总结
我们提出了随机对照试验证据的联合分析模型,这些随机对照试验因其行为缺陷而被归类为低或高偏差风险。我们建立了一个偏倚模型,该模型结合了研究之间、偏倚的荟萃分析异质性和总体平均偏倚的不确定性。我们获得了偏差调整治疗效果后验分布的代数表达式,为从高偏差风险研究中获得的信息提供了极限值。偏倚模型的参数可以从先前发布的荟萃分析中进行估计。我们探索了此类数据的替代模型,以及将偏差参数的先验信息引入新荟萃分析的替代方法。一个示例的结果表明,经偏差调整的治疗效果估计值对元流行病学数据建模的方式很敏感,但使用偏差参数的点估计值提供了使用完全联合先验分布的适当近似值。敏感性分析表明,包括具有高偏倚风险的研究,无论其数量多或规模大,其精确度的提高可能很低,而通过合并此类研究,除非来自具有低偏倚危险的研究的信息有限,否则获得的准确度很低。我们讨论了可能增加包括高风险偏倚研究的价值的方法,以及在评估卫生保健干预措施中方法的可接受性。
1.简介
各种研究提供了经验证据,表明随机对照试验中的具体缺陷可能会使对治疗效果的估计产生偏差(Gluud,2006). 特别是,有充分证据表明,在招募患者时未能隐藏随机分配,以及缺乏双盲法,与夸大治疗效果估计有关(Schulz等。,1995; 穆赫等。,1998; 艾格等。,2003; 麦考利等。,2000; 卡亚加德等。,2001; 木材等。, 2008). 试验特征,如分配隐蔽性或盲性的充分性,通常被视为偏倚风险高或低的二元指标。医学文献中通常报道有行为缺陷的试验,并且通常代表系统综述中包含的大量证据(Egger等。,2003). 虽然可以进行和报告包括或忽略高风险证据的多项分析,但元分析越来越多地用于决策分析,其中必须报告单个“最佳”估计。然后,荟萃分析人员面临着一个选择,是应该通过限制对低风险偏倚试验的关注来采用“最佳可用证据”方法,还是采用“所有可用证据”的方法,其中包括所有试验。
全可用证据方法是本着英国国家临床卓越研究所(NICE)等组织的精神,其重点是反映当前可用证据的决策分析。然而,这种方法在模型的制定过程中提出了方法学问题,以解释潜在的偏见。如果将偏倚高风险的试验纳入荟萃分析,那么在系统审查和数据提取过程中,也会对适当的纳入-排除标准提出问题。
拟议的包含潜在偏见证据的方法侧重于降低权重证据合成中存在高偏差风险的研究(Begg和Pilote,1991; 李和贝格,1994; Larose和Dey,1997; 上一个等。,2000; Spiegelhalter和Best,2003)或基于个别研究特征的研究特定偏差的详细建模,然后用于逐项研究调整观察到的治疗效果之前证据的综合(埃迪等。,1992; 沃尔伯特和蒙格森,2004; 格陵兰,2005). 在这里,我们考虑了一个替代框架,在这个框架中,我们在贝叶斯范式中调整预期偏差以及降低高偏差风险研究的权重。荟萃流行病学研究(其中荟萃分析的集合提供了研究特征与治疗效果估计之间关联的证据)用于提供基于经验的先验信息,以了解高偏倚风险研究的偏倚程度,特定meta分析中研究之间偏差的异质性和meta分析之间平均偏差的额外异质性。
论文组织如下。我们首先定义了我们的偏倚模型,用于将低偏倚风险和高偏倚危险的试验组合起来,并以代数形式获得结果,从而提供了对高风险偏倚试验信息内容的见解。然后我们展示了如何从荟萃流行病学数据(Schulz等。,1995)并研究各种扩展。接下来,我们考虑各种方法,在新的荟萃分析中,可以使用元流行病学分析的输出来引入关于偏倚参数的先验信息。我们将该模型应用于氯氮平的荟萃分析与精神分裂症的抗精神病药物治疗,以得出在该领域适当和不适当的分配隐蔽性试验的相对价值的具体结论。我们提出了敏感性分析,以研究治疗效果的最终估计及其精度如何依赖于偏差参数输入。最后,我们讨论了正在进行的各种建模假设,这种方法对国家决策者(如NICE)的可接受程度,以及在这些模型能够自信地用于实践之前需要做哪些进一步的工作,最后,我们结合其他方法讨论了我们的方法。
2.在单个荟萃分析中结合充分和不充分进行的试验的模型
2.1、。Bias模型
在给定的单一荟萃分析中米假设研究因其行为中的特定缺陷而被归类为低(L研究)或高(H研究)偏见风险n个L、,米L研究和n个H、,米H型研究。每项研究我提供了一个简要的治疗效果评估年我,米,标准误差σ我,米(其中我= 1,…,n个L、,米为L研究和我=(n个L、,米+1),…,(n个L、,米+n个H、,米)H型研究,以及米索引当前兴趣的meta分析)。我们假设L研究提供了对感兴趣的(固定的)真实治疗效果的无偏估计,即d日米H研究以研究特异性偏差估计了同样的治疗效果,β我,米为了获得分析结果,我们假设治疗效果是在一个连续的尺度上测量的,例如二元结果的log-odds比率,具有至少近似的正常似然,因此我们有基本模型
抽样方差被认为是已知的,因为它们通常是从每个荟萃分析的数据中很好地估计出来的。固定的基础处理效果是一个平坦的正态先验分布,d日米∼N个(0,1002)。
我们对研究特定偏差建立了一个层次模型,该模型捕获了可用于告知这些参数的经验证据的性质:
荟萃分析中的H研究米具有总体meta分析特定的平均偏差b条米,以及研究间的meta分析方差κ2.我们使(相当强大的)第7节)平均偏差假设b条米在荟萃分析中米可与其他荟萃分析的平均偏差互换,所有相关荟萃分析中的平均偏差都是相同的b条0平均偏差中的meta分析方差ϕ2.平均偏差b条0其本身因预期而不确定B0和方差五0。请注意五0代表不确定性,可以通过进一步的信息来减少,而κ2和ϕ2是内在的衡量标准变异.英寸第3节我们展示了如何估计κ2,ϕ2,B0和五0可以从荟萃流行病学数据中获得。
这个公式足够简单,使我们能够获得关于真实治疗效果的后验分布的一些分析结果d日米,同时仍然捕获证据库中固有的异质性和不确定性。这一方法提供了对以下因素的关键决定因素的见解d日米并有助于检查结果对各种模型输入的敏感性。然而,当我们考虑对此基本模型的扩展时,我们使用马尔可夫链蒙特卡罗(MCMC)模拟来获得结果。
2.2. 后向分布d日米在单个荟萃分析中
下面我们去掉下标米用于压实。跟随盖尔曼等。(2003)(第15.3节),我们可以将我们的层次先验结构视为附加数据,并以单一似然的形式编写这个层次线性模型:
哪里
第一个n个L(左)+n个H(H)数据向量行年和矩阵X(X)只需选择相关的可能性,条件是,用于观察到的低风险和高风险研究(方程式(1)和(2)). 以下内容n个H(H)行表示meta分析中研究间偏差的层次模型(方程式(3)). “观察到的”数据设置为0。这给出了正确的平均值,E类[β我−b条]=0,同时反映研究之间的meta分析方差κ2。下一行表示meta分析之间的差异(方程式(4)). 再次将“观察到的”数据设置为0,以给出正确的平均值,E类[b条−b条0]=0,同时反映荟萃分析之间的差异ϕ2最后一行表示荟萃分析中平均偏差的先验值(方程式(5)). 观测数据设置为B0给出正确的平均值,E类[b条0] =B0虽然反映了其中的不确定性,五0.
