总结
多重假设检验涉及防止比单一假设检验更复杂的错误。我们通常控制单假设检验的I型错误率,而控制多假设检验的复合错误率。例如,控制错误发现率FDR传统上涉及复杂的序列第页-基于观测数据的值剔除方法。而序列第页-value方法修复错误率和估计它对应的拒绝区域,我们提出了相反的方法修理然后估计其相应的错误率。这种新方法提高了适用性、准确性和威力。我们将该方法应用于正错误发现率pFDR和FDR,并为其效益提供证据。结果表明,pFDR可能是相对于FDR的感兴趣量。还讨论了计算q个-值的pFDR模拟第页-值,这样就无需像传统方法那样预先设置错误率。一些简单的数值例子表明,与Benjamini–Hochberg FDR方法相比,这种新方法的功率增加了八倍以上。
1.简介
单假设检验的基本范式如下。我们希望检验一个无效假设小时0与另一种选择小时1基于统计数据X(X)对于给定的拒绝区域Γ,我们拒绝小时0什么时候X(X)∈Γ,我们接受小时0什么时候X(X)∉Γ. 在以下情况下发生I类错误X(X)∈Γ,但小时0是真的;在以下情况下发生II类错误X(X)∉Γ,但小时1这是真的。为了选择Γ,可接受的I型误差被设置为某种程度α; 则所有拒绝区域都被认为具有小于或等于α.选择II型误差最小的一个。因此,寻求与控制I类错误这种方法相当成功,通常我们可以找到一个具有近似最佳功率(功率=1−II型误差)的拒绝区域,同时保持所需的α-级别I型错误。
当测试多种假设时,情况变得更加复杂。现在,每个测试都有I型和II型错误,我们不清楚应该如何衡量总体错误率。建议的第一个衡量标准是家庭错误率FWER,这是所有假设中出现一个或多个I类错误的概率。而不是在水平上控制I类错误的概率α对于每个测试,整个FWER都控制在水平α尽管如此,α选择FWER≤α,然后发现一个保持水平的排斥区ΓαFWER,但也能产生良好的功率。为了简单起见,我们假设每个测试都有相同的拒绝区域,例如使用第页-值作为统计信息。
在开拓性工作中,本杰米尼和霍奇伯格(1995)引入了一种称为错误发现率(FDR)的多假设测试误差度量。这个数量是所有被拒绝的假设中假阳性发现的预期比例。在许多情况下,FWER过于严格,尤其是在测试数量很大的情况下。因此,FDR是一个更自由但更强大的控制量。在楼层中(2001),我们引入了正错误发现率pFDR。这是一个修改过的,但可以说更合适的错误度量。
本杰米尼和霍奇伯格(1995)提供了一个序列第页-控制FDR的值方法。这才是罗斯福真正控制的第页-值法实现:利用观测数据,估计拒绝区域,使平均FDR≤α对于一些预先选定的α.序列的乘积第页-价值法是一种估计这告诉我们要拒绝,其中第页(1)≤第页(2)≤…≤第页(米)是否遵守了命令第页-值。
我们能说什么?有没有任何自然的方法来提供这个随机变量的误差度量?在多假设测试中,认为我们有100%的误差保证上限是一种错误的安全感。事实是,这个过程涉及到估计。估计的变量越多就是说,该程序在实践中的效果越差。因此,预期值可能是FDR≤α,但我们不知道这些方法的可靠性如何。如果点估计只涉及寻找无偏估计量,那么该领域就不会那么成功。因此尽管尚未对其进行探讨,但具体情况确实重要。
当前错误发现率方法的另一个弱点是,错误率对以下所有值都进行了控制米0(真零假设的数量)同时不使用数据中关于米0。当然有关于米0在观察到的第页-值。在我们提出的方法中,我们使用了此信息,它产生了一个不太严格的过程和更强大的功能,同时保持了强大的控制。通常,多假设测试方法的威力随着增加而降低米。这不应该是这样,尤其是当测试是独立的时。较大的米,我们掌握的更多信息米0,应该使用这个。
在本文中,我们提出了一种新的错误发现率方法。我们尝试使用更传统和直接的统计思想来控制pFDR和FDR。而不是修复α然后估计k个(即估计拒绝区域),我们固定拒绝区域,然后估计α在传统的多假设测试中,确定拒绝区域似乎是反作用的。我们在下一节中认为,在错误发现率的背景下,这是有意义的。
我们提出的方法自然会遭到反对,因为它不能“控制”罗斯福。实际上,控制是在与前一种方法论相同的意义上提供的,它提供了保守的期望偏差。此外,由于采用这种新方法时,我们处于更熟悉的点估计情况,因此可以使用数据进行估计米0,获得pFDR和FDR的置信区间,并在误差度量的定义中获得灵活性。
我们表明,我们提出的方法更加有效、灵活和强大。我们将描述的多假设测试方法利用了数据中的更多信息,并且概念上更简单。在节中2我们讨论了pFDR及其与FDR的关系,以及在多假设测试中使用固定的拒绝区域。在节中三我们制定了我们的方法,并在第节三我们对所提出的方法与本杰米尼和霍奇伯格的方法进行了启发式比较(1995). 章节三提供了数值结果,并将我们的方法与当前方法进行了比较。章节三描述了与该方法有关的几个理论结果,包括最大似然估计解释。章节三描述了一个称为q个-值,它是第页-值和节三认为pFDR和q个-值是要使用的最合适的错误发现率数量。章节三显示如何在估计中自动选取调整参数。章节三是讨论,并且附录A提供定理的技术注释和证明。
2.阳性错误发现率和固定拒绝区域
如第节所述1,在多假设测试中通常使用两种错误度量:FWER和FDR。FWER是使用的传统测量方法;本杰米尼和霍奇伯格(1995)最近推出的罗斯福。表1总结了测试时出现的各种结果米假设。
| 假设. | 接受. | 拒绝. | 总计. |
|---|
| Null真 | U型 | V(V) | 米0 |
| 可选true | T型 | S公司 | 米1 |
| W公司 | R(右) | 米 |
| 假设. | 接受. | 拒绝. | 总计. |
|---|
| Null真 | U型 | V(V) | 米0 |
| 可选true | T型 | S公司 | 米1 |
| W公司 | R(右) | 米 |
| 假设. | 接受. | 拒绝. | 总计. |
|---|
| Null真 | U型 | V(V) | 米0 |
| 可选true | T型 | S公司 | 米1 |
| W公司 | R(右) | 米 |
| 假设. | 接受. | 拒绝. | 总计. |
|---|
| Null真 | U型 | V(V) | 米0 |
| 可选true | T型 | S公司 | 米1 |
| W公司 | R(右) | 米 |
