总结
本文考虑估计参数β它定义了一个估计函数U型(年,x个,β)结果变量年及其协变量x个当一些观察结果缺失时。我们假设,除了结果和协变量外,每个观察中都有一个替代结果。现有估值器的效率β关键取决于是否正确指定U型给定代理变量和协变量。如果没有正确指定条件期望(这是实际中最可能出现的情况),即使正确指定了倾向函数(缺失),估计的效率也会受到严重影响。我们提出了一个通过经验似然对条件期望的选择具有鲁棒性的估计。我们证明,无论条件分数是否正确指定,所提出的估计器都能获得效率增益。当条件得分被正确指定时,估计量达到由以下公式生成的估计函数类内的半参数方差界U型通过仿真和基于1996年美国总统大选的数据集,对估计器的实际性能进行了评估。
1.简介
缺少数据在实证研究中很常见。在这种情况下进行统计分析具有挑战性。一方面,每个观察结果,无论是否包含缺失变量,都包含一些信息。另一方面,对于缺失变量的观察结果,必须进行细致处理,才能得出有效的推论。在本文中,我们研究了一项研究的结果变量在采样数据的子集中缺失的问题。我们假设,除了结果和协变量外,该研究还收集了每一次观察的替代变量或代理变量的信息。这种性质的数据在许多学科中都很常见。例如,在健康科学研究中,为了评估治疗或程序的成功,通常很难观察临床结果(例如治愈与未治愈);因此,替代结果(例如生物标记物)可以用于那些没有真实结果的参与者(例如Wittes等。(1989)、贝格和梁(2000),梁(2001)、贝克等。(2005),伯兹科夫斯基等。(2005)和贝克(2006))而且,在经济学中,代理或替代结果经常用于回答缺失的调查(陈等。,2005).
对缺失结果的数据建模的一个困难是,导致缺失数据的机制通常是未知的,或者最多只能是近似的。例如,当调查中缺少回应时,很难确定没有回应的原因。非响应可能是完全随机的,也可能取决于一些(观察到的)变量,或者可能与(未观察的)结果有关。如果非响应与未观察到的结果有关,那么解决方案的可识别性可能会受到质疑。
可识别性问题的一个解决方案是使用替代结果。我们关注的是数据随机缺失(MAR)的情况,即缺失结果的概率独立于(未观察到的)结果,给定替代项和协变量(Little和Rubin,2002). 在数据MAR下,如果总是观察到代理变量和协变量,则模型是可识别的。结果完全随机缺失的情况(MCAR)是MAR数据的特例,本文讨论的方法也涵盖了这种情况。
让Y(Y)是结果变量,X(X)是感兴趣的协变量,S公司成为…的代理人Y(Y)和Z轴是一组不直接感兴趣的额外协变量。假设S公司,X(X)和Z轴总是被观察到,但Y(Y)在一些观察中缺失。让δ是取值为1的指示符变量,如果Y(Y)观察到,否则为0。采样数据由两部分组成;一部分(Y(Y),S公司,X(X),Z轴)完全观察到,
和一个丢失的零件Y(Y),
让N个=米+n个。我们假设Y(Y)是采样数据中的MAR,即。
其中w个已知参数θ为了便于讨论,在接下来的几节中,我们假设Z轴为空,我们放弃Z轴从公式w个。我们讨论的结果也适用于更一般的情况Z轴非空,并且在第节中5,我们将建议的方法应用于以下情况Z轴非空。
假设w个可以通过以下方式进行估算最大化二项式对数似然:
1
功能w个是Rosenbaum和Rubin意义上的倾向得分(1983). 基于观测数据的完整对数似然为
2
如果参数化模型假设用于(f)(年,x个,秒)和(f)(x个,秒)然后,通过最大化参数似然进行推断是很简单的。然而,在实践中,参数化模型通常很难指定。
假设(f)(年|x个)=(f)(年|x个,β)是的条件密度Y(Y)鉴于X(X)没有考虑S公司; 然后
是的条件分数Y(Y)鉴于X(X)。这里是参数β最感兴趣的是。一种利用信息的方法S公司是考虑的条件密度S公司鉴于X(X)
三
然而,一般来说,很难具体规定法律[S公司|Y(Y),X(X)]尤其是当S公司是多元的(克莱顿等。,1998). 什么时候?Y(Y)是MCAR,佩佩(1992)提出了一种替代未知条件密度的似然估计方法克(秒|年,x个)在方程式中(三)通过基于完全观测数据的核密度估计。申克和泰勒(1996)建议使用插补(鲁宾,1987)缺少结果。陈和陈(2000)提出了一种基于回归估计的方法。陈等。(2003)使用了两个样本的经验似然(EL),一个基于完整观测值的估计方程,另一个基于缺失结果的观测值。然而,陈和陈的方法(2000)和陈等。(2003)由于在数据MAR的假设下,由于缺失中的选择偏差导致了似然结构的改变,因此不能应用于实际重要的数据MAR情况(1985).
而不是指定克(秒|年,x个)、罗宾斯等。(1995)罗宾斯和罗尼茨基(1995)建议在以下情况下使用估算方程Y(Y)可以是MAR。在这里考虑的框架中,它们的估计器(表示为下文)解决
4
用于特定功能ψ和一个均值0估计函数U型.如果U型是的分数函数(f)(年|x个),然后ψ*≡E类{U型(年,x个,β)|秒,x个}对应于的条件得分函数Y(Y)鉴于S公司和X(X).对于给定的无偏估计函数U型(年,x个,β),它们的估计量可以在由U型(年,x个,β)(纽伊,1990)用于估算β如果ψ(秒,x个,β)=ψ*(秒,x个,β). 此外,是一致的,如果w个或ψ已正确指定。此属性是所谓的“双重鲁棒性”属性。然而,在以下情况下可能会损失效率ψ≠ψ*,如第节定理2所示三.