假设方差矩阵∑已知,因此参数的后验值γ可以通过加权最小二乘回归得到(Lindley和Smith,1972; 盖尔曼等。,2003):
对于我们的模型d日(的第一个元素γ)可以在封闭形式中找到:
哪里
后验平均治疗效果是L和H研究的加权平均值。L研究是按面值进行的,其方差权重为反。单个H研究的权重为估计值方差的倒数加上元分析方差中研究间的权重κ2然而,这也会乘以第二个加权因子的倒数w个,随着meta分析平均偏差的不确定性比率增加五0+ϕ2介于研究和荟萃分析之间,估计治疗效果的不确定性因此,如果与估计不确定性和研究间异质性相比,荟萃分析平均偏差的不确定性较大,则H研究的权重较小。换言之,如果我们不知道要进行的偏差调整,那么H研究就无法告诉我们多少关于治疗效果的信息,无论它有多大,也无论有多少这样的研究。
斯特恩等。(2008)已经描述了后验分布的一些性质(方程式(6)). 尤其是,H研究的信息内容有限。如果只有一项H研究,那么即使该试验规模很大,其权重仍会降低五0+ϕ2+κ2。即使有无限多的H研究,后验方差仍取决于荟萃分析平均偏差的不确定性五0+ϕ2注意,为了使该模型恢复到以面值处理所有高风险和低风险证据的标准固定效应荟萃分析,我们需要假设五0=ϕ2=κ2=B0= 0.
因此,为了正确调整H研究和降低H研究的权重,我们需要有关方差参数的信息五0,ϕ2和κ2以及平均偏差b条0.鉴于五0,κ2和b条0(理论上)可以从单个荟萃分析中进行估计,ϕ2不能。然而,所有参数都可以通过荟萃流行病学研究进行估计(斯特恩等。,2008)。
3.元流行病学分析,以估计偏差模型的输入
3.1. 荟萃流行病学分析模型
我们现在展示如何估计B0,五0,ϕ2和κ2来自数据。舒尔茨等。(1995)分析了由33个荟萃分析组成的数据集,米=1,…,33,其中每项研究的特点是根据分配的隐蔽性是否充分。总共有250个试验:79个充分隐藏(L研究)和171个不充分隐藏(H研究)。
斯特恩等。(2008)对Schulz数据(模型M1)进行了分析,该数据基于贝叶斯元分析的标准模型(史密斯等。,1995). 他们假设了一种固定的治疗效果,其中d日米表示纳入荟萃分析的所有试验中的真正治疗效果米,不考虑分配隐藏。结果第页一,我,米用于手臂一审判的我在荟萃分析中米假设具有二项式似然(对于给定分母n个一,我,米):
成功的概率,第页一,我,米,通过逻辑回归建模:
哪里μ我,米是控制臂成功的逻辑,d日米是治疗效果,X(X)我,米是分配隐藏的指示器(X(X)我,米=1,不足;X(X)我,米=0,足够)和β我,米研究中治疗效果的偏差我荟萃分析米该模型简单地推广了近似正态似然模型年我,米这在上一节中使用,以考虑二项式变化,并估计基本风险以及比值比。偏差模型与方程式(1)–(4); 然而,在荟萃流行病学分析中,我们对荟萃分析的平均偏差给予了一个平的先验值b条0所得的后部(具有平均值B0和方差五0)然后形成先验b条0在里面方程式(5)用于未来的荟萃分析。
N个(0,1002)事先已告知μ我,米,d日米和平均偏差b条0方差参数在标准偏差量表上给出均匀(0,10)的先验值。我们按照Gelman的建议对标准偏差使用统一的先验值(2006)并选择范围(0,10)在log-odds尺度上较大。结果对这些先前的变化相当稳健。通过使用WinBUGS 1.4.1软件(Spiegelhalter等。,2000). 根据Brooks–Gelman–Rubin诊断工具(Brooks和Gelman,1998). 这些“老化”模拟随后被丢弃,并进一步运行50000次迭代,所有推断都基于此。重新参数化使层次模型以零为中心可以提高收敛速度。
我们用三种方式扩展了模型M1。我们可以预料到κ2不同的meta分析会有所不同,因此一个自然的扩展是在meta分析中,估计研究之间的层次伽马分布的精确度,,在通用参数上具有平坦伽马先验值η和λM2模型扩展了M1模型,将随机效应分布纳入.后验中值η和λ然后可以通知在一项新的荟萃分析中。
M3模型通过纳入治疗效应的荟萃分析特定随机效应分布扩展了M1,因此固定治疗效应d日米被替换为,其中每个荟萃分析中的平均效应,d日米,被赋予平坦的正常先验值τ米给定均匀(0,10)先验。
最后,M4模型结合了治疗效应的荟萃分析特定随机效应分布和治疗效应的随机效应分布.
此处显示的所有模型的WinBUGS代码可从以下网址下载http://www.bristol.ac.uk/cobm/research/mpes.
3.2. 元流行病学分析结果
对于模型M1,平均偏差b条0后验均值为-0.47,后验标准差为0.095(表1). 这些输出提供了以下参数的估计方程式(5),即。和我们总结了方差参数及其后验中值。荟萃分析标准差内研究之间的后验中位数κ为0.49,meta分析之间的标准偏差ϕ为0.26。在第5节我们比较了使用Schulz分析的后验信息告知先验信息用于新的荟萃分析的各种方法,其中研究的特点是根据随机化分配隐藏是否充分。
表1中描述的M1–M4型号的后部总结第3节用于Schulz数据的荟萃流行病学分析†
| 参数. | 平均值. | 标准偏差. | 中值的. | 95%可信区间. |
|---|
| 模型M1:Schulz分析(固定治疗效果;κ2固定) |
| b条0 | −0.47 | 0.095 | −0.47 | (−0.65, −0.28) |
| ϕ | 0.26 | 0.131 | 0.26 | (0.02, 0.52) |
| κ | 0.50 | 0.062 | 0.49 | (0.38, 0.62) |
| 模型M2:Schulz分析(固定治疗效果; |
| b条0 | −0.45 | 0.094 | −0.45 | (−0.64, −0.27) |
| η | 7.28 | 3.892 | 6.26 | (3.17, 17.27) |
| λ | 1.38 | 3.138 | 0.41 | (0.06, 10.04) |
| ϕ | 0.24 | 0.131 | 0.24 | (0.01,0.51) |
| κ米 | 0.50 | 0.879 | 0.44 | (0.19, 1.13) |
| 模型M3:Schulz分析(随机处理效应,κ2固定的) |
| b条0 | −0.46 | 0.108 | −0.47 | (−0.66, −0.25) |
| ϕ | 0.15 | 0.106 | 0.13 | (0.01, 0.39) |
| κ | 0.11 | 0.085 | 0.10 | (0.00, 0.30) |
| 模型M4:Schulz分析(随机治疗效应;)) |
| b条0 | −0.44 | 0.119 | −0.43 | (−0.68, −0.21) |
| η | 22.27 | 11.20 | 19.83 | (7.24, 51.23) |
| λ | 3.21 | 5.083 | 1.26 | (0.06, 18.30) |
| ϕ | 0.14 | 0.110 | 0.12 | (0.00, 0.40) |
| κ米 | 0.24 | 0.104 | 0.23 | (0.13, 0.43) |
| 参数. | 平均值. | 标准偏差. | 中值的. | 95%可信区间. |
