每一代GPU都会继续变得更快,通常情况下,GPU上的每个活动(例如内核或内存副本)都会很快完成。 在过去,每个活动都必须由CPU单独调度(启动),相关的开销可能会累积起来,成为性能瓶颈。 CUDA Graphs工具通过将多个GPU活动调度为单个计算图形来解决此问题。
这篇文章描述了CUDA图形最近如何被 GROMACS公司 是一个用于生物分子系统的模拟软件包,也是全球使用最广泛的科学软件应用之一。 我们将介绍CUDA图和GROMACS,描述我们将CUDA图集成到GROMACS中(并与之共同设计)的工作,展示性能结果,并向您展示如何在GROMAC斯中使用CUDA图。
经过NVIDIA和 核心GROMACS开发人员 ,以充分利用现代GPU加速服务器。 有关更多详细信息,请参阅 使用GROMACS 2020创建更快的分子动力学模拟 , 使用MPS和MIG通过每个GPU进行多个模拟来最大化GROMACS吞吐量 , 使用GROMACS大幅提高多节点NVIDIA GPU的可扩展性 、和 GROMACS中分子动力学模拟的异构并行化和加速 (以及其中的引用)。
背景 GROMACS之旅的最新一步是使用CUDA图进一步提高性能。 此功能在新的2023版本中可用。 这项共同设计工作不仅包括应用程序级专家,还包括NVIDIA CUDA软件开发团队。 结合先进的CUDA Graphs技术改进GROMACS将最终造福于其他应用程序。
