实验管理系统
内容
介绍
实验管理系统(EMS),或Experiment.perl,由于没有更好的名称,使使用Moses进行实验变得更容易。
进行实验有很多步骤:准备训练数据、建立语言和翻译模型、调整、测试、评分和结果分析。对于大多数这些步骤,需要调用不同的工具,因此这很容易变得非常混乱。
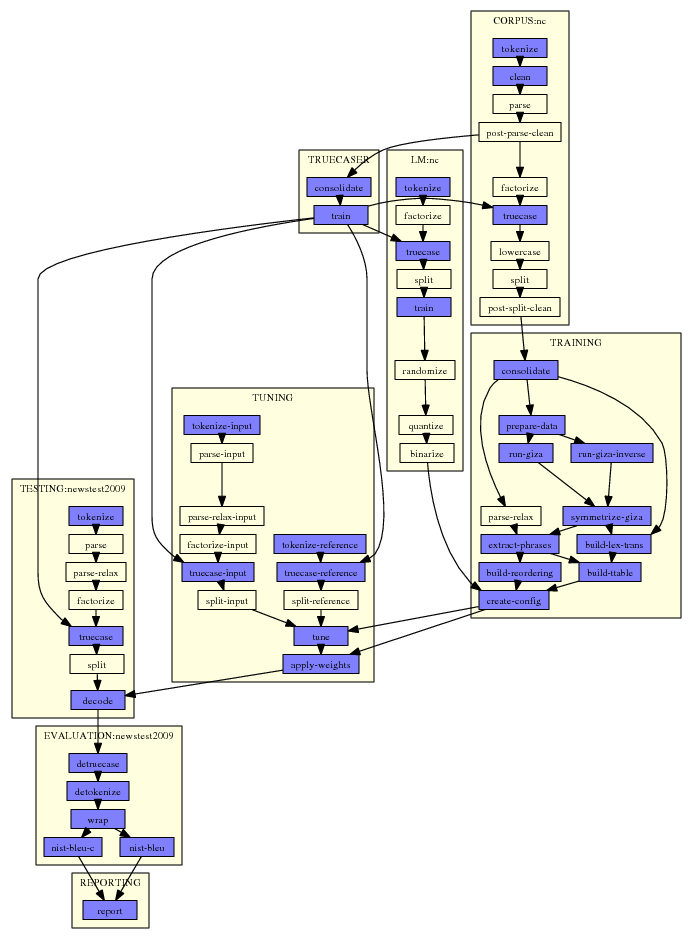
这里是一个典型的例子:
该图由Experiment.perl自动生成。需要做的只是指定一个配置文件,该文件指向实验的数据文件和设置。
在图中,每个步骤都是一个小方框。对于每个步骤,Experiment.perl构建一个脚本文件,该文件要么提交到集群,要么在同一台机器上运行。请注意,其中涉及一些步骤,例如调优:在集群上,调优脚本在头节点上运行,a将作业提交给队列本身。
使用Experiment.perl可以轻松运行具有不同设置或数据资源的多个实验运行。它会自动检测哪些步骤不必再次执行,而可以重新使用之前运行的结果。
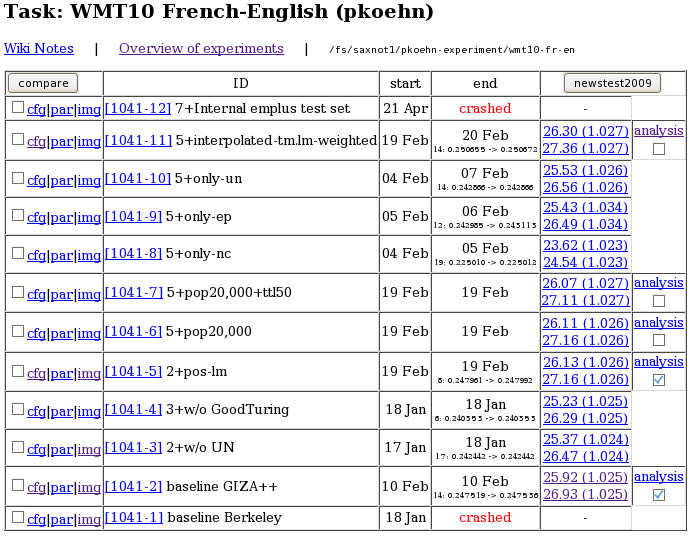
Experiment.perl还为实验运行提供了一个web界面,便于访问和比较实验结果。
网络界面还提供了一些基本的结果分析,例如比较两种不同实验运行之间的n元匹配:
要求
为了正常运行,EMS需要:
快速入门
Experiment.perl使用极其简单:
- 查找
实验.perl在里面脚本/ems
- 从某处获取示例配置文件(例如
scripts/ems/example/config.toy). - 为此任务设置实验的工作目录(
mkdir公司这样做)。 - 在中编辑以下路径设置
配置玩具
工作目录
数据dir
摩西-脚本-dir
摩西-src-dir
srilm-dir(电影目录)
解码器
- 运行
experist.perl-config配置玩具从你的实验工作目录。 - 惊叹于图形化的行动计划。
- 运行
experist.perl-config config.toy-exec. - 检查实验结果(in
评估/报告。1)
让我们仔细看看刚刚发生的事情。
配置文件配置玩具由几个部分组成。例如,每个要使用的语言模型语料库都有一个部分。在我们的玩具示例中,此部分包含以下内容:
[LM:玩具]###原始语料库(未标记)#raw-corpus=$toy-data/nc-5k$输出扩展
设置生皮语料库的位置。定义使用变量$toy-data(玩具数据)和$输出扩展,这也是配置文件中其他地方定义的设置。这些变量被解析,从而得到文件路径ems/examples/data/nc-5k.en在摩西脚本目录中。
步骤及其交互的权威定义在文件中实验.元数据(位于与experiat.perl相同的目录中:脚本/ems).
