

Handwritten Java HashMap core source code
HashMap Usage Analysis
//1 deposit HashMap<String,String> map = new HashMap<>(); map.put("name","tom"); //2 out System.out.println(map.get("name"));// Output tom
Analysis of HashMap Principle
-
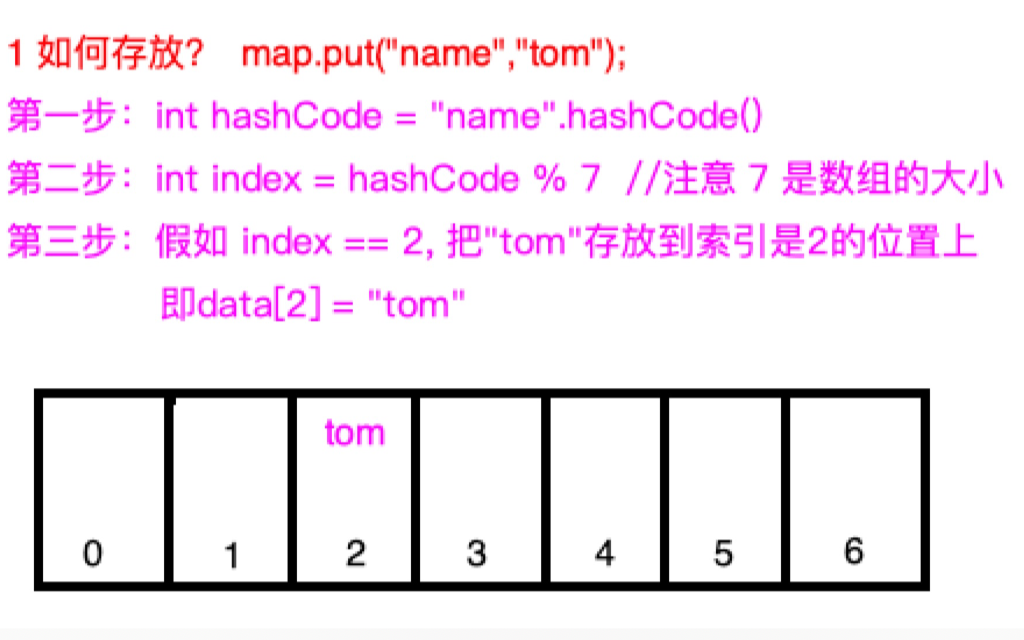
The size of the array is 7, and the index range of the array is [0, 6] -
Get the hashCode of the key, that is, "name". This is a number. No matter how many this number is, if 7 is remaindered, the range must be [0, 6], which is exactly the same as the index of the array. -
If the value of "name". hashCode()% 7 is 2, then the value, that is, the location where "tom" should be stored, is 2 -
Data [2]="tom", stored in the array. Is it very clever.
-
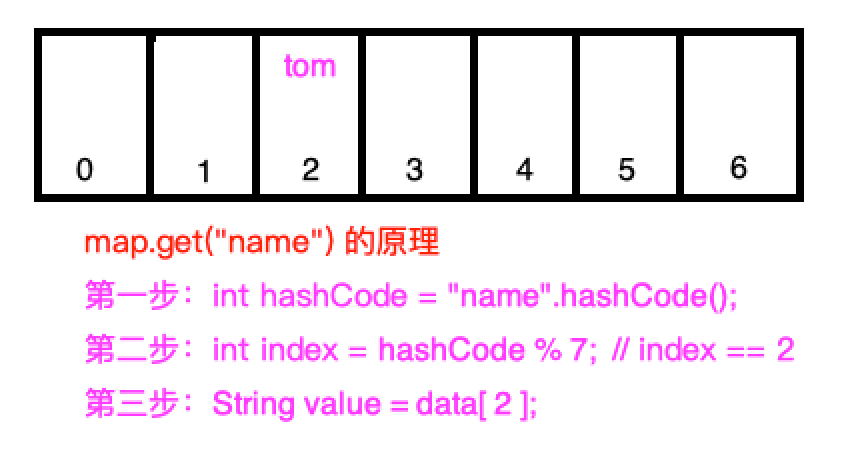
First, obtain the hashCode value of the key, that is, "name" -
Use the hashCode value to fetch the remainder of the size 7 of the array, which is the same as running when saving, and must also be 2 -
Take the value from the second position of the array, that is, String value=data [2]
-
The value returned by the hashCode () method of an object is the same when called at any time -
Take the remainder of a number n, the range is [0, n - 1]
-
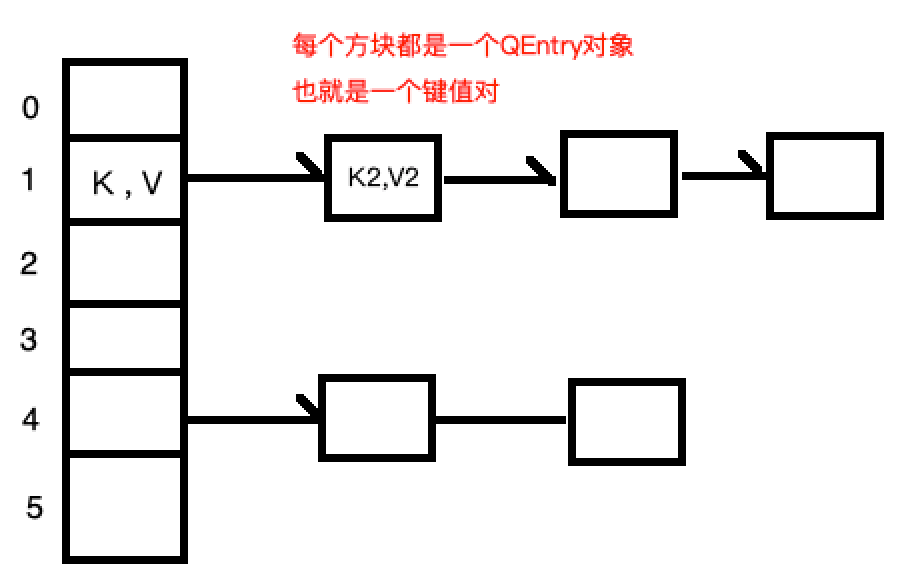
When saving, what if the hashCodes of different keys take the remainder of the array exactly the same, that is, they are all mapped to the same position in the array? This is the hash conflict problem, such as 9 % 7 == 2 , 16 % 7 == 2 Both are equal to 2 Answer: The data structure stored in the array is a node, and the node has the next attribute. If the hash conflicts, the single linked list will be stored. The same is true when fetching, and the linked list will be traversed -
What if the array is full? Answer: Same as ArrayList, expand capacity and remap -
Directly use the hashCode() value for mapping, and the probability of hash conflict is very large. What should I do? Answer: referring to the implementation in HashMap in JDK, there is a hash() function, and then run the value of hashCode() and map it
Handwritten HashMap core source code
//Element classes stored in the underlying array public static class QEntry<K, V> { K key;//Store the key V value;//Store value Int hash;//The hash value corresponding to the key //When the hash conflicts, that is, there is already an element in the mapping location //Then the newly added element is used as the chain header, and the stored element is placed at the back //That is, it is saved in next. One sentence: when adding new elements, add them in the header QEntry<K, V> next; public QEntry(K key, V value, int hash, QEntry<K, V> next) { this.key = key; this.value = value; this.hash = hash; this.next = next; } }
public class QHashMap<K, V> { //The size of the default array private static final int DEFAULT_INITIAL_CAPACITY = 16; //The default expansion factor. When there are more elements in the data, hash conflicts are also easy to occur //Therefore, you need to expand the capacity before the array is used up //0.75 means that when the number of elements reaches 75% of the array size, the capacity will be expanded //For example, the size of the array is 100. When the number of elements in the array increases to 75, it will start to expand private static final float DEFAULT_LOAD_FACTOR = 0.75f; //Array for storing elements private QEntry[] table; //Number of elements in the array private int size; ...... }