V(V)是类型I错误(或假阳性结果)的数量。因此,FWER定义为Pr(V(V)≥1). 控制这个数量提供了一个非常严格的误差测量。一般来说,随着测试次数的增加,控制FWER时功率会降低。FDR定义为
(1)
即,在所有被拒绝的假设中,假阳性结果的预期比例乘以至少一次被拒绝的概率。本杰米尼和霍奇伯格(1995)本杰米尼和刘(1999)提供的顺序第页-控制此数量的值方法。与FWER相比,FDR提供了一个严格得多的多重测试标准,因此导致功率增加。
在楼层中(2001),我们定义了一个新的错误发现率pFDR。
定义1。
(2)
添加了“积极”一词,以反映我们正在考虑积极发现发生的事件。在液位控制FDR时α,并且出现了积极的发现,那么FDR实际上只被控制在水平上α/Pr公司(R(右)>0). 这可能非常危险,但pFDR的情况并非如此。查看故事(2001)以彻底激励pFDR而非FDR。
本杰米尼和霍奇伯格(1995)精确地将FDR定义为表达式(1),因为这个量可以由序列控制第页-值方法。(然而,请注意,FWER的弱控制隐含在该定义中,即当所有零假设均为真时,FWER受控制。)当所有零假定均为真,pFDR为1(米=米0),所以通常的顺序第页-价值方法不能应用于此数量。因此,为了控制pFDR,必须对特定的抑制区域进行估计。
一个连续的第页-值方法允许我们预先确定错误率并估计拒绝区域,这是传统的多假设测试方法。在FWER的背景下,这是有意义的。由于FWER测量了发生一个或多个I类错误(本质上是“0–1”事件)的概率,因此我们可以设置速率先验的发生这种情况的时间。相反,错误发现率更像是一种探索性工具。例如,假设我们正在测试1000个假设,并事先决定将FDR控制在5%的水平。这是否是一个合适的选择在很大程度上取决于被拒绝的假设的数量。如果100个假设被拒绝,那么这显然是一个不错的选择。如果只有两个假设被拒绝,那么显然这是一个不太有用的选择。
因此,在使用pFDR或FDR时,预先确定拒绝区域可能更合适。例如,在进行许多假设测试时,拒绝所有假设都是有意义的第页-值小于0.05或0.01。此外,特定领域的专家知识可以让我们决定应该使用哪个拒绝区域。
我们还将看到,这种方法允许我们控制pFDR,我们发现这是一种更合适的误差度量。修正拒绝区域的最重要原因可能是它允许我们对复杂的复合误差度量(如pFDR和FDR)采取概念上更简单的方法。
这个q个-值(节三)是的pFDR模拟第页-值,并允许由观察到的第页-值。这比固定拒绝区域或固定错误率更合适。但是,通过在我们的方法中首先固定拒绝区域,我们可以公式化q个-值非常容易。
3.正错误发现率和错误发现率的估计和推断
在本节中,我们将所提出的方法应用于pFDR和FDR。我们首先介绍一些独立条件下关于pFDR的简单事实,以激发我们的估计。假设我们正在测试米相同假设检验小时1,小时2,…,小时米具有独立统计数据T型1,T型2,…,T型米.我们让小时我零假设时=0我是真的,并且小时我否则为1。我们假设nullT型我|小时我=0和备选方案T型我|小时我=1的分布相同。我们假设每个测试使用相同的拒绝区域,这使得测试“相同”。最后,我们假设小时我是具有Pr的独立Bernoulli随机变量(小时我=0)=π0和Pr(小时我=1)=π1设Γ为每个假设检验的公共拒绝区域。
下面是Storey的定理1(2001). 它允许我们以非常简单的形式编写pFDR,而不依赖于米为了使这个定理成立,我们必须假设小时我是随机的;然而,对于大型米这种假设没有什么区别。
定理1。
假设米使用独立统计数据进行相同的假设检验T型1,…,T型米和排斥区Γ。还假设虚假设对先验的可能性π0.然后
(3)
(4)
其中Pr(T型∈Γ)=π0优先级(T型Γ∈|小时=0)+π1优先级(T型∈Γ|小时=1).
本文仅限于我们在独立的基础上拒绝的情况第页-值。查看Storey和Tibshirani(2001)用于处理更一般的情况。因此,对于基于以下条件的拒绝第页-值所有拒绝区域的形式为[0,γ]对一些人来说γ≥0。(参见中的备注1附录A以证明这一点。)对于本文的其余部分,我们不是用更抽象的Γ表示拒绝区域,而是用γ,表示间隔[0,γ].
依据第页-我们可以将定理1的结果写成
(5)
哪里P(P)是随机的第页-任何测试产生的值。独立后第页-值是可交换的,因为每个值都来自概率为零的分布(即均匀[0,1])π0从概率的替代分布π1。从简单的角度考虑这是最容易的与简单的假设检验,但该理论也适用于具有随机效应的复合替代假设(Storey,2001).
自π0米的第页-值应为null,然后为最大值第页-值很可能来自null,均匀分布第页-值。因此,保守估计π0是
(6)
给一些精心挑选的人λ,其中第页1,…,第页米被观察到了吗第页-值和W公司(λ)=#{第页我>λ}. (回顾W公司和R(右)来自表1.)目前我们假设λ固定;然而,我们展示了如何选择最佳λ在节中三.(埃夫隆等。(2001)使用了不同的估计π0在与pFDR相关的经验贝叶斯方法中。)Pr的自然估计(P(P)≤γ)是
(7)
哪里R(右)(γ)=#{第页我≤γ}. 因此,可以很好地估计pFDR(γ)用于固定λ是
(8)
pFDR和FDR对于固定的抑制区域是渐近等价的。我们在第节中看到三那个显示了pFDR的良好渐近性质。事实上,我们证明这是一个极大似然估计。然而,由于有限样本的考虑,我们必须对pFDR进行两次轻微的调整。什么时候?R(右)(γ)=0,估计值将是未定义的,这对于有限样本是不可取的。因此,我们替换R(右)(γ)带有R(右)(γ)这相当于在[0,第页(1)]和起源。此外,1−(1−γ)米显然是Pr的下限{R(右)(γ)>0}. 由于pFDR处于开启状态R(右)(γ)>0,我们除以1−(1−γ)米换句话说γ/{1−(1−γ)米}是I型误差的保守估计,条件是R(右)(γ)>0. (参见第节三了解我们为什么这么做的更多信息。)因此,我们估计pFDR为
(9)
由于FDR不以发生至少一次拒绝为条件,我们可以设置
(10)
对于大型米这两个估计是等价的,但我们发现pFDR量更合适,并认为应该使用它。什么时候?γ=1/米,公关{R(右)(γ)>0}可以小到0.632,因此正如前一节中提到的那样,FDR可能会产生误导。对于固定米和γ→0,FDR(γ)和显示了不令人满意的属性,我们在第节中对此进行了说明三.