的逻辑实验.元数据它想在最后创建一个报告。为了生成报告,它需要评估分数,为了得到这些分数,它需要解码输出,为了得到它们,它需要运行解码器,为了能够运行解码器,它需要一个经过训练的模型,为了训练它需要数据的模型。定义要执行的步骤议程的过程与Unix中的Make实用程序非常相似。
我们可以在中找到语言模型模块的以下步骤定义实验.元数据:
获取corpus在:get-corpus-script中输出:raw-corpus默认名称:lm/txt模板:IN>OUT标记化in:raw-corpus输出:标记化语料库默认名称:lm/tok传递除非:输出标记化器模板:$output-tokenizer<IN>OUT可并行化:是
标记化步骤标记化要求生皮作为输入。在我们的示例中,我们在配置文件中指定了设置。我们还可以指定一个已经标记化的语料库标记化语料库。这将允许我们跳过标记化步骤。或者,举另一个例子,我们可以不指定生皮,而是指定一个脚本,该脚本使用设置生成语料库获取corpus-script。这将触发步骤的创建获取corpus.
这些步骤与其输入的定义相关联在里面和输出外面的。每个步骤还具有输出的默认名称(默认名称)和其他设置。
标记化步骤的默认名称为1米/托克。让我们看看目录勒姆查看其中包含的文件:
%ls-tr长度/*lm/toy托克11米/玩具。特制。1lm/玩具.lm.1
我们在文件中找到标记化步骤的输出lm/toy托克1. The玩具是从语言模型的名称定义中添加的(请参见[LM:玩具]在里面配置玩具). 这个1添加了,因为这是第一次实验运行。
目录步骤包含执行每个步骤的脚本、STDERR和STDOUT输出以及元信息。例如:
%ls步骤/1/LM_toy_tokenize.1*|cat步骤/1/LM_toy_tokenize。1步骤/1/LM_toy_tokenize.1完成步骤/1/LM_toy_tokenize.1INFO步骤/1/LM_toy_tokenize.1.STDERR步骤/1/LM_toy_tokenize.STDERR.digest步骤/1/LM_toy_tokenize.1.STDOUT
文件步骤/2/LM_toy_tokenize。2是为执行步骤而运行的脚本。具有扩展名的文件完成在步骤完成时创建-这将向调度程序传递可以执行后续步骤的信息。扩展名为的文件信息包含元信息-步骤的基本设置和依赖项。检查此文件以检测是否可以在新的实验运行中重新使用步骤。
如果踏板发生故障,我们预计会有故障迹象STDERR公司(例如单词段错误或被杀死的). 检查此文件以查看步骤是否已成功执行,因此可以计划后续步骤或在新的实验中重新使用该步骤。自从STDERR公司文件可能非常大(某些步骤会创建兆字节的此类输出),在中创建摘要版本STDERR.摘要。如果步骤成功,则为空。否则,它包含触发故障检测的错误模式。
现在让我们仔细看看重用。如果我们再次运行实验,但更改了一些设置,例如语言模型的顺序,则无需重新运行标记化。
以下是中语言模型培训步骤的定义实验.元数据:
火车in:split-corpus输出:lm默认名称:lm/lmignore-if:rlm培训重新运行-更改:lm-培训订单设置模板:$lm-training-order$order$settings-text IN-lm OUT错误:无法执行二进制文件
提到秩序在后面的列表中更改后重新运行通知experity.perl,如果语言模型的顺序发生变化,则确实需要重新运行此步骤。由于培训前步骤链中的所有设置都没有更改,因此可以重新使用该步骤。
尝试更改语言模型顺序(顺序=5在里面配置玩具),再次运行experiat.perl(experist.perl-config配置玩具)在工作目录中,您将在目录中看到新的语言模型勒姆:
%ls-tr长度/*lm/toy托克11米/玩具。特制。1lm/玩具.lm.1lm/玩具.lm.2
更多示例
这个例子目录包含一些其他示例。
这需要为WMT 2010的共享翻译任务发布培训和调整数据。创建一个工作目录,并将其更改为。然后执行以下步骤:
mkdir数据cd数据wget公司http://www.statmt.org/wmt10/training-parallel.tgztar xzf培训-并行.tgzwget公司http://www.statmt.org/wmt10/dev.tgztar xzf开发.tgz光盘。。
使用这些语料库的示例有
配置基本配置-基于短语的基本模型,配置系数化-基于短语的分解模型,配置层次结构-基于短语的分层模型,以及配置语法-目标语法模型。
在所有这些示例配置文件中,大多数语料库都被注释掉了。这是通过添加单词来完成的IGNORE公司在语料库定义的末尾(也用于语言模型)。这允许您仅对完成得相对较快的新闻评论语料库进行基本实验。移除IGNORE公司包括更多培训数据。在使用一些较大的语料库(尤其是新闻语言模型)时,您可能会遇到内存和磁盘空间问题,这取决于您的计算基础设施。
如果你决定为语言模型使用多个语料库,你可能还想尝试对单个语言模型进行插值(而不是将它们用作单独的特征函数)。为此,您需要注释掉IGNORE公司紧挨着[国际刑警组织-LM]第节。
您还可以通过更改输入扩展,输出扩展、和成对扩展设置。
最后,您可以在同一工作目录中使用不同的给定配置文件和数据变体运行所有实验。实验管理系统自动计算出哪些处理步骤不需要重复,因为它们可以从以前的实验运行中重新使用。
短语模型
与以下示例相比,短语模型是使用Moses训练的最简单模型,也是运行速度最快的模型。你可能更喜欢这些模型,而不是更复杂的模型,这些模型的复杂性可能无法证明小的(如果有的话)收益是合理的。
这个例子配置基本配置与玩具示例类似,只是有一个较大的训练和测试语料库。此外,不会跳过调优阶段。因此,即使大多数语料库都被注释掉了,整个实验运行也可能需要一天的时间,大部分时间都用在单词对齐上(训练_ run-giza和TRAINING_run-giza-反向)和调谐(调谐(_T)).