CUDA图 本节简要概述了以GROMACS友好方式构建的CUDA图。 请参阅上一篇文章, CUDA图形入门 ,以全面介绍CUDA图形。
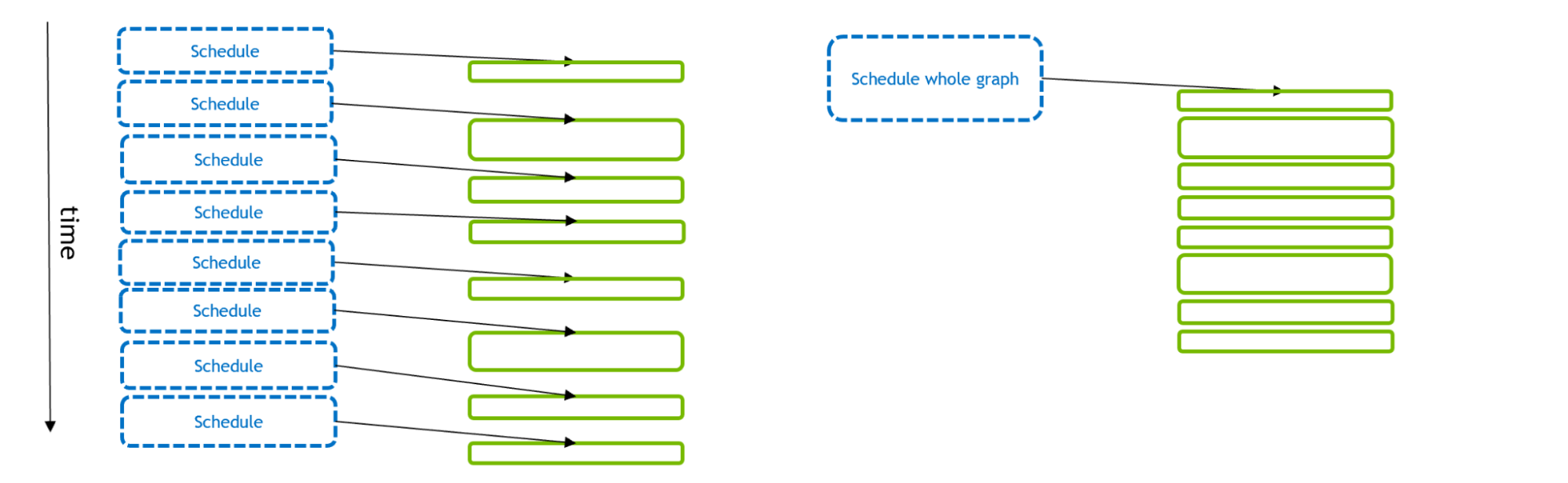
图1描述了许多GPU活动的调度和执行。 使用传统的流模型(左),每个GPU活动都由一个CPU API调用单独调度。 使用CUDA图(右),单个API调用可以调度全套GPU活动。
图1。 图中显示了调度和执行GPU活动所用的时间,左侧是传统流模型,右侧是CUDA图模型。 GPU活动由实心绿色矩形表示,CPU API调用由蓝色矩形表示。 如果GPU活动很小,那么调度时间可能比执行时间更长。 这会使GPU处于饥饿状态(在内核之间留下间隙),总体执行效果不佳。 但是,如果在单个CUDA图中调度多个GPU活动,则可以减少CPU API时间,从而实现更优化的GPU执行。 此外,使用Graphs,CUDA驱动程序可以利用有关工作流的额外信息来优化图形本身的GPU执行。
如中所述 CUDA图形入门 ,将现有的基于流的代码调整为使用图形相对简单。 该功能通过几个额外的CUDA API调用将流执行“捕获”到图形中。 我们利用此功能,使预先存在的GROMACS代码能够使用图形而不是流来执行。