|---|
| 模型M1:Schulz分析(固定治疗效果;κ2固定) |
| b条0 | −0.47 | 0.095 | −0.47 | (−0.65, −0.28) |
| ϕ | 0.26 | 0.131 | 0.26 | (0.02, 0.52) |
| κ | 0.50 | 0.062 | 0.49 | (0.38, 0.62) |
| 模型M2:Schulz分析(固定治疗效果; |
| b条0 | −0.45 | 0.094 | −0.45 | (−0.64, −0.27) |
| η | 7.28 | 3.892 | 6.26 | (3.17, 17.27) |
| λ | 1.38 | 3.138 | 0.41 | (0.06, 10.04) |
| ϕ | 0.24 | 0.131 | 0.24 | (0.01, 0.51) |
| κ米 | 0.50 | 0.879 | 0.44 | (0.19, 1.13) |
| 模型M3:Schulz分析(随机处理效应,κ2固定的) |
| b条0 | −0.46 | 0.108 | −0.47 | (−0.66, −0.25) |
| ϕ | 0.15 | 0.106 | 0.13 | (0.01, 0.39) |
| κ | 0.11 | 0.085 | 0.10 | (0.00, 0.30) |
| 模型M4:Schulz分析(随机治疗效应;)) |
| b条0 | −0.44 | 0.119 | −0.43 | (−0.68, −0.21) |
| η | 22.27 | 11.20 | 19.83 | (7.24,51.23) |
| λ | 3.21 | 5.083 | 1.26 | (0.06, 18.30) |
| ϕ | 0.14 | 0.110 | 0.12 | (0.00,0.40) |
| κ米 | 0.24 | 0.104 | 0.23 | (0.13, 0.43) |
表1中描述的M1–M4型号的后部总结第3节用于Schulz数据的荟萃流行病学分析†
| 参数. | 平均值. | 标准偏差. | 中值的. | 95%可信区间. |
|---|
| 模型M1:Schulz分析(固定治疗效果;κ2固定) |
| b条0 | −0.47 | 0.095 | −0.47 | (−0.65, −0.28) |
| ϕ | 0.26 | 0.131 | 0.26 | (0.02, 0.52) |
| κ | 0.50 | 0.062 | 0.49 | (0.38, 0.62) |
| 模型M2:Schulz分析(固定治疗效果; |
| b条0 | −0.45 | 0.094 | −0.45 | (−0.64, −0.27) |
| η | 7.28 | 3.892 | 6.26 | (3.17, 17.27) |
| λ | 1.38 | 3.138 | 0.41 | (0.06, 10.04) |
| ϕ | 0.24 | 0.131 | 0.24 | (0.01, 0.51) |
| κ米 | 0.50 | 0.879 | 0.44 | (0.19, 1.13) |
| 模型M3:Schulz分析(随机处理效应,κ2固定的) |
| b条0 | −0.46 | 0.108 | −0.47 | (−0.66, −0.25) |
| ϕ | 0.15 | 0.106 | 0.13 | (0.01, 0.39) |
| κ | 0.11 | 0.085 | 0.10 | (0.00, 0.30) |
| 模型M4:Schulz分析(随机治疗效应;)) |
| b条0 | −0.44 | 0.119 | −0.43 | (−0.68, −0.21) |
| η | 22.27 | 11.20 | 19.83 | (7.24, 51.23) |
| λ | 3.21 | 5.083 | 1.26 | (0.06, 18.30) |
| ϕ | 0.14 | 0.110 | 0.12 | (0.00, 0.40) |
| κ米 | 0.24 | 0.104 | 0.23 | (0.13, 0.43) |
| 参数. | 平均值. | 标准偏差. | 中值的. | 95%可信区间. |
|---|
| 模型M1:Schulz分析(固定治疗效果;κ2固定) |
| b条0 | −0.47 | 0.095 | −0.47 | (−0.65,−0.28) |
| ϕ | 0.26 | 0.131 | 0.26 | (0.02, 0.52) |
| κ | 0.50 | 0.062 | 0.49 | (0.38, 0.62) |
| M2型:舒尔茨分析(固定治疗效果; |
| b条0 | −0.45 | 0.094 | −0.45 | (−0.64, −0.27) |
| η | 7.28 | 3.892 | 6.26 | (3.17, 17.27) |
| λ | 1.38 | 3.138 | 0.41 | (0.06, 10.04) |
| ϕ | 0.24 | 0.131 | 0.24 | (0.01, 0.51) |
| κ米 | 0.50 | 0.879 | 0.44 | (0.19, 1.13) |
| 模型M3:Schulz分析(随机处理效应,κ2固定的) |
| b条0 | −0.46 | 0.108 | −0.47 | (−0.66,−0.25) |
| ϕ | 0.15 | 0.106 | 0.13 | (0.01, 0.39) |
| κ | 0.11 | 0.085 | 0.10 | (0.00, 0.30) |
| 模型M4:Schulz分析(随机治疗效应;)) |
| b条0 | −0.44 | 0.119 | −0.43 | (−0.68, −0.21) |
| η | 22.27 | 11.20 | 19.83 | (7.24, 51.23) |
| λ | 3.21 | 5.083 | 1.26 | (0.06, 18.30) |
| ϕ | 0.14 | 0.110 | 0.12 | (0.00, 0.40) |
| κ米 | 0.24 | 0.104 | 0.23 | (0.13, 0.43) |
表1还显示了M2–M4型的后部总结。估计平均偏差对模型的选择相当稳健。然而,元分析间偏差变化的估计值以及研究之间、meta分析中的变异如果使用随机效应模型进行治疗效果,则会降低。这有可能对偏倚高风险研究的假定信息内容产生强烈影响。因此,在形成新荟萃分析的先验数据之前,我们需要仔细考虑荟萃流行病学数据模型的选择。同样重要的是,用于新的荟萃分析的模型与用于形成先前输入的模型相同。
4.固定或随机处理效果:模型拟合和选择
