数
(17)
然后作为.
从引理3可以得出生产证据一致贝叶斯因子.增加证据的行为赞成模型的与前一示例非常相似,未进行描述(请参见巴亚里和加西亚·多纳托(2008)详细信息)。
如前所述,文献中似乎没有关于双边测试问题的任何其他建议。然而,伯杰和佩里奇(2001)考虑过“单边测试”版本,即测试 与 ;他们推测这个问题的算术内在先验是适当的密度
它是一个递减的无界函数θ。我们接下来将此问题之前的最小DB与伯杰和佩里奇(2001)建议。
虽然我们最初的公式似乎是双边测试(见问题(1)),但实际上它足以定义Θ适当地覆盖其他测试情况。例如,在我们的单面测试中,我们。之前的最小DB为
可以检查一下满足条件(17)因此产生证据一致的贝叶斯因子.院长和显示在图4(b)。我们再次发现DB尾巴更厚。
在这种单边测试场景中(与双边测试中的行为形成鲜明对比),贝叶斯因素有利于模型对于每个会增长到∞(而不是取决于n个)作为支持的证据生长。的确,什么时候,无论使用什么先验值。注意,这里,位于参数空间的边界上。
在表1,我们生成用和什么时候对于各种值、和用于和。对于较小的值,当证据支持模型时远大于从而为。对于更大的值T型(即当数据与模型相矛盾时)这两个先验都会产生非常相似的贝叶斯因子。
表1 不规则模型,单侧测试:值对于各种值T型和n个以及之前的两次和,测试时
| T型. | 的结果 . | 的结果 . |
|---|
| . | . | . | . | . |
|---|
| 0.02 | 46.56 | 11.54 | 41.96 | 10.52 |
| 0.05 | 16.66 | 5.16 | 12.65 | 4.04 |
| 0.10 | 6.83 | 2.57 | 3.75 | 1.50 |
| 0.20 | 2.19 | 1.02 | 0.55 | 0.28 |
| 0.50 | 0.16 | 0.10 | 0.002 | 0.002 |
| 1 | 0.002 | 0.001 | | |
| T型. | 的结果 . | 的结果 . |
|---|
| . | . | . | . | . |
|---|
| 0.02 | 46.56 | 11.54 | 41.96 | 10.52 |
| 0.05 | 16.66 | 5.16 | 12.65 | 4.04 |
| 0.10 | 6.83 | 2.57 | 3.75 | 1.50 |
| 0.20 | 2.19 | 1.02 | 0.55 | 0.28 |
| 0.50 | 0.16 | 0.10 | 0.002 | 0.002 |
| 1 | 0.002 | 0.001 | | |
表1 不规则模型,单侧测试:值对于各种值T型和n个以及之前的两次和,测试时
| T型. | 的结果 . | 的结果 . |
|---|
| . | . | . | . | . |
|---|
| 0.02 | 46.56 | 11.54 | 41.96 | 10.52 |
| 0.05 | 16.66 | 5.16 | 12.65 | 4.04 |
| 0.10 | 6.83 | 2.57 | 3.75 | 1.50 |
| 0.20 | 2.19 | 1.02 | 0.55 | 0.28 |
| 0.50 | 0.16 | 0.10 | 0.002 | 0.002 |
| 1 | 0.002 | 0.001 | | |
| T型. | 的结果 . | 的结果 . |
|---|
| . | . | . | . | . |
|---|
| 0.02 | 46.56 | 11.54 | 41.96 | 10.52 |
| 0.05 | 16.66 | 5.16 | 12.65 | 4.04 |
| 0.10 | 6.83 | 2.57 | 3.75 | 1.50 |
| 0.20 | 2.19 | 1.02 | 0.55 | 0.28 |
| 0.50 | 0.16 | 0.10 | 0.002 | 0.002 |
| 1 | 0.002 | 0.001 | | |
3.4混合料模型(示例4)
混合模型是客观贝叶斯方法最具挑战性的场景之一。这些模型有不适当的可能性,即没有不适当的先验产生有限边缘密度的可能性(综合可能性)。最近,佩雷斯和伯杰(2001)已使用预期后验(请参见佩雷斯和伯杰(2002))推导客观估计先验,但基本上似乎没有通用的方法来推导客观先验,以便用这些模型进行测试。
然而,散度度量定义得很好(尽管现在更涉及积分),在用于模型选择之前提供了一个合理的DB。我们考虑一个简单的例子。假设
和测试 与 ,其中已知(如果,这两个假设定义了相同的模型)。作为伯杰和佩里奇(2001)指出,该问题没有最小训练样本,因此无法定义固有贝叶斯因子。分数贝叶斯因子也不存在。对于这个问题,我们唯一知道的是伯杰和佩里奇(2001)使用的.