估计量(4)是Robins开发的一大类半参数有效估计量的特例等。(1994). 然而,作为陈和陈(2000)罗宾斯提出的半参数有效估计等。(1994)由于最优估计函数只能通过求解泛函积分方程获得,因此通常在实际中不可行。闭式最优估计方程(4)存在于此处考虑的情况中,即。U型(年,x个,β)是条件分数S公司是一个替代结果。最近,陈和布雷斯洛(2004)Yu和Nan(2006)还讨论了两种情况,这两种情况与此处所考虑的情况类似,其中可以找到闭合形式的最优估计方程。
尽管ψ*很少精确地知道,估计ψ*≡E类[U型(年,x个,β)|秒,x个]如下所示。让是一致的估计β;可以回归S公司和X(X)给出模型
5
参数未知γ,使用完整的数据。因此,ψ是工作估算ψ*一般来说,ψ可能不是一个完美的猜测;因此E类[ψ]可以是非零的。然而,从方程中获得的估计量(4)是有效的,尽管效率不高,因为在真实参数下,估计方程本身总是具有零均值。
在本文中,我们通过利用包含在S公司和X(X).何时ψ和w个如果指定正确,则我们的方法在由定义的估计函数类中是有效的U型(Y(Y),X(X),β). 即使在ψ指定不正确,只要w个指定正确后,仍能达到良好的效率。论文的其余部分组织如下。在节中2,我们使用EL组合无偏估计方程。大样本结果见第节三.在第节中4,我们报告了一项模拟研究的结果,该研究将提出的方法与现有方法进行了比较。在节中5,将该方法应用于实际数据集。结论见第节6。证明见附录A。
2.提出的方法
假设U型(年,x个,β)是一个估计函数,用于捕获Y(Y)和X(X)通过参数β、和ψ(秒,x个,β,γ)是的函数S公司和X(X)。如果没有进一步明确的符号,我们假设X(X),β和γ可以是向量值。
让是的一致估计量β例如,可能是霍维茨和汤普森(1952)逆加权估计量解决了
6
哪里是前面给出的二项式似然估计量。
以失踪状态为条件δ,基于数据的完全可能性可以写为
7
哪里W公司=对(δ=1). 让第页我=对(年我,秒我,x个我|δ我=1)=w个(秒我,x个我,θ)d日如果(年我,x个我,秒我)/W公司对于我=1,2,…,米和q个j个=对(秒j个,x个j个|δj个=0)={1−w个(秒j个,x个j个,θ)}d日如果(x个j个,秒j个)/(1−W公司)的j个=米+1,…,N个如第节所示1,的平均值ψ(秒,x个,β,γ)可能不是0。因此,似然(7)不能直接用于推断。然而,
哪里μ=E类[ψ(秒,x个,β,γ)]. 因此,通过适当的初步估计稍后讨论,大约
8
可以用于进行推理,如下所示。A log-EL(欧文,1990)的μ是
从属于和
9
为了简化符号,我们写U型我(β)=U型(年我,x个我,β),η=(β,γ),,ψ我(η)=ψ(秒我,x个我,η)和w个我(θ)=w个(秒我,x个我,θ). 通过引入拉格朗日乘数λ和ν并遵循一般估算方程的标准EL推导(Qin和Lawless,1994),的最佳值第页我和q个j个使上述log-EL满足最大化
10
11
带有约束
12
13
替换方程式(10)和(11)回到日志-EL给出
差异化我(μ)关于μ等于0会导致
14
让是方程的解(12)–(14). 将其代入方程式(10)和(11)中,得出EL权重这些权重可用于重新加权原始估算方程(6)这样的话解决
15
我们会证明的比在问题(6)中。
以下是对我们方法的启发性理解。使用拉格朗日乘数
EL估计方程(15)成为
因此,所提出的估计量与回归逆加权估计方程的估计方程的解渐近等价在因此,EL估计方程的方差小于逆加权估计方程的误差。此结果与以下情况类似:Y(Y)和X(X)是两个随机变量;然后是var(Y(Y)−AX公司)=变量(Y(Y))−A类无功功率,无功功率(X(X))A类T型 变量(Y(Y)),其中A类=冠状病毒(Y(Y),X(X))无功功率,无功功率(X(X))−1相比之下,罗宾斯的估算功能等。(1995)是反向加权估计方程与在调查抽样中已知(科克伦,1977; 卡塞尔等。,1976)这种差异估计不如回归估计有效。
使用EL公式β通过使用提取,其中和可以解释为基于和.在进行推理时,我们必须确定ψ,和.让ψ是对…的估计ψ*通过使用方程式(5)和是基于该模型的估计。我们将证明,只要均方收敛到γ0在参数空间内γ,即存在正常数c(c)0这样的话.
找到后,我们可以替换最初的估计通过并重复估算过程。然而,我们的分析表明,初始估计的选择和对渐近效率没有影响。
我们建议的估计器只要w个已正确指定。为此,我们注意到是一致的估计如果(年,秒,x个|D类=1)和
自解决问题(15),该问题可视为上述总体方程的样本版本,是渐近无偏的,其方差收敛到0作为最小值(米,n个)→∞. 因此,是一致的β.
3.主要成果
让β0,γ0和θ0是的真实参数值β,γ和θ分别是。定义η0=(β0,γ0)然后写U型0=d日U型我(β0),ψ0=d日ψ我(η0),μ0=E类[ψ0]和w个0=d日w个我(θ0)其中=d日表示分布中的等价性。此外,让
最后一个量定义了最大似然估计量的渐近方差基于二项式似然(1)。
定理1。在中给出的条件1-4下附录A,
16
哪里
17
18
我们注意到
因此,协方差矩阵可以减少两次:一次一次又一次因此,提出的EL估计器比,当使用真实倾向得分根据完整的观察结果对估计方程进行加权时,除非和同时是零矩阵。
提供的方差减少是基于缺少的观测值在表达式(9)中具有第二个约束的结果Y(Y)-值。如果从表达式(9)中删除此约束,将为0。因此,值得通过倾向得分进行加权,并基于缺失结果部分样本的协变量和替代变量建立额外的估计方程。提供的方差减少部分是由于使用而不是真正的参数θ0从以下方面可以看出这反映了对真实倾向得分的估计具有已知的统计优势(例如,参见Wooldridge(2004)).
我们注意到本质上是一个加权的“相关性”U型和ψ。此相关性的值越高,方差减少越大。此观察结果表明,我们发现了一个函数ψ这与U型.最佳选择ψ是(1−w个)E类[U型(年,x个,β)|秒,x个]=(1−w个)ψ*。这种选择可以通过以下几点来证明
因此
19
当给定的倾向得分已知时,它是方差的下限U型(见罗宾斯等。(1995)和陈等。(2005)). 由于与以往工作不同的设置,我们的最佳选择是ψ有一个额外的系数1−w个0.
现在我们给出了估计器的性质这是罗宾斯提出的等。(1995).
定理2。在中给出的条件1-4下附录A,
20
哪里在定理1中定义,
和
估计员达到半参数效率界限,如果ψ=E类[U型(年,x个,β)|秒,x个]和w个已正确指定。在这种情况下,由∑给出的渐近方差(0)−Σ(2)对于建议的估计器与相同属于等于方程中给出的半参数效率界(19). 然而,当ψ≠E类[U型(年,x个,β)|秒,x个],这在实践中是一种可能的情况即使倾向函数w个已正确指定。原因是,然而总是非负定的(表示效率提高),不能保证是非负定的。的确,对于一些选择ψ,可能比加权估计器效率低解决问题(6);下一节将给出此类情况的一些示例。虽然我们没有建议总是比,确实如此效率总是高于,只要不是0,但没有这样的保证.
