BP algorithm
-
Main string S and sub string T, and S.length>T.length -
The physical position of the string starts from 0
-
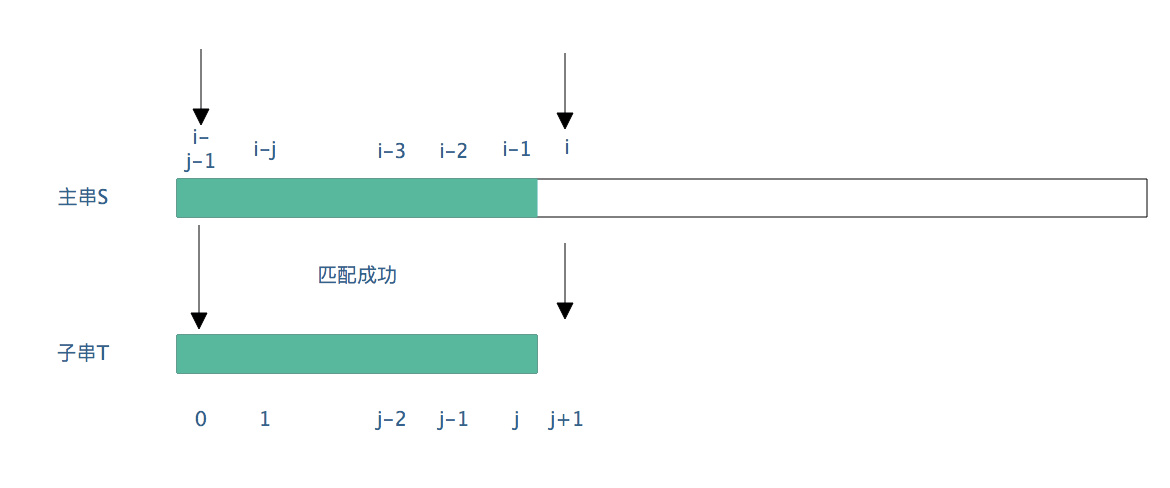
Complete matching with substring from initial position ->matching succeeded -
Failed to match the main string at the position i (the sub string position is j at this time) -> The main string matches the first character of the sub string again from the second position
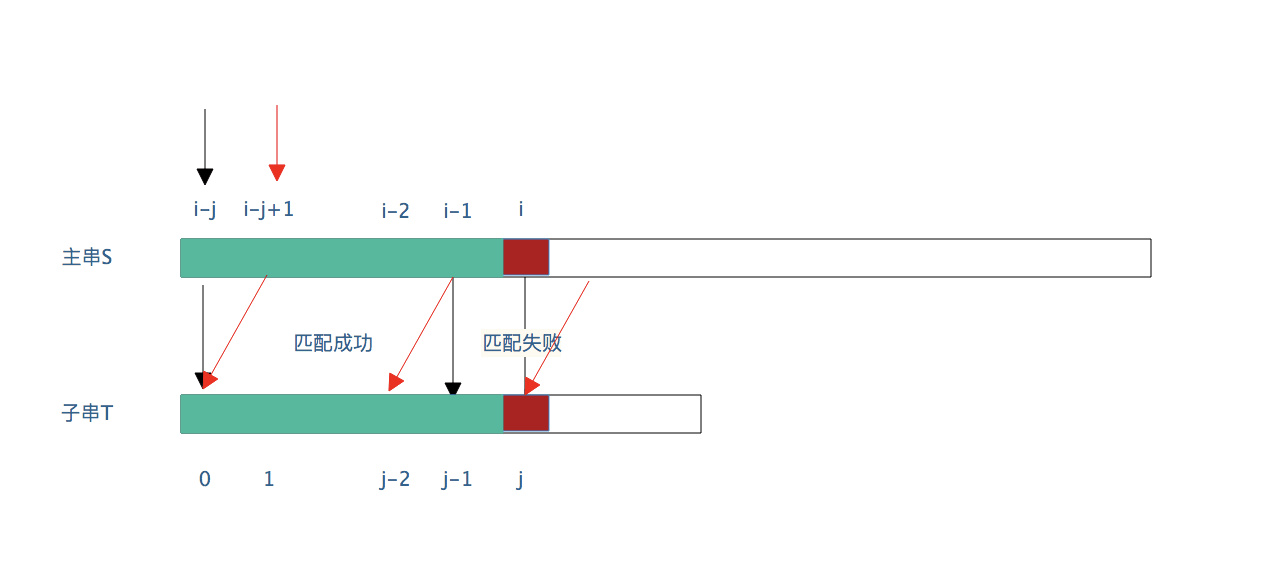
int index(String s, String t){ for (int i = 0,j=0;i<s.length && j < j.length;){ If (s [i]==t [j]) {//The current match is successful j++; i++; }Else {//The location matching failed. I need to return to the original location and add 1 to detect the matching again i = i - j + 1; j = 0; } } //After finishing the cycle, judge whether the matching is successful If (j>=t.length) {//indicates that j has accessed the entire t substring, which means that the matching is successful Return i - j - 1;//Returns the location of the first successful match }else{ return -1; } }
-
The "symmetry (similarity)" here is not general symmetry (general symmetry is that an image is symmetric about the X axis, so it folds along the X axis, and both sides can overlap). As shown in the figure below:

-
Some examples: such as substring abab , similar areas are ab 。
-
Most strings are more or less similar, If there is no "similarity", the BP algorithm still has optimization space (reduce unnecessary checks according to the non similarity of substrings, and this KMP part will be explained) -
The two similar areas of a substring cannot overlap completely and must be offset by a certain distance. For example, substring aaaa , similar areas are aaa (Similar areas are not aaaa , because it cannot overlap completely).