我们在章节中展示三那个p和提供一种类似于强控制的属性,因为它们对所有人都有保守的偏见π0然而,正如我们在第节中所述1多假设测试程序的预期值不够广泛。自从第页-值是独立的,我们可以通过替换对它们进行采样,以获得标准的引导样本。从这些数据中,我们可以形成我们估计的自举版本,并为pFDR和FDR提供置信上限。这使我们能够更准确地说明提供了多少多重假设测试控制。pFDR估计和推断的全部细节(γ)算法1中给出了。同样的算法适用于FDR的估计和推断(γ),除了我们显然使用而不是。在节中三,我们扩展了我们的方法,包括一种自动选择最优值的方法λ.
如果,建议设置显然是pFDR(γ)≤1.我们可以平滑估计,使其始终小于或等于1,但这里我们采用了更简单的方法。同样的评论适用于.
尽管本节中提出的估计数是新的,但以前也隐含地采用了这种方法。叶库蒂利和本杰米尼(1999)在Benjamini和Hochberg引入了估计FDR依赖性不足的想法(1995)还有本杰米尼和霍奇伯格(2000)纳入了对米0在一个事后(post-hoc)时尚。塔瑟等. (2001)修复了拒绝区域和估计的FDR。
3.1. 算法1:pFDR的估计和推断(γ)和FDR(γ)
- (a)
对于米假设检验,计算它们各自的第页-值第页1,…,第页米.
- (b)
估算π0和Pr(P(P)≤γ)由和哪里R(右)(γ)=#{第页我≤γ}和W公司(λ)=#{第页我>λ}. - (c)
对于任何感兴趣的拒绝区域[0,γ],估计pFDR(γ)由给一些精心挑选的人λ(参见第节三如何选择最佳λ.) - (d)
对于B类的引导程序样本第页1,…,第页米,计算引导估计(b条=1,…,B类)与上述方法类似。
- (e)
表格a 1−αpFDR的置信区间上限(γ)通过使用1−α的分位数作为置信上限。
- (f)
对于FDR(γ),执行相同的过程,但使用
(11)
4.两种方法之间的联系
在本节中,我们提出了序列第页-Benjamini和Hochberg的价值方法(1995)以及上一节中介绍的方法。我们的目标是深入了解我们提议的方法的增强功能和有效性。
我们提出的基本观点是,使用本杰米尼和霍奇伯格(1995)水平控制FDR的方法α/π0等于(即拒绝相同的第页-值as)使用建议的方法将FDR控制在水平α从我们的方法中获得的功率很明显,我们可以控制较小的错误率(α≤α/π0),但拒绝相同数量的测试。
让第页(1)≤…≤第页(米)遵守秩序第页-的值米假设检验。本杰米尼和霍克伯格的方法(1995)发现使得
(12)
正在拒绝提供FDR≤α.
现在假设我们使用我们的方法并采用最保守的估计然后是估算如果我们拒绝使得
(13)
但是自从
这相当于()
(14)
因此,什么时候此外,如果我们采用更好的估计
(15)
然后概率很高。
因此,我们已经表明换言之,使用我们的方法,我们在控制相同错误率的同时拒绝了更多的假设,这将带来更大的威力。两者之间的操作差异本杰米尼和霍奇伯格(1995)程序包括然而,值得注意的是,我们并没有简单地颠倒他们的方法并坚持下去相反,我们采取了一种非常不同的方法,从具有固定排斥区域的独立pFDR的简单事实出发。本杰米尼和霍奇伯格(1995)没有让我们深入了解他们为什么选择他们的特定序列第页-值方法。这一比较揭示了它为什么有效。
5.数值研究
在本节中,我们给出了一些数值结果,以比较本杰米尼和霍克伯格的功率(1995)程序和我们提出的方法。如第节所述三,自本杰米尼和霍奇伯格以来,比较这两种方法并不简单(1995)估计了拒绝区域,而我们的方法估计了FDR。我们通过使用Benjamini–Hochberg程序在水平上控制FDR来规避这个问题对于每个迭代。
我们研究了两个排斥区域γ=0.01和γ=0.001超过以下几个值π0。的值γ和π0被选来报道各种各样的情况。我们表演了米=1000个假设检验μ=0与μ=2,对于独立随机变量Z轴我∼N个(μ,1),我=1,…,1000,超过1000次迭代。每个测试的无效假设是μ=0,那么Z轴我∼N个(0,1)设置为π0; 因此,π1的统计数据具有替代分布N个(2,1). 对于每个测试第页-值定义为第页我=优先级{N个(0,1)≥z我},其中z我是的观测值Z轴我.
要计算我们方法的威力,请测试我如果第页我≤γ,并据此计算功率。也,按照我们在第节中概述的方法计算三Benjamini–Hochberg方法在,并计算功率。这种方法应该将这两种方法放在同等的基础上进行比较;报告在实践中等同于使用Benjamini–Hochberg方法在水平上控制FDR.