4.数值研究
在模拟研究中,我们将提出的估计值与其他三个估计值进行了比较:
在整个模拟研究过程中,以下模型用于生成缺失:
21
对于θ=(θ1,θ2,θ三). 两种型号(Y(Y),S公司,X(X))进行了研究。在模型1中,Y(Y)和S公司均为正态分布,分别具有均值和方差
哪里X(X)∼N个(0,1). 对应的估算函数(Y(Y),X(X))是
估计E类[U型(年,x个,β)|秒,x个]在评估过程中需要获得和。对于此模型,我们使用
对于和ψ(秒,x个)={1−w个(秒,x个,θ)}ψRRZ公司(秒我,x个我,β)的.初步估算γ=(γ1,γ2,γ三)通过拟合线性回归得到
22
如本节所述2,方程式(22)不需要是正确的。目标是尽可能多地恢复Y(Y)通过使用S公司和X(X).
在模型2中,结果Y(Y)是带有的二进制变量
和S公司,条件为X(X)和Y(Y),单位方差和均值均正常
和X(X)∼N个(0,1). 估算方程为
哪里γ=(γ1,γ2,γ三)根据具有完整观测值的数据拟合logistic回归进行估计.
对于模型1和2,对以下各项的组合进行了2000次模拟β=(1,1)和β=(1,2)和θ=缺失概率函数中的(-1,0,0),(-1,0.2,0.2),(-1,0.35,0.35),(−1,0.5,0.5)N个每次模拟中=1000。选择θ=(-1,0,0)、(-1,0.2,0.2)、(-1,0.35,0.35)和(-1,0.5,0.5)分别导致数据中约75%、60%、47%和45%的缺失结果。
我们在每种方法中考虑了两种方差估计方法:
- (a)
第节中的渐近方差公式三和
- (b)
bootstrap方法。
在数据MCAR下(θ=(−1,0,0))或弱MAR(θ=(−1,0.2,0.2)),这两种方法给出了相似的方差估计。然而,根据强烈的MAR数据(θ=(-1,0.35,0.35)和θ=(−1,0.5,0.5)),bootstrap方法给出了更可靠的方差估计。bootstrap方法的更好性能是因为渐近方差公式包含数量,可能会受到以下值的过度影响w个我接近0或1,当θ=(-1,0.35,0.35)或θ=(−1,0.5,0.5).
模拟结果如表所示1和2为了这个案子β=(1,2). 的结果β=(1,1)遵循相同的模式,因此不进行报告。对于每种方法,第一行是基于2000次重复的平均值和方差。第二行是95%标称置信区间的观测覆盖率和bootstrap方差估计。表1表明,当结果为数据MCAR时(θ=(−1,0,0)),以及本文提出的估计量,,几乎相等。然而,当θ=(-1,0.35,0.35)和θ=(−1,0.5,0.5),则缺失在很大程度上取决于(S公司,X(X))在这种情况下跑赢大市和.对于型号2,和比当结果是数据MCAR时。然而,当结果变量缺失的选择偏差较大时,他们在效率上的收益会降低,即。θ=(-1,0.35,0.35)和θ=(−1,0.5,0.5). 有趣的是,在这些情况下,与无法达到的估计值相比也就是说,基于完整的样本,缺失的数据并没有导致太多的信息损失。与之相比,所有三种估值器的效率损失模型2中的严重程度低于模型1中的相应情况。在这三种估计量中,本文提出的估计量是最好的。在某些情况下到小于50%。
| 方法. | 以下值的结果θ:. |
|---|
| θ=(−1,0,0). | θ=(−1,0.2,0.2). | θ=(−1,0.35,0.35). | θ=(−1,0.5,0.5). |
|---|
| 0.99880 (0.00095) | 1.00085 (0.00099) | 1.00104 (0.00100) | 0.99962 (0.00104) |
| 94.75%(0.00099) | 94.55% (0.00100) | 94.50% (0.00100) | 94.55% (0.00100) |
| 1.99870 (0.00097) | 1.99954 (0.00095) | 1.99997 (0.00097) | 2.00120 (0.00106) |
| 94.65% (0.00100) | 94.85% (0.00100) | 94.15% (0.00100) | 93.70% (0.00099) |
| 0.99934 (0.00160) | 1.00114(0.00318) | 1.01477(0.00642) | 1.02475 (0.01338) |
| 94.15% (0.00159) | 92.90% (0.00289) | 89.75% (0.00522) | 82.85% (0.00828) |
| 1.99736 (0.00372) | 1.99422 (0.00746) | 1.97474 (0.01444) | 1.96273 (0.02547) |
| 94.75% (0.00382) | 90.45% (0.00626) | 84.95% (0.01009) | 78.65% (0.01378) |
| 0.99936 (0.00158) | 1.00114 (0.00175) | 1.00173 (0.00309) | 0.99905 (0.04684) |
| 94.15% (0.00154) | 93.95% (0.00168) | 93.60% (0.00312) | 94.10% (0.04397) |
| 1.99758(0.00154) | 1.99981 (0.00272) | 1.99867 (0.00955) | 2.00236 (0.35024) |
| 94.35% (0.00156) | 92.20% (0.00263) | 92.80% (0.01004) | 93.00% (0.32538) |
| 0.99931 (0.00158) | 1.00217 (0.00180) | 1.00487 (0.00293) | 1.00077 (0.00567) |
| 94.35% (0.00155) | 93.95%(0.00175) | 94.85%(0.00291) | 94.65% (0.00474) |
| 1.99747 (0.00156) | 1.99872 (0.00267) | 1.99235 (0.00536) | 1.99500 (0.00961) |
| 94.25% (0.00159) | 93.70% (0.00252) | 94.65% (0.00494) | 95.00% (0.00725) |
| 方法. | 以下值的结果θ:. |
|---|
| θ=(−1,0,0). | θ=(−1,0.2,0.2). | θ=(−1,0.35,0.35). | θ=(−1,0.5,0.5). |
|---|
| 0.99880 (0.00095) | 1.00085 (0.00099) | 1.00104 (0.00100) | 0.99962 (0.00104) |
| 94.75% (0.00099) | 94.55% (0.00100) | 94.50% (0.00100) | 94.55% (0.00100) |
| 1.99870 (0.00097) | 1.99954(0.00095) | 1.99997 (0.00097) | 2.00120 (0.00106) |
| 94.65% (0.00100) | 94.85% (0.00100) | 94.15% (0.00100) | 93.70% (0.00099) |
| 0.99934 (0.00160) | 1.00114 (0.00318) | 1.01477 (0.00642) | 1.02475 (0.01338) |
| 94.15% (0.00159) | 92.90% (0.00289) | 89.75%(0.00522) | 82.85%(0.00828) |
