Today's topic is《 Cloud primordial AI resource scheduling and AI workflow engine design sharing, mainly includes three parts:
The first part will briefly introduce what cloud native AI is;
The second part will focus on resource management and scheduling under cloud native AI;
The third part will introduce Baidu's self-developed AI workflow engine PaddleFlow.
1. Introduction to cloud native AI
In the past year, we have visited more than 10 enterprises in several industries, such as Pan Mutual, Smart Drive, biology, science and universities, and collected the top 10 pain points that everyone cares about.
From these problems, we can see that the problems of most customers focus on two aspects. The first is resource efficiency, such as resource utilization, heterogeneous chip scheduling and virtualization, domestic chips, and containers network Etc; The second is engineering efficiency, such as the landing of large models, the efficiency of training/reasoning tasks, and the starting speed of AI images.
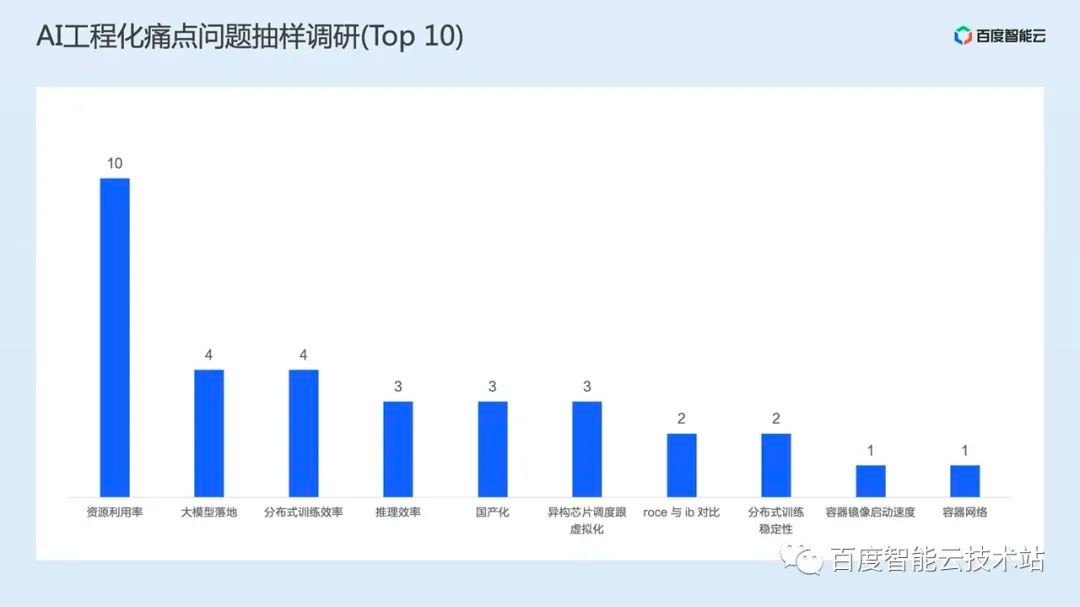
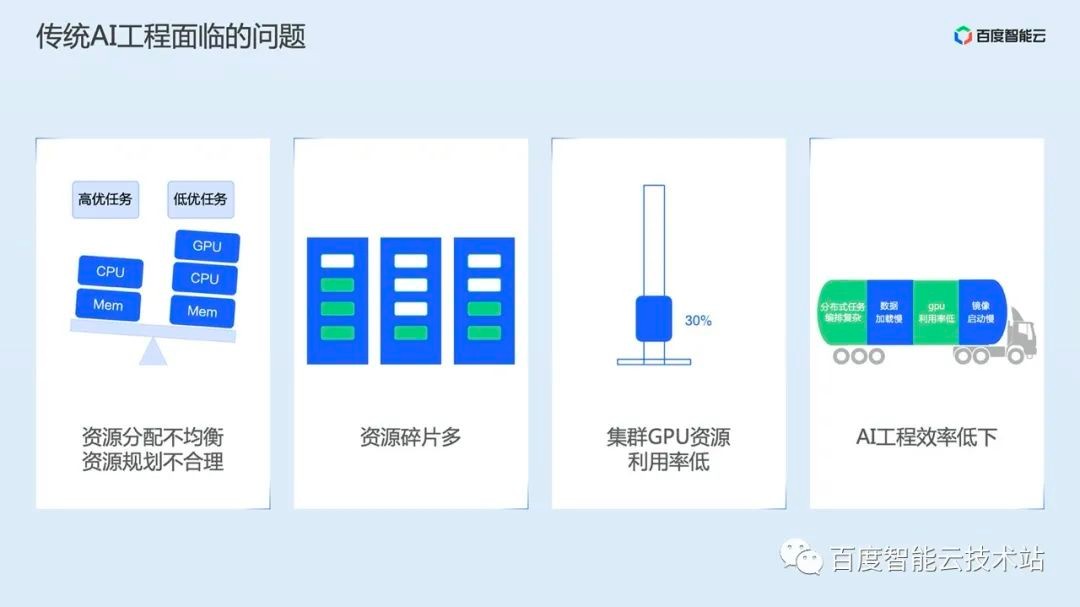
In addition to the pain points concerned by the above customers, we have also analyzed the traditional AI engineering, and listed four outstanding problems:
Unbalanced resource allocation or unreasonable planning often lead to inefficient operation of high-quality tasks;
There are many resource fragments, resulting in some tasks still unable to run when the cluster has free resources, which is especially obvious in AI training scenarios;
The utilization rate of cluster GPU resources is low, of course, this problem is closely related to the first two;
The low efficiency of AI engineering is actually a comprehensive problem. For example, the high complexity of distributed training task arrangement, the slow loading of training data, the unreasonable implementation of training operators lead to low utilization of GPU, and the image of AI operations is often relatively large and slow to start, which will lead to low efficiency of AI engineering.
With the help of cloud native technology, the above problems can be greatly improved.
Let's first introduce what cloud native and cloud native AI are.
Cloud native is currently cloud computing One of the hottest topics in the field, I directly gave the official definition of CNCF: cloud native is a general term for technologies such as building applications. Through cloud native technology, you can build applications that can be elastically extended. These applications can be run in different environments, such as public cloud, private cloud, hybrid cloud and other new dynamic environments.
From the definition of CNCF, we can see two keywords, elastic expansion and dynamic environment. That is to say, cloud native helps applications solve the problem of efficient utilization of resources and seamless migration.
Through several cloud native technologies developer Regardless of the underlying running environment, applications that can be deployed quickly and scaled elastically on demand can be easily realized.
Cloud native AI is an AI engineering solution with container service as the core and cloud native technology as the infrastructure, which seamlessly integrates cloud computing, storage load balancing And other services run through the whole life cycle of AI tasks.
Cloud native AI involves several technical sectors, including AI job scheduling, AI task acceleration, AI heterogeneous resource scheduling and virtualization, AI data acceleration, etc.

Now let's introduce some specific practices of Baidu Smart Cloud in the cloud native AI field.
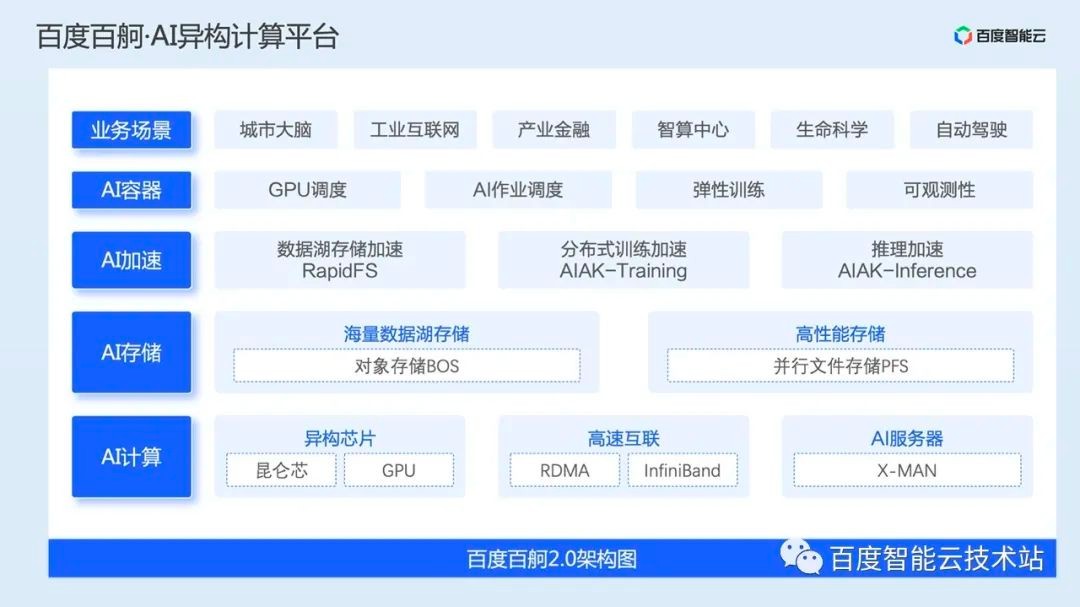
Baidu Smart Cloud's cloud native AI is built on Baidu Baige · AI heterogeneous computing platform. Baidu Baige is a heterogeneous computing platform that focuses on AI engineering construction and provides software and hardware integration. The latest version 2.0 includes four packages, namely AI computing, AI storage, AI acceleration, and AI container.