-
seek The length of the similar area of the "substring" in front of each character of the pattern substring. -
Use this similar area to reduce unnecessary check matching.
KMP algorithm
-
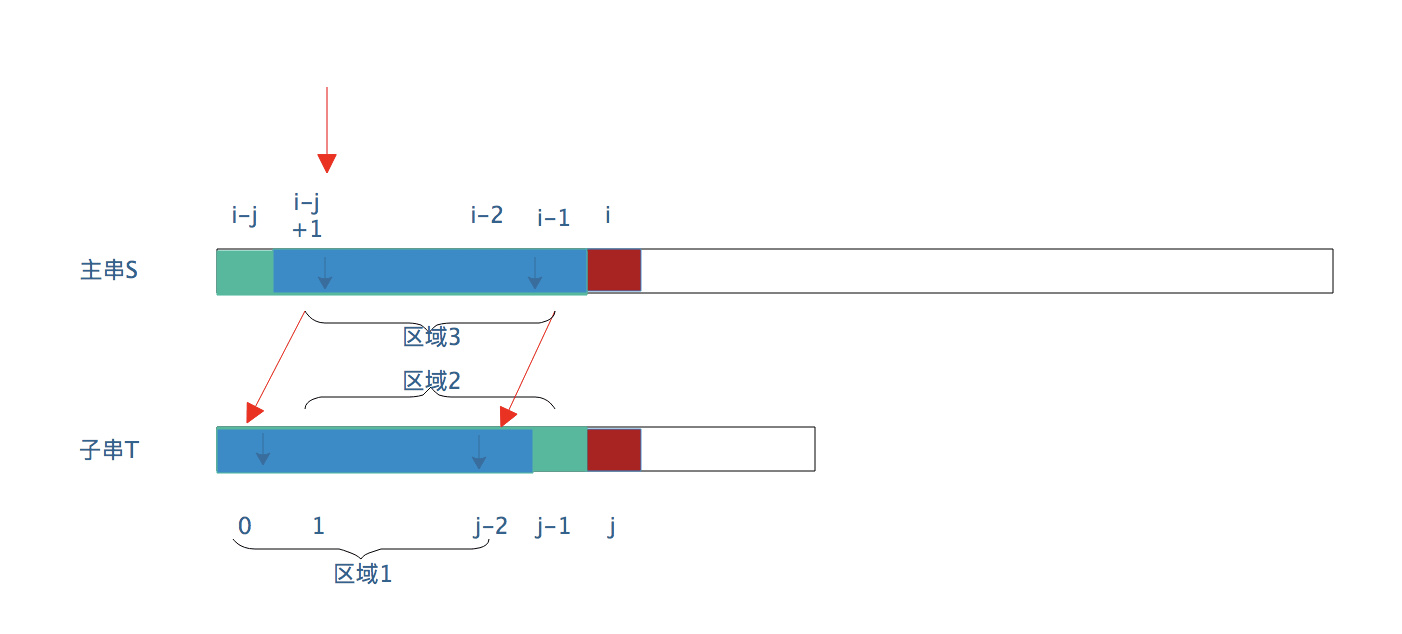
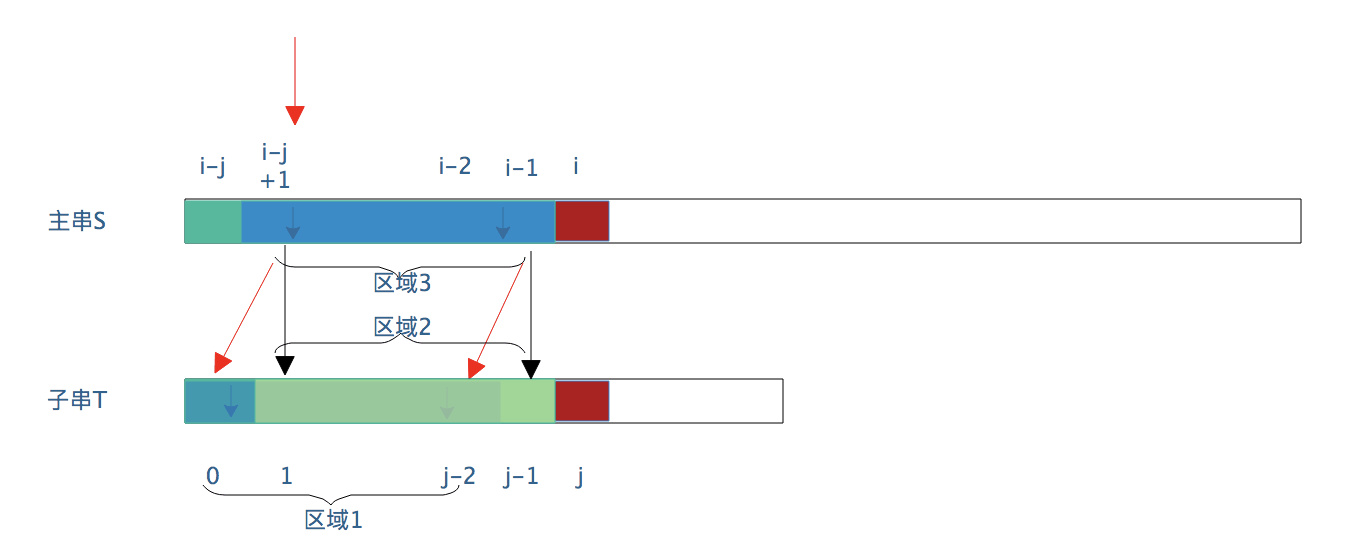
Where substring matching fails The "Kid String" in front And above Corresponding part of main string Are identical -
"Small string" has "similarity", that is, there are similar regions