| 1.99736 (0.00372) | 1.99422 (0.00746) | 1.97474 (0.01444) | 1.96273 (0.02547) |
| 94.75% (0.00382) | 90.45% (0.00626) | 84.95% (0.01009) | 78.65% (0.01378) |
| 0.99936 (0.00158) | 1.00114 (0.00175) | 1.00173 (0.00309) | 0.99905 (0.04684) |
| 94.15% (0.00154) | 93.95% (0.00168) | 93.60% (0.00312) | 94.10% (0.04397) |
| 1.99758 (0.00154) | 1.99981 (0.00272) | 1.99867 (0.00955) | 2.00236 (0.35024) |
| 94.35% (0.00156) | 92.20%(0.00263) | 92.80% (0.01004) | 93.00% (0.32538) |
| 0.99931 (0.00158) | 1.00217 (0.00180) | 1.00487 (0.00293) | 1.00077 (0.00567) |
| 94.35% (0.00155) | 93.95% (0.00175) | 94.85% (0.00291) | 94.65% (0.00474) |
| 1.99747 (0.00156) | 1.99872 (0.00267) | 1.99235(0.00536) | 1.99500(0.00961) |
| 94.25% (0.00159) | 93.70% (0.00252) | 94.65% (0.00494) | 95.00% (0.00725) |
| 方法. | 以下值的结果θ:. |
|---|
| θ=(−1,0,0). | θ=(−1,0.2,0.2). | θ=(−1,0.35,0.35). | θ=(−1,0.5,0.5). |
|---|
| 0.99880 (0.00095) | 1.00085 (0.00099) | 1.00104(0.00100) | 0.99962 (0.00104) |
| 94.75% (0.00099) | 94.55% (0.00100) | 94.50% (0.00100) | 94.55% (0.00100) |
| 1.99870 (0.00097) | 1.99954 (0.00095) | 1.99997 (0.00097) | 2.00120 (0.00106) |
| 94.65% (0.00100) | 94.85% (0.00100) | 94.15% (0.00100) | 93.70%(0.00099) |
| 0.99934(0.00160) | 1.00114 (0.00318) | 1.01477 (0.00642) | 1.02475 (0.01338) |
| 94.15% (0.00159) | 92.90% (0.00289) | 89.75% (0.00522) | 82.85% (0.00828) |
| 1.99736 (0.00372) | 1.99422 (0.00746) | 1.97474 (0.01444) | 1.96273 (0.02547) |
| 94.75% (0.00382) | 90.45% (0.00626) | 84.95% (0.01009) | 78.65% (0.01378) |
| 0.99936 (0.00158) | 1.00114 (0.00175) | 1.00173 (0.00309) | 0.99905 (0.04684) |
| 94.15% (0.00154) | 93.95% (0.00168) | 93.60% (0.00312) | 94.10%(0.04397) |
| 1.99758 (0.00154) | 1.99981 (0.00272) | 1.99867 (0.00955) | 2.00236 (0.35024) |
| 94.35% (0.00156) | 92.20% (0.00263) | 92.80% (0.01004) | 93.00% (0.32538) |
| 0.99931 (0.00158) | 1.00217 (0.00180) | 1.00487 (0.00293) | 1.00077(0.00567) |
| 94.35%(0.00155) | 93.95% (0.00175) | 94.85% (0.00291) | 94.65% (0.00474) |
| 1.99747 (0.00156) | 1.99872 (0.00267) | 1.99235 (0.00536) | 1.99500 (0.00961) |
| 94.25% (0.00159) | 93.70% (0.00252) | 94.65% (0.00494) | 95.00% (0.00725) |
| 方法. | 以下值的结果θ:. |
|---|
| θ=(−1,0,0). | θ=(−1,0.2,0.2). | θ=(−1,0.35,0.35). | θ=(−1,0.5,0.5). |
|---|
| 0.99880 (0.00095) | 1.00085 (0.00099) | 1.00104 (0.00100) | 0.99962 (0.00104) |
| 94.75% (0.00099) | 94.55% (0.00100) | 94.50% (0.00100) | 94.55%(0.00100) |
| 1.99870 (0.00097) | 1.99954 (0.00095) | 1.99997 (0.00097) | 2.00120 (0.00106) |
| 94.65% (0.00100) | 94.85% (0.00100) | 94.15% (0.00100) | 93.70% (0.00099) |
| 0.99934 (0.00160) | 1.00114 (0.00318) | 1.01477 (0.00642) | 1.02475 (0.01338) |
| 94.15%(0.00159) | 92.90%(0.00289) | 89.75% (0.00522) | 82.85% (0.00828) |
| 1.99736 (0.00372) | 1.99422 (0.00746) | 1.97474 (0.01444) | 1.96273 (0.02547) |
| 94.75% (0.00382) | 90.45% (0.00626) | 84.95% (0.01009) | 78.65% (0.01378) |
| 0.99936 (0.00158) | 1.00114 (0.00175) | 1.00173 (0.00309) | 0.99905 (0.04684) |
| 94.15% (0.00154) | 93.95% (0.00168) | 93.60% (0.00312) | 94.10% (0.04397) |
| 1.99758 (0.00154) | 1.99981 (0.00272) | 1.99867 (0.00955) | 2.00236(0.35024) |
| 94.35% (0.00156) | 92.20% (0.00263) | 92.80% (0.01004) | 93.00% (0.32538) |
| 0.99931 (0.00158) | 1.00217 (0.00180) | 1.00487 (0.00293) | 1.00077 (0.00567) |