虽然没有正式的在这里,通常假设(参见示例佩雷斯和伯杰(2002)). 可以看出不存在,但之前的总和DB确实存在。然而,(因此归一化常数)不能以封闭形式导出。当然可以使用数值程序计算,但我们推导了拉普拉斯近似值(参见坦纳(1996)). 由于有效样本量的自然选择是,我们获得
在给出之前,我们使用它来推导(近似)DB的建议,模式为0。
这种近似特别有吸引力,因为它还保留了所建议的散度测度的基本性质,因此也可以解释为从定义1派生不同的发散测度该近似的适用性及其一些性质在巴亚里和加西亚·多纳托(2008).
有趣的是,之前接近柯西密度,这是伯杰和佩里奇的建议,尽管规模不同。如所示巴亚里和加西亚·多纳托(2008),其中几个关键比较,其Cauchy近似和伯杰和佩里奇(2001)之前也考虑了。在这个例子中,DB之前(以及Berger和Pericchi提案)再次为所有人生成证据一致的贝叶斯因子n个事实上,可以证明,如果s趋于∞或则无论使用何种先验,相应的贝叶斯因子都趋于0。
4.干扰参数
在本节中,我们将讨论更现实的问题,其中数据的分布不是在空(最简单)模型下完全指定的,而是取决于一些讨厌的参数。假设,,是独立的(不一定是IID),并且。我们想测试 与 等效地,我们想解决模型选择问题(2),其中明确承认ν在每个模型中可以有不同的含义。
然而,从现在开始,如果需要,在进行适当的重新参数化后,我们假设θ和ν是正交的(即Fisher信息矩阵是块对角线)。因此,习惯上认为ν在两种模型下具有相同的含义(参见伯杰和佩里奇(1996)用于渐近证明)。这将有助于差异度量具有直观的含义,也有助于在ν在这两种模型下,大大简化了评估任务。正交参数在存在模型不确定性的情况下的适用性首先通过杰弗里斯(1961)并被许多其他人成功使用(参见示例Zellner和Siow(1980年、1984年)和克莱德等。(1996)). 对于单变量θ,考克斯和里德(1987)明确提供了一个正交重参数化。
因此,我们假设上述假设检验问题等同于在竞争模型之间进行选择:
(18)
哪里是指定值,并且ν(该旧参数在Jeffreys的术语中)被认为是这两种模型的共同点,其区别仅在于新参数θ模型下.
4.1分歧措施
之间差异的基本度量θ和也是KL定向散度(5),其中ν被认为是相同的在两种型号中:
使用相同的ν只有当ν在两种模型下具有相同的含义,因此可以认为是通用的。事实上,佩雷斯(2005),使用几何参数,表明在正交性下可以解释为衡量和仅由于感兴趣的参数θ这一解释不适用于其他分歧度量,如中定义的内在损失分歧贝尔纳多和鲁埃达(2002).
类似于第2节,我们通过将KL定向发散相加或取其最小值来对称化KL定向散度,从而在θ和对于给定的ν
(19)
和
(20)
由使用佩雷斯(2005)来定义他所说的“正交固有损耗”。
在下文中,许多定义和属性都适用于和,在这种情况下,我们再次使用D类通常表示它们中的任何一个。它们的基本特性在中进行了讨论第2节和以前一样,DB previor的构建块是发散的酉测度 ,其中是的有效样本量θ.