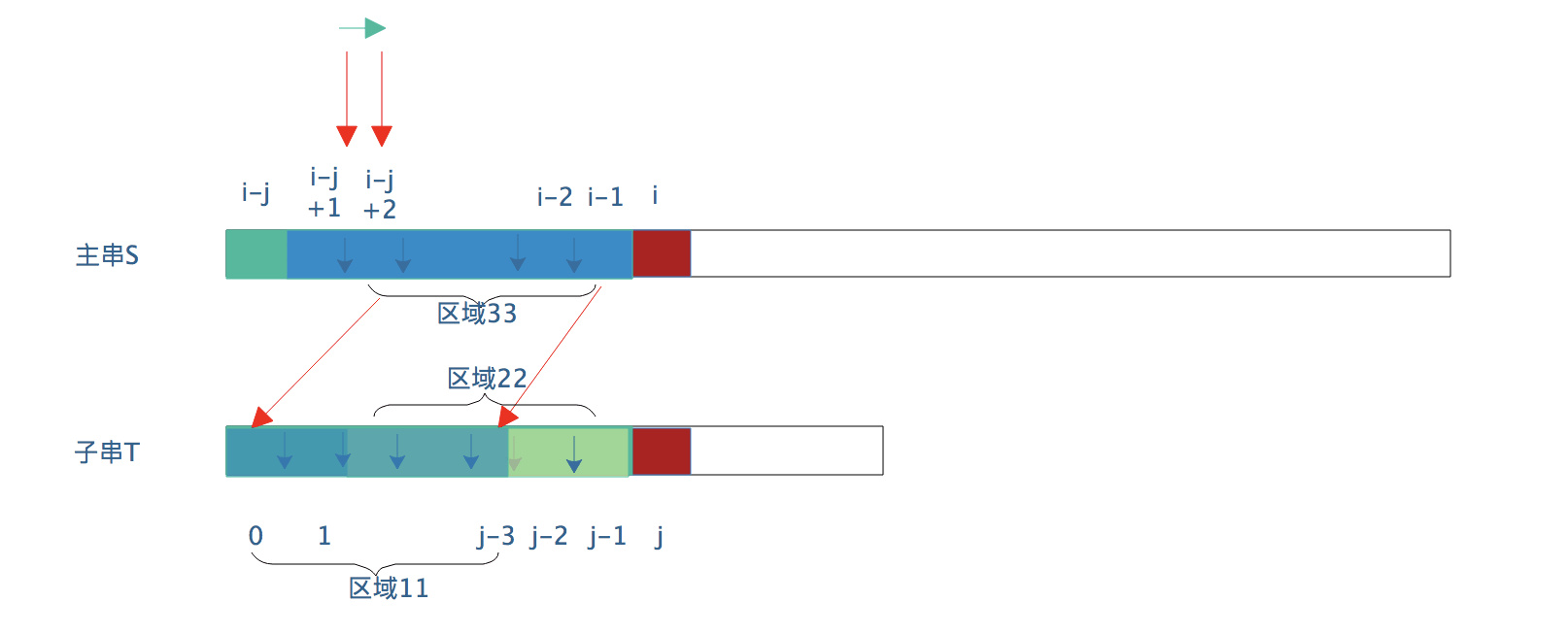
-
The i pointer of the main string does not need to return -
S [i] is directly compared with t [k], where k is the length of the similar region of the small string. The meaning of this k is that when the position matching of substring j fails, the pointer of substring j needs to move to the position of k in the next step (j=k) Then s [i] and t [k] start to detect a match.