| 94.35% (0.00155) | 93.95% (0.00175) | 94.85% (0.00291) | 94.65% (0.00474) |
| 1.99747(0.00156) | 1.99872(0.00267) | 1.99235 (0.00536) | 1.99500 (0.00961) |
| 94.25% (0.00159) | 93.70% (0.00252) | 94.65% (0.00494) | 95.00% (0.00725) |
| 方法. | 以下值的结果θ:. |
|---|
| θ=(−1, 0, 0). | θ=(−1, 0.2, 0.2). | θ=(−1、0.35、0.35). | θ=(−1, 0.5, 0.5). |
|---|
| 1.00334 (0.00934) | 1.00075 (0.00898) | 1.00315 (0.00843) | 0.99887 (0.00877) |
| 93.60% (0.00893) | 94.65% (0.00889) | 94.95% (0.00888) | 94.40% (0.00882) |
| 2.00818 (0.01943) | 2.01027 (0.00181) | 2.08768(0.01727) | 2.00296(0.01758) |
| 93.70% (0.01812) | 94.0% (0.01816) | 94.40% (0.01808) | 94.05% (0.01803) |
| 1.01157 (0.02583) | 1.01425 (0.02112) | 1.01159 (0.01893) | 1.00393 (0.01757) |
| 94.90% (0.02852) | 95.10% (0.02275) | 94.75% (0.01990) | 93.90% (0.01757) |
| 2.02609 (0.07416) | 2.03483 (0.06081) | 2.02950 (0.05938) | 2.02701 (0.05529) |
| 94.0% (0.07602) | 93.35% (0.06384) | 93.50% (0.05907) | 93.40% (0.05714) |
| 1.00794 (0.02167) | 1.00726 (0.01730) | 1.00667(0.01554) | 1.00177 (0.01458) |
| 94.40% (0.02308) | 4.85% (0.01823) | 94.70% (0.01601) | 93.10% (0.01446) |
| 2.02529 (0.05019) | 2.02167 (0.04314) | 2.02264 (0.04278) | 2.02543 (0.03918) |
| 93.60% (0.05160) | 93.25% (0.04399) | 92.40%(0.04063) | 92.20%(0.03891) |
| 1.00795 (0.02184) | 1.00796 (0.01729) | 1.00694 (0.01560) | 1.00297 (0.01470) |
| 94.70% (0.02334) | 94.60% (0.01838) | 94.80% (0.01612) | 93.30% (0.01463) |
| 2.02466 (0.05050) | 2.02238 (0.04350) | 2.02247 (0.04327) | 2.02487 (0.04010) |
| 93.10% (0.05243) | 93.50% (0.04468) | 92.70% (0.04121) | 92.40% (0.03977) |
| 方法. | 以下值的结果θ:. |
|---|
| θ=(−1, 0, 0). | θ=(−1, 0.2, 0.2). | θ=(−1, 0.35, 0.35). | θ=(−1、0.5、0.5). |
|---|
| 1.00334 (0.00934) | 1.00075 (0.00898) | 1.00315 (0.00843) | 0.99887 (0.00877) |
| 93.60% (0.00893) | 94.65% (0.00889) | 94.95% (0.00888) | 94.40% (0.00882) |
| 2.00818 (0.01943) | 2.01027 (0.00181) | 2.08768 (0.01727) | 2.00296 (0.01758) |
| 93.70%(0.01812) | 94.0%(0.01816) | 94.40% (0.01808) | 94.05% (0.01803) |
| 1.01157 (0.02583) | 1.01425 (0.02112) | 1.01159 (0.01893) | 1.00393 (0.01757) |
| 94.90% (0.02852) | 95.10% (0.02275) | 94.75% (0.01990) | 93.90% (0.01757) |
| 2.02609 (0.07416) | 2.03483 (0.06081) | 2.02950 (0.05938) | 2.02701 (0.05529) |
| 94.0% (0.07602) | 93.35% (0.06384) | 93.50% (0.05907) | 93.40% (0.05714) |
| 1.00794 (0.02167) | 1.00726 (0.01730) | 1.00667 (0.01554) | 1.00177 (0.01458) |
| 94.40%(0.02308) | 4.85% (0.01823) | 94.70% (0.01601) | 93.10% (0.01446) |
| 2.02529 (0.05019) | 2.02167 (0.04314) | 2.02264 (0.04278) | 2.02543 (0.03918) |
| 93.60% (0.05160) | 93.25% (0.04399) | 92.40% (0.04063) | 92.20% (0.03891) |
| 1.00795(0.02184) | 1.00796(0.01729) | 1.00694 (0.01560) | 1.00297 (0.01470) |
| 94.70% (0.02334) | 94.60% (0.01838) | 94.80% (0.01612) | 93.30% (0.01463) |
| 2.02466 (0.05050) | 2.02238 (0.04350) | 2.02247 (0.04327) | 2.02487 (0.04010) |
| 93.10% (0.05243) | 93.50% (0.04468) | 92.70% (0.04121) | 92.40% (0.03977) |
| 方法. | 以下值的结果θ:. |
|---|
| θ=(−1, 0, 0). | θ=(−1, 0.2, 0.2). | θ=(−1, 0.35, 0.35). | θ=(−1、0.5、0.5). |
|---|
| 1.00334(0.00934) | 1.00075 (0.00898) | 1.00315 (0.00843) | 0.99887 (0.00877) |
| 93.60% (0.00893) | 94.65% (0.00889) | 94.95% (0.00888) | 94.40% (0.00882) |
| 2.00818 (0.01943) | 2.01027 (0.00181) | 2.08768 (0.01727) | 2.00296 (0.01758) |