Baidu Baige can provide professional solutions for multiple business scenarios. Among them, AI containers and AI acceleration, as well as part of AI computing capabilities, are provided by cloud native AI.
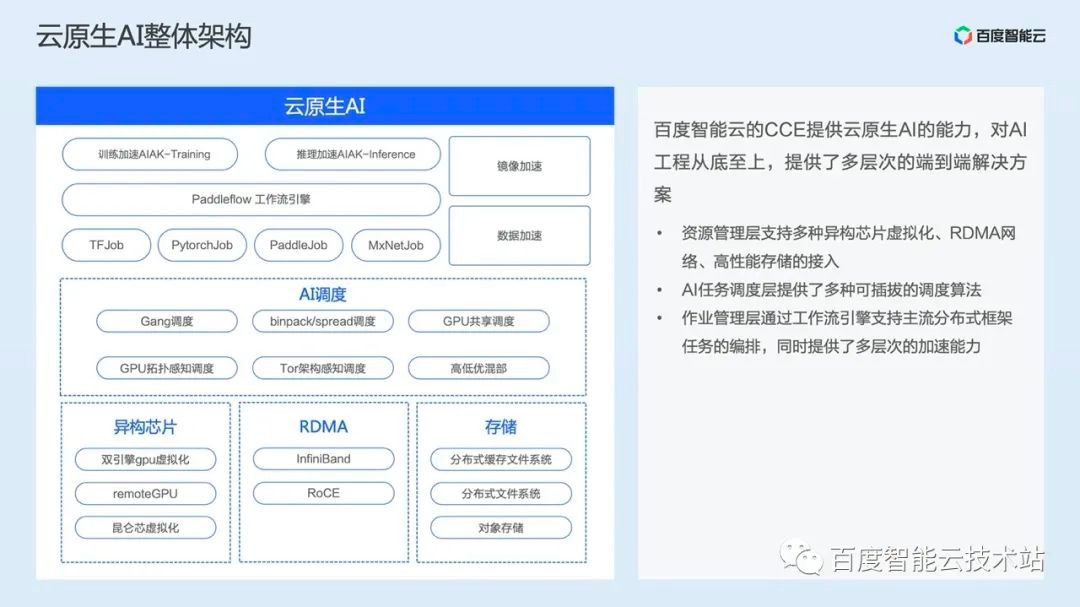
Then let's take a look at the overall architecture of cloud native AI.
Baidu Smart Cloud's cloud native AI provides multi-level end-to-end solutions for AI projects from the bottom to the top.
First is the resource management layer. Cloud native AI provides heterogeneous chip management, high-performance RDMA network access, and high-performance storage access. Heterogeneous chip management also includes dual engine GPU container virtualization (see the end of the article for technical details), remoteGPU, Kunlun core virtualization and other technologies.
Then comes the AI scheduling layer. Through the analysis of various business scenarios and customer exchanges, we gradually precipitate various scheduling algorithms into the cloud native AI products, providing an efficient and high-performance operating environment for AI tasks.
Further up is the AI task management layer, where we provide an Operator deployment interface that supports multiple distributed training tasks, a workflow engine that supports the orchestration of complex engineering jobs, and four acceleration capabilities: training acceleration, reasoning acceleration, image acceleration, and data acceleration. Among them, the AIAK acceleration kit is our high-level acceleration capability for reasoning and training scenarios. The second and third sessions of the "Baidu Baige Cloud Native AI" technology open class will be introduced in detail respectively.
As can be seen from the above architecture diagram, we are providing end-to-end solutions for the overall acceleration of AI projects.
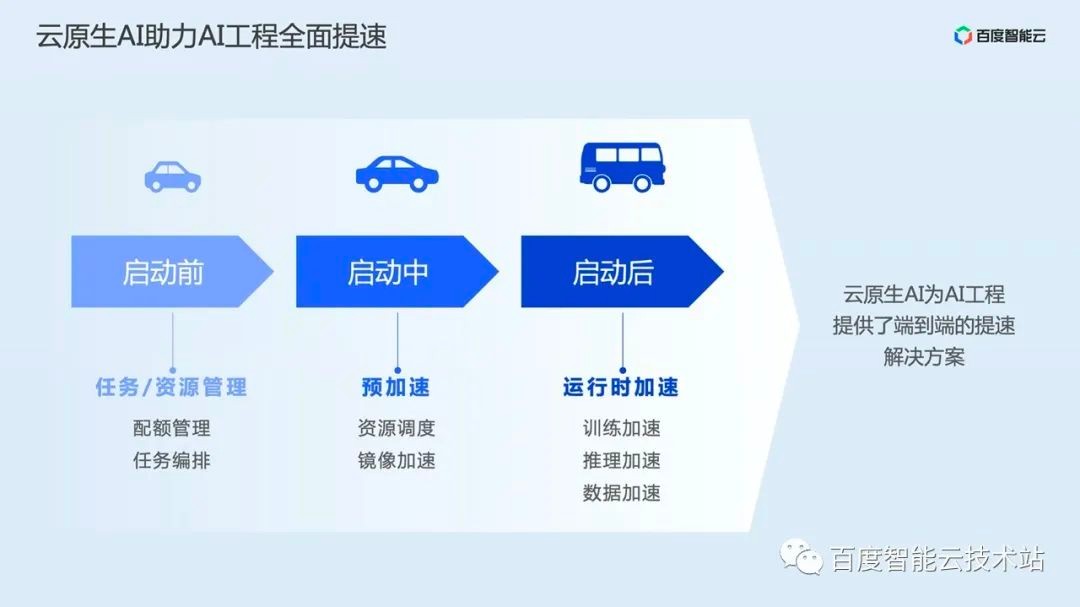
First of all, before the AI task is started, we provide cluster administrators with rich resource quota management portals, so that users can plan cluster resources well. At the same time, AI engineers can quickly arrange and deploy jobs through the workflow engine or the distributed training task operator.
Then during AI task startup, our AI scheduler and image acceleration module provide pre acceleration capability for AI tasks. While efficiently using cluster resources, the on-demand loading capability of AI images makes the AI task startup time more than ten times longer.
Finally, after the AI task is started, that is, when the AI task is running, the AI task can be accelerated several times through the AIAK acceleration suite and the data acceleration component developed by us.
2. Resource scheduling under cloud native AI 2 Resource scheduling under cloud native AI
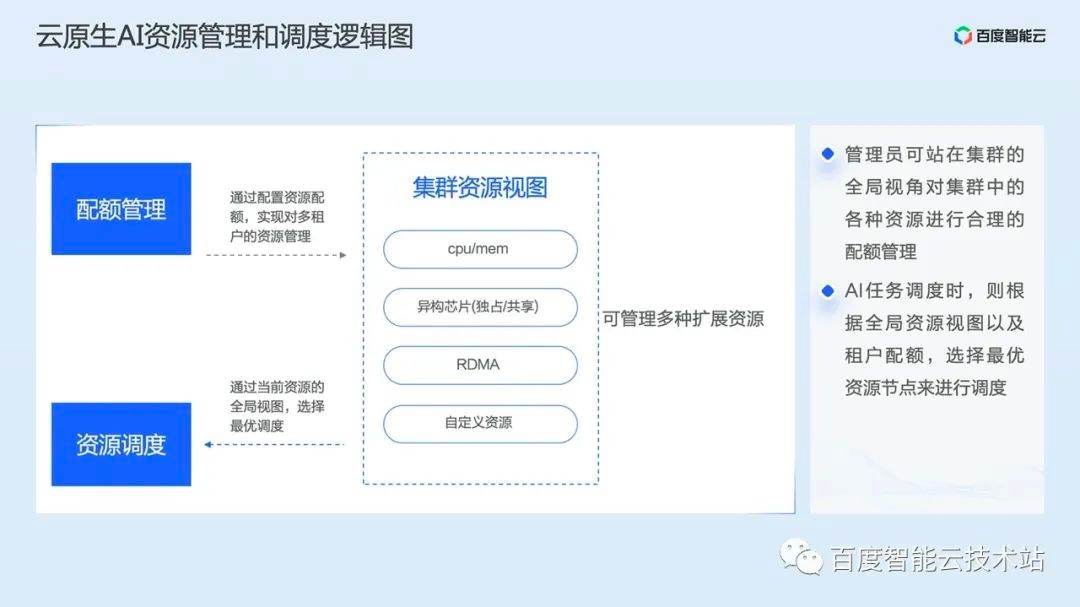
Let's first look at the overall logic diagram of resource management and scheduling of cloud native AI.