GROMACS公司 GROMACS是了解重要生物过程的关键工具,包括新冠肺炎等潜在流行病。 每个GROMACS模拟都使用牛顿运动方程通过重复更新来演化许多粒子系统,其中粒子间作用力决定粒子的运动。
虽然物理过程相当简单,但实现过程(必然)非常复杂,要通过多个级别的并行化和加速来实现非常高的性能。 因此,每个模拟时间步长都涉及一个高度复杂的任务调度(通常为微秒级)。
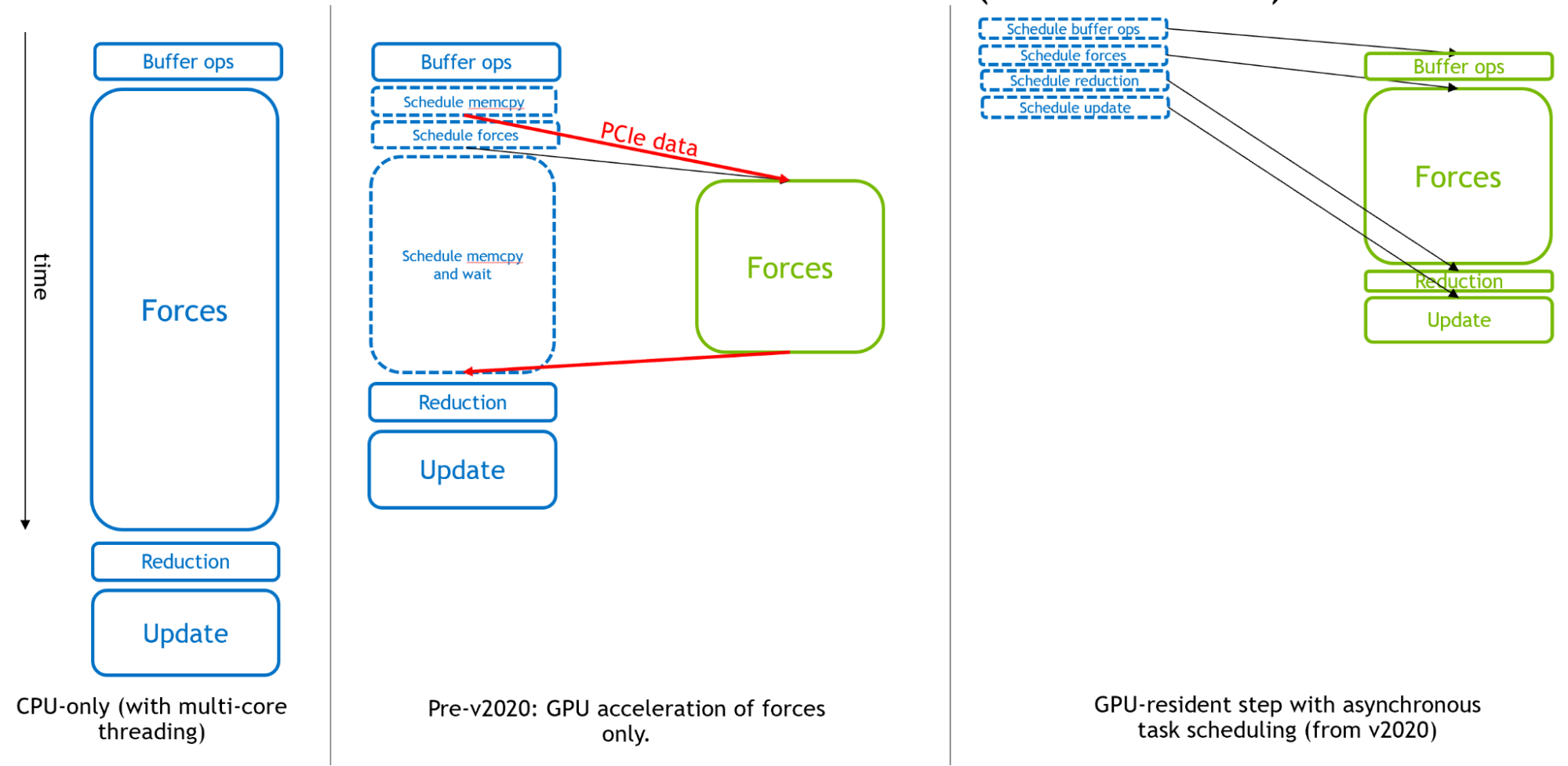
图2从左到右显示了GROMACS是如何演变成用于分子动力学的异步GPU引擎的。
图2。 GROMACS仿真时间步长的执行说明。 在仅CPU模式(左)中,实心矩形对应于CPU计算。 由于只有部队被卸载到GPU(中央),CPU执行混合计算和调度活动。 在新的GPU驻留模式(右)中,CPU只负责调度,所有计算都在GPU上执行。
最初,CPU用于每个模拟时间步的全部。 然后,在GPU计算的早期,昂贵的力计算被卸载到GPU上,以实现有效的整体加速度。
最后,为了支持速度极快的现代GPU,从GROMACS 2020版开始,可以卸载所有其他组件,以启用“GPU驻留模式”,其中模拟状态在GPU上保持多次迭代,CPU主要负责调度GPU上异步执行的活动。 要了解更多信息,请参阅 使用GROMACS 2020创建更快的分子动力学模拟 .