因子短语模型
因子模型允许在单词级别进行附加注释,这些注释可能会在各种模型中使用。中的示例配置系数化在英语目标端使用部分对话标记。
带有部分语音标记的注释是用MXPOST完成的,需要先安装。请阅读安装说明。在此之后,可以使用配置文件运行experiat.perl配置系数化.
如果您比较因子化示例配置系数化使用基于短语的示例配置.basic,您将注意到所使用因子的定义:
###因子训练:在此处指定使用的因子#如果未指定,则假定为单因素培训#(一个平移步骤,面到面)#input-factors=单词output-factors=单词pos对齐因子=“单词->单词”翻译因素=“单词->单词+位置”reordering-factors=“word->word”#生成系数=decoding-steps=“t0”
因子定义:
##################################################################因子定义[输入-因素]#也用于输出因子temp-dir=$working-dir/training/factor[输出系数:位置]###生成该因子的脚本#mxpost=/home/pkoehn/bin/mxpostfactor-script=“$moses-script-dir/training/wrappers/make-factor-en-pos.mxpost.perl-mxpost$mxpost”
以及针对部分语音标记的7克语言模型规范:
[LM:nc=位置]因子=“pos”顺序=7settings=“-interplate-nunk”raw-corpus=$wmt10-data/training/news-commentary10.$pair-extension$输出扩展
这个使用所有可用语料库的因子模型与爱丁堡提交给WMT 2010的英语-西班牙语、西班牙语-英语和英语-德语语言对共享任务相同(法语语言对也使用109语料库中,捷克语对没有使用POS语言模型,而德语-英语使用了额外的预处理步骤)。
层次模型
层次短语模型允许有间隙的规则。由于这些由非终结符表示,并且此类规则最好使用与语法图解析类似的搜索算法进行处理,因此此类模型属于基于树或基于语法的模型类别。有关更多信息,请查看语法教程.
从使用experist.perl设置层次模型的角度来看,与基于短语的模型的配置文件相比,几乎不需要更改:
%差异配置基本配置层次结构33立方厘米33<解码器=$moses-src-dir/bin/moses--->解码器=$moses-src-dir/bin/moses_chart36立方厘米36<ttable-binarizer=$moses-src-dir/bin/processPhraseTable--->#ttable-binarizer=$moses-src-dir/bin/processPhraseTable39立方厘米39<#ttable-binarizer=“$moses-src-dir/bin/CreateOnDiskPt 1 1 5 100 2”--->ttable二进制化器=“$moses src dir/bin/CreateOnDiskPt 1 1 5 100 2”280平方厘米<词汇化重排序=msd-bidirectional-fe--->#lexicalized-reordering=msd-bidirectional-fe284c284号<#hierarchical-rule-set=真--->hierarchical-rule-set=真413c413个<decoder-settings=“-search-algorithm 1-cube-pruning-pop-limit 5000-s 5000”--->#解码器设置=“”
更改包括:不同的解码器二进制文件(默认编译为箱子/摩西图表)和可二进制化器使用。短语立方体修剪的解码器设置不适用。此外,分层模型不允许词汇化的重新排序(它们的规则实现相同的目的),必须启用分层规则集的设置层次规则集.
目标语法模型
语法模型意味着对层次模型的非终结符使用语言注释。这需要运行语法分析器。
在我们的示例中配置语法,语法仅用于英语目标端。语法成分用Collins解析器标记,需要先安装。请阅读安装说明.