First, we will have an overall resource view in the cluster. In this resource view, you can manage multiple heterogeneous computing resources and user-defined resources. Cluster administrators can make reasonable capacity planning for various resources from a global perspective.
When AI tasks are scheduled, the scheduler will select the optimal node for scheduling according to the global resource view and tenant quota.
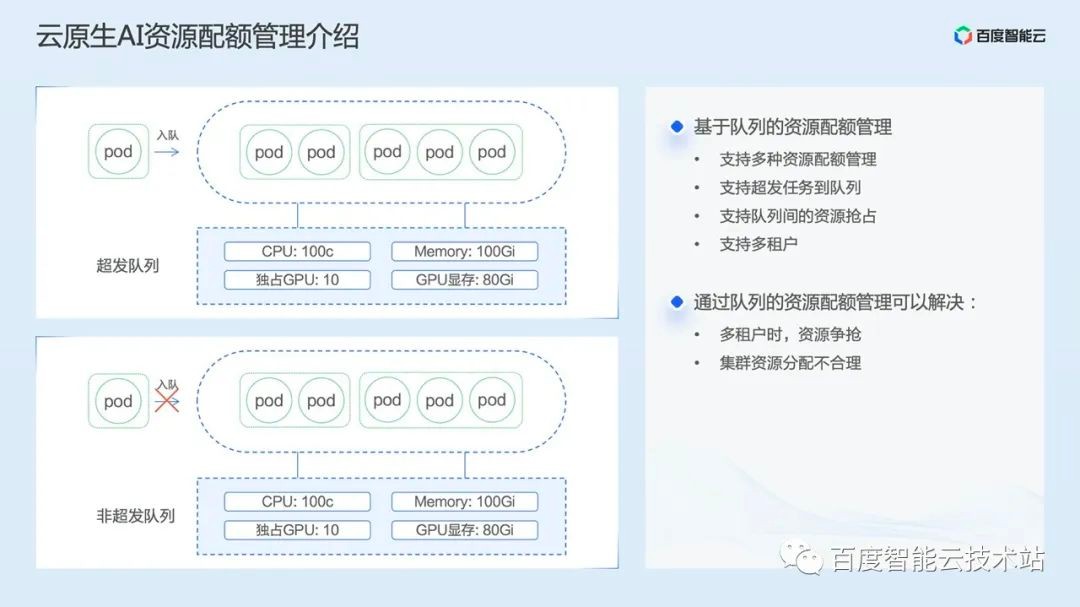
In terms of resource quota management, we have implemented a queue based resource quota management module, which we call resource queue.
The resource queue can support multiple resource quotas, as shown in the figure below. In addition to the conventional CPU and memory, it also supports quota management of GPU cards, GPU video memory, and custom resources.
There are two types of resource queues. The first is the over issued queue. When the resource quota in the queue is consumed, the task can still be over issued to the queue. However, the premise here is that the user needs to use the tag or our Console interface to display and specify the over issued task. When other resources in the queue are insufficient, the scheduler will give priority to expel the over issued task to ensure resource supply. The other is a non overrun queue. When the remaining resources of the resource queue are insufficient, new tasks cannot be scheduled to the resource queue.
Resource queues support multi tenancy. From the user's perspective, reasonable planning of resource queues can solve the problem of resource contention among multi tenants and unreasonable resource allocation.
Let's take a look at how cloud native AI performs resource scheduling based on resource queues.
First, introduce the concept of PodGroup. PodGroup is a set of strongly related pods, mainly used in batch workload scenarios, such as a set of PS and workers in TensorFlow. These pods use the same resources to perform the same tasks, and usually start and stop at the same time. So in the AI scenario, the scheduler will use PodGroup as the scheduling unit. What needs to be added is that PodGroup has the concept of minimum resource, and the scheduler will judge whether the scheduling conditions are met according to the minimum resource of PodGroup.
After the scheduler is started, it will periodically start a scheduling session, save the overall resource view of the current cluster in the session snapshot, and then execute several actions in turn, such as queue ->resource allocation ->resource recovery ->resource preemption ->backfill. Each action will be executed according to different scheduling algorithms in the plug-in collection, Allocate resources to the PodGroup to be scheduled.
Let's first introduce the meaning of these actions.
First, when creating a PodGroup, a resource queue will be specified. When the scheduler performs the first action queuing operation, it will first traverse all the queues in the cluster, and then try to put the PodGroup in the pending state into the queue. At this time, if the remaining resources of the queue do not meet the minimum resources of the PodGroup, it cannot be queued.
The second action executed by the scheduler is resource allocation. Similarly, the scheduler will first fetch all resource queues from the snapshot for traversal, and then fetch the PodGroup in the resource queue for traversal. If there is a pending Pod in the PodGroup, it will perform preselection and optimization operations similar to the K8s default scheduler, and finally select an optimal node to allocate to the Pod.
The third action executed by the scheduler is resource recovery, that is, to recover the resources of the over issued tasks in the over issued queue we mentioned before and allocate resources to the tasks to be scheduled.
The fourth action is resource preemption, which is based on the priority of tasks in the same queue. Therefore, a core difference between resource recovery and resource preemption is that resource recovery occurs between queues and resource preemption occurs within queues.
The last action is backfilling. As long as there are resources in the cluster, they will be allocated to the pods to be scheduled. The main scenario of backfilling is to prevent resources in the cluster from being occupied by large tasks, and small tasks are difficult to allocate to resources. Backfilling can enable small tasks to be quickly scheduled, thus improving the overall resource utilization of the cluster. The above is the general logic of the AI scheduler.
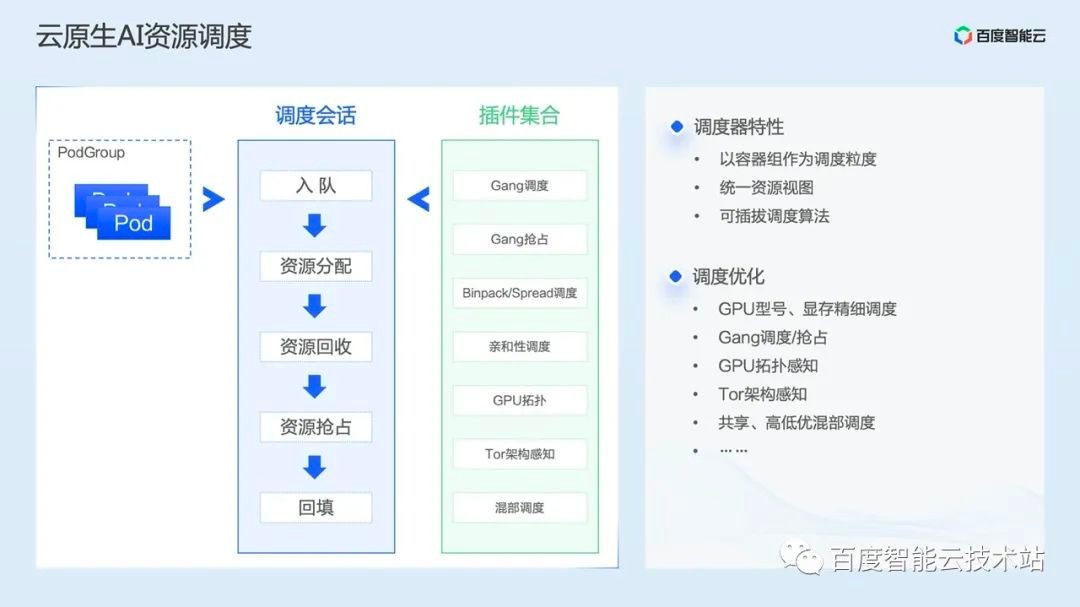
Next, we will introduce some core scheduling algorithms in the cloud native AI scheduler and the problems they solve.