4.2存在干扰参数时基于差异的先验
用于测试 与 ,或在模型之间进行等效选择和在表达式(18)中,我们需要先决条件模型下和在下面.
本着杰弗里斯(以及其他许多追随者)的精神,我们(在每个模型下)相同的公共参数的客观先验(可能不合适)ν以及新参数条件分布的适当先验模型下,其推导类似于第2.2条。自ν发生在两个模型中,如果我们取相同的在这两种情况下,当计算贝叶斯因子时,(公共)任意常数将被抵消;然而,θ,仅出现在模型中,必须具有适当的优先级。旧参数的通用先验只有在以下情况下才有意义ν在两种模型中具有相同的含义(这是另一个原因θ和ν和我们一样正交)。此外,众所周知,在正交性下常见的在…之前ν对产生的贝叶斯因子几乎没有影响(参见杰弗里斯(1961)和Kass和Vaidyanathan(1992)),从而支持对公共参数使用客观先验。
让作为模型的目标(通常是Jeffreys或参考)然后让是模型的对应项(θ如果使用之前的引用,则会引起兴趣)。我们定义 这样的话。要定义数据库优先级,请使用D类要么是方程式(19)或方程式(20)(还可以探索其他适当的分歧措施);然后我们有以下定义。
定义3(一般DB之前)。 让
如果,的D类-模型下的DB先验是、和在模型下是,其中(适当的)是
在这个定义中,我们隐含地使用了推荐的非增量函数,但上的其他非增量函数可以探索。
定义4(之前的总金额和最低DB)。之前的总和DB以及之前的最小DB是定义3中给出的DB优先级D类分别是(请参见方程式(19))和(请参见方程式(20)).
在没有干扰参数的情况下,我们建议尽可能提前使用总和DB。总的来说,它们往往表现出更好的行为,并且更容易衍生。仅当不是有限的我们建议使用.
接下来,我们将研究这些DB先验函数在某些重新参数化下是否也是不变的。假设和分别是一对一单调映射和显然,重新参数化保持正交性。与单变量情况类似,可以看出,如果和在这些重新参数化下是不变的,DB prior也是不变的。请参见Datta和Ghosh(1995)详细分析了存在干扰参数时几个非信息先验的不变性。
因此,DB Bayes因子(使用DB先验计算的Bayes系数)不受所考虑类型的重新参数化的影响。这些是测试问题最自然、最有趣的重新参数化(实际上,其他重新参数化似乎有问题)。此外,DB优先级与命题2中的充分还原兼容。
4.3示例
接下来,我们将在几个示例中演示DB prior和相应Bayes因子的行为。首先是测试伽马模型的平均值,这通常是一个困难的问题。第二部分简要讨论线性模型。
4.3.1伽马模型(示例5)
让是伽马密度的IID样本,具有平均值μ、和形状参数α,即来自
我们想测试一下 与 .
很容易证明μ与…正交α.目标(参考)优先级为和,其中表示digamma函数。因此.
DB之前在假设和D类求和或求最小散度。低于,的条件和DBμ是
条件最小DB优先为
哪里
相应的贝叶斯因子在巴亚里和加西亚·多纳托(2008)并且显示非常相似。
与DB prior相比,在这个示例中派生内在prior看起来像是一项非凡的任务,我们未能获得它们的闭合形式表达式。巴亚里和加西亚·多纳托(2008)将DB贝叶斯因子与内在算术贝叶斯因子进行比较(请参见伯杰和佩里奇(1996)). 我们发现,当模型没错,这三项指标相当接近。当“null”模型为真,方差适中。在所有这些情况下,这三项措施为真正的模型提供了支持。然而,当为真且方差较小,DB Bayes因子非常合理(为null模型提供最大支持),但不是,支持模型.这种行为可能是由于众所周知的当样本量较小时(在这种情况下,由于方差较小而恶化)。
4.3.2线性模型中的变量选择(示例6)
接下来,我们简要展示了本文的激励示例;具体来说,我们展示了DB先验如何再现线性模型中变量选择的JZS先验。线性模型中更完整的测试示例可以在巴亚里和加西亚·多纳托(2007)中给出了随机效应的DB先验值推导加西亚·多纳托和太阳(2007).
