基于短语的教程
本教程使用一个可从Moses网站下载的简单模型描述了Moses中基于短语的解码器的工作原理。
内容
一个简单的翻译模型
让我们首先看看基于短语的玩具翻译模型可从下载http://www.statmt.org/moses/download/sample-models.tgz.打开焦油球包装并进入目录样本模型/短语模型.
模型由两个文件组成:
短语表短语翻译表,以及摩西·伊尼解码器的配置文件。
让我们看一下短语翻译表(文件短语表):
排序为0.3|||
这个条目意味着翻译英语单词的可能性这个来自德国命令为0.3。或者用数学符号表示:p(the | der)=0.3。注意,由于信道模型有噪声,这些平移概率的顺序是相反的。
翻译表是机器翻译解码器的主要知识来源。解码器查阅这些表格,找出如何将一种语言的输入转换为另一种语言输出。
作为短语翻译模型,翻译表不仅包含单字条目,还包含多字条目。这些被称为短语但这个概念只意味着一个任意的单词序列,没有复杂的语言动机。
下面是中短语翻译条目的示例短语表:
das ist这是0.8|||
运行解码器
不用再麻烦了,让我们运行解码器(它需要从样本模型目录):
%echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini>out定义的参数(根据moses.ini或开关):配置:短语模型/moses.ini输入系数:0lmodel文件:8 0 3 lm/europarl.srim.gz映射:T 0n个最佳列表:nbest.txt 100ttable-file:0 0 0 1短语模型/短语表ttable-limit:10个重量-d:1重量-1:1重量t:1重量-w:0正在加载词法失真模型。。。有0个模型开始加载LanguageModel lm/europarl.strim.gz:[0.000]秒如果构建二进制文件,加载LM将更快。阅读lm/europarl.srim.gz----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100****************************************************************************************************ARPA文件丢失<unk>。替代log10概率-100.000。已完成加载LanguageModels:[2.000]秒开始加载短语表短语模型/短语表:[2.000]秒文件路径:短语模型/短语表已完成加载短语表:[2.000]秒开始从短语模型/短语表加载短语表:[2000]秒阅读短语模型/短语表----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100****************************************************************************************************已完成加载短语表:[2.000]秒来自STDOUT/STDIN的IO创建的输入输出对象:[2.000]秒正在转换线程id 0中的行0翻译:das ist ein kleines haus收集选项耗时0.000秒搜索耗时0.000秒最佳翻译:这是一栋小房子[11111][总数=-28.923]<<0.000,-5.000,0.000,-27.091,-1.833>>翻译耗时0.000秒已完成翻译%猫出来了这是一所小房子
在这里,玩具模型成功地翻译了德语输入句子das ist ein kleines haus公司融入英语这是一所小房子,这是一个正确的翻译。
解码器由配置文件控制摩西·伊尼。上面示例中使用的文件如下所示。
############################MOSES配置文件#############################输入因素[输入因素]0#映射步骤,(T)转换或(G)生成[映射]温度0[功能]KENLM名称=LM系数=0顺序=3个特征=1路径=LM/europarl.srilm.gz失真文字惩罚未知罚款短语定义内存输入系数=0输出系数=0路径=phrase-model/phrase-table num-features=1 table-limit=10[重量]惩罚字0=0LM=1畸变0=1短语词典记忆0=1[n个最佳列表]nbest.txt(英文)100
我们将查看此处指定的所有参数(和然后一些)。在这一点上,让我们注意到这里指定了模型文件和语言模型文件。在这个例如,文件名是相对路径,但通常是完整的路径更好,因此解码器不必从特定目录。
我们只是在命令中提供的一个句子上运行了解码器行。通常我们要翻译多个句子。在这个在这种情况下,输入的句子存储在一个文件中,每行一个句子。这个文件通过管道传输到解码器,输出通过管道传输到一些用于进一步处理的输出文件:
%moses-f短语模型/moses.ini<短语模型/in>out
跟踪
解码器的工作原理在背景第节。但是,让我们首先通过观察引擎盖下面来发展直觉。有两个开关可强制解码器显示其内部工作的更多信息:-报告细分和-冗长的.
trace选项显示在解码器找到的最佳翻译。使用运行解码器分段跟踪开关(短-t吨)在同一个例子上
echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini-t>out
为我们提供了扩展输出
%猫出来了这是0-2小3-3房子4-4|
现在,每个生成的英语短语都添加了附加注释信息:
这是由德语单词0-1生成,达斯主义者,一由德语单词2-2生成,ein公司,小的源于德语单词3-3,克莱因,以及房子源于德语单词4-4,豪斯.