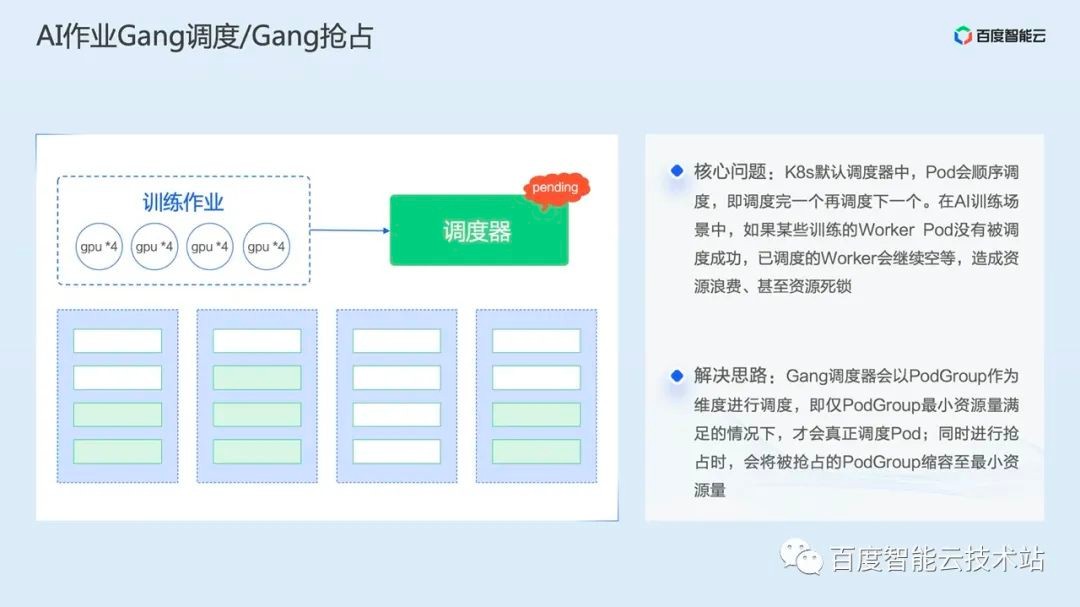
The first is Gang scheduling, which is actually a common scheduling algorithm in AI scenarios. In AI training scenarios, if some trained worker pods are not successfully scheduled, the scheduled workers will continue to wait empty, resulting in resource waste, or even resource deadlock. Therefore, Gang scheduling will be based on the minimum resources of the PodGroup set by the business. When the resources meet the requirements, it will actually schedule.
When we introduced the scheduler logic above, we mentioned the logic of resource preemption. In the same way, if only part of the Pod in a task is preempted, it will also bring two results. Either the preempted task fails, or it is in an empty state, which will also cause resource waste. Therefore, based on the logic of Gang scheduling, we also implemented the logic of Gang preemption, that is, when preemption occurs, the preempted PodGroup will be shrunk to the minimum amount of resources.
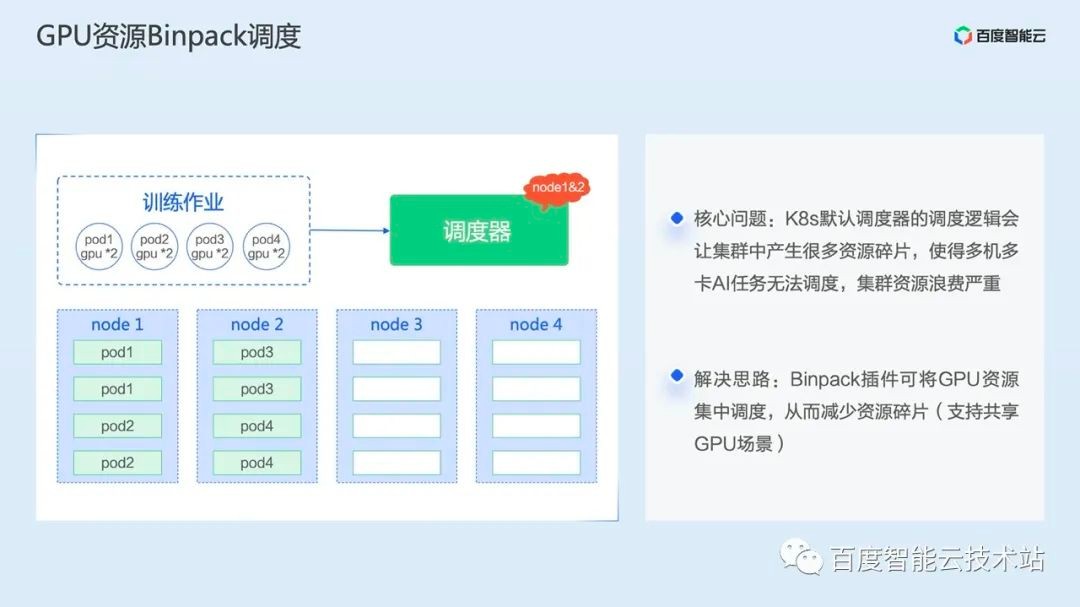
Then there is the Binpack scheduling plug-in. Binpack mainly solves the problem of cluster resource fragments. From the figure below, we can see that the GPU resources allocated by Pod are allocated to the second node only after the resources of the node are full according to the logic of centralized scheduling.
The logic of Binpack is also applicable to our self-developed GPU virtualization scenario. When multiple tasks sharing GPUs are scheduled, they will first occupy one card and then the second card. In this way, the Binpack plug-in can effectively improve the utilization of cluster resources.
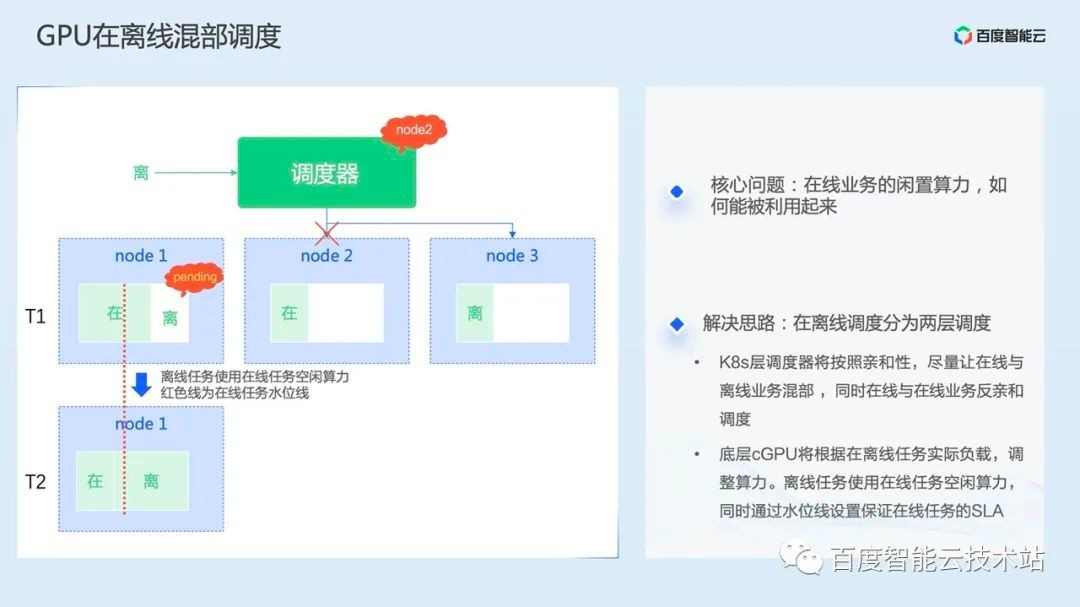
Then, the GPU is scheduled in the offline mixed part. In the GPU cluster within Baidu Group, there are often two types of business at the same time:
One is online service, which is highly sensitive to delay and has strict SLA. It usually occupies GPU for a long time, but it also has obvious peaks and troughs during operation;
One is the near line service, which can be understood as a resident offline service. It is insensitive to delay and has relatively high throughput requirements, but also has certain SLA requirements.