图2的右侧部分显示了GPU计算(如果它们足够大)如何形成执行的“关键路径”,以便这些组件的性能决定整体仿真性能。
然而,随着GPU性能的不断提高,小的情况可能会受到CPU调度开销的限制,而不是GPU执行的限制,如前一节所述。 当并行使用多个GPU来执行单个GROMACS模拟时,尤其如此。
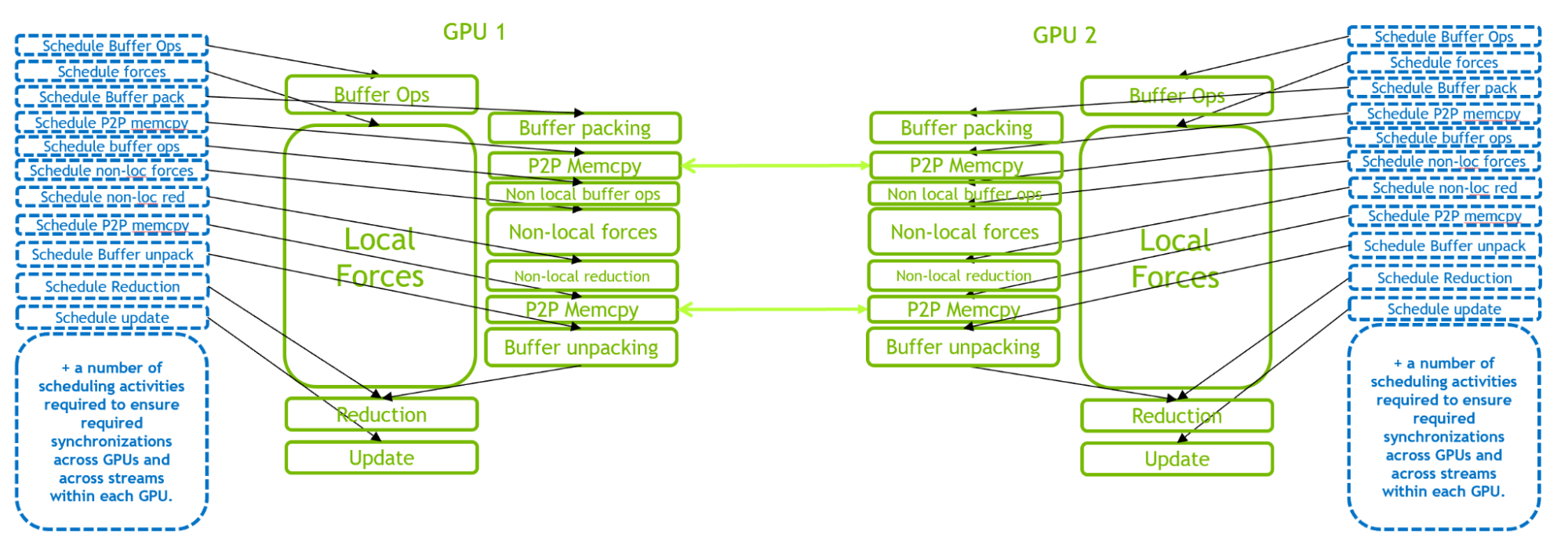
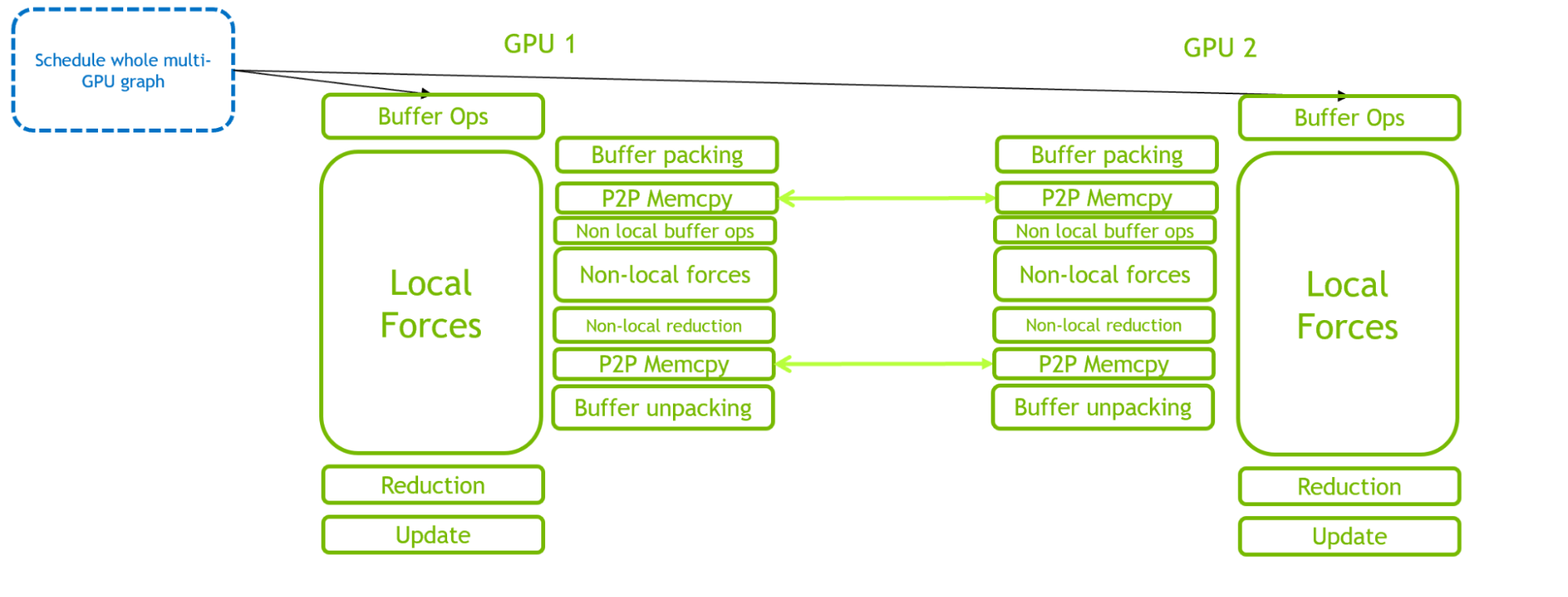
图3。 针对2-GPU运行的GROMACS模拟时间步长的执行图示。 存在大量CPU调度活动来管理多GPU通信和同步。 图3说明了2-GPU情况下的GPU驻留模式。 与单GPU情况相比,由于GPU内部和内部的复杂交互,此场景带来了更为苛刻的CPU调度工作负载。 当引入更多的GPU时,调度工作负载的要求甚至更高。
因此,在许多小的情况下,性能瓶颈是CPU调度开销,而不是GPU执行。 这促使在GROMACS中引入CUDA图,以便能够将多个活动安排为单个图,如下一节所述。
在GROMACS中实现CUDA图 本节介绍如何将CUDA图引入GROMACS。 在较高级别上,图形捕获和回放功能的使用风格与中提供的示例类似 CUDA图形入门 .