考虑满秩一般线性模型以及测试问题.在通常的正交重新参数化后(参见示例Zellner和Siow(1984))和,DB优先级为(总和和最小值)
哪里是的尺寸和、和.
注意,只有当有效样本量为。这种“巧合”是具体选择在DB prior的定义中(参见加西亚·多纳托(2003)详细信息)。然而,可能取决于设计矩阵(或协变量)。例如,在线性模型中,使用和θ很明显,如果然后应该是n个但是,如果具有ɛ很小,那么应为1。中定义的有效样本量伯杰等。(2008)满足此要求,但其他定义可能不满足。对这个问题的深入调查超出了本文的范围,将在其他地方进行。
由于文献中广泛出现了线性模型的现有客观贝叶斯测试程序之间的比较,包括用JZS先验值导出的贝叶斯因子,因此我们在此跳过它们(参见示例伯杰等。(2003),梁等。(2008)和巴亚里和加西亚·多纳托(2007)).
5.近似值和计算
在本节中,我们推导了DB之前的简单近似值,并展示了它们与现有提案的联系。我们还利用了DB Bayes因子和用通常(可能不合适)的非信息先验计算的修正Bayes系数之间的联系,提出了简单的DB Baye因子的马尔可夫链蒙特卡罗计算。
5.1基于近似发散的先验
众所周知(参见库尔贝克(1968))通过使用预期的Fisher信息,KL散度测量值可以近似到二阶,因此
哪里是Fisher信息矩阵中对应于θ,评估时间因此,对于问题(18)(回忆一下θ和ν正交),DB优先(或或)可以近似为和
(21)
其中建议是、和是的下确界q个-表达式(21)中定义的条件密度(现在用Fisher信息表示)适用的值。
当不依赖于θ(所以θ作为位置参数的渐近行为)特别有趣。很容易证明,其中k个是的尺寸θ,因此
(22)
许多研究人员对条件先验(22)进行了解释(例如,参见卡斯和瓦瑟曼(1995))作为杰弗里斯多元问题思想的概括。我们刚刚表明,只有在以下情况下,该提案才能被解释为近似DB:θ是一个渐进的位置参数。
5.2贝叶斯因子的计算
有趣的是,与其他客观贝叶斯建议(如固有和分数贝叶斯因子)类似,可以证明DB-Bayes因子可以表示为使用非信息性(通常不正确)先验计算的未标度贝叶斯因子乘以修正系数。此表达式还允许在以下情况下轻松计算DB Bayes因子很容易计算。
引理5。 对于问题(18)(带有θ和ν正交),设表示通过使用和;那么对于总和和最小DB先验值
(23)
计算通常很简单。在这种情况下,来自后验分布的样本(通常为马尔可夫链蒙特卡罗)可用于评估方程式(23),从而简化了或相当地。这实际上是我们计算贝叶斯因子的方法,例如第4.3.1节。
此外,如果n个较大(相对于尺寸我们可以通过使用后验分布的渐近表达式以及表达式(21)中给出的近似DB先验来近似方程(23)。
我们在一个简单的环境中说明了这种方法。首先,我们假设渐近后验分布由以下公式给出(参见示例中的条件伯杰(1985)),其中是(假设存在)的最大似然估计和是(块对角线)预期的Fisher信息矩阵.