与层次模型相比,配置文件中几乎不需要更改:
%diff配置层次结构配置语法46年47月49日>#语法分析器>柯林斯=/home/pkoehn/bin/collins-PARSER>output-parser=“$moses-script-dir/training/wrappers/parse-en-colins.perl”>241c244号<#extract-settings=“”--->extract-settings=“--MinHoleSource 1--NonTermConsecSource”
需要指定解析器,并且可以调整提取设置。你已经准备好出发了。
再尝试几件事
词干对齐
因子化翻译模型训练可以很容易地建立单词对齐,而不是基于单词的表面形式,而是基于单词的任何其他属性。一种相对流行的方法是使用词干词进行单词对齐。
这有两个原因:首先,对于形态丰富的语言,词干处理克服了数据稀疏性问题。其次,GIZA++在词汇量很大的情况下可能会遇到困难,词干会减少独特单词的数量。
要在experiat.perl中设置词干对齐,需要将词干定义为一个因子:
[输出因子:阀杆4]factor-script=“$moses-script-dir/training/wrappers/make-factor-stem.perl 4”[输入-系数:阀杆4]factor-script=“$moses-script-dir/training/wrappers/make-factor-stem.perl 4”
并指出该系数在培训部分:
input-factors=单词词干4output-factors=字干4alignment-factors=“stem4->stem4”translation-factors=“word->word”重新排序因子=“单词->单词”#生成系数=decoding-steps=“t0”
使用多线程GIZA++
GIZA++是培训流程中最慢的步骤之一。Qin Gao实现了GIZA++的多线程版本,称为MGIZA,它可以加快多核机器上的单词对齐。
要使用MGIZA,您首先需要安装它。
要使用它,只需在部分中添加一些培训选项培训:
###一般选项#培训选项=“-mgiza-mgiza-cpus 8”
使用Berkeley Aligner
Berkeley Aligner是GIZA++的另一种单词对齐方式。使用此工具可能会(也可能不会)获得更好的结果。
要使用Berkeley Aligner,首先需要安装它。
示例配置文件中已有一节用于工具的参数。您需要取消注释并进行调整伯克利罐到您的安装。你应该发表评论线形对称法,因为这是GIZA++设置。
###从giza输出中获取单词对齐的对称化方法#(常用:grow-diag-final-and)##alignment-symmetrization-method=grow-diag-final-and###使用berkeley对齐器进行单词对齐#use-berkeley=真对准对称化方法berkeley-train=$moses脚本目录/ems/support/berkeley-train.sh伯克利进程=$moses-script-dir/ems/support/berkeley-process.shberkeley-jar=/your/path/to/berkeleyaligner-2.1/berkekeleyaigner.jarberkeley-java-options=“-server-mx30000m-ea”berkeley-training-options=“Main.iters 5 5-EMWordAligner.numThreads 8”berkeley-process-options=“EMWordAligner.numThreads 8”伯克利-后=0.5
伯克利校准器分两步进行:一个训练步骤从数据中学习对齐模型,另一个处理步骤为训练数据找到最佳对齐。此步骤包含参数伯克利-后调整朝向或多或少对齐点的偏移。您可以尝试使用此参数的不同值进行不同的运行。Experiment.perl不会重新运行训练步骤,只会重新运行处理步骤。
使用Dyer's Fast Align
GIZA++的另一个替代方案是快速对齐(_A)从Dyer等人。。它运行得更快,甚至可以提供更好的结果,特别是对于没有大规模重新排序的语言对。
要使用Fast Align,首先需要安装它。
示例配置文件已经使用推荐的默认值提供了该工具的示例设置。只需在设置之前删除注释标记@#@:
###使用Chris Dyer的快速对齐进行单词对齐#fast-align-settings=“-d-o-v”
Experiment.perl假设您将二进制文件复制到了通常的外部bin目录(设置外部-内部)GIZA++和其他外部二进制文件所在的位置。
IRST语言模型
提供的示例在解码期间使用SRI语言模型。当您想使用IRSTLM时,需要额外的处理步骤:语言模型必须转换为二进制格式。
这部分LM公司第节定义了IRSTLM的使用:
###用于irstlm二进制表格式的脚本#(默认:无二进制化)##lm-binarizer=$moses-src-dir/irstlm/bin/compile-lm###创建量化语言模型格式的脚本(irstlm)#(默认:无量化)# #lm-量化器=$moses-src-dir/irstlm/bin/quantize-lm
如果你不发表评论lm二进制化器,将使用IRSTLM。如果您另外评论lm-量化器,语言模型将被压缩为更紧凑的表示。注意,上面的值假设您在目录中安装了IRSTLM工具包$moses-src-dir/irstlm(美元).
随机语言模型
随机语言模型允许更紧凑(但有损)的表示。能够为语言模型使用更大的语料库可能会有助于减少出错的可能性。
首先,你需要安装RandLM工具包。
训练随机语言模型有两种不同的方法。一个是从头开始训练。另一种方法是将SRI语言模型转换为随机表示。
从头开始培训:在示例配置文件中找到以下部分,并取消注释rlm培训设置。注意,下面的部分假设您在目录中安装了随机语言模型工具包$moses-src-dir/randlm(美元).
###用于从头开始训练随机语言模型的工具#(更常见的是,对SRILM进行培训)#rlm-training=“$moses-src-dir/randlm/bin/buildlm-falsepos 8-values 8”
转换SRI语言模型:在示例配置文件中找到以下部分,并取消注释lm-随机化器设置。
###用于转换为随机表格式的脚本#(默认:无随机化)#lm-randomizer=“$moses-src-dir/randlm/bin/buildlm-falsepos 8-values 8”
您可能想尝试其他值假的和值。请参阅语言模型部分兰德LM有关这些参数的更多信息。
您还可以通过指定lm-随机化器在节中插值-LM.