GROMACS实现中存在许多与GROMACS可以在不同步骤上执行的不同类型任务相关的复杂性,以及与管理多GPU任务和域分解相关的复杂性。 请继续阅读以获得简要概述。 有关完整的技术详细信息,请参阅GitLab问题, 实现CUDA图形功能并执行相关重构 ,以及其中链接的合并请求。
请注意,GROMACS执行不同类型的模拟步骤:“常规”步骤加上不常见的“不规则”步骤,其中包括必须偶尔执行的额外活动(压力耦合、温度耦合、邻居列表更新、域分解等)。 我们通过每个步骤使用单独的图将CUDA图引入GROMACS,并且so-far只支持完全驻留在自然界中的常规步骤。
在每个模拟时间步长上:
检查此步骤是否支持CUDA图形。 如果是:
检查是否已经存在合适的图形。 如果是:
Else:捕获、实例化并保存新图形
Else:使用传统流执行步骤
这样可以在绝大多数步骤中使用CUDA图执行。 有必要重新捕获并为每个邻域列表或域分解步骤创建一个新的图形可执行文件(通常是每100-400个步骤),这是非常罕见的,因此开销最小。
对于多GPU,在所有GPU上使用单个图形。 到目前为止,仅支持 螺纹-MPI ,其中多GPU图是通过利用CUDA在同一进程内跨不同GPU分叉和连接流的自然能力来定义的(使用基于事件的GPU侧同步),并将这些工作流自动捕获到单个图中。
我们在GROMACS中创建了一个新类来管理所有必需的功能。 对于多GPU,这包括额外的基于事件的fork和join操作,以允许跨多个GPU定义和执行单个图形。
图4。 2-GPU运行的GROMACS仿真时间步长的执行说明,其中使用单个CUDA图调度完整的多GPU时间步长 通过比较图3和图4,可以清楚地看到CUDA图在减少CPU端开销方面的好处。 关键路径从CPU调度开销转移到GPU计算。