接下来我们假设不依赖于θ,因此近似(条件)DB先验是近似中的Cauchy先验(22)。作为一种符号装置,它将便于书写作为以通常的方式将柯西密度(22)表示为正态和逆伽马分布的比例混合,并使用渐近后验的DB Bayes因子,如方程式(23),可以近似为
哪里第页是的尺寸ν,k个的尺寸θ和.类似的渐近近似最后给出了DB Bayes因子的期望渐近近似值:
这很容易通过简单的蒙特卡罗抽样进行评估。请注意在上面的表达式中取消。
6.总结与结论
通过以下方式扩展开拓性工作杰弗里斯(1961),我们提出了一类新的基于散度测度的客观贝叶斯假设检验先验,我们称之为DB先验。DB先验具有几个理想的属性,包括重新参数化下的不变性、证据一致性以及与足够统计的兼容性。我们在一系列示例中探索了DB prior,在这些示例中,DB prior被证明是直观可靠的,并且能够产生合理的Bayes因子。即使对于不规则模型和不适当的可能性也是如此,这对于其他客观贝叶斯测试方法来说是非常具有挑战性的场景。我们建议在存在总和DB先验的情况下使用它,因为它比最小DB先验更容易计算,并且似乎表现出更好的行为。
DB先验函数的行为类似于算术内在先验函数(定义时),通常更容易推导;两者都不同于分数先验。此外,在正常情况下,它们会重现杰弗里斯(1961)和Zellner和Siow(1980年、1984年)正是这些建议,所以它们可以被视为这些经典建议在非正常情况下的延伸。我们还提供了DB Bayes因子的渐近近似,这在复杂场景中很有用。然而,DB prior仅适用于嵌套比较,因此它们不如分数和内在方法一般。
我们对散度度量、非信息先验估计和有效样本量提出了具体建议。我们做出的其他明显武断的选择是和,共然而,他们的动机是以下论点。
- (a)
选择是专门为在正常情况下重现JZS先验而设计的,但还有其他原因。一个令人信服的原因是,它是一个简单的函数,可以产生具有良好属性的贝叶斯因子;另一个简单的函数可以是指数,但这会导致正常的先验证据一致(请参见梁等。(2008)). 也,结果是尾巴很重;这是一个重要的特征,以便在null模型无法很好地解释数据时,不至于压倒可能性。然而,我们不排除其他递减函数的选择,其最大值为零,并且生成适当的DB类型优先级可以在特定场景中更好地工作。有趣的是,如果使用,然后近似在表达式(21)中,基本上是正常的单位信息,如下所定义卡斯和瓦瑟曼(1995)并由进一步研究拉夫特里(1998).
- (b)
第二个动机是选择原则上,任何可以使用。事实上,我们并不期望δ只要是(这是生成重尾且无正整数矩的先验信息所必需的),但这还需要进一步研究。我们建议使用因为这是复制杰弗里斯建议的价值。
致谢
感谢Jim Berger的评论。作者还感谢副主编和两位审稿人提出了许多有用的建议。这项研究得到了西班牙教育和科学部(MTM2007-61554)的部分资助。
工具书类
巴亚里
,医学博士。
和
加西亚·多纳托
,G.公司。
(
2007
)扩展传统先验以检验线性模型中的一般假设
.生物特征
,94
,135
——152
.
巴亚里
,医学博士。
和
加西亚·多纳托
,G.公司。
(
2008
)基于Jeffreys散度的贝叶斯假设检验先验的推广
.预打印arXiv:0801.4224v1(统计ME)。
伯杰
,J.O.公司。
(
1985
)统计决策理论与贝叶斯分析
,第2版。纽约
:施普林格
.
伯杰
,J.O.公司。
,
巴亚里
,医学博士。
,
张成泽
,西。
,
佩里基
,左心室。
,
雷
,美国。
和
Visser公司
,一、。
(
2008
)BIC的扩展和推广
.工作文件.国家统计科学研究所三角研究园
.
伯杰
,J.O.公司。
和
贝尔纳多
,J·M·。
(
1992
)关于参考先验方法的发展。在贝叶斯统计4
(编辑
J·M·。
贝尔纳多
,
J.O.公司。
伯杰
,
A.P.公司。
Dawid公司
和
A.F.M.公司。
史密斯
),第页。35
——60
.牛津
:牛津大学出版社
.
伯杰
,J.O.公司。
和
德兰帕迪
,M。
(
1987
)测试精确的假设
.统计师。科学。
,三
,317
——352
.