public QHashMap() { //Create an array with the default size of 16 table = new QEntry[DEFAULT_INITIAL_CAPACITY]; //At this time, the number of elements is 0 size = 0; }
/** *1. The parameter key and value are easy to understand *2 Return V, we know that HashMap has one feature, *If map.put ("name", "tom") is called multiple times; map.put("name","lilei"); *The following values will overwrite the previous ones. If this happens, the old value will be returned, and "tom" will be returned here */ public V put(K key, V value) { //1. For simplicity, key does not support null if (key == null) { throw new RuntimeException("key is null"); } //Instead of using key. hashCode() directly, we perform another operation on key. hashCode() as the hash value //I copied the hash () method directly from the HashMap source code. Do not care about the hash() algorithm itself //Just know that hash () inputs a number and returns a number. int hash = hash(key.hashCode()); //Use the hash value of the key and the size of the array to make a mapping to get the location that should be stored int index = indexFor(hash, table.length); //Check whether the key of an existing element in the array is equal to the key in the parameter //If equal, replace the old value with a new one, and then return the old value QEntry<K, V> e = table[index]; while (e != null) { //First compare whether hashes are equal, then compare whether objects are equal, or compare equals methods //If they are equal, it means that there is the same key. At this time, the old value should be updated to the new value, and the old value should be returned if (e.hash == hash && (key == e.key || key.equals(e.key))) { V oldValue = e.value; e.value = value; return oldValue; } e = e.next; } //If the key without element in the array is equal to the passed key //Save the elements in the current position QEntry<K, V> next = table[index]; //Next may or may not be null, regardless of whether it is null //Next should be the next node of the new element (next is passed to the constructor of QEntry) //Then the new element is saved in the index location table[index] = new QEntry<>(key, value, hash, next); //If you need to expand, the number of elements is greater than table. length * 0.75 (don't ask why it is 0.75, experience) if (size++ >= (table.length * DEFAULT_LOAD_FACTOR)) { resize(); } return null; }
//The HashCode is calculated, and the implementation of HashMap in JDK is directly copied static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } //Find where the key falls in the array according to h static int indexFor(int h, int length) { //Or return h&(length-1) has better performance //Here we take the remainder of length in the easiest way to understand. The range is [0, length - 1] //Exactly the range of all indexes of the table array H=h>0? H: - h;//Prevent negative numbers return h % length; }
//Capacity expansion, the number of elements is greater than table. length * 0.75 //Expand the array to twice the original size private void resize() { //Create a new array whose size is twice the size of the original array int newCapacity = table.length * 2; QEntry[] newTable = new QEntry[newCapacity]; QEntry[] src = table; //Traverse the old array and remap it to the new array for (int j = 0; j < src.length; j++) { //Get old array elements QEntry<K, V> e = src[j]; //Release old array src[j] = null; //Because e is a linked list, there may be multiple nodes, which are mapped by looping through while (e != null) { //Save the next node of e QEntry<K, V> next = e.next; //E The current node is mapped in a new array int i = indexFor(e.hash, newCapacity); //The newTable [i] position may or may not be null //Whether it is null or not, it will be the next node of the e node e.next = newTable[i]; //Save e in the location of i of the new array newTable[i] = e; //Continue the same processing of the next node of e e = next; } } //All nodes are mapped to the new array. Don't forget to assign the new array to table table = newTable; }