请注意,德语句子不必翻译成顺序。这里是一个重新排序英文输出的示例:
echo'ein haus ist das'| moses-f短语模型/moses.ini-t权重覆盖“失真0=0”
此命令的输出是:
这个3-3是2-2是0-0房子1-1|
详细
现在是下一个切换,-冗长的(短-v(v)),它显示其他运行时信息。解码器输出的冗长程度分为三个级别。默认值为1。接下来是-第2版提供每个翻译句子的附加统计信息:
%echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini-v 2[...]翻译(1):das is ein kleines haus翻译选项总数:12修剪的翻译选项总数:0
关于这些句子的翻译使用了多少翻译选项的简短总结。
堆栈大小:1,10,2,0,0堆栈大小:1、10、27、6、0、0堆栈大小:1、10、27、47、6、0堆栈大小:1、10、27、47、24、1堆栈大小:1、10、27、47、24、3堆栈大小:1、10、27、47、24、3
堆栈解码器每次迭代后的堆栈大小。迭代是在一个堆栈上处理所有假设:在第一次迭代(处理最初的空假设)之后,覆盖一个德语单词的10个假设被放置在堆栈1上,覆盖两个外来单词的2个假设被放在堆栈2上。请注意这与12个翻译选项的关系。
生成的假设总数=453重组数量=69修剪的数量=0提前丢弃的数量=272
在波束搜索过程中,生成了大量假设(453)。许多被提前丢弃,因为它们被认为太糟糕了(272),或者在后期被修剪(0),还有一些被重新组合(69)。剩下的留在烟囱里。
源字总数=5删除的单词=0()插入的单词=0()
有关单词删除和插入的一些附加信息,这两个高级选项在默认情况下未激活。
最好的翻译:这是一栋小房子[11111][总数=-28.923]<<0.000,-5.000,0.000,-27.091,-1.833句子解码时间::[4.000]秒
最后,翻译后的句子、其覆盖向量(设置了5个德语输入词的所有5位)、其整体对数概率分数,以及分数分解为语言模型、重新排序模型、单词惩罚和翻译模型组件。
给出了句子的解码时间。
最详细的输出-第3版提供了更多信息。事实上,它太多了,我们不可能在本教程中使用它。运行以下命令并享受:
%echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini-v 3
让我们一起来看一些亮点。总翻译分数由几个部分组成。解码器报告这些组件,在我们的示例中:
分数分量向量如下所示:0失真分数1个单词的惩罚2未知单词惩罚3 3克LM分数,因子类型=0,文件=LM/europarl.srilm.gz4翻译分数,文件=短语表
解码之前,短语请参阅翻译表以了解可能的短语翻译。对于某些短语,我们可以找到词条,而对于其他短语,我们什么也找不到。以下是摘录:
[das;0-0]pC=-0.916,c=-5.789这个,pC=-2.303,c=-8.002它,pC=-2.303,c=-8.076[dasist;0-1]它是,pC=-1.609,c=10.207即pC=-0.223,c=10.291[ist;1-1]是,pC=0.000,c=-4.922s,pC=0.000,c=-6.116
短语旁边的一对数字是覆盖范围,保时捷中心表示短语翻译概率的对数,在c(c)给出了该短语的未来成本估算。
未来成本是对句子不同部分翻译难度的估计。查找短语翻译概率后,计算句子中所有连续跨度的未来成本:
从0到0的未来成本是-5.789从0到1的未来成本是-10.207从0到2的未来成本是-15.722从0到3的未来成本是-25.443从0到4的未来成本是-34.709从1到1的未来成本是-4.922从1到2的未来成本为-10.437从1到3的未来成本为-20.158从1到4的未来成本为-29.425从2到2的未来成本是-5.515从2到3的未来成本是-15.236从2到4的未来成本是-24.502从3到3的未来成本为-9.721从3到4的未来成本是-18.987从4到4的未来成本是-9.266
这个句子的某些部分比其他部分更容易翻译。例如,前两个单词(0-1:达斯主义者)被认为比后两种(3-4:克莱恩·豪斯, -18.987). 同样,负数是对数概率。
在所有这些准备工作之后,我们开始通过一次翻译一个短语来创建部分翻译。第一个假设是通过将第一个德语单词翻译为这个:
从0创建假设1(<s>)基本得分0.000覆盖0-0:das翻译为:得分-2.951+未来成本-29.425=-32.375未加权特征得分:<0.000、-1.000、0.000、-2.034、-0.916>>向堆栈添加了hyp,在堆栈上效果最好,现在大小为1
