EMR Serverless Spark

-
Hot commodity -
Content selection

EMR Serverless Spark
Cloud native fast computing engine
Flexible resource management
DATA and AI
Ecological compatibility

SQL Editor
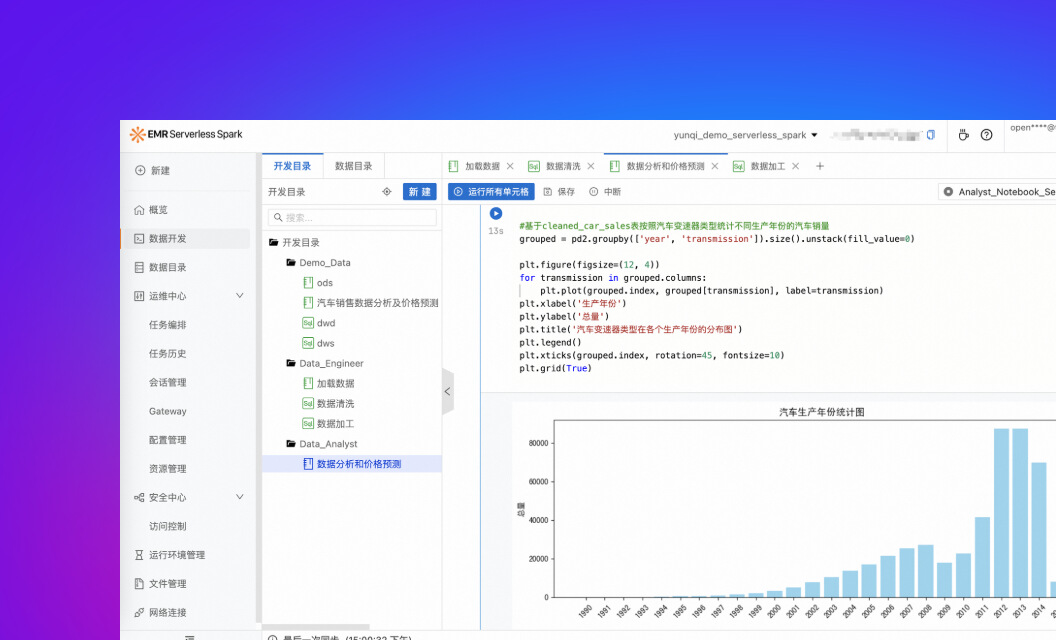