//Get the value according to the key public V get(K key) { //Also for simplicity, key does not support null if (key == null) { throw new RuntimeException("key is null"); } //Hash the key int hash = hash(key.hashCode()); //Map with hash value to get the data at which position in the array int index = indexFor(hash, table.length); //Save the element at index for traversal //Because e is a linked list, we need to traverse the linked list //Find the QEntry equal to the key and return the value QEntry<K, V> e = table[index]; while (e != null) { //Compare whether hash values are equal if (hash == e.hash && (key == e.key || key.equals(e.key))) { return e.value; } //If not, continue to find the next e = e.next; } return null; }
public class QHashMap<K, V> { //The size of the default array private static final int DEFAULT_INITIAL_CAPACITY = 16; //The default expansion factor. When the size of the array is greater than or equal to the current capacity * 0.75, it starts to expand private static final float DEFAULT_LOAD_FACTOR = 0.75f; //The underlying layer uses an array to store data private QEntry[] table; //Array size private int size; //A dot node, the unit stored in the array public static class QEntry<K, V> { K key; V value; int hash; QEntry<K, V> next; public QEntry(K key, V value, int hash, QEntry<K, V> next) { this.key = key; this.value = value; this.hash = hash; this.next = next; } } public QHashMap() { table = new QEntry[DEFAULT_INITIAL_CAPACITY]; size = 0; } //Get the value according to the key public V get(K key) { //Also for simplicity, key does not support null if (key == null) { throw new RuntimeException("key is null"); } //Hash the key int hash = hash(key.hashCode()); //Map with hash value to get the data at which position in the array int index = indexFor(hash, table.length); //Save the element at index for traversal //Because e is a linked list, we need to traverse the linked list //Find the QEntry equal to the key and return the value QEntry<K, V> e = table[index]; while (e != null) { //Compare whether hash values are equal if (hash == e.hash && (key == e.key || key.equals(e.key))) { return e.value; } //If not, continue to find the next e = e.next; } return null; } /** *1. The parameter key and value are easy to understand *2 Return V, we know that HashMap has one feature, *If map.put ("name", "tom") is called multiple times; map.put("name","lilei"); *The following values will overwrite the previous ones. If this happens, the old value will be returned, and "tom" will be returned here */ public V put(K key, V value) { //1. For simplicity, key does not support null if (key == null) { throw new RuntimeException("key is null"); } //Instead of using key. hashCode() directly, we perform another operation on key. hashCode() as the hash value //I copied the hash () method directly from the HashMap source code. Do not care about the hash() algorithm itself //Just know that hash () inputs a number and returns a number. int hash = hash(key.hashCode()); //Use the hash value of the key and the size of the array to make a mapping to get the location that