复合拆分
复合语言,如德语,允许创建长单词,如Neuwortgenerierung公司(新词生成). 这会在任何文本中产生大量未知单词,因此从这些语言翻译时,分割这些复合词是一种常见的方法。
摩西(Moses)提供了一个支持工具,如果单词各部分的频率的几何平均值高于单词的频率,那么它可以拆分单词。该方法需要一个模型(语料库中单词的频率统计),因此有一个训练和应用步骤。
只需在概述部分:
input-splitter=$moses-script-dir/generic/compound-splitter.perl
当前不支持在输出端拆分单词。
一本简短的手册
基本原理是:实验.perl将统计机器翻译系统的训练、调整和评估分解为多个步骤,然后根据它们的相互依赖性和可用资源安排并行或顺序运行。文件中定义了可能的步骤实验.元数据。实验由配置文件定义。
运行实验的主要模块有:
语料库:准备平行语料库,致动器输入和输出系数:创建因子的命令,培训:培训翻译模型,LM公司:训练语言模型,插值-LM:插入语言模型,分离器:训练分词模型,重复:训练重铸者,信任:训练truecaser,调谐:运行最小错误率训练以设置组件权重,测试:翻译测试集并为其评分,以及报告:在一个文件中编译所有分数。
实验。Meta公司
实际步骤、它们的相关性和其他重要信息可在文件中找到实验.meta。把experiment.meta想象成一个“模板”文件。
以下是步骤描述的部分CORPUS:get-CORPUS公司和CORPUS:标记化:
获取corpus在:get-corpus-script中输出:原始状态[...]标记化in:原始-静态输出:标记化阀杆[...]
每个步骤都需要一些输入(在里面)并提供一些输出(外面的). 这也建立了步骤之间的依赖关系。这一步标记化需要输入原始状态。这由步骤提供获取corpus.
实验.元数据为步骤及其交互提供了通用模板。对于实际实验,配置文件确定需要运行哪些步骤。此配置文件是在调用时指定的实验.perl。例如,它可能包含以下内容:
[公司:欧洲中心]###原始语料库文件(未标记,但句子对齐)#raw-stem=$europarl-v3/training/europarl-v3.fr-en
这里,将要使用的平行语料库命名为欧洲议会并且在位置中以原始文本格式提供$europarl-v3/training/europarl-v3.fr-en(变量$europarl-v3在配置文件的其他位置定义)。配置文件中此规范的作用是获取corpus不需要运行,因为它的输出是以文件的形式给出的。下一节将详细介绍下面的配置文件。
中指定了几种类型的信息实验.元数据:
在里面和外面的:建立步骤之间的依赖关系;输入也可以由配置中指定的文件提供。默认名称:将在其中存储步骤输出的文件的名称。模板:放置在步骤的执行脚本中的命令模板。模板-if:执行脚本的潜在命令。仅当第一个参数存在时才使用。错误:实验.perl通过扫描STDERR中的关键字(如killed、error、dead、not found等)来检测步骤是否失败。此参数提供了其他关键字和短语。无误:声明默认错误关键字不表示失败。无通行证:只有在定义了给定参数的情况下,才会执行此步骤,否则会传递此步骤(如图中的黄色框所示)。无知的:如果定义了给定参数,则不执行此步骤。这将覆盖下游步骤的要求。重新运行切换:如果运行类似的实验,如果输入和参数设置相同,则可以使用步骤的输出。这指定了一些参数,这些参数的更改不允许在不同的运行中重复使用。可并行化的:在集群上运行时,此步骤可以并行(仅当通用并行器在配置文件中设置,则可以在中找到脚本$moses-script-dir/scripts/ems/support.qsub脚本:如果在集群上运行,则此步骤在头节点上运行,而不会提交到队列(因为它自己提交作业)。
下面是步骤的完整定义配置:标记化
标记化in:原始-静态输出:标记化阀杆默认名称:语料库/tokpass-unless:输入-转换器输出-转换器template-if:input-tokenizer IN.$input-extension OUT$输入扩展模板if:output标记化器IN.$output扩展名OUT$输出扩展可并行化:是
这一步需要原始状态并生产标记化阀杆。它可以与通用并行器并行。
该输出存储在文件中语料库/标记注意,实际文件名还包含语料库名称和运行编号。此外,在这种情况下,并行语料库存储在两个文件中,因此文件名可能类似语料库/欧洲.tok.1.fr和语料库/europarl.tok.1.en.
只有在以下情况下,才会执行该步骤输入转换器或输出转换器已指定。模板指示步骤的执行脚本中的命令行的外观。
多语料库,一种翻译模型
我们可以使用多个并行语料库来训练一个翻译模型,也可以用多个单语语料库训练一个语言模型。其中每一个都有自己的语料库和LM公司模块。中也可能有多个测试集测试). 然而,只有一个翻译模型,因此只有一个培训模块。
中的定义实验.元数据反映了这些模块的不同性质。例如语料库标记为倍数,同时培训被标记为单一的.
定义不同模块的设置时,单个模块培训只有一个部分,而这一个通用部分和特定部分LM公司每个训练语料库的部分。在特定部分中,语料库被命名,例如。LM:欧洲中心.
可以想象,跟踪不同类型模块的步骤之间的依赖关系以及整合特定于公司的模块实例有点复杂。但其中大部分对实验管理系统的用户来说是隐藏的。
查找步骤的参数设置时,首先是设置特定部分(LM:欧洲中心)已咨询。如果没有定义,则模块定义(LM公司)最后是一般定义(在第概述)已咨询。换句话说,本地设置会覆盖全局设置。
定义设置
实验运行的配置文件是一组参数设置,每行一个,带有空行和注释行,以提高可读性,并按每个模块的节进行组织。
设置定义的语法为设置=值(注意:等号周围有空格)。如果值包含空格,则必须将其置于引号中(setting=“值”),除非隐含值向量(仅在定义因子列表时使用:output-factor=字位置.