对以下各项进行了模拟π0=0.1,0.2,…,0.9. 尽管在这里我们知道第页-价值观,我们没有使用这些知识。相反,我们估计FDR,就好像替代分布未知一样。因此,我们必须选择一个值λ估计π0; 我们用过在所有计算中都很简单。
表2显示了仿真研究的结果。表格的前半部分对应于γ=0.01,下半部分对应γ=0.001. 可以看出,使用所提出的方法可以大幅提高功率。一个案例甚至使功率增加了800%以上。在我们的方法的每种情况下,功率是恒定的,因为使用了相同的抑制区域。Benjamini–Hochberg方法的威力随着π0由于程序变得不那么保守,所以变得越来越大。事实上,它遵循第节三那,作为π0→1,Benjamini–Hochberg方法成为建议的方法。
| π0. | 飞行数据记录器. | 电源. | E类( ),建议的方法. | E类( ),建议的方法. | E类( )Benjamini–Hochberg方法. |
|---|
| 建议的方法. | Benjamini-Hochberg方法. |
|---|
| γ=0.01 |
| 0.1 | 0.003 | 0.372 | 0.074 | 0.004 | 0.141 | 0.0003 |
| 0.2 | 0.007 | 0.372 | 0.122 | 0.008 | 0.236 | 0.0008 |
| 0.3 | 0.011 | 0.372 | 0.164 | 0.013 | 0.331 | 0.001 |
| 0.4 | 0.018 | 0.372 | 0.203 | 0.019 | 0.426 | 0.002 |
| 0.5 | 0.026 | 0.372 | 0.235 | 0.027 | 0.523 | 0.003 |
| 0.6 | 0.039 | 0.372 | 0.268 | 0.040 | 0.618 | 0.004 |
| 0.7 | 0.060 | 0.371 | 0.295 | 0.061 | 0.714 | 0.005 |
| 0.8 | 0.097 | 0.372 | 0.319 | 0.099 | 0.809 | 0.007 |
| 0.9 | 0.195 | 0.372 | 0.344 | 0.200 | 0.905 | 0.008 |
| γ=0.001 |
| 0.1 | 0.0008 | 0.138 | 0.016 | 0.001 | 0.141 | 1×10−5 |
| 0.2 | 0.002 | 0.138 | 0.031 | 0.002 | 0.236 | 5×10−5 |
| 0.3 | 0.003 | 0.137 | 0.046 | 0.003 | 0.331 | 0.0001 |
| 0.4 | 0.005 | 0.138 | 0.060 | 0.005 | 0.426 | 0.0002 |
| 0.5 | 0.007 | 0.138 | 0.074 | 0.008 | 0.523 | 0.0003 |
| 0.6 | 0.011 | 0.138 | 0.088 | 0.011 | 0.618 | 0.0004 |
| 0.7 | 0.017 | 0.138 | 0.101 | 0.017 | 0.714 | 0.0005 |
| 0.8 | 0.028 | 0.138 | 0.129 | 0.030 | 0.809 | 0.0006 |
| 0.9 | 0.061 | 0.137 | 0.133 | 0.066 | 0.905 | 0.0008 |
| π0. | 财务总监. | 电源. | E类( ),建议的方法. | E类( ),建议的方法. | E类( )Benjamini–Hochberg方法. |
|---|
| 建议的方法. | Benjamini-Hochberg方法. |
|---|
| γ=0.01 |
| 0.1 | 0.003 | 0.372 | 0.074 | 0.004 | 0.141 | 0.0003 |
| 0.2 | 0.007 | 0.372 | 0.122 | 0.008 | 0.236 | 0.0008 |
| 0.3 | 0.011 | 0.372 | 0.164 | 0.013 | 0.331 | 0.001 |
| 0.4 | 0.018 | 0.372 | 0.203 | 0.019 | 0.426 | 0.002 |
| 0.5 | 0.026 | 0.372 | 0.235 | 0.027 | 0.523 | 0.003 |
| 0.6 | 0.039 | 0.372 | 0.268 | 0.040 | 0.618 | 0.004 |
| 0.7 | 0.060 | 0.371 | 0.295 | 0.061 | 0.714 | 0.005 |
| 0.8 | 0.097 | 0.372 | 0.319 | 0.099 | 0.809 | 0.007 |
| 0.9 | 0.195 | 0.372 | 0.344 | 0.200 | 0.905 | 0.008 |
| γ=0.001 |
| 0.1 | 0.0008 | 0.138 | 0.016 | 0.001 | 0.141 | 1×10−5 |
| 0.2 | 0.002 | 0.138 | 0.031 | 0.002 | 0.236 | 5×10−5 |
| 0.3 | 0.003 | 0.137 | 0.046 | 0.003 | 0.331 | 0.0001 |
| 0.4 | 0.005 | 0.138 | 0.060 | 0.005 | 0.426 | 0.0002 |
| 0.5 | 0.007 | 0.138 | 0.074 | 0.008 | 0.523 | 0.0003 |
| 0.6 | 0.011 | 0.138 | 0.088 | 0.011 | 0.618 | 0.0004 |
| 0.7 | 0.017 | 0.138 | 0.101 | 0.017 | 0.714 | 0.0005 |
| 0.8 | 0.028 | 0.138 | 0.129 | 0.030 | 0.809 | 0.0006 |
| 0.9 | 0.061 | 0.137 | 0.133 | 0.066 | 0.905 | 0.0008 |
| π0. | 财务总监. | 电源. | E类( ),建议的方法. | E类( ),建议的方法. | E类( )Benjamini–Hochberg方法. |
|---|
| 建议的方法. | Benjamini-Hochberg方法. |
|---|
| γ=0.01 |
| 0.1 | 0.003 | 0.372 | 0.074 | 0.004 | 0.141 | 0.0003 |
| 0.2 | 0.007 | 0.372 | 0.122 | 0.008 | 0.236 | 0.0008 |
| 0.3 | 0.011 | 0.372 | 0.164 | 0.013 | 0.331 | 0.001 |
| 0.4 | 0.018 | 0.372 | 0.203 | 0.019 | 0.426 | 0.002 |
| 0.5 | 0.026 | 0.372 | 0.235 | 0.027 | 0.523 | 0.003 |
| 0.6 | 0.039 | 0.372 | 0.268 | 0.040 | 0.618 | 0.004 |
| 0.7 | 0.060 | 0.371 | 0.295 | 0.061 | 0.714 | 0.005 |
| 0.8 | 0.097 | 0.372 | 0.319 | 0.099 | 0.809 | 0.007 |
| 0.9 | 0.195 | 0.372 | 0.344 | 0.200 | 0.905 | 0.008 |
| γ=0.001 |
| 0.1 | 0.0008 | 0.138 | 0.016 | 0.001 | 0.141 | 1×10−5 |
| 0.2 | 0.002 | 0.138 | 0.031 | 0.002 | 0.236 | 5×10−5 |
| 0.3 | 0.003 | 0.137 | 0.046 | 0.003 | 0.331 | 0.0001 |
| 0.4 | 0.005 | 0.138 | 0.060 | 0.005 | 0.426 | 0.0002 |
| 0.5 | 0.007 | 0.138 | 0.074 | 0.008 | 0.523 | 0.0003 |
| 0.6 | 0.011 | 0.138 | 0.088 | 0.011 | 0.618 | 0.0004 |
| 0.7 | 0.017 | 0.138 | 0.101 | 0.017 | 0.714 | 0.0005 |
| 0.8 | 0.028 | 0.138 | 0.129 | 0.030 | 0.809 | 0.0006 |
| 0.9 | 0.061 | 0.137 | 0.133 | 0.066 | 0.905 | 0.0008 |
| π0. | 飞行数据记录器. | 电源. | E类( ),建议的方法. | E类( ),建议的方法. | E类( )Benjamini–Hochberg方法. |
|---|
| 建议的方法. | Benjamini-Hochberg方法. |
|---|
| γ=0.01 |
| 0.1 | 0.003 | 0.372 | 0.074 | 0.004 | 0.141 | 0.0003 |
| 0.2 | 0.007 | 0.372 | 0.122 | 0.008 | 0.236 | 0.0008 |
| 0.3 | 0.011 | 0.372 | 0.164 | 0.013 | 0.331 | 0.001 |
| 0.4 | 0.018 | 0.372 | 0.203 | 0.019 | 0.426 | 0.002 |
| 0.5 | 0.026 | 0.372 | 0.235 | 0.027 | 0.523 | 0.003 |
| 0.6 | 0.039 | 0.372 | 0.268 | 0.040 | 0.618 | 0.004 |
| 0.7 | 0.060 | 0.371 | 0.295 | 0.061 | 0.714 | 0.005 |
| 0.8 | 0.097 | 0.372 | 0.319 | 0.099 | 0.809 | 0.007 |
| 0.9 | 0.195 | 0.372 | 0.344 | 0.200 | 0.905 | 0.008 |
| γ=0.001 |
| 0.1 | 0.0008 | 0.138 | 0.016 | 0.001 | 0.141 | 1×10−5 |
| 0.2 | 0.002 | 0.138 | 0.031 | 0.002 | 0.236 | 5×10−5 |
| 0.3 | 0.003 | 0.137 | 0.046 | 0.003 | 0.331 | 0.0001 |
| 0.4 | 0.005 | 0.138 | 0.060 | 0.005 | 0.426 | 0.0002 |
| 0.5 | 0.007 | 0.138 | 0.074 | 0.008 | 0.523 | 0.0003 |
| 0.6 | 0.011 | 0.138 | 0.088 | 0.011 | 0.618 | 0.0004 |
| 0.7 | 0.017 | 0.138 | 0.101 | 0.017 | 0.714 | 0.0005 |
| 0.8 | 0.028 | 0.138 | 0.129 | 0.030 | 0.809 | 0.0006 |
| 0.9 | 0.061 | 0.137 | 0.133 | 0.066 | 0.905 | 0.0008 |
表的第五列2显示我们的方法。可以看出,这与第二列中的真实FDR非常接近(通常在0.1%以内),并且总是保守的。提出的方法几乎是最优的,因为它估计了FDR(γ)对于每个排斥区域基本上尽可能保守地接近。因此,无论π0此外,随着测试次数的增加,该方法变得更好;过去情况恰恰相反。第六列显示我们的方法。可以看出,这个估计总是保守的,并且非常接近实际值。回想一下,Benjamini–Hochberg方法基本上估计了拒绝区域[0,γ]. 第八列显示超过1000个变现可以看出,这些估计值相当保守。功率比较也如图所示。1.