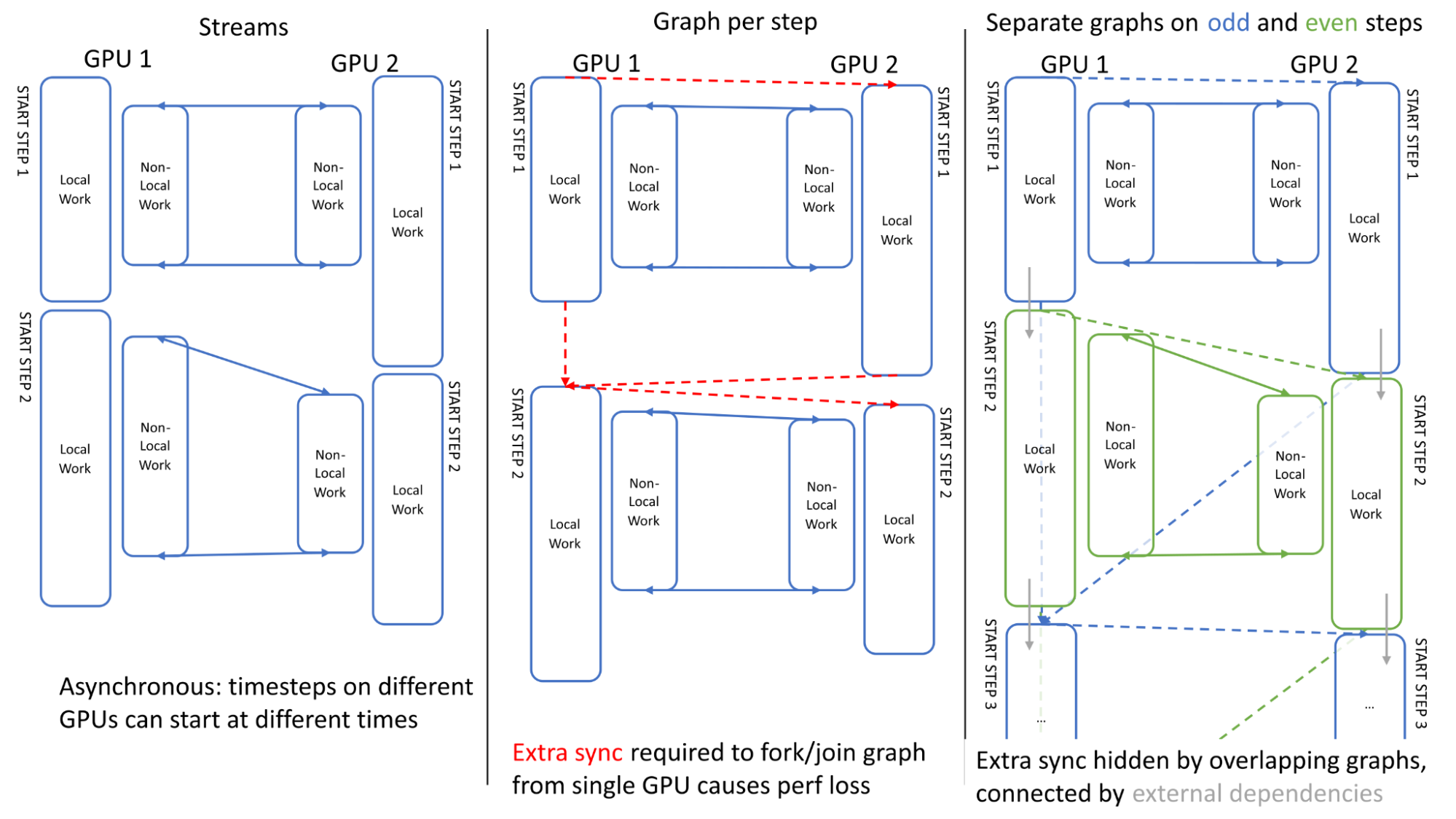
图5。 两个GPU上两个模拟时间步长的流和图执行比较 为了最大限度地提高多GPU的性能,在链接多个模拟时间步长时确保GPU之间的异步非常重要。 图5说明了跨两个步骤的GPU活动。 可以看出,当使用传统流时,GPU之间的执行是异步的:GPU1可以在GPU2完成第一步之前开始第二步(左)。
我们第一次尝试使用单个图形进行调度时遇到了一个问题:定义图形所需的额外同步(分叉/连接到单个GPU上的开始/结束点)丢失了这种异步,导致开销(中心)。
我们通过在奇数步和偶数步(右)上使用单独的图来解决这个问题,其中奇数步与偶数步使用“外部”CUDA事件进行链接,这些事件可以记录在一个图中,并在另一个图(用灰色箭头表示)中排队,有效地重叠了额外的同步。
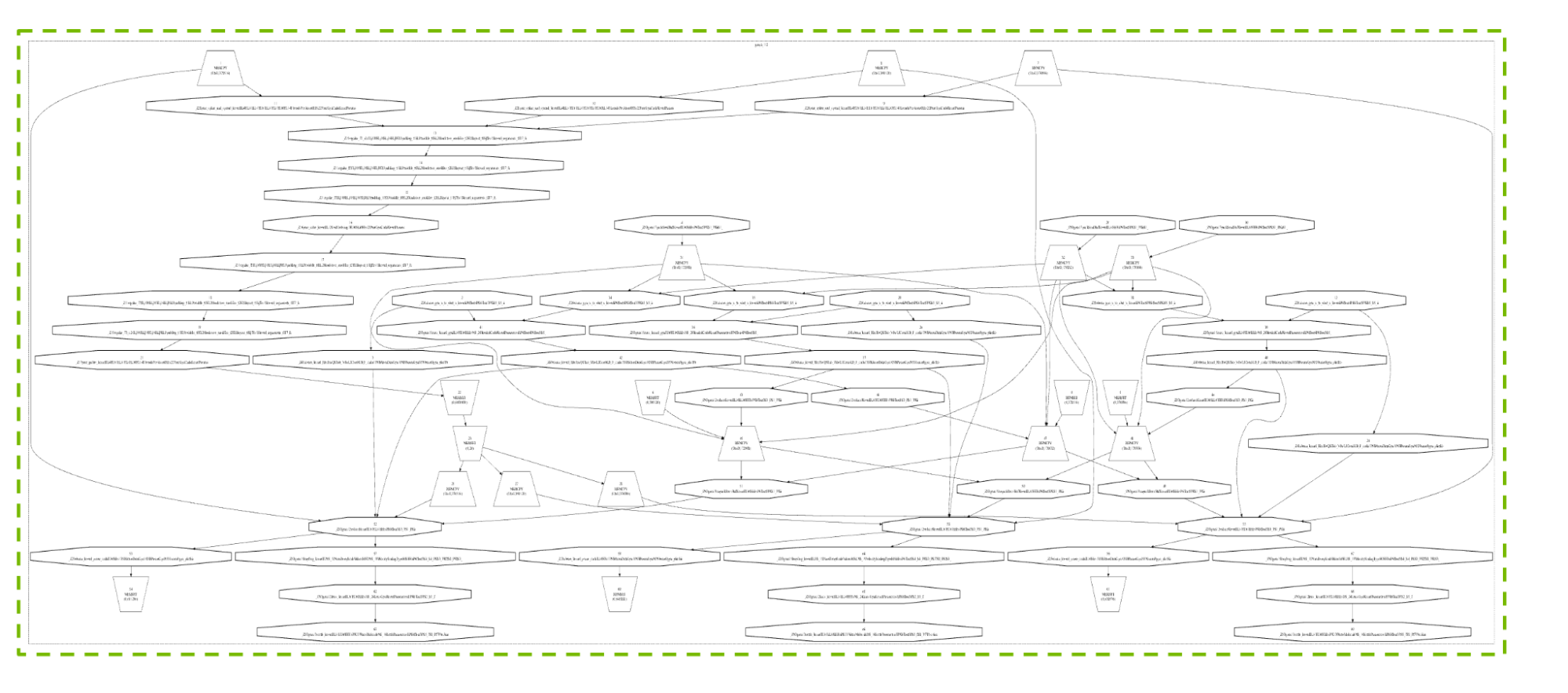
图6显示了典型4-GPU配置的常规时间步长产生的真实图形。 我们不打算描述细节,但包含此图是为了提供所涉及的许多活动和依赖关系的可视化,以及CUDA图如何能够如此有效地处理这种复杂性。
图6。 具有三个Particle-Particle GPU和一个Particle Mesh Ewald GPU的4-GPU案例的真实CUDA图,显示了总体复杂性(而非细节)。 使用获得的图像 cuda图形DegugDotPrint CUDA Graphs技术本身的开发受到了GROMACS要求的指导,包括支持图形更新和多线程图形捕获,以及图形中的流优先级支持。 这些增强功能还将最终惠及其他应用程序。