在偏差模型中(方程式(3)–(5))我们已经假设了随机效应;因此,仅使用充分隐藏的证据来决定是否使用固定或随机效应模型来获得真正的治疗效果似乎是合理的。表2显示了残余偏差的后验平均值,,有效参数数,第页天和偏差信息标准DIC(Spiegelhalter等。,2002)对于Schulz数据的固定效应和随机效应处理模型,仅基于充分隐蔽的研究。DIC是剩余偏差的总和以及参数的有效数量,第页天,并提供了一种衡量模型拟合程度的方法,以降低模型的复杂性。由于似然和模型参数之间的非线性,我们计算第页天拟合值的后验均值,而不是参数的后验平均值(Welton和Ades,2005). 我们看到,尽管随机治疗效果模型具有更好的拟合度(较低,它还有更多的参数(更高第页天)因此具有较高的DIC。因此,仅充分隐藏的证据就表明,固定的治疗效果模型更为节俭。然而,即使没有证据表明治疗效果存在异质性,我们可能仍然认为假设一个固定效应模型是不合适的,因为这一假设将在所有荟萃分析(包括新的荟萃分析)中被强制保持。
表2后验平均剩余偏差,有效参数数,第页天和偏差信息标准DIC用于荟萃流行病学分析†
| 模型. | . | 第页天. | 驾驶员信息中心. |
|---|
| Schulz数据中充分隐藏的证据 |
| 固定治疗效果 | 179.7 | 115 | 294.7 |
| 随机治疗效果 | 156.5 | 145.8 | 302.3 |
| Schulz数据中充分且不充分隐藏的证据 |
| M1,固定处理效果;κ固定的 | 538.1 | 373.7 | 911.8 |
| M2,固定处理效果;κ米随机的,随机的 | 535.8 | 370.2 | 906 |
| M3,随机处理效果;κ固定的 | 500.6 | 401.6 | 902.2 |
| M4,随机治疗效果;κ米随机的,随机的 | 497.3 | 405.6 | 902.9 |
| 模型. | . | 第页天. | 驾驶员信息中心. |
|---|
| Schulz数据中充分隐藏的证据 |
| 固定治疗效果 | 179.7 | 115 | 294.7 |
| 随机治疗效果 | 156.5 | 145.8 | 302.3 |
| Schulz数据中充分且不充分隐藏的证据 |
| M1,固定处理效果;κ固定的 | 538.1 | 373.7 | 911.8 |
| M2,固定处理效果;κ米随机的,随机的 | 535.8 | 370.2 | 906 |
| M3,随机处理效果;κ固定的 | 500.6 | 401.6 | 902.2 |
| M4,随机治疗效果;κ米随机的,随机的 | 497.3 | 405.6 | 902.9 |
表2后验平均剩余偏差,有效参数数,第页天和偏差信息标准DIC用于荟萃流行病学分析†
| 模型. | . | 第页天. | 驾驶员信息中心. |
|---|
| Schulz数据中充分隐藏的证据 |
| 固定治疗效果 | 179.7 | 115 | 294.7 |
| 随机治疗效果 | 156.5 | 145.8 | 302.3 |
| Schulz数据中充分且不充分隐藏的证据 |
| M1,固定处理效果;κ固定的 | 538.1 | 373.7 | 911.8 |
| M2,固定治疗效果;κ米随机的,随机的 | 535.8 | 370.2 | 906 |
| M3,随机处理效果;κ固定的 | 500.6 | 401.6 | 902.2 |
| M4,随机治疗效果;κ米随机的,随机的 | 497.3 | 405.6 | 902.9 |
| 模型. | . | 第页天. | 驾驶员信息中心. |
|---|
| Schulz数据中充分隐藏的证据 |
| 固定治疗效果 | 179.7 | 115 | 294.7 |
| 随机治疗效果 | 156.5 | 145.8 | 302.3 |
| Schulz数据中充分且不充分隐藏的证据 |
| M1,固定处理效果;κ固定的 | 538.1 | 373.7 | 911.8 |
| M2,固定处理效果;κ米随机的,随机的 | 535.8 | 370.2 | 906 |
| M3,随机治疗效果;κ固定的 | 500.6 | 401.6 | 902.2 |
| M4,随机治疗效果;κ米随机的,随机的 | 497.3 | 405.6 | 902.9 |
表2还显示了基于四种不同型号M1–M4的充分和不充分隐蔽试验的模型拟合。有趣的是,尽管M2模型(随机效应具有类似的,实际有效参数数减少,导致固定治疗效果模型中的DIC降低。这似乎违反了直觉——越复杂的模型复杂度越低,第页天然而,随机效应模型其结果是总体上在偏置参数中存在较高程度的收缩,从而导致总体上较低的参数有效数量。
根据证据,在这些模型之间没有什么可供选择的。我们将初步提出M4,即随机治疗效应模型和随机效应这是因为固定的治疗效果模型对于一般用途来说过于严格,而且研究间的偏差变化在不同的荟萃分析中不太可能相同。然而,我们必须承认,不充分隐藏的证据被轻视的程度可能对模型选择敏感。无论我们选择哪种模型进行荟萃流行病学分析,在新荟萃分析的分析中都应使用相同的模型。
5.新荟萃分析中的偏差调整治疗效果评估:对模型选择和先验格式的敏感性
5.1. 对车型选择的敏感性
我们现在展示如何将从Schulz数据分析中获得的偏见参数的循证先验引入新的荟萃分析。我们以比较氯氮平研究的荟萃分析为例与精神分裂症的抗精神病药物治疗(沃尔贝克等。,1998). 每个研究中的分配隐藏被分为不充分、不清楚或充分。数据以二项式计数的形式出现,我们使用了逻辑回归模型,如方程式(7),用于单一荟萃分析米,偏差模型如下所示方程式(1)–(5).
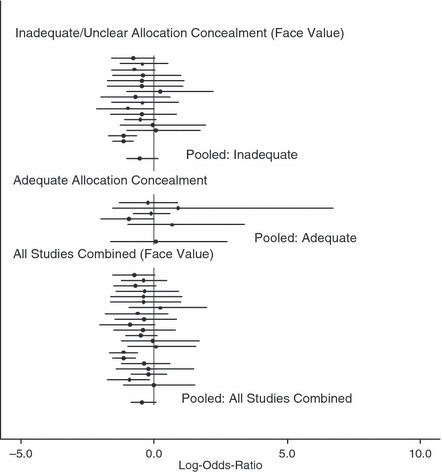
我们首先根据高风险和低风险偏倚试验的单独荟萃分析来评估联合治疗效果(表3). 这使我们能够在拟合更复杂的模型来调整偏差之前,调查高风险研究中的偏差程度。如果仅包括充分隐藏的试验,则合并(固定效应)对数-加总比率的后验均值为-0.321(95%可信区间(CI)-0.84至0.19),而对于未充分隐藏的研究,其后验均值则为-0.884(95%CI-1.13至-0.64),这表明这些研究存在偏差。注意,充分隐藏和不充分隐藏研究之间的后验平均合并对数-加总比率差异为-0.563,这与Schulz数据分析中平均偏差的估计95%置信区间一致(95%置信区间-0.65至-0.28)(表1). 如果所有证据都是按表面价值得出的,则后验平均合并对数-加总比率为-0.781(95%CI−1.13 to−0.64),介于两者之间,但更接近于规模更大、数量更多、未充分隐蔽研究的平均值。随机效应模型得到了不同的估计,因为显示出最强效应的大型研究的权重相对较小(图1). 然而,从表面上看,所有证据的综合效应再次介于充分隐藏和不充分隐藏研究的综合效应之间。
表3氯氮平荟萃分析中合并治疗效果(log-odds-ratio)的后验总结†
| Bias模型. | 以下治疗效果模型的后验平均值(95%可信区间):. |
|---|
| 固定效果. | 随机效应. |
|---|
| 面值 |
| 充分隐蔽的研究 | −0.321 (−0.836, 0.193) | −0.065 (−1.682, 2.840) |
| 隐蔽性研究不足 | −0.884(−1.129,−0.641) | −0.533 (−1.031, 0.130) |
| 充分和不充分的隐蔽研究相结合 | −0.781 (−1.002, −0.562) | −0.452 (−0.883, 0.081) |
| 型号M1 | M3型 |
| 偏置调整,κ固定 |