伯杰
,J.O.公司。
,
高希
,J.K。
和
穆霍帕迪耶
,。
(
2003
)模型选择问题和一致性问题中贝叶斯因子的近似
.J.统计。计划信息。
,112
,241
——258
.
伯杰
,J.O.公司。
和
莫特拉
,J。
(
1999
)非嵌套假设检验的默认贝叶斯因子
.《美国统计杂志》。助理。
,94
,542
——554
.
伯杰
,J.O.公司。
和
佩里基
,L.R.公司。
(
1996
)用于模型选择和预测的固有贝叶斯因子
.《美国统计杂志》。助理。
,91
,109
——122
.
伯杰
,J.O.公司。
和
佩里基
,L.R.公司。
(
2001
)模型选择的客观贝叶斯方法:介绍和比较(带讨论)。在型号选择
(编辑)。
第页。
拉希里
),第页。135
——207
.海滩木:数理统计研究所
.
伯杰
,J.O.公司。
,
佩里基
,L.R.公司。
和
瓦尔沙夫斯基
,J.A.公司。
(
1998
)不变情况下的Bayes因子和边际分布
.Sankhya A公司
,60
,307
——321
.
伯杰
,J.O.公司。
和
塞尔克
,T。
(
1987
)检验点无效假设:P值与证据的不可调和性
.《美国统计杂志》。助理。
,82
,112
——122
.
贝尔纳多
,J·M·。
(
2005
)内在可信域:区间估计的客观贝叶斯方法
.测试
,14
,317
——384
.
贝尔纳多
,J·M·。
和
鲁埃达
,R。
(
2002
)贝叶斯假设检验:一种参考方法
.国际统计。修订版。
,70
,351
——372
.
克莱德
,M。
(
1999
)贝叶斯模型平均和模型搜索策略(与讨论)。在贝叶斯统计6
(编辑
J·M·。
贝尔纳多
,
A.第页。
Dawid公司
,
J.O.公司。
伯杰
和
A.F.M.公司。
史密斯
),第页。157
——185
.牛津:牛津大学出版社
.
克莱德
,M。
,
德西蒙
,H。
和
帕尔米贾尼
,G.公司。
(
1996
)正交模型混合预测
.《美国统计杂志》。助理。
,91
,1197
——1208
.
考克斯
,D.R.公司。
和
里德
,N。
(
1987
)参数正交性和近似条件推理(附讨论)
.J.R.统计。Soc.B公司
,49
,1
——39
.
达塔
,通用标准。
和
高希
,M。
(
1995
)关于无信息先验的不变性
.安。统计师。
,24
,141
——159
.
德桑提斯
,F、。
和
斯佩扎费里
,F、。
(
1999
)默认和稳健贝叶斯模型比较方法:分数贝叶斯因子法
.国际统计。修订版。
,67
,267
——286
.
加西亚·多纳托
,G.公司。
(
2003
)Bayes y因子Bayes conventionales:algunos aspectos relevantes
. 博士论文.巴伦西亚大学统计系
,巴伦西亚
.
加西亚·多纳托
,G.公司。
和
太阳
,D。
(
2007
)单向随机效应模型中模型选择的客观先验
.可以。J.统计。
,35
,1874
——1906
.
休庭
,J.A.公司。
,
马迪根
,D。
,
拉夫特里
,答:E。
和
沃林斯基
,C.T.公司。
(
1999
)贝叶斯模型平均:教程
.统计师。科学。
,14
,382
——417
.
易卜拉欣
,J。
和
劳德
,第页。
(
1994
)设计实验分析的预测方法
.《美国统计杂志》。助理。
,89
,309
——319
.
杰弗里斯
,H。
(
1961
)概率论
,第3版。伦敦:牛津大学出版社
.
卡萨丁
,右。
和
拉夫特里
,答:E。
(
1995
)贝叶斯因子
.《美国统计杂志》。助理。
,90
,773
——795
.
卡萨丁
,右。
和
瓦迪亚纳桑
,S.K.公司。
(
1992
)近似贝叶斯因子和正交参数,用于测试两个二项式比例的相等性
.J.R.统计。Soc.B公司
,54
,129
——144
.