should be stored int index = indexFor(hash, table.length); //Check whether the key of an existing element in the array is equal to the key in the parameter //If equal, replace the old value with a new one, and then return the old value QEntry<K, V> e = table[index]; while (e != null) { //First compare whether hashes are equal, then compare whether objects are equal, or compare equals methods //If they are equal, it means that there is the same key. At this time, the old value should be updated to the new value, and the old value should be returned if (e.hash == hash && (key == e.key || key.equals(e.key))) { V oldValue = e.value; e.value = value; return oldValue; } e = e.next; } //If the key without element in the array is equal to the passed key //Save the elements in the current position QEntry<K, V> next = table[index]; //Next may or may not be null, regardless of whether it is null //Next should be the next node of the new element (next is passed to the constructor of QEntry) //Then the new element is saved in the index location table[index] = new QEntry<>(key, value, hash, next); //If you need to expand, the number of elements is greater than table. length * 0.75 (don't ask why it is 0.75, experience) if (size++ >= (table.length * DEFAULT_LOAD_FACTOR)) { resize(); } return null; } //Capacity expansion, the number of elements is greater than table. length * 0.75 //Expand the array to twice the original size private void resize() { //Create a new array whose size is twice the size of the original array int newCapacity = table.length * 2; QEntry[] newTable = new QEntry[newCapacity]; QEntry[] src = table; //Traverse the old array and remap it to the new array for (int j = 0; j < src.length; j++) { //Get old array elements QEntry<K, V> e = src[j]; //Release old array src[j] = null; //Because e is a linked list, there may be multiple nodes, which are mapped by looping through while (e != null) { //Save the next node of e QEntry<K, V> next = e.next; //E The current node is mapped in a new array int i = indexFor(e.hash, newCapacity); //The newTable [i] position may or may not be null //Whether it is null or not, it will be the next node of the e node e.next = newTable[i]; //Save e in the location of i of the new array newTable[i] = e; //Continue the same processing of the next node of e e = next; } } //All nodes are mapped to the new array. Don't forget to assign the new array to table table = newTable; } //The HashCode is calculated, and the implementation of HashMap in JDK is directly copied static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } //Find where the key falls in the array according to h static int indexFor(int h, int length) { //Or return h&(length-1) has better performance //Here we take the remainder of length in the easiest way to understand. The range is [0, length - 1] //Exactly the range of all indexes of the table array H=h>0? H: - h;//Prevent negative numbers return h % length; } }
public static void main(String[] args) { QHashMap<String, String> map = new QHashMap<>(); map.put("name", "tom"); map.put("age", "23"); map.put("address", "beijing"); String oldValue = map.put("address", "shanghai"); // The key returns the old value and saves the new value System.out.println(map.get("name")); System.out.println(map.get("age")); System. out. println ("old value="+oldValue); System. out. println ("new value="+map. get ("address")); }
tom twenty-three Old value=beijing New value=shanghai




























