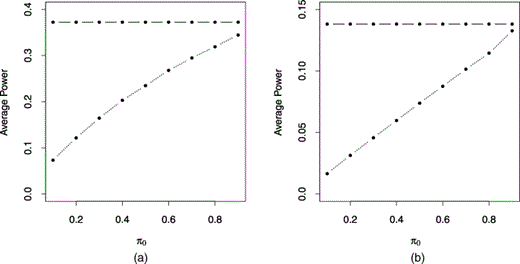
图1
平均功率与π0对于Benjamini–Hochberg方法(………)和建议的方法(-):(a)由γ=0.01; (b) 拒绝区域由定义γ=0.001(可以看出,在这两种情况下,建议方法下的功率都有大幅增加)
我们方法的成功也很大程度上取决于我们对pFDR的估计程度(γ)和FDR(γ). 从这个模拟中可以看出,估计值非常好。这尤其是由于功率-类型I误差曲线在第节讨论的意义上表现良好三.如果我们选择λ自适应性更强,估计效果更好。这是第节的主题三.
6.理论结果
在本节中,我们为以下内容提供有限样本和大样本结果和我们的目标当然是提供pFDR的保守估计值(γ)和FDR(γ). 例如,我们想要在不太保守的情况下尽可能多地使用。以下是我们的主要有限样本结果。
定理2。
和为所有人γ和π0.
这一结果类似于显示了对我们方法的“强有力的控制”。该定理是在我们不截断估计值为1的假设下提出的。当然,在实践中,由于FDR≤\hboxpFDR≤1,我们会将估计值截断为1,但估计值的预期值仍按我们希望的方式运行。以下结果表明,在同时考虑偏差和方差时,截断估计值是一个好主意。
定理3。
和
我们现在提供了以下方面的大样本结果(这些结果也适用于自从紧密性收敛于pFDR的上界(γ)这在很大程度上取决于功率如何随I型错误而变化。为此,让我们克(λ)=优先级(P(P)≤λ|小时=1)作为I类错误函数的功率λ。请注意克(‧)只是备选方案的累积密度函数第页-值。对于米相同的简单测试,克(λ)每个测试都是相同的。如果替代假设是复合的,那么克(λ)必须定义为适当的混合物。我们假设克(0)=0,克(1) =1和克(λ)≥λ用于0<λ<1.
定理4。
概率为1时,我们有
(16)
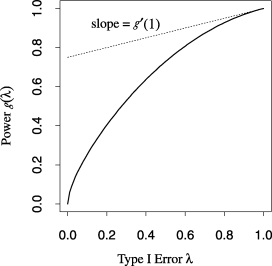
根据每个拒绝区域的I型误差功率图[0,λ]. 功能克(λ)在拒绝区域[0上给出功率,λ],当然,该区域的I类错误是λ.估计π0在间隔期间被接管(λ,1],所以1−克(λ)是一个概率第页-替代分布的值分为(λ,1]. 同样,1−λ是null的概率第页-价值属于(λ,1]. 对π0越多越好克(λ)>λ。这是自间隔以来的情况(λ,1]将包含较少的备选方案第页-值,因此估计值不太保守。图。2显示了克(λ)与λ对于凹面克.对于凹面克,估计π0变得不那么保守λ→1.这在以下推论中得到了正式说明。
图2
电源克(λ)与类型1错误λ:由此可见克是凹形{1−克(λ)}/(1−λ)随着λ→1; 线路有坡度限制λ→1[{1−克(λ)}/(1−λ)],它是{1−的最小值克(λ)}/(1−λ)凹面可以达到克
推论1。
对于凹面克
(17)
哪里克′(1) 是的导数克评估值为1。
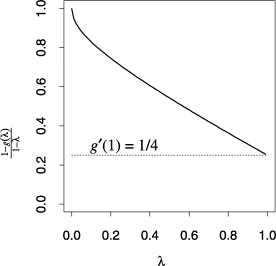
换句话说,方程式的右侧(17)是最严格的上限可以在pFDR上获得米→ ∞ 用于凹面克推论可以从图中图形化地看到。三{1−图克(λ)}/(1−λ)与λ所示为凹面克可以看出,最小值是在λ=1.最小值为克′1) ,碰巧是在这个图表中。当拒绝区域基于零假设和替代假设之间似然比的单调函数时,克是凹形的。如果克不是凹的,那么最佳λ用于估算π0可能不是λ=1.