注释由散列表示(#).
节的开始由方括号中的节名称表示([训练]或[公司:欧洲中心]). 如果这个词IGNORE公司附加到节定义中,则忽略整个节。
设置可以用作变量来定义其他设置:
working-dir=/home/pkoehn/实验wmt10-data=$working-dir/data
变量名可以放在花括号中,以便更清楚地分隔:
wmt10-data=${工作目录}/data
此类变量引用也可能到达其他模块:
[回忆]标记化=$LM:europarl:标记化语料库
最后,可以参考配置文件中未定义的设置,但这些设置是定义的步骤序列的产物。
比如,在上面的例子中,标记化语料库未在节中定义LM:欧洲中心,但实际上生皮然后,通过正常的处理流水线生成标记化的语料库。这样的中间文件可以在其他地方使用:
[回忆]标记化=[LM:europarl:标记化语料库]
对值的有效性进行了一些错误检查。所有看似文件路径的值都会触发对此类文件的存在性检查。必须存在前缀为值的文件。
有很多设置反映了许多步骤,解释这些设置需要解释整个培训、调优和测试管道。请在此处其他地方找到步骤所需的文档。已尽一切努力在示例配置文件中包含详细描述,这应该作为起点。
使用实验。波尔
您必须在配置文件中定义一个实验,实验管理系统会找出需要运行的步骤,并将它们作为集群上的作业进行调度,或者在单个机器上连续运行。
其他选项:
-无图形:抑制图形的显示。-继续运行:继续实验RUN(运行),它早些时候坠毁了。确保已删除崩溃的步骤及其输出(请参阅下文)。-删除已擦洗的跑步记录:删除特定崩溃步骤的所有步骤文件及其输出文件RUN(运行).-删除-运行run:删除给定步骤的所有步骤文件及其输出文件RUN(运行),除非其他运行使用这些步骤。-删除版本RUN:同上。-最大有效值:指定在单个计算机上运行时可以并行运行的步骤数(默认值:2,在群集上运行时不使用)。-睡眠:设置检查任务完成之前在调度程序中等待的秒数(默认值:2)。-忽略时间:更改重复使用行为。默认情况下,当文件的时间戳更改时,无法重新使用文件(通常是一个工具,如更改了的标记器,因此需要在新的实验中重新运行所有标记化步骤)。使用此开关,可以重新使用更改了时间戳的文件。-元:允许指定自定义实验.meta文件,而不是使用与实验.perl脚本。-最后一步step:不运行完整的实验,但在指定的时间完成步骤.-最终输出out:不运行完整的实验,但当指定的输出文件OUT(输出)已创建。这些是中使用的输出文件说明符实验.元数据.-群集:表示当前计算机是群集头节点。步骤文件作为作业提交到集群。-多芯:表示当前计算机是多核计算机。这允许使用通用并行器设置进行额外的并行化。
如果在文件中指定,脚本可能会自动检测它是在计算集群还是多核机器上运行实验机器,例如:
集群:塞维利亚镇多核-8:tyr thor多核-16:loki
定义机器联排别墅和塞维利亚作为GridEngine群集计算机,提尔和雷神作为8核机器和洛基语作为16核机器。
通常,实验是通过以下命令开始的:
experiat.perl-config my-config-exec
由于实验要运行很长时间,您可能希望在后台运行它,并设置更好的优先级:
不错的nohup-config my-config-exec>&OUT。[运行]&
这还将在名为的文件中保存有关执行的报告(STDERR和STDOUT),例如,输出.1,编号与运行编号相对应。
运行的元信息存储在目录中步骤。每次运行都有一个子目录及其编号(步骤/1,步骤/2等)。子目录步骤/0包含在调用Experiment.perl时没有-执行官开关。
每次运行的子目录包含步骤定义及其元信息和输出。子目录还包含配置文件的副本(例如。步骤/1/config.1)议程图(例如。步骤/1/graph.1.{dot,ps,png}),包含所有扩展参数设置的文件(例如。步骤/1/参数.1),以及一个空文件,只要实验仍在运行,该文件每分钟都会被触摸一次(例如。步骤/1/运行。1).
持续碰撞试验
台阶可能会断裂。不,步骤会崩溃,无论是因为错误的设置、错误的工具、计算资源的问题、实验的故意中断还是天灾。
继续崩溃实验的第一件事是检测崩溃的步骤。这要么由显示的图形中的红色节点显示,要么在崩溃前最后一行的命令行中报告;尽管这可能不是很明显,但如果之后继续运行并行步骤。然而,自动错误检测并不完美,如果不进行检测,一个步骤可能会在上游失败,从而导致进一步失败。
你应该了解每个步骤的作用。然后,通过查看STDERR公司和STDOUT公司文件,以及它应该生成的输出文件,您可以跟踪出错的地方。
修复问题,并删除与失败步骤相关的所有文件(例如。,rm步数/13/TUNING_tune.13*,rm-r调整/tmp.1). 要查找崩溃的步骤产生了什么,您可能需要查看此步骤的输出放在哪里,方法是实验.元数据.