From the perspective of improving resource utilization, we hope that when online business is in the trough, we can give computing power to the near line business, and when it is in the peak, we can suppress the near line business and return computing power to online business.
Therefore, we have developed the GPU offline mixed function, which is divided into two parts of scheduling logic:
First, on the K8s layer, the AI scheduler will try to mix online and offline businesses according to affinity, and simultaneously make online and online businesses anti affinity scheduling;
The second is the bottom layer. The cGPU will adjust the computing power according to the actual load of offline tasks. Offline tasks use the idle computing power of online tasks, and the SLA of online tasks is guaranteed through the watermark settings.
Let's use the example on the left of the figure below to understand the logic of this section.
First, there are three single card GPU nodes in the cluster. The GPU on node 1 has one online service and one offline service running. The red dotted line is the SLA watermark. At T1, the amount of GPU computing power used by online business exceeds the SLA water mark, so offline tasks are held by pending. Although offline business has not exited the process, the computing power has not been allocated at this time. At T2, the GPU usage of online business drops below the SLA level. At this time, offline tasks are allocated to computing power, and the remaining computing power of online business can be used.
Then we look at Node2 and Node3. If another offline task is scheduled at this time, the scheduler will schedule the offline business to Node2 according to the offline affinity logic.
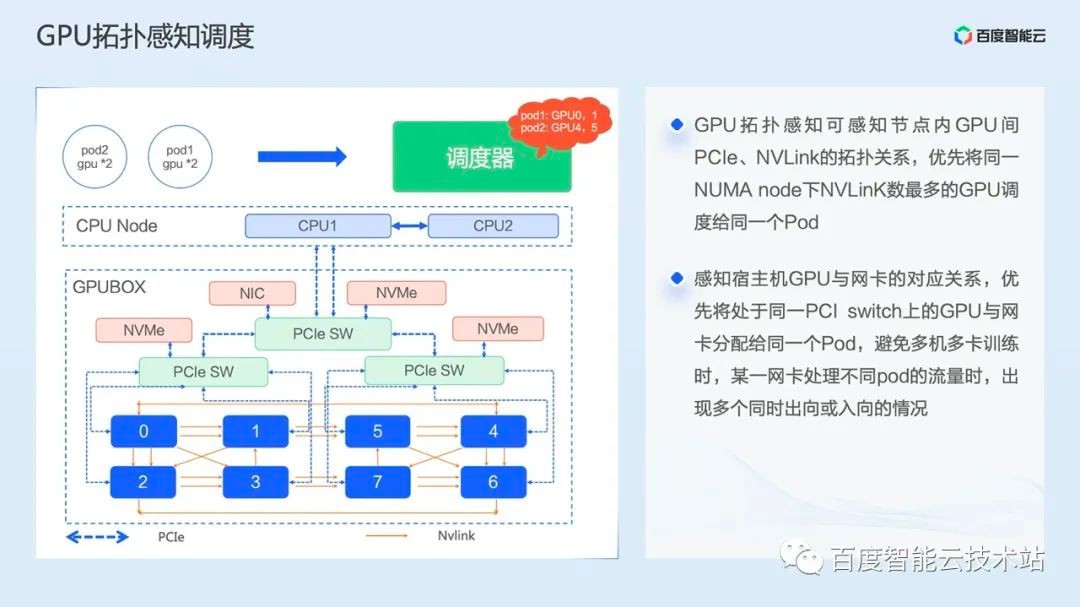
GPU topology aware scheduling is a special scheduling optimization for single machine multi card and multi machine multi card training.
We know that NVIDIA GPU cards have supported NVLink since the Volta architecture. Compared with PCIe, NVLink has a huge bandwidth advantage.
In terms of best practice, the GPU with the largest number of NVLinks under the same NUMA node should be preferentially dispatched to the same pod during single machine multi card training. When training multiple computers and multiple cards, in addition to the number of NVLinks, the physical location relationship between the network card and the GPU card should also be considered to avoid the situation that the same card network is assigned to different Pods. Because in this case, there may be mutual bandwidth impact between multiple Pods.
Based on the above considerations, we have implemented the GPU topology aware scheduling algorithm, which first senses the topological relationship between GPUs, and then senses the topological relationship between network cards and GPUs.
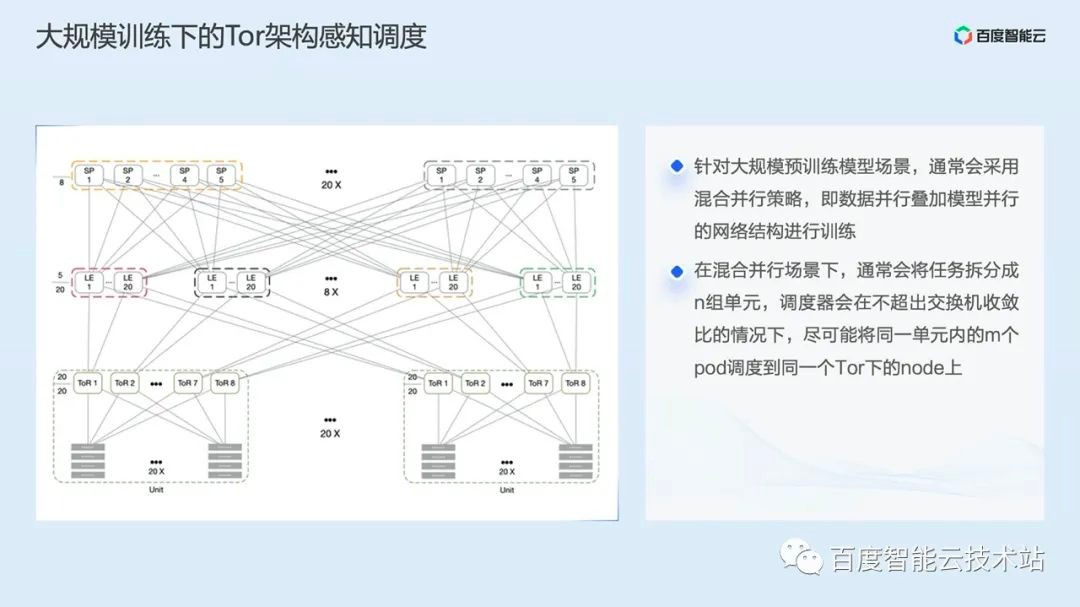
Finally, we introduce the Tor architecture aware scheduling algorithm. This is mainly a scheduling optimization for large-scale pre training model scenarios.
For some super models, thousands of calories may be required for training, which may lead to the size of GPU nodes reaching hundreds. These nodes will undoubtedly be under different Tor switches. A common Spine Leaf network architecture diagram is shown on the left of the following figure.
Usually, in this scenario, the model will adopt a hybrid parallel strategy, that is, the data parallel overlay model parallel network structure for training, and the training task will be divided into n groups of units, The pods in the n group cells will synchronize data first, and then synchronize data between cells. If these training pods are distributed to nodes of different switches, it is possible that the pods in the same group unit will communicate with the Spine switch at the top level, which will seriously affect the training performance and cause serious network congestion in extreme cases.
Based on this situation, we realized Tor architecture aware scheduling. The scheduler will schedule m pods in the same cell to nodes under the same Tor as far as possible according to the convergence ratio of the switch, so as to improve the network communication performance of large-scale distributed training.
The above is some introduction to the resource scheduling management of our cloud native AI. Next, we will introduce another core component of cloud native AI, the AI workflow engine PaddleFlow.
3. AI workflow engine – PaddleFlow
Cloud native technology has greatly improved our resource efficiency, but also introduced higher learning costs. For AI engineers, how to quickly access the cloud native environment is a problem. So there is the emergence of AI workflow engine.
AI workflow engine can serve as a good bridge to enable AI engineers to use simpler and more familiar semantics to arrange AI projects, and form a standard and acceptable engineering template to improve operation efficiency; At the same time, the workflow engine also shields many underlying details for AI engineers, so that AI tasks and AI resources can be seamlessly connected.
Based on the above background, Baidu has developed a workflow engine for AI scenarios - PaddleFlow.
Paddleflow is the core component of Baidu Smart Cloud CCE (Cloud Container Engine) cloud native AI products. It can undertake various AI middle platforms upward and carry various core capabilities in cloud native AI downward, including resource scheduling, GPU virtualization, RDMA components, and distributed cache systems.