| 93.70% (0.01812) | 94.0% (0.01816) | 94.40% (0.01808) | 94.05% (0.01803) |
| 1.01157 (0.02583) | 1.01425 (0.02112) | 1.01159 (0.01893) | 1.00393 (0.01757) |
| 94.90% (0.02852) | 95.10% (0.02275) | 94.75% (0.01990) | 93.90% (0.01757) |
| 2.02609(0.07416) | 2.03483 (0.06081) | 2.02950 (0.05938) | 2.02701 (0.05529) |
| 94.0% (0.07602) | 93.35% (0.06384) | 93.50% (0.05907) | 93.40% (0.05714) |
| 1.00794 (0.02167) | 1.00726 (0.01730) | 1.00667 (0.01554) | 1.00177 (0.01458) |
| 94.40%(0.02308) | 4.85%(0.01823) | 94.70% (0.01601) | 93.10% (0.01446) |
| 2.02529 (0.05019) | 2.02167 (0.04314) | 2.02264 (0.04278) | 2.02543 (0.03918) |
| 93.60% (0.05160) | 93.25% (0.04399) | 92.40% (0.04063) | 92.20% (0.03891) |
| 1.00795 (0.02184) | 1.00796 (0.01729) | 1.00694 (0.01560) | 1.00297 (0.01470) |
| 94.70% (0.02334) | 94.60% (0.01838) | 94.80% (0.01612) | 93.30% (0.01463) |
| 2.02466 (0.05050) | 2.02238 (0.04350) | 2.02247 (0.04327) | 2.02487 (0.04010) |
| 93.10%(0.05243) | 93.50% (0.04468) | 92.70% (0.04121) | 92.40% (0.03977) |
| 方法. | 以下值的结果θ:. |
|---|
| θ=(−1, 0, 0). | θ=(−1, 0.2, 0.2). | θ=(−1, 0.35, 0.35). | θ=(−1, 0.5, 0.5). |
|---|
| 1.00334 (0.00934) | 1.00075(0.00898) | 1.00315(0.00843) | 0.99887 (0.00877) |
| 93.60% (0.00893) | 94.65% (0.00889) | 94.95% (0.00888) | 94.40% (0.00882) |
| 2.00818 (0.01943) | 2.01027 (0.00181) | 2.08768 (0.01727) | 2.00296 (0.01758) |
| 93.70% (0.01812) | 94.0% (0.01816) | 94.40% (0.01808) | 94.05% (0.01803) |
| 1.01157 (0.02583) | 1.01425 (0.02112) | 1.01159 (0.01893) | 1.00393 (0.01757) |
| 94.90% (0.02852) | 95.10% (0.02275) | 94.75% (0.01990) | 93.90% (0.01757) |
| 2.02609 (0.07416) | 2.03483 (0.06081) | 2.02950(0.05938) | 2.02701 (0.05529) |
| 94.0% (0.07602) | 93.35% (0.06384) | 93.50% (0.05907) | 93.40% (0.05714) |
| 1.00794 (0.02167) | 1.00726 (0.01730) | 1.00667 (0.01554) | 1.00177 (0.01458) |
| 94.40% (0.02308) | 4.85% (0.01823) | 94.70%(0.01601) | 93.10%(0.01446) |
| 2.02529 (0.05019) | 2.02167 (0.04314) | 2.02264 (0.04278) | 2.02543 (0.03918) |
| 93.60% (0.05160) | 93.25% (0.04399) | 92.40% (0.04063) | 92.20% (0.03891) |
| 1.00795 (0.02184) | 1.00796 (0.01729) | 1.00694 (0.01560) | 1.00297 (0.01470) |
| 94.70% (0.02334) | 94.60% (0.01838) | 94.80% (0.01612) | 93.30% (0.01463) |
| 2.02466 (0.05050) | 2.02238 (0.04350) | 2.02247 (0.04327) | 2.02487 (0.04010) |
| 93.10% (0.05243) | 93.50% (0.04468) | 92.70%(0.04121) | 92.40% (0.03977) |
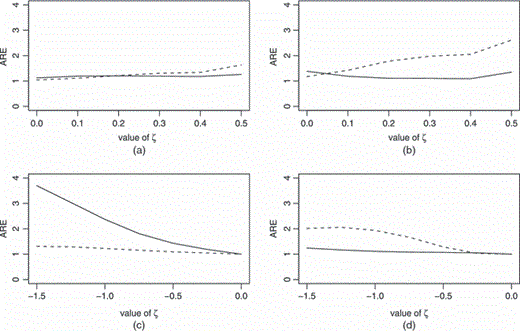
为了进一步说明定理1和2的结果,我们比较了适度设置下估计量之间的渐近相对效率。使用了两个模型。第一个模型是一个线性模型,与仿真研究中的模型1类似,但E类[S公司|Y(Y),X(X)]=2Y(Y)如果Y(Y)0和E类[S公司|Y(Y),X(X)]=Y(Y)如果Y(Y)<0和θ≡(θ1,θ2,θ三)=(−2,ζ,0.5)在缺失函数中w个,使用ζ允许在0到0.5之间变化。第二个模型是二进制的Y(Y)如模拟研究中的模型2和S公司也是二进制的
所以ζ是一种干扰S公司不完美的代理人。的价值ζ变化范围为−1.5至0θ=(−3,3,0)英寸w个。因此ζ在这两种模型中,都会出现无法找到简单ψ-与相同的函数ψ0(秒,x个,β)≡E类[U型(年,x个,β)|秒,x个]在两个模型中,我们假设(β1,β2)=(1,2),我们使用定理1和2中的渐近公式计算
用于估算β1和β2结果如图所示1(a) ——1(d) ●●●●。他们证明了这一点始终与和在所有研究的场景中。这些结果最显著的特点是罗宾斯方法的表现不佳等。(1995)在数据MAR下,当ζ非零(图1(b) 和1(d) )。罗宾斯方法表现不佳等。(1995)结果是因为ψ与E类[U型(年,x个,β)|秒,x个]在这些情况下。这是在第节末尾提出的观点三不能保证他们的估计总是优于逆加权估计。在这两种模型中,使用不太明显β1比β2这是因为模型的建立改变了X(X)通过S公司根据数据MAR,这些变化会影响β2更多是因为它是与X(X).
图1
三个估计量之间的渐近相对效率(ARE)(缺失概率函数为对(δ=1|S公司=秒,X(X)=x个)=经验(θ1+θ2秒+θ三x个)/{1+经验(θ1+θ2秒+θ三x个)}; ,ARE公司(; - - - - - - - -, ARE公司(,); 对于(a)和(b),Y(Y)∼N个(β1+β2X(X), 1),S公司∼N个(2Y(Y),1)如果Y(Y)0和S公司∼N个(Y(Y),1)如果Y(Y)<0和θ≡(θ1,θ2,θ三)=(−2,ζ, 0.5); 对于(c)和(d),对(Y(Y)=1|X(X))=经验(β1+β2X(X))/{1+经验(β1+β2X(X))},对(S公司=1|X(X))=经验{β1+β2(X(X)+ζ)}/[1+经验{β1+β2(X(X)+ζ)}]和θ=(−3,3,0):(a)线性模型,β1; (b) 线性模型,β2; (c) 二进制模型,β1; (d) 二进制模型,β2