您可以使用自动删除所有崩溃的步骤及其输出文件
experiat.perl-delete-crashed 13-exec
在删除失败的步骤并确保故障原因得到解决后,您可以继续进行崩溃的实验运行(例如,运行编号13),方法是:
experist.perl-continue 13-exec
您可能希望通过排除-执行官首先命令。该图指示将从原始崩溃的运行中重新使用哪些步骤。
如果错误是参数设置,则可以在存储的配置文件中更改该设置(例如。,步骤/1/config.1). 但是,请注意删除与该设置不同的所有步骤(及其后续步骤)。
如果实验运行提前崩溃,或者您不想重复,那么删除整个步骤目录可能会更容易(rm-r步骤/13). 仅在最新的实验运行中进行此操作(例如,在已经运行14时不要进行此操作),否则可能会破坏结果的重复使用。
您还可以使用命令删除与运行关联的所有输出rm-r*/*.13*。但这需要注意,因此您可能需要先检查要删除的内容(ls*/*.13).
运行部分实验
默认情况下,experiat.perl将运行一个完整的实验:模型构建、调优和测试。您可能只想运行管道的一部分,例如构建模型,但不想进行调优和测试。您可以通过指定最终步骤或最终结果来完成此操作。
如果要在特定步骤终止
experiat.perl-config my-config-final-step步骤名称-exec
哪里步骤名称例如培训:创建配置,LM:my-corpus:列车,或调谐:调谐.
如果要在生成特定输出文件后终止:
experiat.perl-config my-config-final-out-out-exec
的示例外面的是训练:配置,LM:my-corpus:LM,或调谐:重量配置事实上,这三个示例与上面的三个示例相同,这只是指定管道终点的另一种方法。
从技术上讲,这是通过不使用报告:报告作为管道的终点,但为指定的步骤。
删除跑步记录
如果要删除与特定运行关联的所有步骤文件和输出文件,可以使用执行此操作,例如:
experist.perl-删除-运行13-exec
如果你在没有-执行官您将看到要删除的文件列表(但实际上没有删除任何文件)。
将保留其他运行中使用的步骤及其生成的输出文件。此外,步骤目录(例如。,步骤/13未删除。如果没有步骤文件,您可以手动删除。
在群集上运行
Experiment.perl适用于Sun GridEngine集群。该脚本需要在head节点上运行,作业在节点上调度。
有两种方法可以告诉testing.perl当前机器是一台集群计算机。一种是使用开关-群集,或通过将计算机名添加到实验机器.
配置文件中有一节允许设置特定于群集的设置。设置工作用于指定在调整和测试期间拆分解码的作业数。有关详细信息,请参阅摩西平行.pl.
所有其他设置都指定了通过qsub每次提交作业时传递的开关:
qsub存储器:内存插槽数(-pe存储器编号),q子小时:为每个作业保留的小时数(-l h_rt=编号:0:0),q子项目:name,如果项目用于用户记帐(-P项目)、和qsub设置:逐字传递的任何其他设置。
请注意,可以在每个模块定义中覆盖常规设置-您可能希望对不同的步骤使用不同的设置。
如果设置通用并行器已设置(通常设置为ems支持脚本$moses-script-dir/ems/support/generic-parallelizer.perl),然后将多个附加步骤并行化。例如,通过将语料库分解为指定的尽可能多的部分来执行标记化工作,处理部件的作业将并行提交到集群,完成后将其输出拼凑在一起。
请注意,配置GridEngine集群有很多不同的方法。并非这里描述的所有选项都可用,而且由于您的特定安装,它可能无法开箱即用。
在多核机器上运行
使用多核机器首先意味着可以并行安排更多的步骤。还有一个通用的并行程序(通用多核并行化器.perl)它的作用与集群的通用并行器相同。
然而,解码并没有分解成几个部分。使用更明智解码器中的多线程.