我们使用了 水箱 一组基准,用于演示GROMACS中CUDA图的优点。 这组基准测试可在 gromacs.org基准测试库 它具有提供多个原子数的优点,可以评估性能行为如何随系统大小而扩展。
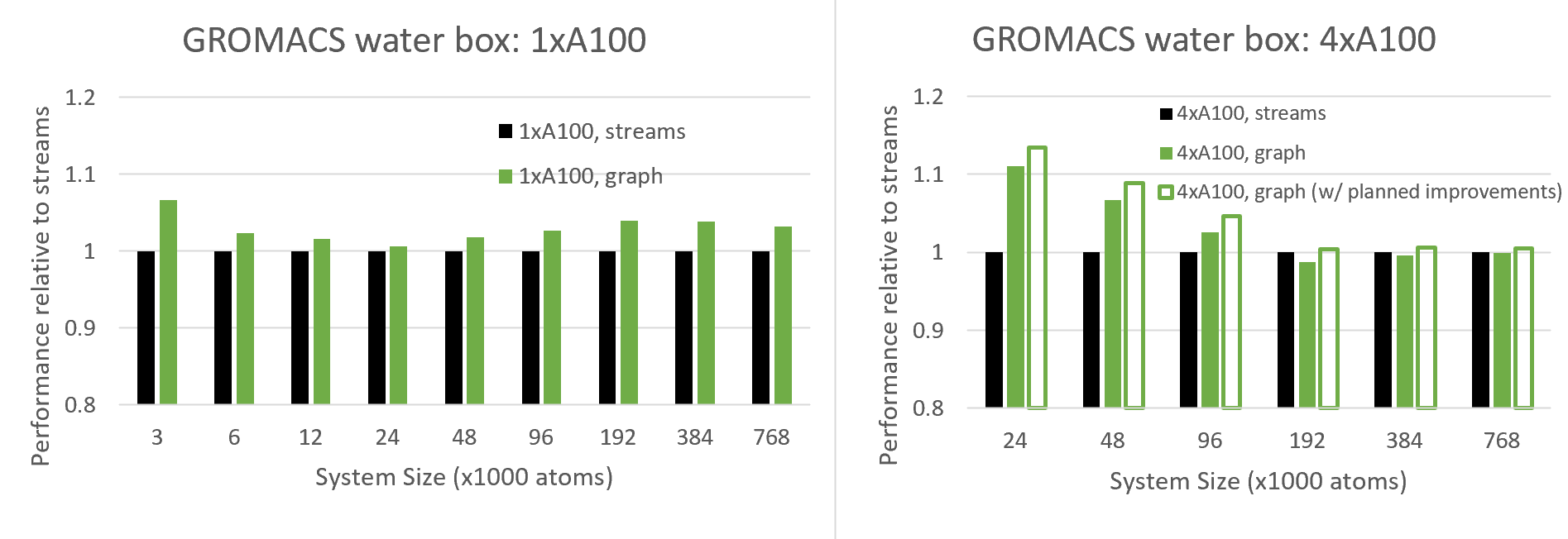
图7。 当使用单个GPU(左)和四个并行GPU(右)时,使用CUDA图与传统流进行性能比较,对于配置了原子数范围的水箱系统 图7比较了新CUDA Graphs功能与传统流的性能,对于不同的系统大小,无论是单GPU还是4-GPU运行。
由于CUDA图旨在减少CPU API开销,这在小型情况下最为显著,因此我们希望在小型系统中看到越来越多的好处,我们确实看到了多GPU情况下的这种行为,以及单GPU情况中24K原子和更低原子的这种行为。
有趣的是,对于24K原子以上的单GPU情况,当系统大小达到约100K原子时,好处实际上会增加,在那里它会趋于稳定。 可以看出,与各种系统大小相比,图表具有显著的性能优势。 这种行为需要更多的调查,但我们预计这是由于CUDA Graphs的GPU端优势,在使用图形时,CUDA可以更有效地跨多个内核调度线程块。
对于多GPU情况,图形的好处更为深远,因为(如上所述)由于其复杂的调度,此配置对CPU API开销更为敏感。 在当前版本中,我们看到了大约100K原子的好处(在这种情况下),在这上面我们看到了轻微的退化。
然而,我们还显示了计划改进的预计结果,该改进减少了与重复重新构建图表相关的开销。 这种改进需要未来版本的CUDA驱动程序的支持,目前正在与GROMACS共同设计中进行改进。 通常,我们建议用户针对自己的情况尝试CUDA Graphs,并在有利的地方启用该功能(请参阅下一节)。