这里,从空的初始假设0开始,一个新的假设(身份证件=1)已创建。从零成本(底分)开始,翻译短语达斯进入之内这个携带翻译成本(-0.916)、失真或重新排序成本(0)、语言模型成本(-2.034)和单词惩罚(-1)。回想一下,分数分量信息是早先打印出来的,所以我们能够解释向量。
总的来说,累计的加权对数概率成本为-2.951。再加上句子剩余部分(-29.425)的未来成本估算,该假设的得分为-32.375。
所以它继续下去,共有453个假设被创造出来。最后,找到得分最高的最终假设,并向后遍历假设图以检索最佳翻译:
最佳路径:417<=285<=163<=5<=0
困惑够了吗?在我们深入了解解码器内部工作的复杂细节之前,让我们回到实际使用它。在阅读背景信息。
调整质量
好的翻译性能的关键是有一个好的短语翻译表。但是解码器可以进行一些调整。最重要的是模型参数的调整。
分配给翻译的概率成本是四种模型概率成本的乘积:
- 短语翻译表,
- 语言模型,
- 重新排序模型,以及
- 单词惩罚。
每一个模型都提供了一个好翻译特征方面的信息:
- 这个短语翻译表确保了英语短语和德语短语相互之间的良好翻译。
- 这个语言模型确保输出流利的英语。
- 这个畸变模型允许重新排序输入句子,但有代价:重新排序越多,翻译成本越高。
- 这个文字惩罚确保翻译不会太长或太短。
可以为每个组件指定一个权重,以确定其重要性。从数学上讲,翻译成本是:
p(e|f)=φ(f|e)^weight_phi*LM(e)^ weight_LM*D(e,f)^weight _D*W(e)*weight_W
将给定外来输入f的英语翻译e的概率p(e|f)分解为四个模型,短语翻译phi(f|e)、语言模型LM(e)、失真模型D(e,f)和单词惩罚W(e)=exp(长度(e))。四个模型中的每一个都有一个权重。
权重通过四个参数提供给解码器重量t,重量l,重量-d,以及重量-w。这些权重的默认设置为1、1、1和0。这些也是配置文件中的值摩西·伊尼.
将这些权重设置为正确的值可以提高翻译质量。我们已经潜入了上面的一个例子。翻译德语句子时ein haus ist das公司,我们将失真权重设置为0以获得正确的平移:
%echo“ein haus ist das”|摩西-f短语模型/摩西.ini-d 0这是一所房子
使用默认权重时,转换结果会出错:
%echo“ein haus ist das”|摩西-f短语模型/摩西.ini房子是
什么是正确的权重设置取决于语料库和语言对。通常,使用一个持久的开发集来优化参数设置。这里最简单的方法是尝试大量可能的设置,并选择最有效的设置。短语翻译表权重的良好值(重量t,短tm(tm)),语言模型(重量-1,短勒姆)、和重新排序模型(重量-d,短d日)是0.1-1,很适合单词pension(重量-w,短w个)为-3-3。单词pension的负值有利于较长的输出,正值有利于较短的输出。
速度调节
现在让我们看看有助于加快速度的一些其他参数向上打开解码器。不幸的是,更高的速度通常以翻译质量。通过限制搜索来实现加速解码器的空间。通过删除部分搜索空间,我们可以再也找不到最好的翻译了。
转换表大小
限制搜索空间的一个策略是减少每个输入短语使用的翻译选项,即检索到的短语翻译表条目。在玩具里的时候例如,翻译表非常小,可以有在实际场景中,每个短语有数千个条目。如果短语翻译表是从实际数据中学习的,它包含了很多噪音。所以,我们真正感兴趣的只是最可能的并希望排除其他人。
有两种限制转换表大小的方法:通过固定对每个输入检索的翻译选项数量的限制短语,并按概率阈值指定短语转换概率必须高于某个值。
如果没有,请比较玩具模型的统计数据和翻译输出使用了转换表限制
%echo“das ist ein kleines haus”|摩西-f短语模型/moses.ini-ttable-limit 0-v 2[...]翻译选项总数:12[...]生成的假设总数=453重组数量=69修剪的数量=0提前丢弃的数量=272[...]最好的翻译:这是一栋小房子[11111][total=-28.923]
当使用极限值1时,统计和翻译输出
%echo“das ist ein kleines haus”|摩西-f短语模型/moses.ini-ttable-limit 1-v 2[...]翻译选项总数:6[...]生成的假设总数=127重组数=8修剪的数量=0提前丢弃的数量=61[...]最好的翻译:这是一栋小房子[11111][total=-30.327]