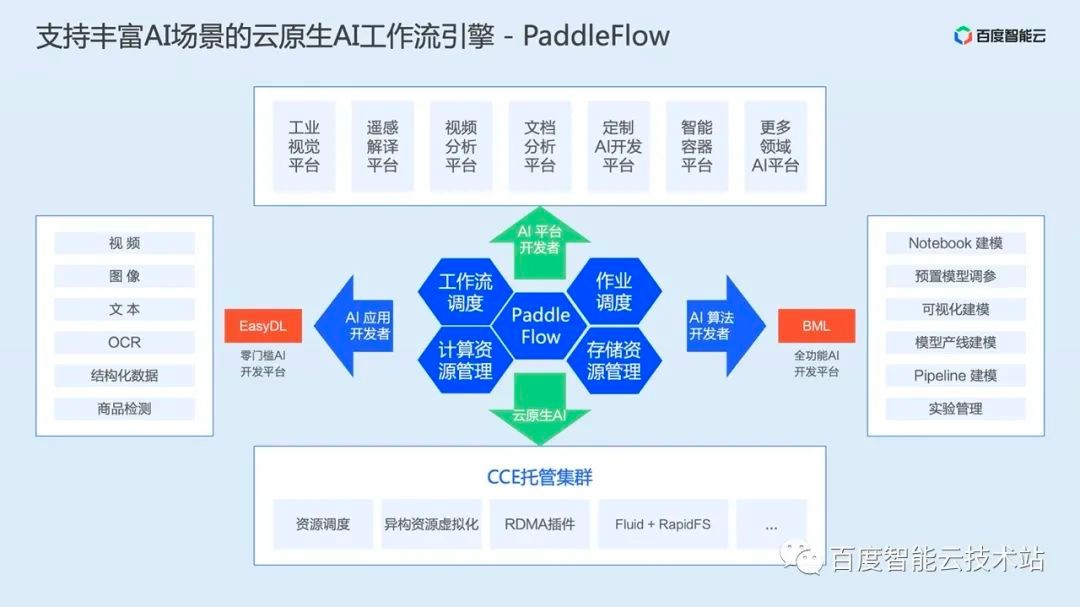
First of all, PaddleFlow is a workflow engine built on K8s, which is inherently cloud native. With the help of K8s technology ecology, PaddleFlow can easily access various heterogeneous environments.
Secondly, PaddleFlow provides a unified access mode for computing and storage, with a variety of data processing and algorithm libraries built in, and supports various mainstream distributed training frameworks in the industry.
At present, PaddleFlow has been widely practiced in Baidu's factory. Based on the cloud native AI resource scheduling management engine we introduced above, PaddleFlow can already carry the scheduling of ten thousand power cards, and the number of training jobs run every day has reached ten thousand, which can support the training tasks of hundred billion level parameter models.
Finally, PaddleFlow is a lightweight and easy-to-use workflow engine. We have provided a product portal for one click deployment on CCE, combined with cloud load balancer and RDS services, to provide users with a stable and highly available operating environment.
PaddleFlow is currently open source on GitHub, and interested students can also download PaddleFlow on GitHub to deploy it to their K8s environment for trial.

Let's take a look at the overall architecture of PaddleFlow.
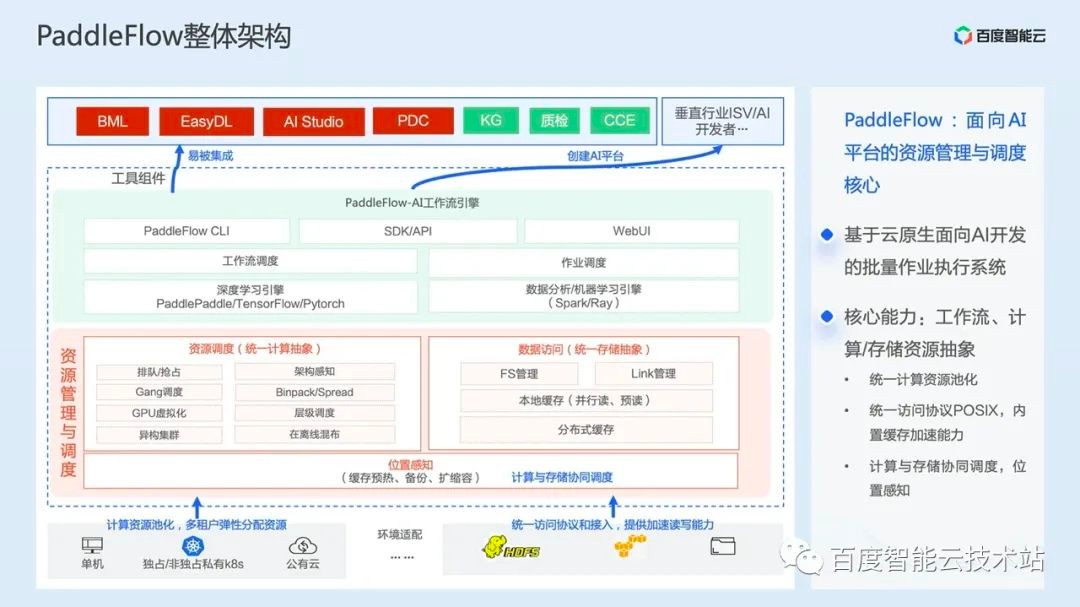
As we mentioned earlier, AI workflow engine is a bridge between AI engineering and cloud native, which mainly solves the two core issues of job efficiency and resource efficiency, so we divide PaddleFlow into two parts as a whole.
The first part is the batch job scheduling system for AI development engineers or AI platforms, which is the green part in the figure below. In this part, we use the built-in deep learning engine and the traditional machine learning The engine can support various mainstream AI frameworks, and through the workflow scheduling kernel Pipeline Core, AI tasks can be operated efficiently. Further up the user interface layer, we also provide multiple access methods of command line/SDK/WebUI, so that AI tasks can be flexibly connected.
The second part is the management and scheduling system for the underlying resources, that is, the red part in the figure below. Here we have further abstracted the computing resources and storage resources, forming two core modules: resource scheduling and data access. We can see that the resource scheduling part uses the scheduling algorithm we introduced in the second part above, while the data access part is combined with the PaddleFlowFS distributed cache file system, which shields the underlying storage differences upward, provides users with efficient data access, and exposes the POSIX interface to users, Tasks can be accessed without code modification.
At the same time, in this layer, we also realize the ability of location awareness, which enables computing instances and storage instances to schedule together, shorten data access paths, and accelerate data access performance.
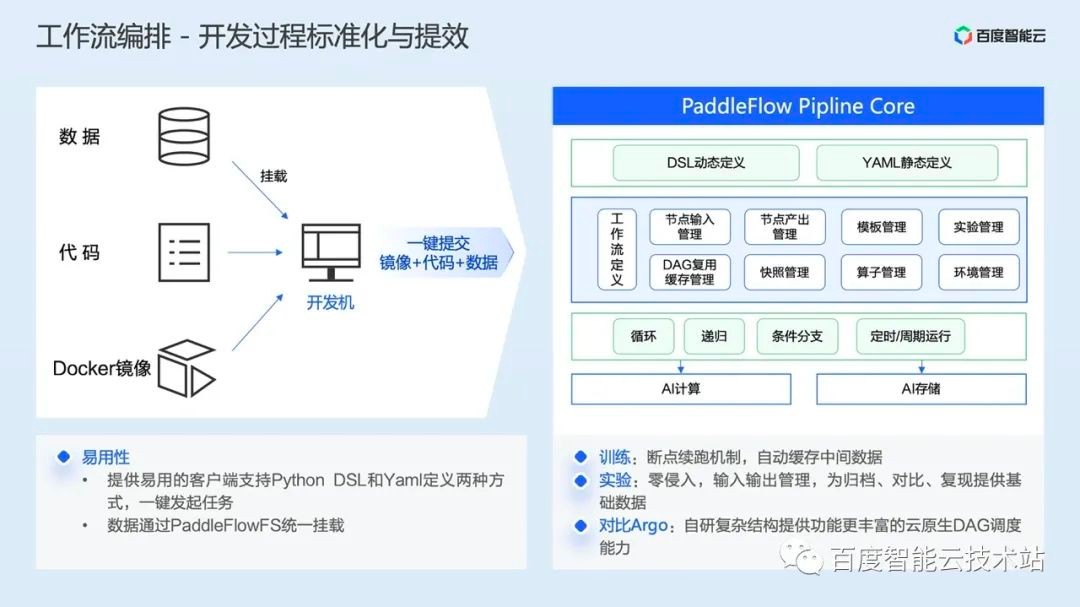
Let's focus on the design of several core modules. First, one of the core modules of workflow scheduling: Pipeline Core.