,ARE公司(; - - - - - - - -, ARE公司(,); 对于(a)和(b),Y(Y)∼N个(β1+β2X(X), 1),S公司∼N个(2Y(Y),1)如果Y(Y)0和S公司∼N个(Y(Y),1)如果Y(Y)<0和θ≡(θ1,θ2,θ三)=(−2,ζ, 0.5); 对于(c)和(d),对(Y(Y)=1|X(X))=经验(β1+β2X(X))/{1+经验(β1+β2X(X))},对(S公司=1|X(X))=经验{β1+β2(X(X)+ζ)}/[1+经验{β1+β2(X(X)+ζ)}]和θ=(−3,3,0):(a)线性模型,β1; (b) 线性模型,β2; (c) 二进制模型,β1; (d) 二进制模型,β2
5.选举数据的应用
我们将提出的方法应用于国家选举研究的一组数据(沃伦等。,1999; 李和康,2002; 李,2005). 美国总统选举遵循选举团制度,而不是通常的普选制度。然而,有两次(包括2000年布什和戈尔之间的那次),一位候选人尽管赢得了普选,却在选举中失利。我们认为选举遵循的是普选制度。正如Lee所说(2005),这种方法之所以合理,有两个原因:
这些数据来自选举前后进行的两项调查。有三位候选人:克林顿、多尔和佩罗。我们重点关注两位主要候选人:克林顿和多尔。该数据集的一个显著特点是,有很大比例的观察结果(33%)没有得到结果,如那些没有投票的人所代表的。
我们使用了三个问题的答案来构建替代结果S公司在选举后调查中,每个非选民都被问到一个问题:“作为总统,你更喜欢谁?”。如果答案是克林顿或多尔,那么它被用作替代结果。如果没有给出答案,那么我们比较了选举前和选举后调查中非选民对克林顿和多尔的平均评分(0-100分),并将平均评分较高的候选人作为替代结果。如果平均收视率持平,那么我们看看非选民的政党特征。通过执行这个程序,我们到达了N个=1486名受访者,他们要么有替代对象,要么有真实结果,并且有完整的协变量信息。
可用于分析的数据的投票模式(N个=1486)如下:无投票权,474票或32%;克林顿,586人,占39%;多尔,426或29%。使用上一段描述的方法,在1486名受访者中,929人将克林顿作为替代结果,557人将多尔作为替代结果。评估代理质量的一种方法是将其价值与投票人的真实结果进行比较。比较总结见表三这表明真实结果和替代结果之间的关联非常显著(第页<0.001,通过使用χ2-测试)。
| 代孕结果. | 真正的结果. | 总计. |
|---|
| 克林顿. | 多尔. |
|---|
| 克林顿 | 574 | 17 | 591 |
| 多尔 | 23 | 404 | 427 |
| 总计 | 597 | 421 | 1018 |
| 替代结果. | 真正的结果. | 总计. |
|---|
| 克林顿. | 多尔. |
|---|
| 克林顿 | 574 | 17 | 591 |
| 多尔 | 23 | 404 | 427 |
| 总计 | 597 | 421 | 1018 |
| 替代结果. | 真正的结果. | 总计. |
|---|
| 克林顿. | 多尔. |
|---|
| 克林顿 | 574 | 17 | 591 |
| 多尔 | 23 | 404 | 427 |
| 总计 | 597 | 421 | 1018 |
| 替代结果. | 真正的结果. | 总计. |
|---|
| 克林顿. | 多尔. |
|---|
| 克林顿 | 574 | 17 | 591 |
| 多尔 | 23 | 404 | 427 |
| 总计 | 597 | 421 | 1018 |
阿尔瓦雷斯和纳格勒(1998)讨论了几个可能感兴趣的与全国选举研究有关的问题。我们关注的问题是选民对经济的看法如何影响选举结果。在选举前的调查中,每个被调查者都被问及,在选举前一年,美国经济是好转了,还是保持不变,还是恶化了。表中总结了受访者的答案以及真实结果和替代结果的价值4因此,选民的看法代表X(X)-模型中的变量。
| 真正的结果. | 替代结果. | 以下经济认知的结果:. |
|---|
| 更好. | 相同. | 更糟. |
|---|
| 无投票权 | 克林顿 | 117 | 168 | 52 |
| 多尔 | 34 | 57 | 46 |
| 克林顿 | 克林顿 | 338 | 187 | 44 |
| 多尔 | 6 | 9 | 2 |
| 多尔 | 克林顿 | 11 | 10 | 2 |
| 多尔 | 94 | 222 | 87 |
| 真正的结果. | 替代结果. | 以下对经济的看法的结果:. |
|---|
| 更好. | 相同. | 更糟. |
|---|
| 无投票权 | 克林顿 | 117 | 168 | 52 |
| 多尔 | 34 | 57 | 46 |
| 克林顿 | 克林顿 | 338 | 187 | 44 |
| 多尔 | 6 | 9 | 2 |
| 多尔 | 克林顿 | 11 | 10 | 2 |
| 多尔 | 94 | 222 | 87 |
| 真正的结果. | 替代结果. | 以下经济认知的结果:. |
|---|
| 更好. | 相同. | 更糟. |
|---|
| 无投票权 | 克林顿 | 117 | 168 | 52 |
| 多尔 | 34 | 57 | 46 |
| 克林顿 | 克林顿 | 338 | 187 | 44 |
| 多尔 | 6 | 9 | 2 |
| 多尔 | 克林顿 | 11 | 10 | 2 |
| 多尔 | 94 | 222 | 87 |
| 真正的结果. | 替代结果. | 以下经济认知的结果:. |
|---|
| 更好. | 相同. | 更糟. |
|---|
| 无投票权 | 克林顿 | 117 | 168 | 52 |
| 多尔 | 34 | 57 | 46 |
| 克林顿 | 克林顿 | 338 | 187 | 44 |
| 多尔 | 6 | 9 | 2 |
| 多尔 | 克林顿 | 11 | 10 | 2 |
| 多尔 | 94 | 222 | 87 |
为了模拟失去结果的可能性,我们查阅了以前研究美国总统选举选民投票率的著作(Riker和Ordshick,1968; Filer和Kenney,1980; 桑德斯,2001). 砂光机(2001)使用本文中的数据集对道岔断开概率进行建模(表1在桑德斯(2001))具有以下变量:年龄、收入、种族、性别、教育程度(高中与大学与其他)、(选民的)政治意识和效力、(选民和候选人之间的)意识形态和性格差异、(选民对候选人的)意识形态与性格确定性、选举前政党是否联系(动员)选民以及选民是否关心选举。这些变量是Z轴这将在第节中讨论1。除此之外Z轴,我们添加了S公司和X(X)并建模w个通过使用logistic回归
23
此示例突出显示了所扮演的不同角色Z轴和S公司.鉴于S公司是那些没有投票的人的投票偏好的替代品,Z轴用于模拟投票行为。这两个变量对于组合选民和非选民的信息以得出有效的推论是必要的。
使用二元逻辑回归来建模真实结果(总统的选择)和单个协变量(感知的经济状况)之间的关系。让Y(Y)成为真正的结果Y(Y)=1代表“克林顿是我们的选择”Y(Y)=0表示“多尔是选择”;让X(X)是协变量X(X)=−1,0,1,如果受访者认为国家经济“变得更糟”、“保持不变”和“变得更好”。模型可以写成
替代结果S公司也是一个二进制变量S公司=1代表克林顿S公司=0代表Dole是选择。我们假设
哪里γ=(γ1,γ2,γ三)根据投票的受访者和按等式建模(23).