图3
{1−克(λ)}/(1−λ)与λ对于凹面克:可以看出,最小值是在λ=1,有值
最后一个结果的一个好特性是克′1) 当对指数族的单个参数进行单侧测试时,=0。因此,在许多常见情况下,我们可以实现精确收敛λ→1
回忆一下估计根据方程式(8)在第节中三.和如我们所见,是这个的修改版本,显示了良好的有限样本属性。然而,由此可以看出是定理4中极限量的最大似然估计。
定理5。
在定理1的假设下,是的最大似然估计
(18)
该数量略大于pFDR(γ)用于强大的测试。在以下情况下克这一估计是“最优的”,因为偏差通常可以任意小(见推论1),同时获得该偏差估计值的最小渐近方差。具有良好的有限样本性质(避免了纯最大似然估计的不便),但它渐近等价于,因此它具有相同的大样本属性。
7q个-价值
我们现在讨论一种天然的pFDR类似物第页-值,我们称之为q值该数量首次在Storey开发和调查(2001). 这个q个-值为科学家提供了关于pFDR的每个观测统计的假设检验误差度量。这个第页-值在I类错误方面实现了相同的目标第页-相对于FWER的值。
尽管我们只考虑独立的假设检验第页-价值观,它有助于引入q个-在一般环境下正式评估,以更好地激励其定义。我们还将定义q个-价值第页-值。对于拒绝区域的嵌套集合{Γ}(例如,{Γ}可以是形式的所有集合[c(c),∞)对于−∞≤c(c)≤∞)第页-观测统计值T型=t吨定义为
(19)
这个数量给出了观察到的统计数据在产生I类错误方面的强度的度量——它是拒绝具有值的统计数据时可能发生的最小I类错误率t吨对于嵌套拒绝区域集。在多次测试的情况下,我们可以调整第页-控制FWER的几个统计值。调整后的第页-这些值给出了观测统计值相对于一个或多个I类错误的强度的度量。作为pFDR的自然扩展q个-值具有以下定义。
定义2。
对于观察到的统计数据T型=t吨,的q值属于t吨定义为
(20)
总之q个-值是对观察到的统计数据相对于pFDR的强度的度量,它是拒绝具有值的统计数据时可能出现的最小pFDRt吨对于嵌套拒绝区域集。
当统计数据独立时,定义更简单第页-值。嵌套的拒绝区域集的形式为[0,γ]pFDR可以用简单的形式编写。因此,就独立性而言第页-值,以下是q个-观测值第页-价值第页.
定义3。
对于一组独立进行的假设测试第页-值q个-观测值第页-价值第页是
(21)
定义的右侧仅在小时我是随机的,如定理1所示。查看故事(2001)有关的更多理论细节q个-价值。在这里,我们提出以下算法来计算q个(第页我)在实践中。
该程序确保根据我们的定义,这是必要的。这个q个-值可以以下列方式在实践中使用:给了我们对于包含[0,第页(我)]的我=1,…,米换句话说,对于每个第页-值存在pFDR等于的拒绝区域q个(第页(我))所以至少第页(1),…,第页(我)被拒绝。请注意,我们将计算的q个-值为。这是因为是一个估计属于q个(第页(我)). The exact operating characteristics of作为一个开放问题,但模拟表明,它的行为是保守的,正如我们所希望的那样。
7.1. 算法2:计算q值
8.以下优势和结束
在本节中,我们将更深入地了解和以及为什么使用pFDR和q个-价值。考虑以下事实米:
(22)
换句话说,当我们使排斥区域越来越小时,我们最终估计pFDR为这是保守的做法,因为我们只能得出这样的结论
此外,在没有参数假设的情况下,这正是我们想要的。例如,假设我们取一个很小的拒绝区域。那么很可能只有一个第页-价值属于该区域。没有其他人的信息第页-值,如果没有关于替代分布的参数信息,我们几乎无法说明这一点第页-值为null或可选值。因此,用先验概率估计pFDR是有意义的在极小的排斥区域。
相比之下,请注意
(23)
这有意义吗?在那片林中是这样的γ→0{财务总监(γ)}=0. 但我们总是实现这种收敛的唯一原因是额外的Pr项{R(右)(γ)>FDR中的0}。因此,作为γ当发现率变小时,FDR的驱动因素是拒绝区域很小,而不是“发现错误率”很小。毕竟,正如我们上面所说的,对于这些小间隔内的替代分布,没有足够的信息来了解第页-值为null或可选值。
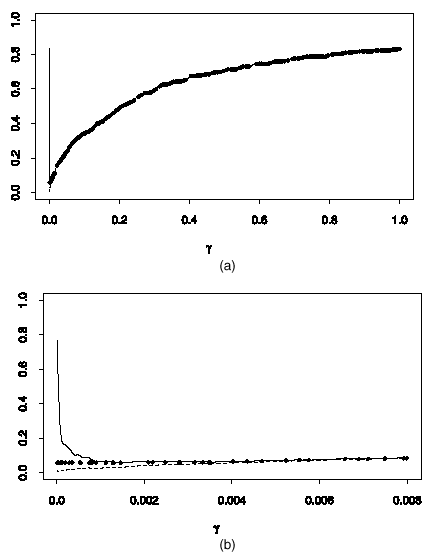
因此,如果我们要定义q个-FDR值,然后是小值第页-值,因为第页-价值很小,尽管我们几乎不知道它来自没有认真假设的替代假设的可能性有多大。考虑图。4。我们进行了1000项假设测试N个(0,1)与N个(2,1). 800来自空区N个(0,1)分布和200来自备选方案N个(2,1)分布。图。4(a) 显示和作为的函数γ,以及q个-值作为观察值的函数第页-值。可以看出,除了靠近原点外,这三个函数看起来都很相似。
图4
的绘图(—-),(----------------------)和对于N个(0,1)与N个(2,1)示例:可以看出和表现得比靠近原点
图。4(b) 放大到接近零的位置,我们可以看到迅速发展到、和迅速下降到0。这个q个-然而,价值在以下方面保持稳定达到最小值(大约第页(10)). 换句话说q个-该值用于校准我们开始接收足够信息以对pFDR做出正确陈述的位置。罗斯福没有提到在原点附近“发现错误的比率”,只测量了我们在原点附近的事实。此外,接近零度的区域可以说是最重要的区域,因为这是最显著的区域第页-价值观是谎言。因此,通过使用和q个-值,我们获得坚固耐用的pFDR的估计值,我们认为这是更合适的误差度量。这个q个-值绕过我们已固定的拒绝区域,并以适当的方式使拒绝区域随机。它还绕过了任何需要提前修复错误率的环节,这在传统框架中是必须的。
9.计算最佳值λ
在节中三我们展示了如何估计pFDR(γ)和FDR(γ),使用固定参数λ用于估算π0。在本节中,我们将介绍如何选择λ以最佳方式最小化我们估计的均方误差。我们提出了,尽管相同的过程适用于。我们提供了一种自动估算方法
(24)
我们使用bootstrap方法来估计λ最好的并计算出在一定范围内λ.(调用此范围R(右); 例如,我们可以采取R(右)={0,0.05,0.10,…,0.95}.) 如第节所述三,我们可以生成引导程序版本(用于b条=1,…,B类)估计值的对于任何固定λ理想情况下,我们想知道pFDR(γ)然后是MSE的自举估计(λ)将是
(25)
然而,我们不知道pFDR(γ),所以我们必须对这个数量进行插入式估算(Efron和Tibshirani,1993). 对于任何λ我们有
(26)
如第节所示三因此,我们对pFDR的插件估计(γ)是.MSE估算(λ)就是那个时候
(27)
该方法可以很容易地并入第节所述的主要方法中三以计算高效的方式。我们建议的选择方法λ在算法3中进行了形式上的详细说明。最后要注意,在选择λ在q值上,我们可以最小化平均MSE(λ)在所有的q个-值并相应地调整算法3。