Here we first solve the problem of ease of use of homework arrangement. When users need to build a workflow, they only need to prepare their own code, data, and image in advance, and define the workflow at the same time, then they can submit and run with one click. Considering that most AI developers use Python language for development, we provide users with Python DSL and Yaml semantic editing methods. AI engineers can quickly build a complex workflow by using a variety of built-in management modules and conditional expressions.
At the same time, we support developers to directly mount remote data to the local on the development machine to facilitate viewing results and debugging data.
We have made a wealth of customized functions for training scenarios. For example, when a complex training workflow is running, it may frequently occur that a task fails. At this time, if we want to re run the failed task, we do not need to re train from the first task of the workflow, and continue to re run the workflow on the failed task node based on the PaddleFlow breakpoint running mechanism. For tasks that have been successfully completed, PaddleFlow will automatically cache the intermediate data, and the successful task nodes will be automatically skipped when the workflow is re run.
For development experiment scenarios, AI engineers may need to conduct frequent parameter adjustment and testing. This process may require frequent archiving of data, data transfer between tasks, and comparison of historical version data. In response to this situation, we provide a zero intrusion I/O management mechanism to provide basic data for archiving, comparison, replication and other work.
In job scheduling, we can provide more abundant DAG scheduling capabilities than Argo, a popular workflow engine in the industry. For example, we support sub DAG running.
Here we give a simple example of workflow orchestration:
In the workflow definition file, the user first defines a data preprocessing task named preprocess as the workflow entry, and then defines a training task named train for training. In the task definition, it describes its pre dependent task preprocess through the deps field, and finally defines a task named validate to verify the trained model, This is the simplest training workflow.
From Yaml, we can see that we have abstracted the complex commands of K8s. One writing can be called many times. AI engineers can run a complete workflow through simple choreography. At the same time, we preset many common operators in the workflow, which can be directly called in the command.
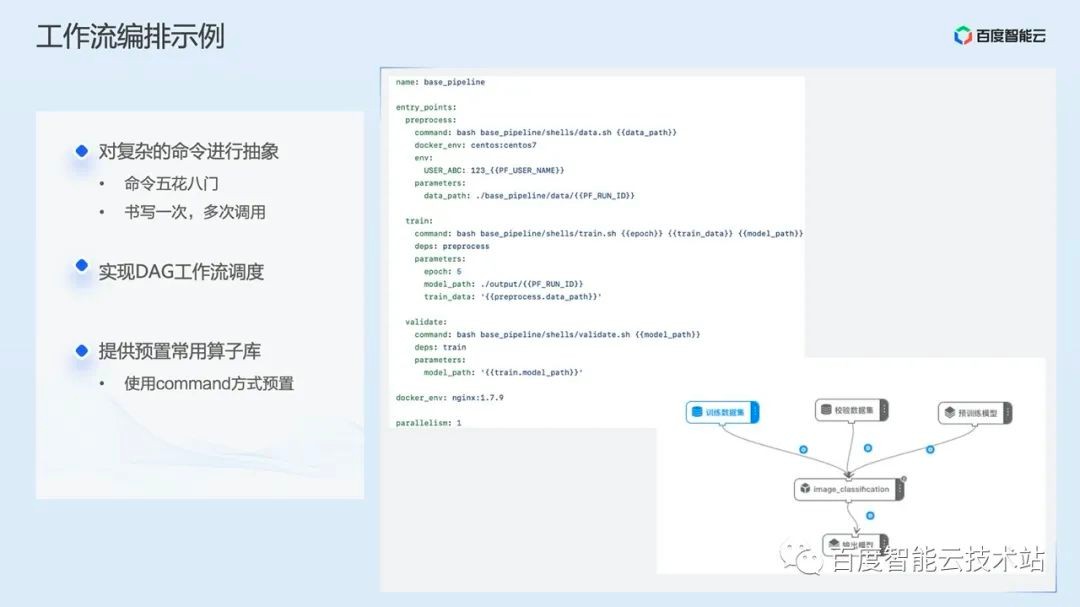
After the workflow is defined and submitted to PaddleFlow Server, PaddleFlow Server will first parse the workflow, then schedule it according to the DAG execution order, and submit the task to the K8s environment in the form of Pod.
After entering K8s, it is the logic of the second part above. However, in the AI workflow engine scenario, we have further expanded the hierarchical scheduling capability.
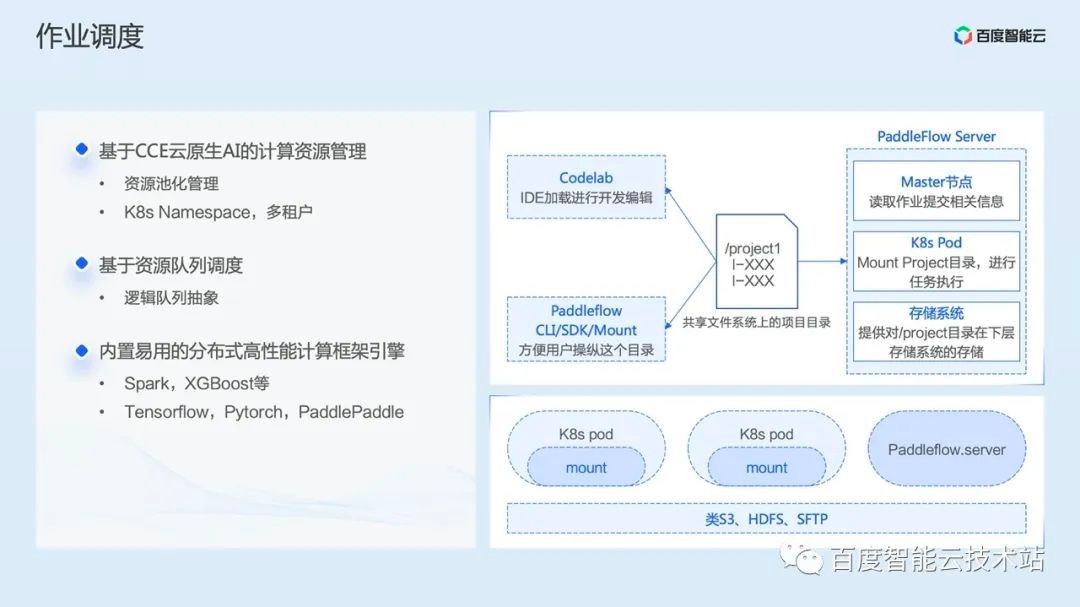
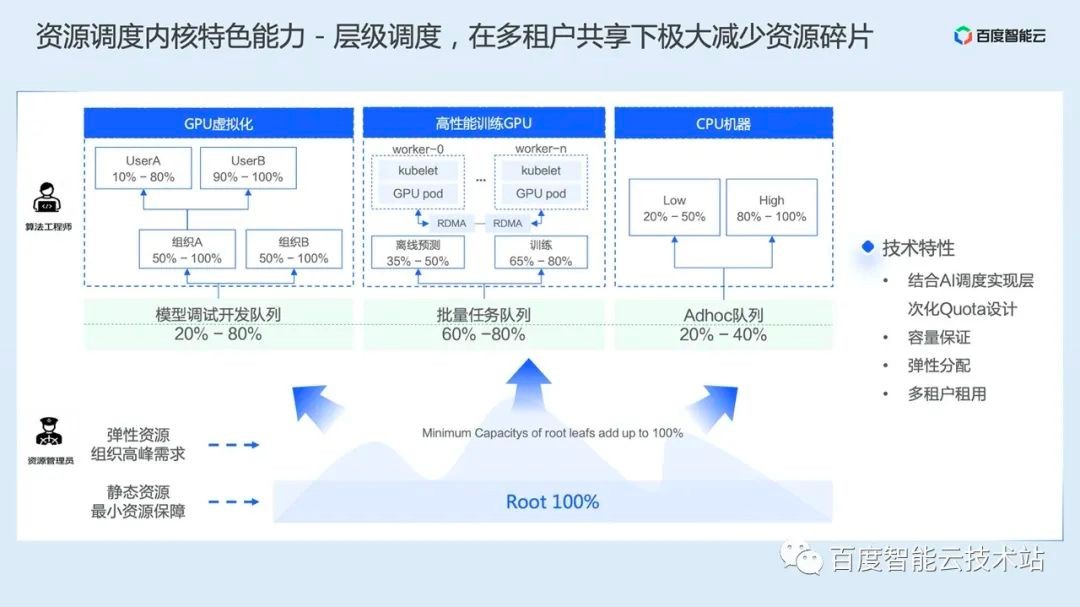
Hierarchical scheduling is a characteristic capability of PaddleFlow based on cloud native AI scheduling. We have further expanded the resource queue of cloud native AI and realized the hierarchical elastic quota design.