本文考虑的三种方法用于分析数据。表5基于bootstrap方法和定理1和2中的渐近公式,给出了参数估计和相应的方差。所有方法都有强有力的证据那个选民对经济的看法对投票行为有重大影响。使用加权估计,投票给克林顿的几率为
对于那些对经济持赞成态度而对经济持否定态度的人来说。使用其他两种方法得出的结论相似。使用罗宾斯的方法等。(1995)与加权估计器相比,本文提出的方法在效率上有显著提高。bootstrap和相应的渐近公式方差估计值类似,在大多数实际情况下也是如此。
| 方法. | 参数估计(方差†,方差‡)对于以下参数:. |
|---|
| β1. | β2. |
|---|
| 加权估计器 | 0.2989 | 0.8004 |
| (0.00839, 0.00642) | (0.01682, 0.01578) |
| 罗宾斯等。(1995) | 0.2223 | 0.8792 |
| (0.00386, 0.00485) | (0.00818, 0.01006) |
| 拟议估价师 | 0.2950 | 0.7867 |
| (0.00399,0.00442) | (0.00786, 0.00825) |
| 方法. | 参数估计(方差†,方差‡)对于以下参数:. |
|---|
| β1. | β2. |
|---|
| 加权估计器 | 0.2989 | 0.8004 |
| (0.00839, 0.00642) | (0.01682, 0.01578) |
| 罗宾斯等。(1995) | 0.2223 | 0.8792 |
| (0.00386, 0.00485) | (0.00818, 0.01006) |
| 建议估算量 | 0.2950 | 0.7867 |
| (0.00399, 0.00442) | (0.00786, 0.00825) |
| 方法. | 参数估计(方差†,方差‡)对于以下参数:. |
|---|
| β1. | β2. |
|---|
| 加权估计器 | 0.2989 | 0.8004 |
| (0.00839, 0.00642) | (0.01682, 0.01578) |
| 罗宾斯等。(1995) | 0.2223 | 0.8792 |
| (0.00386, 0.00485) | (0.00818, 0.01006) |
| 拟议估价师 | 0.2950 | 0.7867 |
| (0.00399, 0.00442) | (0.00786, 0.00825) |
| 方法. | 参数估计(方差†,方差‡)对于以下参数:. |
|---|
| β1. | β2. |
|---|
| 加权估计器 | 0.2989 | 0.8004 |
| (0.00839, 0.00642) | (0.01682, 0.01578) |
| 罗宾斯等。(1995) | 0.2223 | 0.8792 |
| (0.00386, 0.00485) | (0.00818, 0.01006) |
| 拟议估价师 | 0.2950 | 0.7867 |
| (0.00399,0.00442) | (0.00786、0.00825) |
6.结束语
当缺少真实结果时,替代结果已成为提高估计效率的一种常用方法。本文通过Owen(1990)的EL提出了一种提高代理结果问题估计效率的方法。提出了两种不同的观测似然分解。第一次分解使用基于观测值的二项式似然条件(Y(Y),X(X),S公司)在方程式中(1). 参数θ在倾向函数中w个可以通过最大化二项式似然很容易地进行估计。第二次分解以缺失状态为条件。因此,可以通过连接无偏估计方程来构造两个EL。众所周知,最佳估计方程一般不可用,但对于缺失的响应数据,存在更简单的形式;见陈和布雷斯洛(2004)Yu和Nan(2006). 实际上,U型(Y(Y),X(X),β)可以回归S公司和X(X)使用工作非线性模型或一般的可加性模型。我们使用估计方程修正了工作模型中可能存在的偏差(8)然后利用EL将它们结合起来。所得估计具有诱人的理论性质和良好的有限样本性能。当关于条件密度的信息很少时,该方法特别有用S公司给定(Y(Y),X(X)),因为在这种情况下,罗宾斯估计量等方法所需的最佳条件估计函数等。(1995)不可用。经过一些修改,所提出的方法可以推广到其他缺少数据的情况,例如在测量误差问题中。
致谢
我们感谢副主编和两位推荐人提出的建设性意见和建议。陈的研究得到了国家科学基金资助SES-0518904和DMS 06-04563。梁的研究得到了新加坡管理大学研究中心的支持。我们感谢韩国大学的Myoung-Jae Lee教授为我们提供了选举数据以及他对数据的宝贵意见。
工具书类
附录A
建立定理1和定理2所需的条件如下。
条件1。倾向得分w个我(θ)是关于的两倍连续可微θ在…附近θ0且从0和1一致有界;此外,米/N个→ρ∈(0,1)为N个→∞.
条件2。初始估计器在均方收敛到γ0在参数空间Γ内,对于足够大的米和N个,对于固定正定矩阵A类0.
条件3。让。假设和是正定的,并且E类[∂U型0/∂β]是第页,这也是β.
条件4。∂2U型(β)/∂β∂βT型在附近是连续的β0其中‖ñU型(β)/∂β‖有界2ψ(β,γ)/∂γ∂γT型在附近是连续的(β0,γ0),在这个街区ψ(β,γ)/∂γ‖有界,E类[‖U型(β)‖]2<∞和E类[‖ψ(β,γ)第二十四条2<∞.
让
关于最大似然估计量,我们有以下结果倾向得分的参数。
引理1。在条件1下,
证明。自是二项式似然(1)的最大值,
24
由泰勒方程展开(24)以真实值θ0,
25
哪里
作为B类N个=Λ+o(o)第页(1) 和q个N个0=O(运行)第页(N个−1/2),引理是由方程建立的(25).
引理2。在条件1-4下,,和.
证明。结果变量缺失中的选择偏差意味着
因此两者都是和是O(运行)第页(N个−1/2). 请注意如条件2中假设的那样。引理2随后遵循与欧文中类似的推导(1990)秦与无法无天(1994).
A.1、。定理1的证明
自然后进行泰勒方程展开(12)–(15)在(β=β0,μ=μ0,λ=0)并忽略o(o)第页(N个1/2)导致
26
27
28
29
让
哪里
和
此外,让
30
四个方程式(26)–(29)可以写为
31
可以看出
32
其中∑12=(0,我第页,我第页)和
在这里我第页是一个第页×第页单位矩阵。因此,方程(31)和(32)暗示
33
请注意
34
哪里
此外,
让R(右)是∑的第二行−1删除第一列后。然后,
35
哪里
这种独特的结构R(右)有助于为渐近协方差矩阵提供简洁的表达式.根据方程式(33),
36
将泰勒展开应用于q个N个,
37
哪里
哪里q个N个0定义见附录开头。请注意是独立同分布随机向量的样本平均值。应用标准多元中心极限定理和Slutsky定理,可以证明
38
哪里
39
让
然后,
40
根据方程式(35),因此,因此,.该结果和方程式(38)共同给予
41
其中∑=R(右)(Ω(11)−Ω(12))R(右)T型.经过一些矩阵代数,可以证明
很明显这些结果暗示了定理1的结果。
A.2、。定理2的证明
泰勒展开式在方程中的应用(4)在(β0,γ0,θ0)给予
42
哪里
标准推导表明
43
和
44
中心极限定理和方程(43)和(44)共同意味着
45
定理2很容易由方程式隐含(42)和(45).
©2008皇家统计学会







{kind=link}