我们在以下设置下提供了一些数值结果。我们测试了米假设N个(0,1)与N个(1,1)具有拒绝区域Γ=[c(c), ∞ ). 每个统计数据都是独立的,因此,当我们形成引导统计数据时,我们只需从米统计数据。我们计算了一下λ最好的每种情况下的真实均方误差。对于每个参数集,我们使用B类=500,然后平均其预测的均方误差曲线。通过取最小值平均均方误差曲线。取100的中位数产生几乎相同的结果。
图。5显示的结果米=1000和c(c)=2超过值π0=1,0.8,0.5,0.2. 对程序的应用进行平均,只有100次可以得出正确的结果λ最好的对于前三个案例。预测均方误差曲线并不重要,重要的是预测其最小值在哪里。从图中也可以看出,bootstrap程序对任何λ.表三显示了其他几组参数的仿真结果。可以看出,即使在它们的真实均方误差相差不大,因此几乎在我们模拟的所有情况下都能达到最小均方误差。
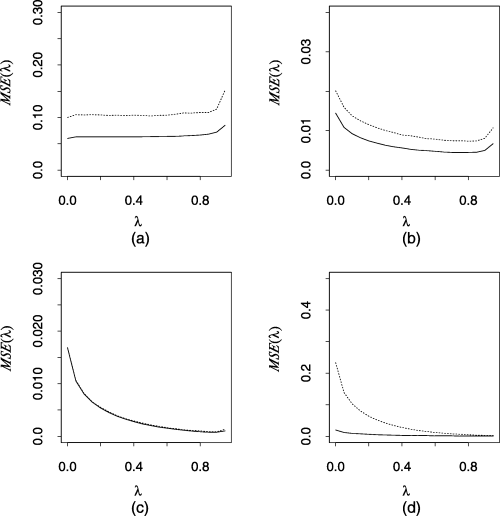
图5
MSE图(λ)与λ对于Γ=[2,∞),对于(a)π0=1,(b)π0=0.8,(c)π0=0.5和(d)π0=0.2(--,真正的均方误差;………….引导程序预测的平均误差,100个应用程序的平均值)
| π0. | 米. | 切割点. | λ最好的. | . | MSE公司(λ最好的). | (). |
|---|
| 1 | 1000 | 2 | 0 | 0 | 0.0602 | 0.0602 |
| 0.8 | 1000 | 2 | 0.8 | 0.8 | 0.00444 | 0.00444 |
| 0.5 | 1000 | 2 | 0.9 | 0.9 | 0.000779 | 0.000779 |
| 0.2 | 1000 | 2 | 0.95 | 0.9 | 0.000318 | 0.000362 |
| 0.8 | 100 | 2 | 0.75 | 0.65 | 0.123 | 0.127 |
| 0.8 | 500 | 2 | 0.75 | 0.75 | 0.00953 | 0.00953 |
| 0.8 | 10000 | 2 | 0.9 | 0.9 | 0.000556 | 0.000556 |
| 0.8 | 1000 | 0 | 0.7 | 0.85 | 0.00445 | 0.00556 |
| 0.8 | 1000 | 1 | 0.7 | 0.8 | 0.00361 | 0.00385 |
| 0.8 | 1000 | 三 | 0.85 | 0.9 | 0.0323 | 0.0326 |
| π0. | 米. | 切割点. | λ最好的. | . | MSE公司(λ最好的). | (). |
|---|
| 1 | 1000 | 2 | 0 | 0 | 0.0602 | 0.0602 |
| 0.8 | 1000 | 2 | 0.8 | 0.8 | 0.00444 | 0.00444 |
| 0.5 | 1000 | 2 | 0.9 | 0.9 | 0.000779 | 0.000779 |
| 0.2 | 1000 | 2 | 0.95 | 0.9 | 0.000318 | 0.000362 |
| 0.8 | 100 | 2 | 0.75 | 0.65 | 0.123 | 0.127 |
| 0.8 | 500 | 2 | 0.75 | 0.75 | 0.00953 | 0.00953 |
| 0.8 | 10000 | 2 | 0.9 | 0.9 | 0.000556 | 0.000556 |
| 0.8 | 1000 | 0 | 0.7 | 0.85 | 0.00445 | 0.00556 |
| 0.8 | 1000 | 1 | 0.7 | 0.8 | 0.00361 | 0.00385 |
| 0.8 | 1000 | 三 | 0.85 | 0.9 | 0.0323 | 0.0326 |
| π0. | 米. | 切割点. | λ最好的. | . | MSE公司(λ最好的). | (). |
|---|
| 1 | 1000 | 2 | 0 | 0 | 0.0602 | 0.0602 |
| 0.8 | 1000 | 2 | 0.8 | 0.8 | 0.00444 | 0.00444 |
| 0.5 | 1000 | 2 | 0.9 | 0.9 | 0.000779 | 0.000779 |
| 0.2 | 1000 | 2 | 0.95 | 0.9 | 0.000318 | 0.000362 |
| 0.8 | 100 | 2 | 0.75 | 0.65 | 0.123 | 0.127 |
| 0.8 | 500 | 2 | 0.75 | 0.75 | 0.00953 | 0.00953 |
| 0.8 | 10000 | 2 | 0.9 | 0.9 | 0.000556 | 0.000556 |
| 0.8 | 1000 | 0 | 0.7 | 0.85 | 0.00445 | 0.00556 |
| 0.8 | 1000 | 1 | 0.7 | 0.8 | 0.00361 | 0.00385 |
| 0.8 | 1000 | 三 | 0.85 | 0.9 | 0.0323 | 0.0326 |
| π0. | 米. | 切割点. | λ最好的. | . | MSE公司(λ最好的). | (). |
|---|
| 1 | 1000 | 2 | 0 | 0 | 0.0602 | 0.0602 |
| 0.8 | 1000 | 2 | 0.8 | 0.8 | 0.00444 | 0.00444 |
| 0.5 | 1000 | 2 | 0.9 | 0.9 | 0.000779 | 0.000779 |
| 0.2 | 1000 | 2 | 0.95 | 0.9 | 0.000318 | 0.000362 |
| 0.8 | 100 | 2 | 0.75 | 0.65 | 0.123 | 0.127 |
| 0.8 | 500 | 2 | 0.75 | 0.75 | 0.00953 | 0.00953 |
| 0.8 | 10000 | 2 | 0.9 | 0.9 | 0.000556 | 0.000556 |
| 0.8 | 1000 | 0 | 0.7 | 0.85 | 0.00445 | 0.00556 |
| 0.8 | 1000 | 1 | 0.7 | 0.8 | 0.00361 | 0.00385 |
| 0.8 | 1000 | 三 | 0.85 | 0.9 | 0.0323 | 0.0326 |
9.1. 算法3:pFDR的估计和推断(γ)和FDR(γ)具有最佳λ
- (a)
对于某些范围λ,说吧R(右)={0,0.05,0.10,…,0.95},计算如第节所示三.