Web界面
介绍包括实验管理系统web界面的一些屏幕截图。您需要在能够访问存储工作目录的文件系统的计算机上运行一个web服务器(Linux上的LAMPP或Mac上的MAMP就是其中之一)。
复制或链接网状物目录(在脚本/ems)在web服务器上。确保web服务器用户对web界面目录具有正确的写入权限。
要将实验添加到此界面,请在文件中添加一行/您的/web/interface/dir/setup。文件的格式在文件中进行了说明。
分析
通过指定设置,可以在web界面中包含对实验运行的附加分析分析在其配置文件中。
分析=$moses-script-dir/ems/support/analysis.perl
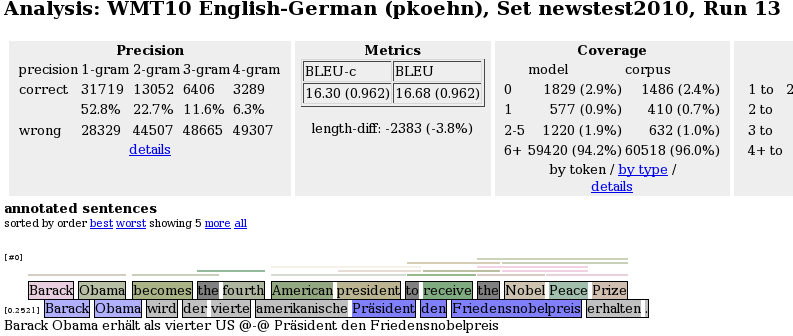
它当前报告输出语句的n-gram精度和召回统计数据以及彩色编码n-gram正确性标记,如
根据与参考翻译的n-gram匹配,输出以高亮度显示。使用以下颜色:
- 灰色:单词不在参考中,
- 浅蓝色:1克匹配的单词部分,
- 蓝色:2克匹配的单词部分,
- 深蓝色:3克匹配的单词部分,以及
- 非常深的蓝色:4克匹配的单词部分。
细分
设置分析平均值包括覆盖率分析:输入中的哪些单词和短语出现在训练数据或翻译表中?当移动单词或短语的鼠标时,这将以颜色编码和黄色报告框进行报告。此外,给出单词出现频率的汇总统计信息,并生成未知或罕见单词的报告。
覆盖率分析
设置分析平均值包括覆盖率分析:输入中的哪些单词和短语出现在训练数据或翻译表中?当移动单词或短语的鼠标时,这将以颜色编码和黄色报告框进行报告。此外,给出单词出现频率的汇总统计信息,并生成未知或罕见单词的报告。
双语协和者
为了更仔细地检查输入单词和短语在训练语料库中的出现位置,分析工具包括一个双语词库。您可以通过将此行添加到配置文件的培训部分来打开它:
biconcor=$moses-bin-dir/biconcor
在训练期间,在模型目录中构建语料库的后缀数组。分析web界面访问这些二进制文件,以快速扫描训练语料库中出现的源单词和短语。为了实现这一点,您需要在web根目录中包含biconcor二进制文件。
当你点击一个单词或短语时,网页会增加一个部分,显示该短语在语料库中的所有出现(或频繁出现的单词,所有样本),以及它是如何对齐的:
源引用(带上下文)显示在左半部,对齐的目标显示在右侧。
在主体部分中,出现的内容按不同的翻译进行分组,在上下文中也以粗体显示。未对齐的边界词显示为蓝色。提取启发式为这些情况提取了额外的规则,但为了清楚起见,这里没有列出这些规则。
最后,将显示无法提取规则的源引用。这可能是因为源单词没有与任何目标单词对齐。在这种情况下,该工具显示前一个单词(紫色)和后一个单词的对齐方式(橄榄色),以及一些相邻的未对齐单词(同样是蓝色)。提取规则失败的另一个原因是对齐错误,当源短语映射到包含与外部源单词对齐的单词的目标范围时(违反连贯约束)。这些未对齐的单词(在源和目标中)显示为红色。
王定远笔记-biconcor二进制文件应复制到web界面目录。
覆盖范围的精确度
为了进一步调查,如果输入单词的翻译正确性取决于语料库中的频率(以及单词频率的分布情况),则可以通过以下设置打开按覆盖率计算精度的报告:
report-precision-by-coverage=是精度-覆盖系数=posprecision-by-coverage-base=$working-dir/评估/测试分析。5
仅第一次设置按覆盖范围报告决策报告需要。第二次设置精确覆盖因子为特定的输入因子提供了一个额外的细分(在示例中,名为销售时点情报系统). 更多关于按覆盖率计算的精度如下所示。
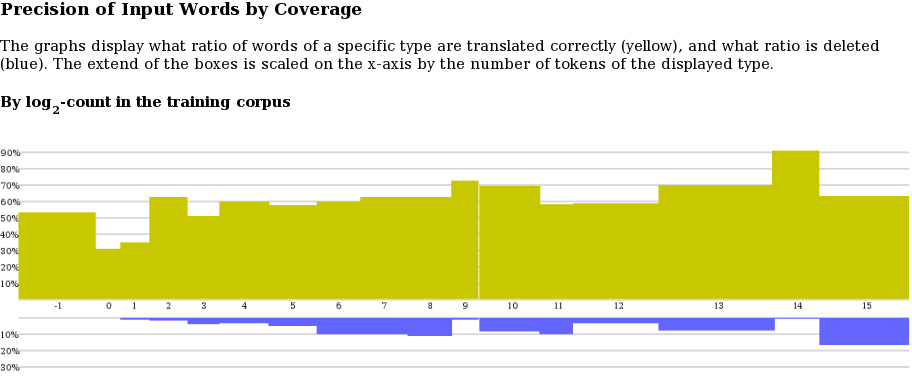
单击主页上的“按覆盖率输入的精度”时,将显示按覆盖率的精度图:
log-coverage类位于x轴上(-1表示未知,0表示单例,1个单词出现两次,2个单词出现3-4次,3个单词出现5-8次,依此类推)。每个类的方框比例由测试集中该类单词的比例决定。类中单词的翻译精度显示在y轴上。
输入词的准确度不能在明文单词中确定。我们的判断依赖于解码器的短语对齐、短语中的单词对齐,以及在输出和参考翻译中翻译单词的多次出现。这并不是说精度指标不会因掉词而受到惩罚,所以这显示在精度图下方的第二个图中(蓝色)。
如果你点击图表,你会看到表格形式的图表。下面的附加链接可以让你看到实际单词的分解,甚至可以找到它们出现的句子。
最后按覆盖范围基数计算的精度设置。为了进行比较,将覆盖率统计数据建立在前一次运行的语料库上可能会很有用。例如,如果添加训练数据,单词的翻译质量是否会提高?好吧,一个单词在小语料库中出现了3次,现在可能在大语料库里出现了10次,因此这个单词被放在了不同的类中。要将单词的原始分类保留到日志平均类中,可以使用此设置指向较早的运行。