Special topic: OpenAI releases the latest flagship model GPT-4o, which is full of free voice function
Source: Hard AI
Although it has not brought the highly anticipated AI search engine, OpenAI has devoted more attention to the AI model of its main product, expanding multimodal functions, so that users can play with text, pictures and voice input for free.
On Monday, May 13, US Eastern Time, Mira Murati, the chief technology officer of OpenAI, announced in the live demonstration that she would launch a new OpenAI flagship AI model, called GPT-4o, which she said was open to all people, including free users, and would "bring GPT-4 intelligence to our free users". OpenAI also introduced the desktop version of ChatGPT and a new user interface (UI).
Murati said, "This is the first time that we have really taken a big step in terms of ease of use." She commented that GPT-4o is "much faster", improving GPT-4's functions in text, video and audio. "GPT-4o infers through voice, text and vision".
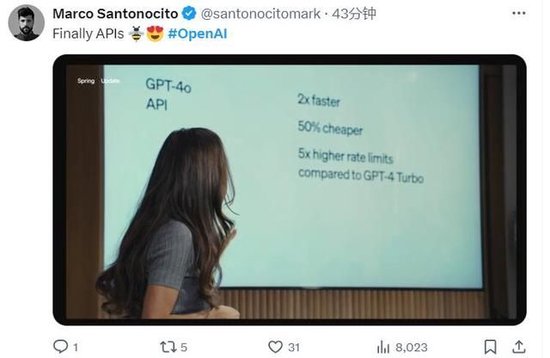
Murati said in the demonstration that GPT-4o is twice as fast as GPT-4 Turbo, its cost is reduced by 50%, and the API rate limit, that is, the number of requests that users can send, is increased by five times. Some netizens are happy about this on social media X, saying that the API has finally improved.
Real time equation solving, interpretation, chart analysis, reading user emotions
GPT-4 has already been able to analyze images and texts, complete tasks such as extracting text from images and describing image content in text. GPT-4o adds voice function. Murati emphasized the necessary security of GPT-4o in terms of real-time voice and audio functions, saying that OpenAI will continue to deploy iterations to bring all functions.
In the demonstration, Mark Chen, the research director of OpenAI, took out his mobile phone to open ChatGPT, made a live demonstration in Voice Mode, and asked for advice from ChatGPT supported by GPT-4o. GPT sounds like an American woman. When it hears Chen's excessive exhalation, it seems to sense his nervousness. Then say "Mark, you are not a vacuum cleaner" and tell Chen to relax and breathe. If there are some major changes, users can interrupt the GPT. The delay of GPT-4o should not exceed two or three seconds.
In another demonstration, Barret Zoph, the post training team leader of OpenAI, wrote an equation 3x+1=4 on the whiteboard. ChatGPT prompted him to guide him to complete each step of the solution, identify his writing results, and help him solve the value of X. In this process, GPT acts as a real-time math teacher. GPT can recognize mathematical symbols, even a heart shape.
At the request of social media X users, Murati spoke Italian to ChatGPT on the spot. GPT translated her words into English and told Zoph and Chen. After listening to Murati's Italian speech, GPT translated it into English and told Chen: "Mark, she wants to know whether whales can speak, and what will they tell us?"
OpenAI said that GPT-4o can also detect people's emotions. In the demonstration, Zoph held the phone in front of him, facing his face, and asked ChatGPT to tell him what he looked like. Initially, GPT referred to a photo he shared earlier and identified him as a "wooden surface". After a second attempt, GPT gave a better answer.
GPT noticed the smile on Zoph's face and said to him, "It seems that you feel very happy and happy."
It is commented that this demonstration shows that ChatGPT can read human emotions, but it is still a little difficult to read.
OpenAI executives said that GPT-4o can interact with the code base, and showed that it can draw some conclusions on a global temperature map based on some data analysis charts and what it sees.
OpenAI said that the text and image input function of ChatGPT based on GPT-4o will be launched on Monday, and voice and video options will be launched in the next few weeks.
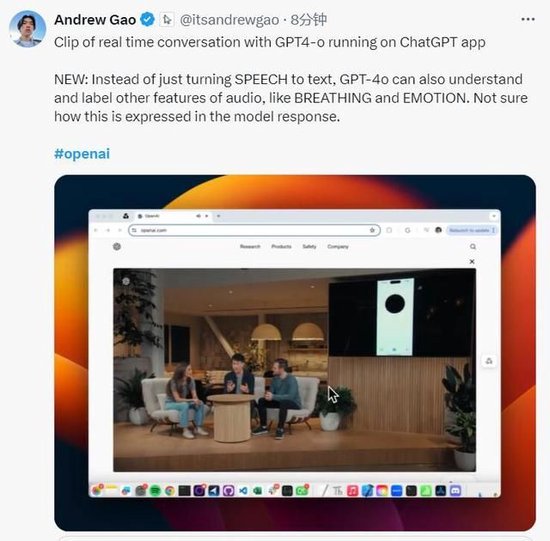
X platform netizens noticed the new functions displayed by OpenAI. Some netizens pointed out that GPT-4o can not only convert voice into text, but also understand and mark other features of audio, such as breath and emotion. It is uncertain how this is expressed in the model response.
Some netizens pointed out that, according to the demonstration, ChatGPT's voice can help solve equations in real time, speak like a human, and respond almost instantly, all of which run on mobile phones.
The fastest 232 ms response The average response time of audio input is similar to that of human
According to the OpenAI official website, o in GPT-4o means omnipotent prefix omni, which is a step towards more natural human-computer interaction, because it accepts any combination of text, audio and image as input content, and generates any combination of text, audio and image output content.
In addition to the faster API speed and significantly reduced cost, OpenAI also mentioned that GPT-4o can respond to audio input in the fastest time of 232 milliseconds, with an average response time of 320 milliseconds, which is similar to the response time of human in conversation. Its performance in English text and code is consistent with that of GPT-4 Turbo, and its performance in non English text has been significantly improved.
OpenAI introduced that GPT-4o is particularly good at visual and audio understanding compared with existing models. Previously, GPT-3.5 and GPT-4 users used the voice mode Voice Mode to talk to ChatGPT with an average delay of 2.8 seconds and 5.4 seconds, because OpenAI used three independent models to realize such conversations: one model transcribed audio into text, one model received and output text, and another model converted the text back to audio. This process means that GPT has lost a lot of information. It cannot directly observe the tone, multiple speakers or background noise, nor can it output laughter, singing or expressing emotions.
GPT-4o's voice dialogue is the product of OpenAI's end-to-end training of a new model across text, vision and audio, which means that all inputs and outputs are processed by the same neural network. OpenAI said that GPT-4o is its first model combining all these modes, so it is still just a superficial exploration of the functions and limitations of this model.
Last week, there was news that OpenAI would release AI based search products, but on Friday, Sam Altman, CEO of OpenAI, denied the news, saying that neither GPT-5 nor search engine was demonstrated on Monday. This means that once again OpenAI has not launched AI search as the time line revealed in the market. Later, some media said that the new product of OpenAI may be a new multimodal AI model with visual and auditory functions, and has better logical reasoning ability than current chat robots.
This Monday's demo really demonstrated OpenAI's efforts in voice. As for the new model and UI update launched by OpenAI, some netizens said that so far, OpenAI is not so groundbreaking.
Some netizens also think that OpenAI has further developed its relationship with Apple He also sent a picture of people sweating, saying that Siri, Apple's voice assistant, should look like this now.
Massive information, accurate interpretation, all in Sina Finance APP
Editor in charge: Ouyang Mingjun