- (b)
对于每个λ∈R(右),表单B类引导程序版本在估计中,b条=1,…,B类.
- (c)
对于每个λ∈R(右),估计其各自的均方误差为(28)
- (d)
设置我们对pFDR的总体估计(γ)是(29)
- (e)
表格a 1−α的上置信区间通过使用1−α分位数作为上端点(下端点为0)。
- (f)
在估计FDR时,使用而不是。
10.讨论
本文提出了一种新的多假设检验方法。我们建议固定拒绝区域并估计错误率,而不是将错误率设置在特定水平并估计拒绝区域。这种方法可以更直接地分析问题。我们已经看到,结果是一种更强大、更适用的方法。例如,我们估计了一个新的定义,正错误发现率,我们认为这个定义通常更合适。通过使用具有固定抑制区域的pFDR的理论结果,我们可以得到pFDR和FDR的良好估计。有趣的是,本杰米尼和霍奇伯格(1995)升压法自然就不适用于这些结果。
我们在本文中讨论的所有内容都是在假设我们正在与独立的第页-值。在更一般的情况下,如相关性或非参数情况下,可以应用非常相似的思想来获得pFDR和FDR的准确估计。查看Storey和Tibshirani(2001)来治疗这个。这种方法还揭示了其他几个悬而未决的问题。可能还有其他更好的估计。人们也可能在某些框架内证明关于估计pFDR的最优性定理。
这个q个-讨论了该值,它是第页-价值。尽管必须事先确定拒绝区域或错误率可能不方便q个-价值观要求我们两者都不做。通过开发具有固定拒绝区域的方法,我们可以制定q个-以概念上简单的方式进行评估。作为一个悬而未决的问题,研究计算的q个-我们称之为.
在一篇非常有趣的论文中,弗里德曼(2001)讨论了统计在新兴的数据挖掘领域中的作用。数据挖掘涉及调查发现“有趣”特征的巨大数据集。经典的例子是确定哪些产品倾向于在杂货店一起购买。通常,确定有趣特征的规则没有简单的统计解释。可以理解的是,假设检验在这一领域没有发挥重要作用,因为我们拥有的假设越多,发现效果的力量就越小。这里介绍的方法具有相反的性质——我们执行的测试越多,估计就越好。因此,在这种方法下,拥有具有许多测试的大型数据集是一种优势。唯一的要求是测试必须是可交换的,即第页-值具有相同的null分布。
即使测试是独立的,我们的方法也可以完全应用。它在Storey中显示(2001)依赖性的影响可以忽略,如果米对于一大类依赖关系来说是很大的。还有Storey和Tibshirani(2001)处理了依赖性不能被忽视的情况。因此,我们希望这种提出的多假设测试方法不仅在基因组学或小波分析等领域有用,而且在数据挖掘领域也有用,因为在数据挖掘中,需要从许多有趣的特征中找出几个,同时限制假阳性发现的比率。
致谢
感谢Bradley Efron和Ji Zhu的宝贵意见和建议。我特别感谢我的导师罗伯特·蒂布什拉尼的想法和鼓励。这项研究得到了国家科学基金会研究生奖学金的部分支持。
工具书类
附录A:备注和证明
备注1。
这里,我们解释为什么第页-值的格式应为[0,γ]. 回想一下,对于一组嵌套的拒绝区域{Γ}第页-的值X(X)=x个定义为
(30)
因此,对于两个第页-值第页1和第页2,第页1≤第页2意味着各自观察到的统计数据x个1和x个2是这样的x个2∈Γ蕴涵x个1∈Γ. 因此,无论何时第页2被拒绝,第页1也应该被拒绝。
定理1的证明。查看故事(2001)用于定理1的证明。
定理2的证明。召回根据方程式(9). 还要注意的是
(31)
因此,
(32)
自Pr{R(右)(γ)>0}≥1−(1−γ)米在独立状态下。调节开启R(右)(γ),因此
(31)
通过独立,E类{W公司(λ)|R(右)(γ)}是的线性非递增函数R(右)(γ)、和E类{V(V)(γ)|R(右)(γ)}是的线性非递减函数R(右)(γ). 因此,通过Jensen不等式R(右)(γ)由此可见
(34)
自E类{R(右)(γ)}=E类{R(右)(γ)|R(右)(γ)>0}优先{R(右)(γ)>0},因此
35
另外,请注意
36
(37)
上一次不平等持续至今E类{R(右)(γ)}≥Pr{R(右)(γ)>0}. 因此,
(38)
(39)
(40)
(41)
现在
(42)
因此,.
既然我们展示了
43
和
(44)
由此可见.
备注2。
在前面的证明中,它隐含地使用了小时我都是随机的。然而,这种假设是不必要的,事实上,替代统计数据是独立的假设也是不必要的。查看Storey和Tibshirani(2001)在这些较弱的假设下证明定理2。
定理3的证明。
定理3的证明很容易遵循以下几点:
(45)
自pFDR(γ)≤1.证明如下所示。
定理4的证明。
召回根据方程式(9). 根据强大的大数定律,几乎可以肯定。此外,Pr(P(P)≥λ|小时=0)=1−λ和Pr(P(P)≥λ|小时=1)=1−克(λ),其中克(λ)是拒绝的力量超过[0,λ]如第节所述三因此,根据强大的大数定律W公司(λ)/米→(1−λ)π0+{1−克(λ)}π1几乎可以肯定。因此,可以得出以下结论
(46)
推论的证明1。
自克(λ)凹进λ, {1−克(λ)}/(1−λ)没有增加λ因此,最小值{1−克(λ)}/(1−λ)在lim获得λ→1[{1−克(λ)}/(1−λ)]. 根据《乐施会》的规定,
定理5的证明。
我们可以观察两者R(右)(γ)和R(右)(λ). 根据定理1的假设,数据的可能性可以写成
(47)
还有
(48)
结果来自标准方法。
备注3。
如果克(●)已知,则pFDR的最大似然估计(γ)是
(49)
©2002皇家统计学会







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}