| Schulz关节后部的非参数先验采样 | −0.244 (−0.656, 0.152) | −0.145 (−0.630, 0.438) |
| 参数化优先级 |
| κ,ϕ常数 | −0.249 (−0.663, 0.162) | −0.149 (−0.613, 0.430) |
| κ,ϕ随机的,随机的 | 二元正态分布, | 独立γ, |
| −0.241 (−0.656, 0.165) | −0.133 (−0.609, 0.448) |
| M2型 | M4型 |
| 偏差调整,κ米随机的,随机的 |
| Schulz关节后部的非参数先验采样 | −0.259 (−0.664, 0.143) | −0.150 (−0.644, 0.450) |
| 参数化优先级 |
| η,λ,ϕ常数 | −0.256 (−0.658, 0.144) | −0.144 (−0.625, 0.439) |
| η,λ,ϕ随机的,随机的 | η,λ伽玛射线;ϕ正常, | η,λ,ϕ伽玛, |
| −0.260 (−0.669, 0.147) | −0.142 (−0.634, 0.437) |
| Bias模型. | 以下治疗效果模型的后验平均值(95%可信区间):. |
|---|
| 固定效果. | 随机效应. |
|---|
| 面值 |
| 充分隐蔽的研究 | −0.321 (−0.836, 0.193) | −0.065 (−1.682, 2.840) |
| 隐蔽性研究不足 | −0.884(−1.129,−0.641) | −0.533 (−1.031, 0.130) |
| 充分和不充分的隐蔽研究相结合 | −0.781 (−1.002, −0.562) | −0.452 (−0.883, 0.081) |
| 型号M1 | M3型 |
| 偏置调整,κ固定 |
| Schulz关节后部的非参数先验采样 | −0.244 (−0.656, 0.152) | −0.145 (−0.630, 0.438) |
| 参数化优先级 |
| κ,ϕ常数 | −0.249 (−0.663, 0.162) | −0.149 (−0.613, 0.430) |
| κ,ϕ随机的,随机的 | 二元正态分布, | 独立γ, |
| −0.241 (−0.656, 0.165) | −0.133 (−0.609, 0.448) |
| M2型 | M4型 |
| 偏差调整,κ米随机的,随机的 |
| Schulz关节后部的非参数先验采样 | −0.259 (−0.664, 0.143) | −0.150 (−0.644, 0.450) |
| 参数化优先级 |
| η,λ,ϕ常数 | −0.256 (−0.658, 0.144) | −0.144 (−0.625, 0.439) |
| η,λ,ϕ随机的,随机的 | η,λ伽玛射线;ϕ正常, | η,λ,ϕ伽玛, |
| −0.260 (−0.669, 0.147) | −0.142 (−0.634, 0.437) |
表3氯氮平荟萃分析中合并治疗效果(log-odds-ratio)的后验总结†
| Bias模型. | 以下治疗效果模型的后验平均值(95%可信区间):. |
|---|
| 固定效果. | 随机效应. |
|---|
| 面值 |
| 充分隐蔽的研究 | −0.321(−0.836,0.193) | −0.065 (−1.682, 2.840) |
| 隐蔽性研究不足 | −0.884 (−1.129, −0.641) | −0.533 (−1.031, 0.130) |
| 充分和不充分的隐蔽研究相结合 | −0.781 (−1.002, −0.562) | −0.452(−0.883、0.081) |
| 型号M1 | M3型 |
| 偏差调整,κ固定 |
| Schulz关节后部的非参数先验采样 | −0.244 (−0.656, 0.152) | −0.145 (−0.630, 0.438) |
| 参数化优先级 |
| κ,ϕ常数 | −0.249 (−0.663, 0.162) | −0.149 (−0.613, 0.430) |
| κ,ϕ随机的,随机的 | 二元正态分布, | 独立γ, |
| −0.241 (−0.656, 0.165) | −0.133 (−0.609, 0.448) |
| M2型 | M4型 |
| 偏差调整,κ米随机的,随机的 |
| Schulz关节后部的非参数先验采样 | −0.259 (−0.664, 0.143) | −0.150 (−0.644, 0.450) |
| 参数化优先级 |
| η,λ,ϕ常数 | −0.256(−0.658,0.144) | −0.144 (−0.625, 0.439) |
| η,λ,ϕ随机的,随机的 | η,λ伽玛射线;ϕ正常, | η,λ,ϕ伽马射线, |
| −0.260 (−0.669, 0.147) | −0.142 (−0.634, 0.437) |
| Bias模型. | 以下治疗效果模型的后验平均值(95%可信区间):. |
|---|
| 固定效果. | 随机效应. |
|---|
| 面值 |
| 充分隐蔽的研究 | −0.321(−0.836,0.193) | −0.065 (−1.682, 2.840) |
| 隐蔽性研究不足 | −0.884 (−1.129, −0.641) | −0.533 (−1.031, 0.130) |
| 充分和不充分的隐蔽研究相结合 | −0.781 (−1.002, −0.562) | −0.452(−0.883、0.081) |
| 型号M1 | M3型 |
| 偏差调整,κ固定 |
| Schulz关节后部的非参数先验采样 | −0.244 (−0.656, 0.152) | −0.145 (−0.630, 0.438) |
| 参数化优先级 |
| κ,ϕ常数 | −0.249 (−0.663, 0.162) | −0.149 (−0.613, 0.430) |
| κ,ϕ随机的,随机的 | 二元正态分布, | 独立γ, |
| −0.241 (−0.656, 0.165) | −0.133 (−0.609, 0.448) |
| M2型 | M4型 |
| 偏差调整,κ米随机的,随机的 |
| Schulz关节后部的非参数先验采样 | −0.259 (−0.664, 0.143) | −0.150 (−0.644, 0.450) |
| 参数化优先级 |
| η,λ,ϕ常数 | −0.256(−0.658,0.144) | −0.144 (−0.625, 0.439) |
| η,λ,ϕ随机的,随机的 | η,λ伽玛射线;ϕ正常, | η,λ,ϕ伽马射线, |
| −0.260 (−0.669, 0.147) | −0.142 (−0.634, 0.437) |
图1
随机效应模型的后验平均研究特异性和合并治疗效应(以对数-加数比表计),95%置信区间,分别用于未充分隐藏(按面值计算)和充分隐藏的试验:此外,当两种类型的研究合并并按面值计算时,会显示结果