When there are multiple users in the cluster, the administrator will allocate the resources of the cluster to different users to ensure that users have enough resources to use.
The traditional method is to allocate fixed resources through the K8s native ResourceQuota method. Because different users use resources in different periods and ways, it may occur at a certain time that some users' resources are not enough, while others' resources are idle. If several similar situations occur, the entire cluster will waste a lot of resources, resulting in a decline in the overall resource utilization of the cluster.
To solve the above problems, we have implemented hierarchical queuing and hierarchical scheduling. Here are several key design points:
Hierarchical queue design. This hierarchical queue design ensures that all resources set by the parent queue can be used by the child queue. In this way, it is easier to reasonably allocate and limit the use of resources through hierarchical management.
Capacity guarantee. A resource proportion will be set on the queue to ensure that each queue will not occupy the resources of the whole cluster.
Flexible allocation. Idle resources can be allocated to any queue. When multiple queues compete, they will be balanced according to the proportion or other strategies.
Multi tenant leasing. By limiting the capacity of queues, multiple users can share the same cluster. Colleagues ensure that each queue is allocated to its own capacity to improve utilization.
These design features have brought many advantages, such as flexible resource management, which is more suitable for enterprises to use multiple levels for resource isolation and allocation; The resource capacity is guaranteed by setting the upper and lower limits of resources to ensure the lowest available resources for tasks and limit the upper limit of resources; On demand preemption recovery ensures that resources can be reused between tasks with different priorities and free resources.
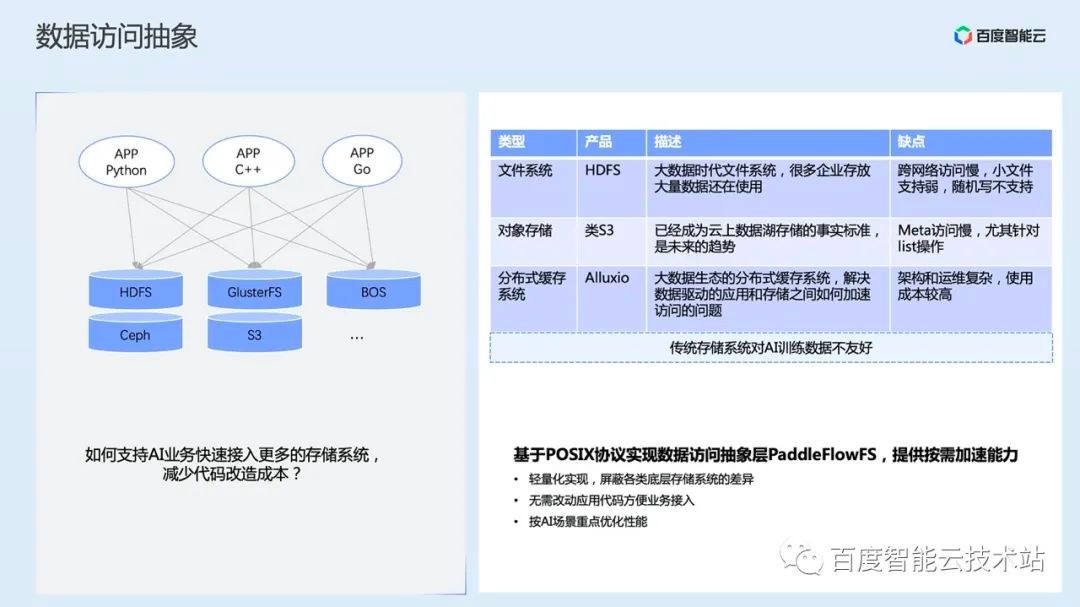
The second core capability of PaddleFlow is how to unify the storage abstraction, which can support AI business to quickly access more storage systems and reduce the cost of code transformation.
The scenarios for AI storage are very complex. For example, there will be structured storage requirements for images and texts in AI scenarios, such as reading and writing large files, random reading and writing small files journal Writeback and so on. No storage system can meet all requirements at the same time. We have made a special comparison: traditional storage systems have problems such as insufficient AI training data, general problems with meta access, poor remote access performance and frequent timeout.
Considering that privatized users generally have file systems and no more machine budget data migration, we use storage middleware with a unified access protocol, open secondary development capabilities, and focus on optimization for AI scenarios. The benefits of this are lightweight and simple operation and maintenance.
Let's take a look at the specific design:
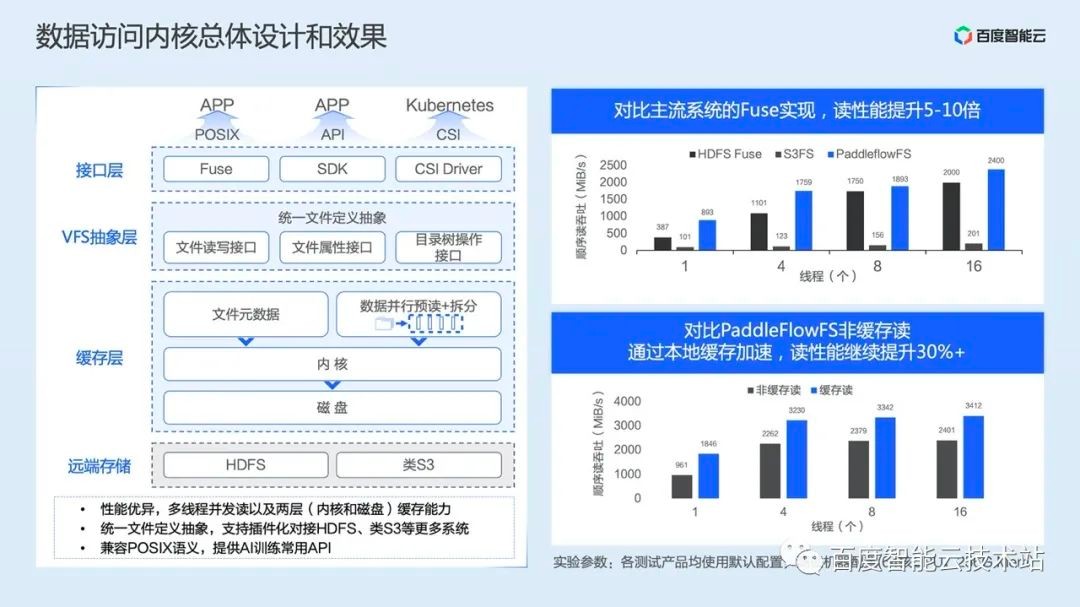
The left side of the figure below is the logical architecture diagram of the data access kernel PaddleFlowFS.
The first is the interface layer. We have implemented the Fuse Client, which can support the most common API in training scenarios. When training the second round of epoch, we can directly read the cache to improve training efficiency. In addition, we also provide SDK and CSI Driver interfaces for users to access more flexibly.
Next is the VFS abstraction layer. In this layer, we have implemented the abstract definition of the file system, including the file read/write interface, file attribute interface, directory tree operation interface, so that we can interface with a variety of remote storage, including HDFS file systems, S3 classes Object Storage System, etc.
Then, between the VFS abstraction layer and remote storage, we also implemented a cache layer, which can store high-frequency access data to local memory and disk, providing two-layer cache capability. Using Cache Locality technology, we can achieve sub millisecond level security of bandwidth and network latency. At the same time, we have established directory tree cache for HDFS and S3 storage, which can support millions of QPS.
On the right side of the figure below is a comparison chart of the measured performance. It can be seen that PaddleFlowFS has a 5-10 times increase in the first read performance compared with HDFS Fuse and S3FS, and a 30%+increase in the second cached read performance.
Today, I will first introduce the two parts of cloud native AI in terms of resource efficiency and engineering efficiency. Later, my colleagues and colleagues from NVIDIA will also introduce the training and reasoning acceleration of cloud native AI, including its principles and practices. Welcome to continue your attention.