卡萨丁
,右。
和
瓦瑟曼
,L。
(
1995
)嵌套假设的参考贝叶斯检验及其与施瓦兹准则的关系
.《美国统计杂志》。助理。
,90
,928
——934
.
库尔贝克
,美国。
(
1968
)信息论与统计学
.纽约
:多佛出版物
.
劳德
,P.W.公司。
和
易卜拉欣
,J·G·。
(
1995
)预测模型选择
.J.R.统计。Soc.B公司
,57
,247
——262
.
梁
,F、。
,
保罗
,R。
,
莫利纳
,G.公司。
,
克莱德
,M。
和
伯杰
,J.O.公司。
(
2008
)贝叶斯变量选择的g-prior混合
.《美国统计杂志》。助理。
,103
,410
——423
.
莫雷诺
,E.公司。
,
贝尔托利诺
,F、。
和
拉库尼奥
,西。
(
1998
)模型选择和假设检验的内在限制过程
.《美国统计杂志》。助理。
,93
,1451
——1460
.
奥哈根
,答:。
(
1995
)模型比较的分数贝叶斯因子(带讨论)
.J.R.统计。Soc.B公司
,57
,99
——138
.
保勒
,D。
(
1998
)正态线性模型的Schwarz准则及相关方法
.生物特征
,85
,13
——27
.
保勒
,D.K.博士。
,
韦克菲尔德
,J.C.公司。
和
卡萨丁
,右。
(
1999
)方差分量模型的贝叶斯因子和近似
.《美国统计杂志》。助理。
,94
,1242
——1253
.
佩雷斯
,美国。
(
2005
)Métodos Bayesianos objetivos de comparación de medias媒体比较
.
博士论文
.巴伦西亚大学统计系
,巴伦西亚
.
佩雷斯
,J·M·。
和
伯杰
,J。
(
2001
)使用预期后验先验对混合模型进行分析,并应用于伽马射线暴的分类。在贝叶斯方法及其在科学、政策和官方统计中的应用
(编辑
E.公司。
乔治
和
第页。
纳米微粒
),第页。401
——410
.卢森堡
:欧洲共同体
.
佩雷斯
,J·M·。
和
伯杰
,J.O.公司。
(
2002
)模型选择的期望后验先验分布
.生物特征
,89
,491
——512
.
拉夫特里
,答:E。
(
1998
)贝叶斯因子与BIC——评韦克利姆
.技术报告347.华盛顿大学统计系
,西雅图
.
坦纳
,文学硕士。
(
1996
)统计推断工具:探索后验分布和似然函数的方法
,第3版。纽约
:施普林格
.
泽尔纳
,答:。
和
Siow公司
,答:。
(
1980
)选定回归假设的后验优势比。在贝叶斯统计1
(编辑
J·M·。
贝尔纳多
,
M.H.先生。
德格罗特
,
直流电。
林德利
和
A.F.M.公司。
史密斯
),第页。585
——603
.巴伦西亚
:瓦伦西亚大学出版社
.
泽尔纳
,答:。
和
Siow公司
,答:。
(
1984
)计量经济学的基本问题
.芝加哥
:芝加哥大学出版社
.附录A:证明
A.1、。引理2的证明
首先我们展示一下方程式(16)意味着作为.假设.然后
结果如下。要显示相反的情况,请注意,因为是正确的,
现在,自相矛盾地假设,因为,特别是.通过控制收敛定理
这与不等式(24)相矛盾作为,证明了结果。
A.2引理的证明4
很容易看出,然后
现在,,引理4来自不等式
A.3引理的证明5
对于,让和表示通过以下方法获得的先前预测边际和分别是。通过DB先验的定义,,因此
最后,
哪里是DB先验归一化常数,结果如下。
©2008皇家统计学会
本文根据牛津大学出版社标准期刊出版模式的条款出版和发行(https://academic.oup.com/journals/pages/open_access/funder_policies/chorus/standard_publication_model)







{kind=link}
{kind=link}
{kind=link}
{kind=link}