我们可能预计,偏差调整后的后验平均合并对数比值比(对于固定治疗效果模型)介于−0.321和−0.884+0.47=−0.414之间,−0.321是充分隐蔽研究的面值估计值,−0.884+0.47=−0.414是经平均偏差调整后的不充分隐蔽研究的面值估计值。也许与直觉相反,经后验平均偏差调整的合并估计值为-0.244(95%CI−0.66至0.15)(表3). 然而,偏见模型本质上是分层的,就像随机治疗效果模型一样,对大型研究的权重相对较小,在本例中,大型研究也是显示最大治疗效果的研究。随机效应模型对偏差和偏差调整的综合影响是将综合治疗效果估计值实质上转向无影响的方向。每一个经偏差调整的模型都没有提供多少治疗效果的证据,与从表面上看不充分隐藏证据的分析相比(表3)。
将分析扩展到随机治疗效应模型会导致更大的后验标准偏差,并减少治疗效应大小。这部分是因为较大的研究(在固定效应分析中具有相对较大的权重)显示了本例中较大的治疗效应(图1),但也因为方差参数的先验输入对随机或固定效应模型的使用很敏感(表1). 如上所述,我们可能预计经偏差调整后的后验平均log-odds比率介于−0.065和−0.533+0.47=−0.063之间,而实际上,经组合偏差调整的估计值为−0.145(95%CI−0.63到0.44)(表3). 对于随机效应模型,治疗效果强于直觉预期。这也是偏倚分层模型的结果,这导致了偏倚调整模型中治疗效果的估计研究间异质性降低。因此,与以表面价值获取证据的模型相比,更重视具有强大治疗效果的大型研究。
5.2. 对先验信息格式的敏感性
接下来,我们将更详细地考虑如何将基于Schulz数据分析的先验信息引入新的荟萃分析。在上述结果中(表3),我们从Schulz分析的关节后验分布中取样,以形成关节先验b条0,κ和ϕ(用于κ固定的;型号M1和M3)或b条0,η,λ和ϕ(用于κ米随机;M2和M4型)。我们通过保存Schulz分析中的MCMC链(每25次迭代减薄一次)(生成2000条记录)来实现这一点,然后从这些2000条记录中进行替换取样,以提供非参数关节先验。
荟萃分析人员可能无法获得完整的相关荟萃流行病学数据集,也无法从荟萃流行病学分析中获得MCMC链。可以进行几种可能的参数近似。我们可以直接进入κ和ϕ(用于κ固定的;型号M1和M3)或η,λ和ϕ(用于κ米随机;M2和M4型)作为常数方程式(3)–(5),从Schulz输出中获取它们的后验中值。或者,我们可以治疗κ和ϕ,或η,λ和ϕ,并尝试根据Schulz分析的输出,以参数逼近其联合分布。不可避免地,这里会有各种各样的建模选项(中描述的近似值表3仅代表一个这样的选择),提出了进一步的问题,即MCMC输出是否已在近似值中充分捕获。
这些形成先验的不同方法具有广泛的可比性(表3),随机和恒定的先验偏差参数给出了估计的偏差调整治疗效果,接近于使用Schulz全关节后置模型获得的效果等。(1995)作为之前。对于随机模型,不同模型的结果略有不同,但没有一致的模式。
6.偏倚高风险证据的贡献:对偏倚模型参数的敏感性
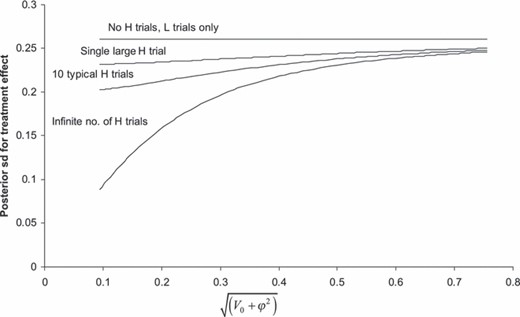
从这一分析中可以清楚地看出,经偏倚调整的估计治疗效果及其后验不确定性将对元流行病学模型的偏倚模型的输入敏感。代数解(方程式(6))对于基本偏差模型,我们可以通过直接评估给定输入值的后验总结或查看给定输入的导数,对先前输入进行更详细的敏感性分析。例如,图2显示了治疗效果的后验标准差如何随着荟萃分析中的先验不确定度(标准偏差量表上)的增加而增加(对于设置为0.25,即Schulz数据固定治疗效果模型的后验均值)。√值越大(五0+ϕ2)偏倚高风险的证据越被低估。随着偏倚高风险研究的数量从单一(即使非常大)研究增加到10项典型规模的研究,再到无限多的研究,治疗效果的后验标准差降低(图2). 对后验不确定性的影响取决于√的值(五0+ϕ2). 基于Schulz数据的固定治疗效果模型,√的后验均值(五0+ϕ2)为0.52,CI为(0.17,0.73)。当√(五0+ϕ2)=0.52,则后验标准差从无偏倚高风险研究的0.260下降到有偏倚风险高的单个大型研究的0.245,到有偏斜高风险的10个典型研究的0.239,再到无限多偏倚高危研究的0.233。因此,在这种情况下,由于使用具有高偏差风险的数据,后验不确定性的减少相对较小。
图2
固定治疗效果后验标准差d日米,根据荟萃分析特定平均偏差√的先前标准偏差绘制(五0+ϕ2),对于四种情况(其中L表示偏见的低风险,H表示偏见的高风险),仅L试验,一个无限大小的单一H试验,10个典型的H试验(来自Schulz数据)方差为以及无限数量的H试验:在所有情况下,都使用了氯氮平例子中的L证据设为0.25,即Schulz数据固定治疗效果模型的后验均值;√的后CI(五0+ϕ2)基于Schulz数据的固定治疗效果模型为(0.17,0.73)
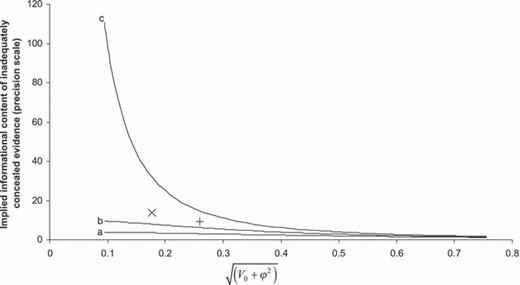
查看获得由于纳入了具有高偏差风险的证据,精确度(定义为1/方差)降低。这只是H试验的精度减去无H试验的精确度。这是针对中的各种场景绘制的图3。例如,如果√(五0+ϕ2)取95%置信区间(0.17,0.73)上的值,包括10次典型H试验(精度为1/0.7=1.43)的精度增益等于5.7(=pt(磅)8.1/1.43)和1.1(=pt(磅)1.6/1.43)按面值进行的典型试验。我们发现,除非√(五0+ϕ2)低(接近本分析中其CI限值的下限)。图3还显示了用以下公式拟合固定和随机处理效果模型的数值结果随机进入氯氮平荟萃分析,其中有16项试验具有较高的偏倚风险。随机效应分析的主要特征是√的后验均值(五0+ϕ2)位于CI的低端,并且将具有高偏差风险的试验包括在内,在精确度方面获得的收益更大。因此(至少对于氯氮平的例子),与随机效应模型相比,固定效应模型可能会导致对具有高偏倚风险的证据进行更多的加权。
图3
高风险偏差证据的隐含信息含量(精密度包括H试验减去仅L试验的精密度),与荟萃分析特异性平均偏差的先前标准偏差进行绘制,√(五0+ϕ2):给出了单个无限大小H试验(曲线a)的结果,10个H试验的典型方差(来自舒尔茨数据)为(曲线b)和无限数量的H试验(曲线c);在所有情况下,均使用氯氮平示例中的L-证据设为0.25,即Schulz数据固定治疗效果模型的后验均值;具有随机性的固定和随机处理效应模型的数值结果叠加氯氮平荟萃分析;√的后95%置信区间(五0+ϕ2)基于Schulz数据的固定治疗效应模型为(0.17,0.73)(×,氯氮平,随机效应模型;+,氯氮碱,固定效应模型)
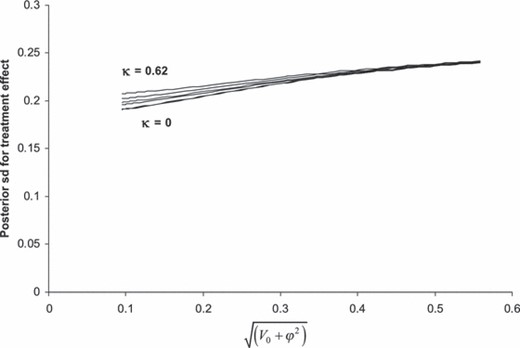
图4显示了对于10个具有高偏倚风险的典型规模研究,这种关系如何随着κ.增加研究间偏差的异质性κ导致治疗效果的后标准差适度增加。例如,当√(五0+ϕ2)=0.52(固定治疗效果模型的平均值),则后验标准差从0.240降至0.238κ从0.62降至0。随机效应模型导致κ从而更加重视偏倚风险高的证据。然而,图2和4表明治疗效果的后验标准差对荟萃分析特异性平均偏差√的不确定性变化更为敏感(五0+ϕ2),而不是到κ对于固定效应模型,通过考虑方程式(6).
