Building a data warehouse integrating lake and warehouse
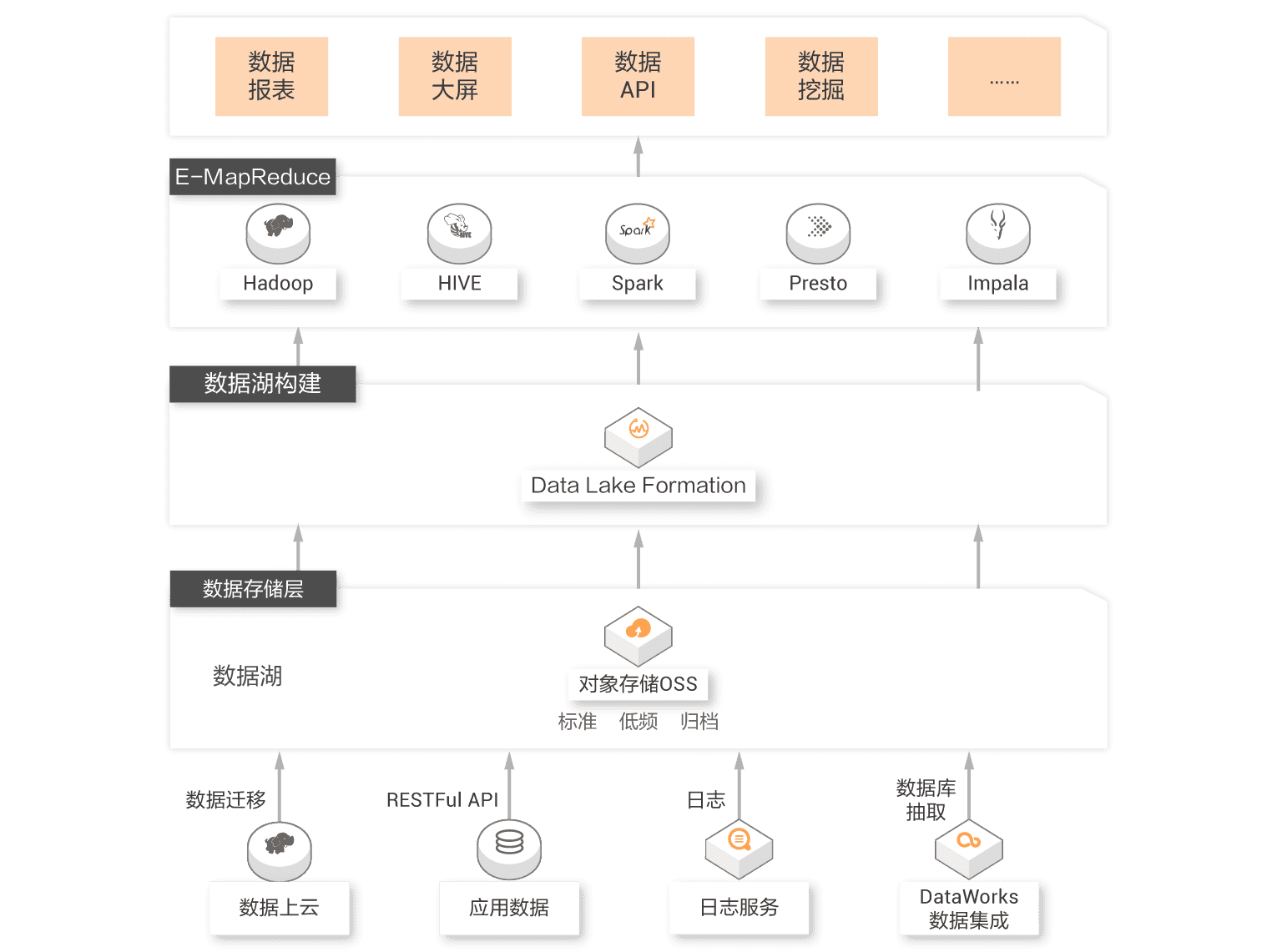
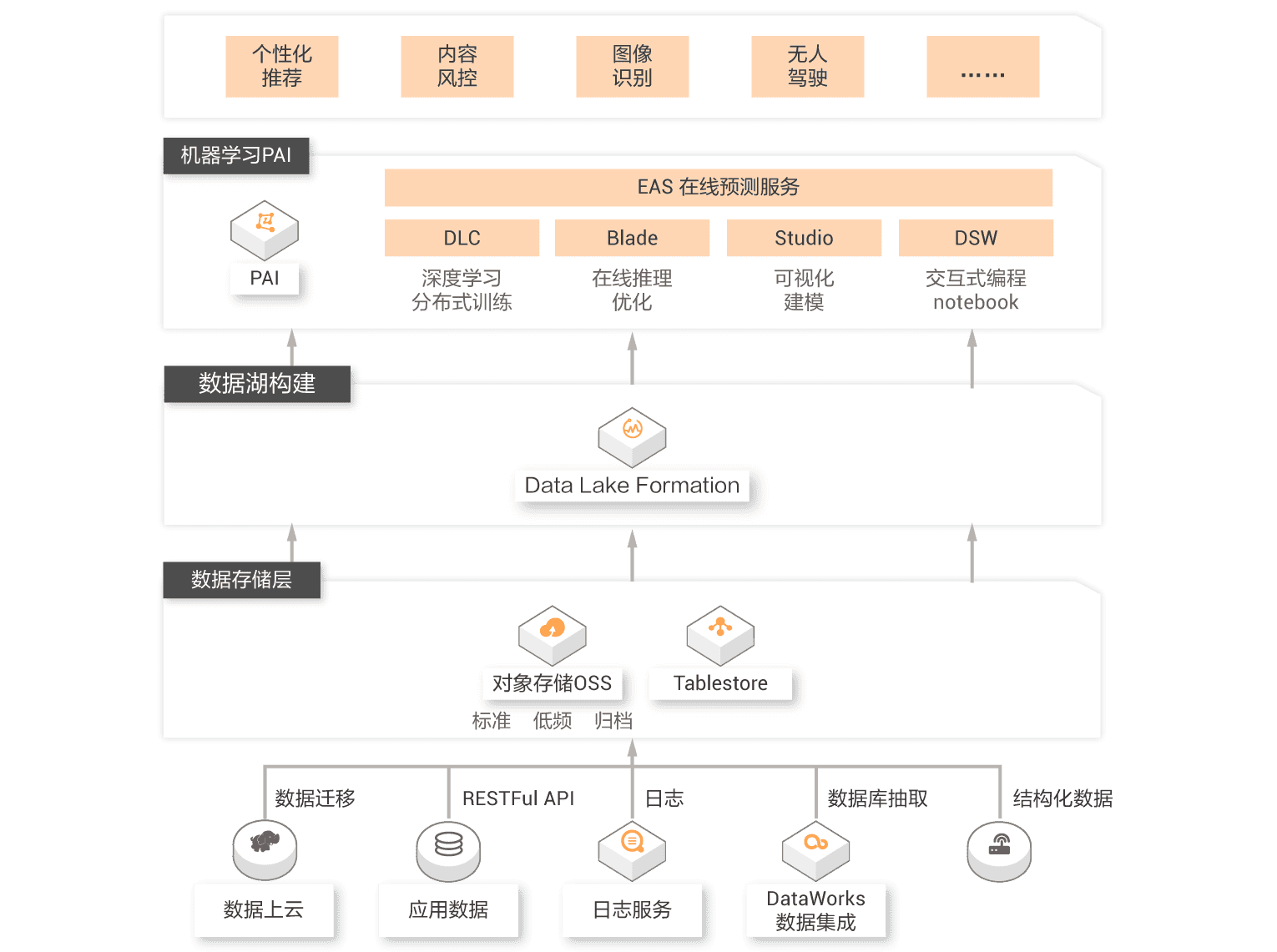
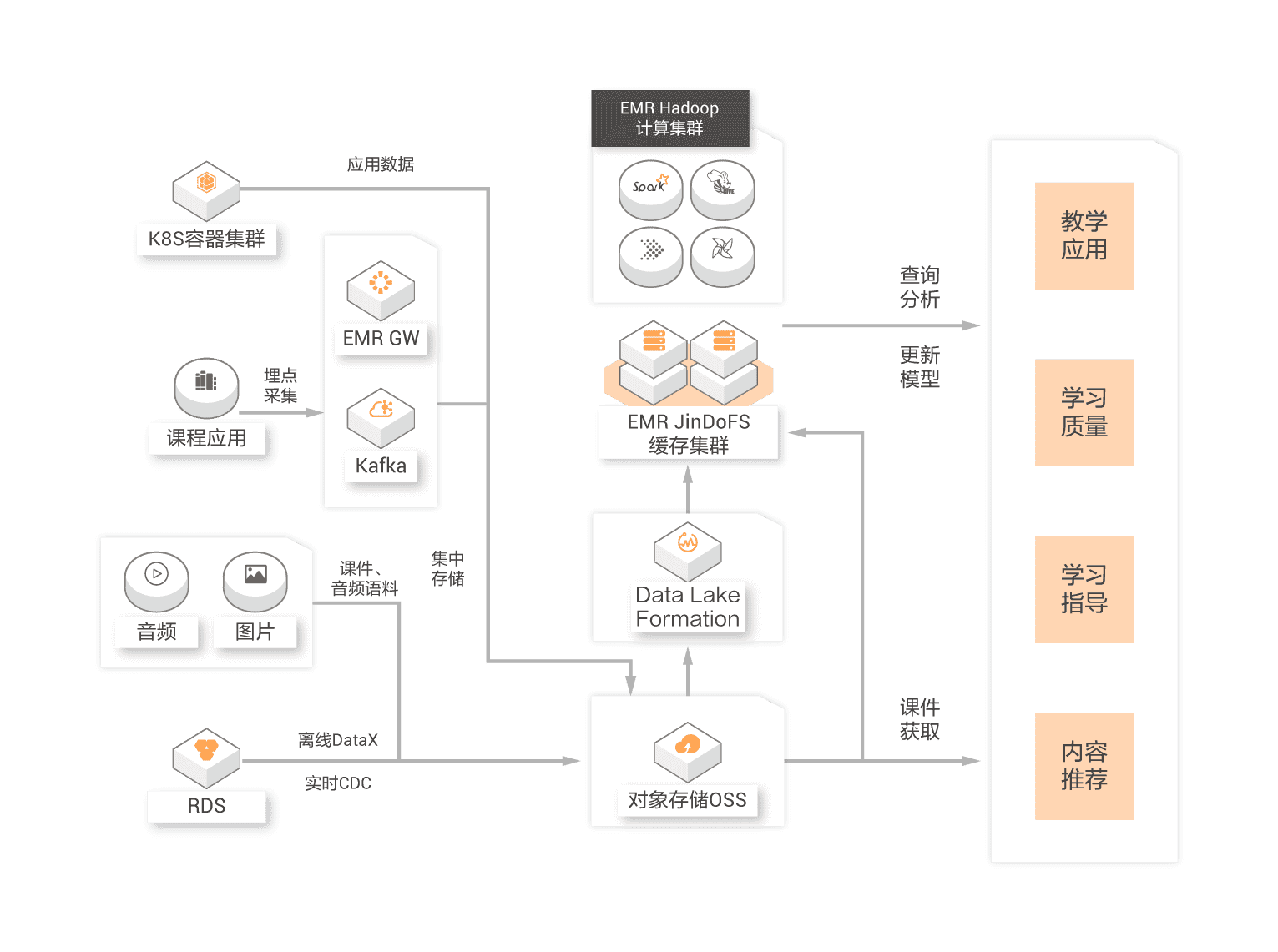
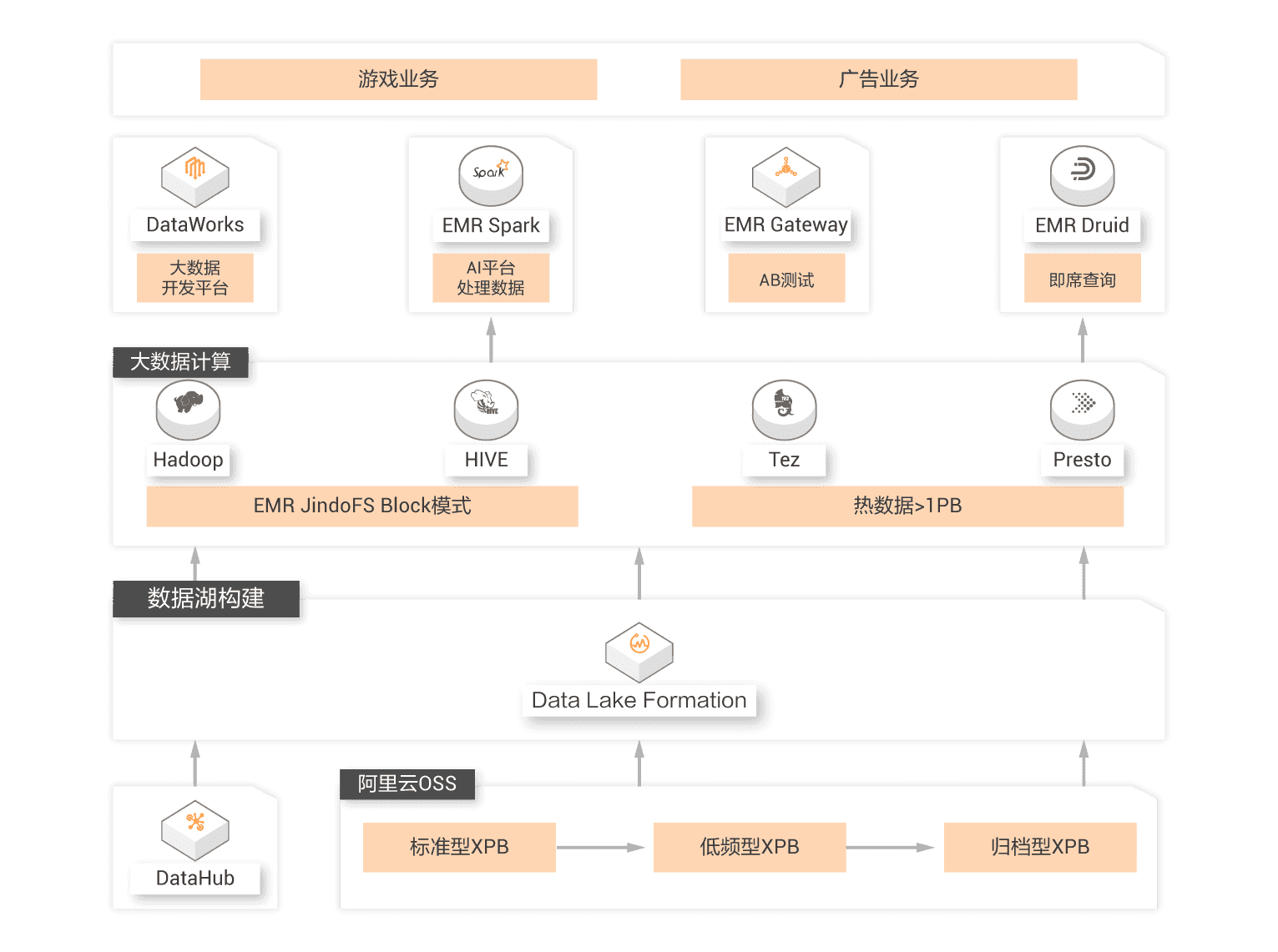
Data warehouse and data lake are two design orientations of big data architecture. The priority design of data lake brings maximum flexibility to data entering the lake by opening the underlying file storage. The priority design of data warehouse focuses more on the growth requirements of enterprise level such as data usage efficiency, data management under large-scale, security/compliance. Flexibility and growth are of different importance to enterprises in different periods. With the gradual clarity and precipitation of users' business, users are faced with the integration of data lake and data warehouse architecture. Relying on Alibaba Cloud data warehouse (MaxCompute, Hologres, ADB and other products) and data lake, they build products to help users build a data system integrating lake and warehouse, so that data and computing can flow freely between lake and warehouse, So as to build a complete and organic big data technology ecosystem.
Programme value
Operation and maintenance free
The data lake construction product provides users with full hosting services. It can help users quickly build the data lake system on the cloud with a simple click
Safety is guaranteed
Unified authority management system can control the authority of database, table and column.