Notebook

Workflow
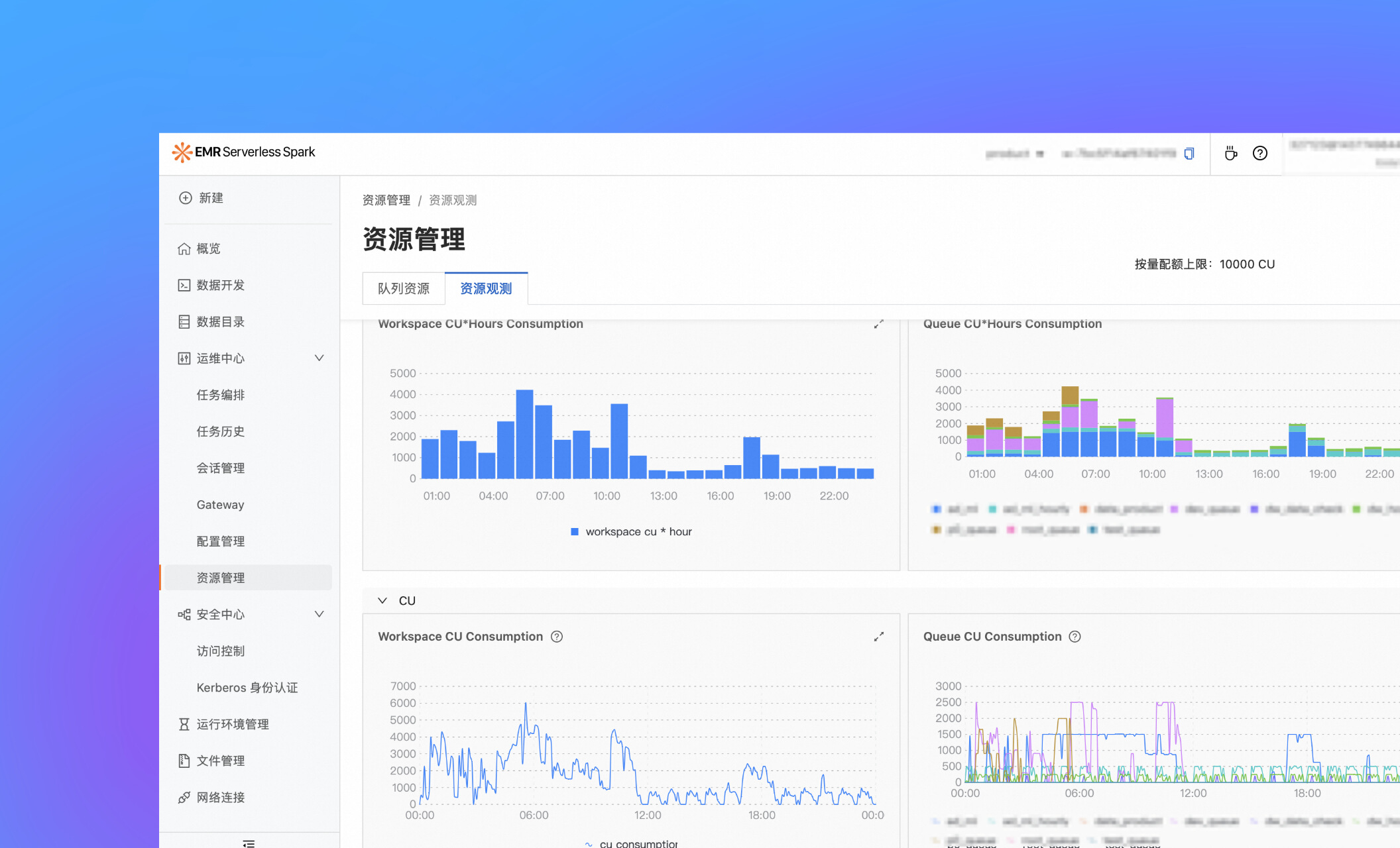
resource management

Custom Environment
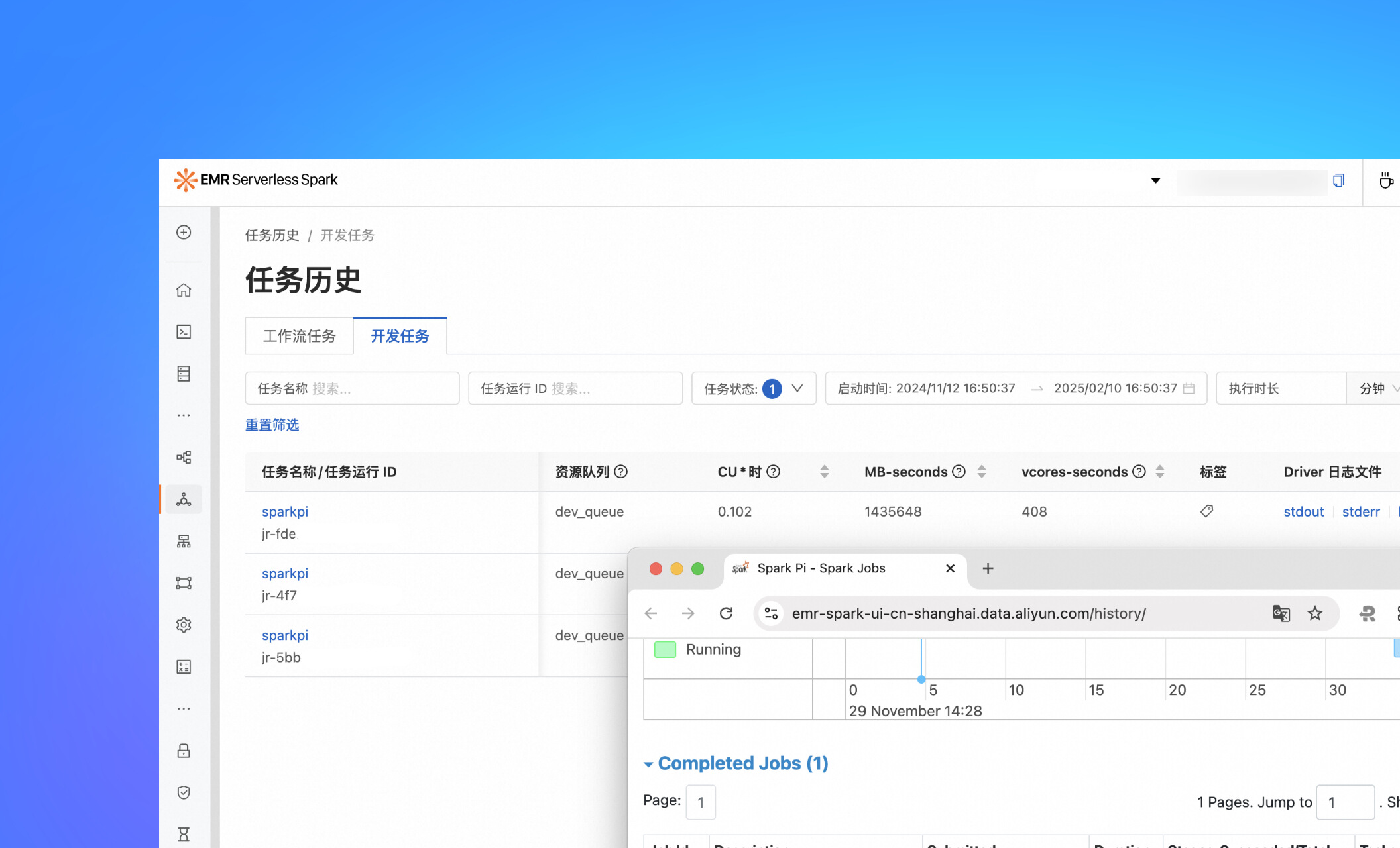
Task History
Quickly create a workspace on the EMR Serverless Spark page