图4
治疗效果后标准差d日米,根据荟萃分析特定平均偏差√的先前标准偏差绘制(五0+ϕ2)对于的六个值κ代表固定后的2.5%、50%和95%(κ=0.38、0.49、0.62)和随机-(κ=0,0.1,0.3)Schulz数据的效应模型:在所有情况下,均使用氯氮平示例中的低风险偏差证据,10次H试验的典型(来自Schulz的数据)方差为
7.讨论
任何包含偏倚高风险和低风险研究的荟萃分析都应比较结果,以评估治疗效果和相应的精确度,包括和排除高风险证据(按面值计算)。然而,荟萃分析中的信息通常太少,无法准确估计低风险和高风险研究中治疗效果之间的差异(Sterne等。,2002). 因此,无论包括或排除高风险证据的治疗效果评估是否一致,我们仍应更加相信低风险证据。以表面价值进行高风险研究会低估治疗效果的不确定性,这可能会对任何最终的决策分析产生影响。本文提出的偏差调整模型试图捕捉这种不确定性,以及低风险和高风险研究中治疗效果评估之间的系统差异。
在观察性或随机研究中,最近有相当多的关于解决偏差的方法的讨论。迄今为止发表的大多数提案都是重估方案,这些方案使证据具有较高的偏倚风险,权重较低(Begg和Pilote,1991; 李和贝格,1994; Larose和Dey,1997; 上一个等。,2000; Spiegelhalter和Best,2003). 埃迪等。(1992)指出,这减轻了偏见,但并没有消除偏见。我们的方法可以从两个方面与之前的工作区分开来。首先,我们提出的偏倚模型包含了研究之间、荟萃分析内部和荟萃分析之间平均偏倚程度的变化。此外,我们在此估计中包括了估计的总体平均偏差项和相应的不确定性。这不仅会降低潜在偏见证据的权重,而且至少在原则上,也会导致无偏见的汇总估计。第二,我们将偏见模型的参数建立在从以前发表的荟萃分析收集的经验证据上,因为单一荟萃分析通常只提供关于偏见程度的有限信息(Egger等。,2003; 斯特恩等。,2002). 当然,这需要一个强有力的假设,即新荟萃分析中的平均偏差可以与之前实证(荟萃流行病学)研究中的荟萃分析的平均偏差互换。例如,舒尔茨研究中的荟萃分析等。(1995)主要来自妇幼保健研究,我们必须怀疑精神分裂症药物研究(氯氮平示例荟萃分析)中的平均偏差是否可以与荟萃分析集合中的平均偏见互换。
我们的示例重点关注由于分配隐藏不足而导致的偏差问题,这是一些实证调查的主题(尽管在某些方面,这只是探索统计方法和建模假设含义的工具)。我们的敏感性分析表明,由于荟萃分析特异性平均偏差√的不确定性相对较高,不充分隐藏分配的研究对治疗效果的精确性贡献甚微(五0+ϕ2). 如果由于几乎没有足够的隐蔽证据和/或由于使用了随机治疗效果模型,仅基于充分隐蔽证据的治疗效果精确度较低,则不充分隐蔽的证据可能有用。否则,我们将暂时建议,根据现有证据,纳入不充分隐蔽试验的证据几乎没有价值。
我们已经澄清了将以前的荟萃流行病学研究中的信息引入新的荟萃分析中的一些技术问题。理想情况下,荟萃流行病学分析的联合后验分布应用于形成新荟萃分析的先验分布。这将需要访问完整的荟萃流行病学数据库(一般来说不太现实)或MCMC从此类分析中得出的结果,我们主张将其普遍可用。我们发现,插入偏差方差参数的后验中值会产生结果,在本例中,该结果可以充分近似于偏差模型参数的完整联合分布。然而,这需要在更广泛的示例中进行更全面的探讨,尤其是当联合分布不对称和/或参数高度相关时。
最近,开发了一个更大的荟萃分析数据库(Wood等。,2008),可用于在新的荟萃分析中形成偏倚的先兆。木材等。(2008)证实了治疗效果取决于分配隐蔽性,也发现了缺乏盲法的证据。有趣的是,当主观评估结果时,偏见的证据要比客观评估或使用全因死亡率结果时强得多。这表明,如果荟萃流行病学数据能够更具体地适应新的荟萃分析,也许侧重于类似医学领域的研究,并采用相同的结果测量,则可能减少品种不同的meta分析,从而生成一个证据库,其中估计ϕ2,meta分析之间的变异较小。这种方法还可以解决困难但关键的可交换性假设,即在有问题的荟萃分析中偏倚风险高的研究中的平均偏倚可以与流行病学数据库中荟萃分析的平均偏爱互换。然而,证据库规模的缩小会增加五0,平均偏差预期的不确定性。因此,可能会减少五0或ϕ2只能以牺牲另一方的利益为代价来完成,这表明,高风险偏见研究所能提供的信息量有明确的限制,无论人们如何仔细地为先验者量身定做证据基础。
荟萃流行病学研究本质上是观察性的,因此可能会受到混杂因素的影响。之所以会产生困惑,是因为由于其行为中的某一特定缺陷而导致偏见的高风险研究比其他研究更有可能在其行为中存在进一步的缺陷。伍德解决了这种可能性等。(2008)他发现,在没有盲法的情况下进行控制时,分配隐蔽性不足的影响会适度减弱,反之亦然。这种混淆的可能性意味着分配隐蔽性不足可能不是原因中确定的偏差表1; 然而,分配隐蔽性不足可能仍然被认为是偏倚风险较高的研究的替代品。
Siersma公司等。(2007)讨论了允许这种混淆的统计模型。通过在荟萃流行病学分析中添加回归项,可以调整潜在的混杂因素方程式(7)将相互作用项合并到方程中也很简单(7)这使得平均偏差可以根据诸如结果变量是主观评估还是客观评估等特征而变化。在一项新的荟萃分析中,我们还可以将协变量项添加到方程式(1)和(2)例如,临床医生可能感兴趣的具有差异治疗效果的患者亚组。
这里介绍的模型都假设了试验和荟萃分析的统计独立性。如果在一个以上的荟萃分析中包括一些试验,那么这些假设将被违背。大多数已发表的荟萃流行病学分析都非正式地处理了这个问题,包括解决不同临床问题的荟萃分析,以及每个系统综述只包括一个荟萃分析。木材等。(2008)综合三项荟萃流行病学研究的数据。他们通过使用PubMed或类似标识符对所有试验进行索引来处理重叠,这些标识符用于识别那些包含重叠试验的荟萃分析。删除了荟萃分析,以确保所分析的数据集重叠最小。另一种选择是使用建模技术,该技术可以考虑重复所暗示的相关性,例如交叉分类随机效应(Patterson和Thompson,1971)使用MCMC模拟进行建模(Browne等。,2001)。
在这里,我们限制了对随机对照试验的关注。将这些方法扩展到包括观察性研究的证据是有意义的,并且原则上是可能的。然而,与随机对照试验相比,在收集关于观察性研究治疗效果估计偏差的大小和变异性的经验元流行病学证据方面存在很大的实际困难。尽管在随机对照试验和观察性研究(Deeks等。,2003),我们不知道这些差异的方差的公开估计。许多实证研究都是基于已发表的荟萃分析的便利样本(麦克莱霍斯等。,2000; 孔卡托等。,2000),可能不具有代表性。因此,当结合观察性研究和随机对照试验的证据时,可交换性假设可能更难以证明其合理性。
最后,我们反思了我们的结果对未来在卫生保健干预评估中使用偏差调整方法的潜在影响。在国家决策者(如NICE)的背景下,所做的任何决策都需要得到患者群体和制药行业等接受的证据的支持。因此,至关重要的是,所有建模假设都是透明和可复制的,并且不允许解释。目前,似乎至少有三个障碍阻碍了这些方法的常规使用。
首先,一个关键的假设是,新的荟萃分析可以被认为与现有证据库中的分析是可交换的。伍德的成果等。(2008)建议我们当然需要考虑临床领域和结果之间偏差的可变性。然而,可能还有其他可能的偏见机制,这可能会使可互换性假设存在争议。其次,本文关注的是作为二进制变量编码的单一偏差源。如前所述,还需要进一步的工作来概括这一点,以解释偏见的多种来源,并处理混淆。尽管这种针对多个偏置源的模型在技术上是可行的(Eddy等。,1992; 格陵兰,2005; Siersma公司等。,2007)这将增加对可交换性假设的依赖,以及对meta流行病学数据模型的敏感性。接受这些方法的第三个障碍是估计治疗效果对采用固定或随机效应治疗模型的敏感性(表3). 选择固定效应模型可能会导致对偏倚高风险的证据进行更大的权重降低,而随机效应模型可能给出偏倚风险高的证据相对权重更大。
当然,随着建立更全面的荟萃流行病学数据库,可以更详细地检查使用精心定制的先前证据子集的可能性,以及多个偏差来源的问题。这些分析无疑将增加我们对偏差机制的了解,导致方法的改进,最重要的是为偏差调整提供更好的经验基础。然而,很容易想象,如果一家公司的药物不被推荐,那么该公司可能会对一种降低其疗效证据的方法产生争议,尤其是如果建模假设或荟萃流行病学数据中的微小变化产生了更有利的结果。