-
Get the next array of pattern substrings -
When the matching fails, the pointer of the main string i does not need to return, and the pattern substring j moves to the next [j] position to continue the matching detection until the main string detection is completed (i>=s.length)
-
(fix the value of the first two digits) next [0]=- 1; next [1] = 0; -
Then, starting from j=2, calculate the length of the similar region of the small string in front of the position.
If (j==- 1) {//The j=next [j] has been done previously. See the following complete code for details I++;//The pointer of main string i moves forward one bit J++;//j becomes 0, that is, matching detection with t [0] }
int KMPindex(String s,String t){ //1. Find the next array of substrings int [] next = new int[MaxSize]; next[0] = -1; next[1] = 0;// Fixed value of the first two digits int k = -1; for(int j= 0; J<t.length;) {//Find the length of the similar region of the small string for each bit //It is easy to calculate the next array manually, but it is not easy to use code. The code on Li Chunbao's Data Structure is very exquisite, only using 4 lines //If you follow the code process in the textbook and find that you can get the correct results, you can't think of writing it like this //I don't want to take this part of the code for the postgraduate entrance exam. I won't go into it first, but I can do it by hand if (k == -1 || t[j] == t[k]){ j++; k++; next[j] = k; }else{ k = next[k]; } } //2. Start matching. You can see that the matching process code is basically the same as the BP algorithm, but the processing is different where the matching error occurs for (int i = 0,j=0;i<s.length && j < j.length;){ If (j==- 1 | | s [i]==t [j]) {//The current match succeeds or fails and j=(next [j]==- 1) j++; i++; }Else {//The position matching fails. I will not move, and j will move to the next [j] position to continue comparing with s [i] j = next[j]; } } //After finishing the cycle, judge whether the matching is successful If (j>=t.length) {//indicates that j has accessed the entire t substring, which means that the matching is successful Return i - j - 1;//Returns the location of the first successful match }else{ return -1; } }
//2. Start matching. You can see that the matching process code is basically the same as the BP algorithm, but the processing is different where the matching error occurs for (int i = 0,j=0;i<s.length && j < j.length;){ If (s [i]==t [j]) {//The current match is successful j++; i++; }Else {//The location matching failed, I will not move if(next[j] != - 1) {//j Move to the next [j] position to continue comparing with s [i] j = next[j]; }Else {//If next [j]==- 1, it means that the position where the matching failed is 0 of the substring, so