Billing method
Monthly package (prepayment) Monthly subscription is a prepaid billing method. When purchasing, you need to pay in advance according to the selected duration. EMR Serverless Spark will strictly calculate the price of the billing cycle according to the duration you purchased. It is applicable to scenarios with long-term stable use or clear budget planning. View details Resource deduction package Preferential resource packages with different capacities are purchased in advance, and the consumption is deducted from the resource package in priority when the cost is settled. The part exceeding the limit of resource package shall be paid as you go. It is applicable to scenarios where business usage is relatively stable. View details






-
Product selection -
Product billing -
Product use
-
Q: What is the EMR Serverless Spark version? What are the advantages of the product? -
A: EMR Serverless Spark is a cloud native, fully hosted serverless product designed for large-scale data processing and analysis. It provides enterprises with one-stop data platform services, including task development, debugging, scheduling, operation and maintenance, which greatly simplifies data ..... View details
-
Q: What are the application scenarios of EMR Serverless Spark? -
A: EMR Serverless Spark can meet various data processing and analysis needs of enterprise level users, such as establishing data platforms, data query and analysis scenarios, etc. View details
-
Q: What is Fusion? -
A: The Fusion engine is a high-performance vectorized SQL execution engine built into EMR Serverless Spark. Compared with the open source Spark, the performance of the Fusion engine in the TPC-DS benchmark is three times higher. The Fusion engine is fully compatible with the open source Spark, and you don't need to make any changes to the existing code. View details
-
Q: What billing modes and items does the product support? -
A: This article introduces the resource estimation policy, billing items, calculation methods, and the unit price of the supported regions of EMR Serverless Spark. View details
-
Q: How to use Paimon in EMR Serverless Spark? -
A: This article introduces how to implement the read and write operations of Paimon tables in EMR Serverless Spark. View details
-
Q: How to connect external Hive Metastore in EMR Serverless Spark? -
A: EMR Serverless Spark supports the connection of external Hive Metastore services, so you can easily access the data stored in Hive Metastore. This article describes how to configure and connect external Hive Metastore services in EMR Serverless Spark, so that ..... View details
-
Q: How to submit tasks to EMR Serverless Spark through Airflow? -
A: This article shows you how to automatically submit tasks to EMR Serverless Spark through Apache Airflow to automate job scheduling and execution and help you manage data processing tasks more effectively. View details
-
Q: How to submit tasks to EMR Serverless Spark through DolphinScheduler? -
A: DolphinScheduler is a distributed and easy to expand visual DAG workflow task scheduling open source system, which can efficiently execute and manage big data processes. This article shows you how to easily create, edit, and schedule Spark jobs through the DolphinScheduler Web interface. View details
-
Q: How to interact with EMR Serverless Spark through Jupyter Notebook? -
A: Jupyter Notebook is a powerful interactive development tool. You can write and execute code in real time in the Web interface, and view the results in real time without precompiling or executing scripts separately. This article will introduce you how to build an efficient communication with Serverless Spark ..... View details
Experience now and create the future in Alibaba Cloud