总之,健康干预评估的“所有可用证据”方法以增加偏差风险为代价,牺牲了提高的准确性。这里介绍的模型提供了一种方法,可以降低并调整潜在的偏差。然而,在我们目前的知识状态下,这里提出的模型还不能被放心地用于健康干预评估,除非对模型输入的敏感性进行彻底和广泛的分析之后,才能决定采用哪种干预措施。
致谢
作者感谢Simon Thompson教授(剑桥医学研究委员会生物统计学组)和其他对本论文早期版本发表评论的人,该论文已提交给研讨会“解释复杂概率建模的结果:冲突、一致性和敏感性分析”,该项目由医学研究委员会人口健康科学研究网络赞助,于2006年9月7日至8日在剑桥举行。我们还感谢两位评委对本文件早些时候的草案所作的非常有益的评论。
工具书类
贝格
,C.B.公司。
和飞行员
,L。
(
1991
)将历史控制纳入元分析的模型
.生物计量学
,47
,899
–906
.布鲁克斯
,标准普尔。
和盖尔曼
,答:。
(
1998
)监测迭代模拟收敛性的替代方法
.J.计算图表。统计人员。
,7
,434
–455
.布朗
,W·J。
,戈尔茨坦
,H。
和拉斯巴什
,J。
(
2001
)多成员分类(MMMC)模型
.统计师。莫德林
,1
,103
–124
.孔卡托
,J。
,沙阿
,N。
和霍维茨
,钢筋混凝土。
(
2000
)随机对照试验、观察性研究和研究设计层次
.新英语。医学杂志。
,342
,1887
–1892
.迪克斯
,J·J。
,丁内斯
,J。
,德米科
,R。
,索登
,A.J.公司。
,萨卡罗维奇
,C、。
,歌曲
,F、。
,小衬裙
,M。
和奥尔特曼
,D.G.公司。
(
2003
)评估非随机干预研究
.高技术。评估
,7
,编号27。埃迪
,D.M.博士。
,哈塞尔布拉德
,五、。
和沙赫特
,R。
(
1992
)置信轮廓法的Meta分析:证据的统计综合
.伦敦
:学术出版社
.艾格
,M。
,朱尼
,第页。
,巴特利特
,C、。
,霍伦斯坦
,F、。
和斯特恩
,美国期刊。
(
2003
)综合文献检索和系统评价中试验质量的评估有多重要实证研究
.高技术。评估
,7
,编号1。盖尔曼
,答:。
(
2006
)层次模型中方差参数的先验分布(对Browne和Draper文章的评论)
.贝叶斯。分析。
,1
,515
–534
.盖尔曼
,答:。
,卡林
,J.B.公司。
,斯特恩
,H.S.公司。
和鲁宾
,D、B。
(
2003
)贝叶斯数据分析
,第2版。博卡拉顿
:查普曼和霍尔——CRC
.格鲁德
,法律。
(
2006
)临床干预研究中的偏见
.美国J.Epidem。
,163
,493
–501
.格陵兰岛
,美国。
(
2005
)观测数据分析的多偏差建模(附讨论)
.J.R.统计。社会学硕士
,168
,267
–306
.卡亚加德
,法律。
,维尔卢姆森
,J。
和格鲁德
,C、。
(
2001
)荟萃分析中大、小随机试验的报告方法学质量和差异
.Ann.实习生。医学。
,135
,982
–989
.拉罗斯
,D.T.公司。
和戴伊
,D.K.博士。
(
1997
)贝叶斯元分析的分组随机效应模型
.统计师。医学。
,16
,1817
–1829
.锂
,Z.公司。
和贝格
,C.B.公司。
(
1994
)荟萃分析中结合对照和非对照研究结果的随机效应模型
.《美国统计杂志》。助理。
,89
,1523
–1527
.林德利
,直流电。
和史密斯
,A.F.M.公司。
(
1972
)线性模型的Bayes估计(带讨论)
.J.R.统计。Soc.B公司
,34
,1
–41
.麦克莱霍斯
,共和国。
,里夫斯
,公元前。
,哈维
,国际货币基金组织。
,谢尔顿
,T.A.公司。
,罗素
,信息技术。
和黑色
,上午。
(
2000
)随机和非随机研究中效应大小比较的系统综述
.高技术。评估
,4
,编号34。麦考利
,L。
,彭
,B。
,塔格韦尔
,第页。
和穆赫
,D。
(
2000
)纳入灰色文献是否影响荟萃分析中报告的干预有效性评估
?柳叶刀
,356
,1228
–1231
.穆赫
,D。
,彭
,B。
,琼斯
,答:。
,厨师
,D.J.博士。
,达德
,A.R.公司。
,穆赫
,M。
,塔格韦尔
,第页。
和克拉森
,T.P.公司。
(
1998
)随机试验报告的质量是否影响荟萃分析中报告的干预效果估计
?柳叶刀
,352
,609
–613
.帕特森
,高密度。
和汤普森
,R。
(
1971
)块大小不相等时块间信息的恢复
.生物特征
,58
,545
–554
.上一个
,T.C.公司。
艾布拉姆斯
,K.R.公司。
和琼斯
,D.右。
(
2000
)证据综合中的层次模型:以乳腺癌筛查研究为例
.统计师。医学。
,19
,3359
–3376
.舒尔茨
,K.F.公司。
,查尔默斯
,一、。
,海耶斯
,R·J。
和奥尔特曼
,D.G.公司。
(
1995
)偏差的经验证据:与对照试验中治疗效果估计相关的方法学质量维度
.美国医学杂志。
,273
,408
–412
.西尔斯玛
,五、。
,阿尔斯·尼尔森
,B。
,陈
,西。
,希尔登
,J。
,格鲁德
,法律。
和格鲁德
,C、。
(
2007
)随机临床试验中试验质量与治疗效果相关性的荟萃流行病学评估的多变量模型
.统计师。医学。
,26
,2745
–2758
.史密斯
,T.C.公司。
,Spiegelhalter公司
,D.J.博士。
和托马斯
,答:。
(
1995
)随机效应元分析的贝叶斯方法:一项比较研究
.统计师。医学。
,14
,2685
–2699
.Spiegelhalter公司
,D.J.博士。
和最佳
,N.G.公司。
(
2003
)复杂成本效益模型中多证据来源和不确定性的贝叶斯方法
.统计师。医学。
,22
,3687
–3709
.Spiegelhalter公司
,D.J.博士。
,最佳
,N.G.公司。
,卡林
,业务伙伴。
和范德林德
,答:。
(
2002
)模型复杂度和拟合度的贝叶斯度量(含讨论)
.J.R.统计。Soc.B公司
,64
,583
–639
.Spiegelhalter公司
,D.J.博士。
,托马斯
,答:。
和最佳
,N。
(
2000
)WinBUGS用户手册
.剑桥
:医学研究委员会生物统计股
.斯特恩
,美国期刊。
,尤尼
,第页。
,舒尔茨
,K.F.公司。
,奥尔特曼
,D.G.公司。
,巴特利特
,C、。
和艾格
,M。
(
2002
)“荟萃流行病学”研究中评估研究特征对治疗效果影响的统计方法
.统计师。医学。
,21
,1513
–1524
.斯特恩
,美国期刊。
,威尔顿
,新泽西州。
,阿德斯
,答:E。
,奥尔特曼
,D.G.公司。
和卡林
,J.B.公司。
(
2008
)在系统评价和荟萃分析中纳入潜在偏见证据
。已提交至国际期刊(Int.J.Epidem)
.瓦尔贝克
,英国。
,谢纳
,M.V.公司。
和埃萨利语
,答:。
(
1998
)氯氮平与典型的精神分裂症抗精神病药物
.科尔。数据库系统。版次。
,1
.威尔顿
,新泽西州。
和阿德斯
,答:E。
(
2005
)英国弓形虫病发病率模型:证据综合和证据一致性
.申请。统计人员。
,54
,385
–404
.沃尔伯特
,共和国。
和蒙格森
,K.L.公司。
(
2004
)从质量和设计不同的研究中合成经验证据的调整可能性:环境烟草烟雾的影响
.统计师。科学。
,19
,450
–471
.木材
,L。
,艾格
,M。
,格鲁德
,法律。
,舒尔茨
,英国。
,朱尼
,第页。
,奥尔特曼
,D。
,格鲁德
,C、。
,马丁
,风险管理。
,木材
,A·J·G。
和斯特恩
,美国期刊。
(
2008
)不同干预措施和结果的对照试验中治疗效果估计偏差的经验证据:荟萃流行病学研究
.英国医学杂志。
,336
,601
–605
.
©2009皇家统计学会







{kind=link}
{kind=link}
{kind=link}
{kind=link}