将翻译选项的数量减少到每个短语只有一个效果数量:(1)总体上只有6个翻译选项,而不是收集了12个翻译选项。(2) 生成的数量假设从442下降到127,没有删减任何假设。(3) 翻译发生了变化,现在输出的对数概率更低:-30.327对-28.923。
假设堆栈大小(波束)
减少搜索的另一种方法是减少假设堆栈。每翻译一个外来词,解码器保存一堆最佳(部分)翻译。通过减小堆栈大小,搜索将更快,因为每个阶段都有假设,因此假设较少生成。这在背景第页。
从用户的角度来看,搜索速度与最大堆栈成线性关系大小。将以下系统运行与堆栈大小1000、100(默认值)、10和1:
%echo“das ist ein kleines haus”|摩西-f短语模型/mose.ini-v 2-s 1000[...]生成的假设总数=453重组数量=69修剪的数量=0提前丢弃的数量=272[...]最好的翻译:这是一栋小房子[11111][total=-28.923]%echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini-v 2-s 100[...]生成的假设总数=453重组数量=69修剪的数量=0提前丢弃的数量=272[...]最好的翻译:这是一栋小房子[11111][total=-28.923]%echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini-v 2-s 10[...]生成的假设总数=208重组数量=23修剪的数量=42提前丢弃的数量=103[...]最好的翻译:这是一栋小房子[11111][total=-28.923]%echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini-v 2-s 1[...]生成的假设总数=29重新组合的数量=0修剪的数量=4提前丢弃的数量=19[...]最好的翻译:这是一座小房子[11111][total=-30.991]
注意,随着堆栈大小的增加,输入到堆栈中的假设数量越来越少:453、453、208和29。
正如我们之前对翻译表修剪所描述的那样,我们可能还想使用假设的相对分数进行修剪,而不是固定的极限。这两种策略也称为直方图修剪和阈值修剪。
这里有一些实验来显示不同堆栈大小限制和波束大小限制的影响。
%echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini-v 2-s 100-b 0[...]生成的假设总数=1073重组数量=720修剪的数量=73提前丢弃的数量=0[...]%echo“das ist ein kleines haus”|摩西-f短语模型/摩西.ini-v 2-s 1000-b 0[...]生成的假设总数=1352重组数=985修剪的数量=0提前丢弃的数量=0[...]%echo“das ist ein kleines haus”|摩西-f短语模型/mose.ini-v 2-s 1000-b 0.1[...]生成的假设总数=45重组数量=3修剪的数量=0提前丢弃的数量=32[...]
在第二个示例中,没有进行修剪,这意味着执行了彻底搜索。使用较小的堆栈大小或较小的阈值,我们会面临搜索错误的风险,这意味着生成的翻译的得分低于最佳翻译到模型。
在这个玩具示例中,只有堆栈大小为1时才会生成较差的转换。同样,根据我们的模型,翻译糟糕意味着得分更差(-30.991 vs.-28.923)。另一个问题是,就翻译质量而言,它是否真的是一个较差的翻译。然而,解码器的任务是找到最佳评分翻译。如果评分较差的翻译质量更好,那么这是模型的问题,应该通过更好的建模来解决。
变形限制(重新排序)
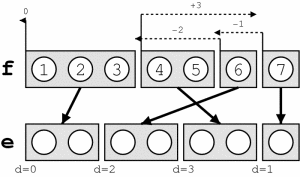
解码器中实现的基本重排序模型相当薄弱。重新排序的成本是通过在挑选出不符合顺序的外来短语时跳过的单词数来衡量的。
总再订购成本按D(e,f)=-∑计算我(di)其中每个短语i的d定义为d=abs(之前翻译短语的最后一个单词位置+1-新翻译短语的第一个单词位置)。
下图说明了这一点:
这种重新排序模型适用于本地重新排序:它们是不鼓励,但可能在语言的充分支持下发生模型。但大规模的重新排序往往是武断的对翻译绩效产生负面影响。
通过限制重新排序,我们不仅可以加快解码器的速度,通常翻译性能会得到提高。重新排序可以是限制为跳过的最大字数(最多d个)用开关-畸变极限,或短-数字图书馆.
将此参数设置为0意味着单调转换(无需重新排序)。如果您想允许无限制的重新排序,请使用值-1。