I needs to move forward one bit, and j remains unchanged at 0 J=0;//This sentence can be removed because j must be 0 at this time i ++; } } } //After finishing the cycle, judge whether the matching is successful If (j>=t.length) {//indicates that j has accessed the entire t substring, which means that the matching is successful Return i - j - 1;//Returns the location of the first successful match }else{ return -1; }
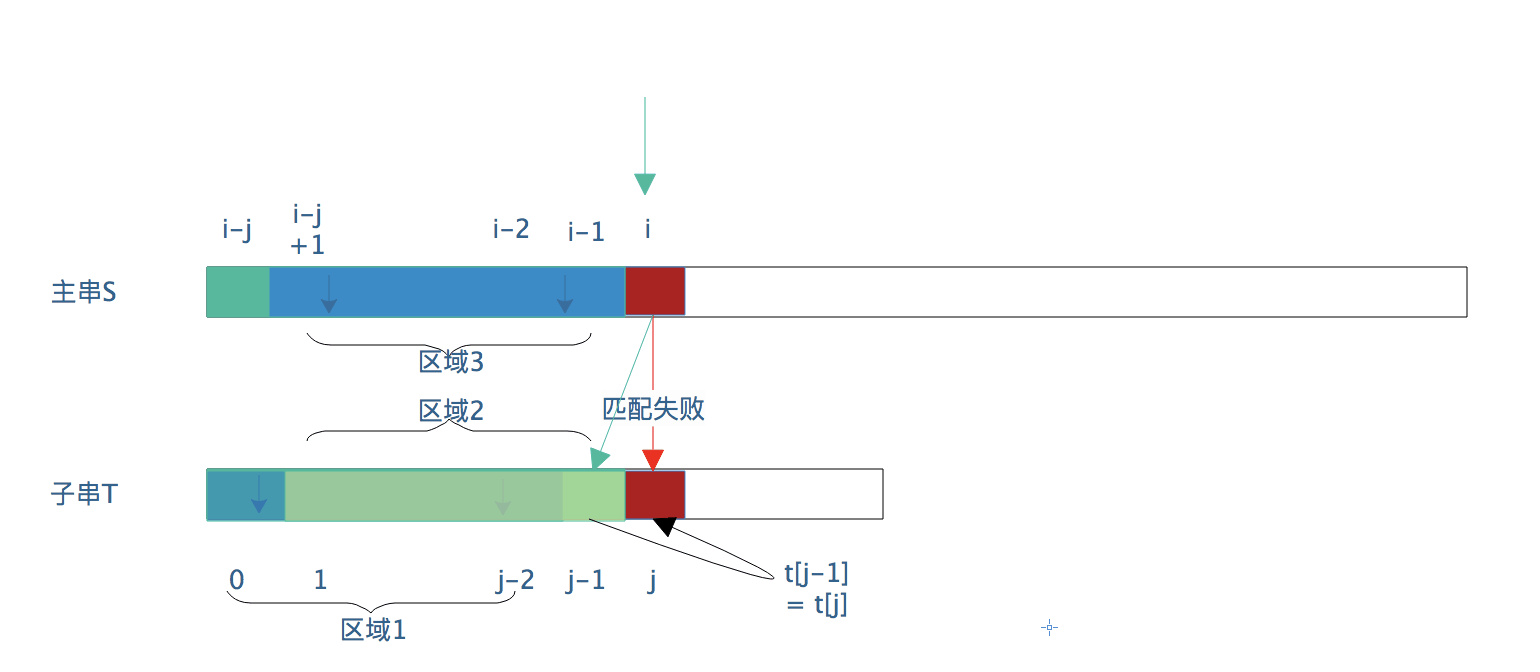
Improved KMP algorithm
-
If equal, next [j]=next [next [j]]; -
If they are not equal, the next [j] value is still the previous calculation method (the length of the similar region of the small string)
-
If equal, next [j]=nextval [next [j]];
-
If not, nextval [j]=next [j]
int KMPindex(String s,String t){ //1. Find the nextval array of substrings int [] nextval = new int[MaxSize]; nextval[0] = -1;// Fixed value of the previous digit int k = -1; for(int j= 0; J<t.length;) {//Find the length of the similar region of the small string for each bit //Same as KMP, it only requires manual calculation results, and the code has not been studied in depth } //2. Start matching. You can see that the matching process code is basically the same as the BP algorithm, but the processing is different where the matching error occurs for (int i = 0,j=0;i<s.length && j < j.length;){ If (s [i]==t [j]) {//The current match is successful j++; i++; }Else {//The location matching failed, I will not move if(next[j] != - 1) {//j Move to the position of nextval [j] to continue comparing with s [i] j = nextval[j]; }Else {//If nextval [j]==- 1, it means that j will eventually move to position 0, and t [j]==t [0], so J=0;//This sentence must not be removed!! Because not only 0 position nextval [0]=- 1, but also other positions may be equal to - 1 i ++; } } } //After finishing the cycle, judge whether the matching is successful If (j>=t.length) {//indicates that j has accessed the entire t substring, which means that the matching is successful Return i - j - 1;//Returns the location of the first successful match }else{ return -1; } } last
-
The code is manually typed in the editor, and has not been run by the code. It is likely that there is an error in the operation, and it is only used to show the algorithm ideas -
It can be seen that the KMP (and improved) algorithm is essentially dealing with the problem of how to move the j of the substring when the position matching of the substring j fails. So the meaning of the next (nextval) array is that if the position matching fails, where should the current position be moved -
KMP algorithm and BP algorithm are completely consistent in the process of successful matching -
Understand that there may be mistakes, please correct them