如何在GROMACS中使用CUDA图 如上所述,此新的CUDA图功能可用于GPU驻留步骤,通常在通过以下方式将所有强制和更新计算卸载到GPU时调用 mdrun软件 选项:
-nb gpu-绑定gpu-pme gpu-更新gpu 当使用多个任务并行运行以启用多个GPU时,GROMACS应该使用其内部线程MPI库而不是外部MPI来构建( -DGMX_MPI=关闭 ); 应通过设置以下环境变量来指定GPU直接通信:
导出GMX_ENABLE_DIRECT_GPU_COMM=1 应使用指定单个PME GPU -核动力装置1 .
然后,CUDA图形可以通过以下方式触发:
导出GMX_CUDA_GRAPH=1 我们建议尝试任何特定的情况,如果图形具有性能优势,则选择使用图形。 请注意,这仍然是一个实验特性,测试有限,因此应注意确保结果符合预期(例如,通过比较使用和不使用图形的科学结果子集)。 我们欢迎在 GROMACS GitLab公司 现场。
总结 这篇文章描述了我们如何将CUDA图集成到GROMACS中。 这使得CPU可以在单个计算图中调度多个GPU活动,这比传统的流编程模型更加优化。 我们演示了这些好处,包括在多个GPU上并行运行时的好处。 这项工作是我们正在努力的一个重要部分,即通过基于图形的任务调度使GROMACS现代化,以帮助开发日益复杂的硬件来解决日益复杂的科学问题。
要开始,请按照本文中提供的说明为您自己的GROMACS案例激活CUDA图形。
想了解更多信息吗? 加入 GROMACS论坛 .