物理嵌入 它允许从原子数创建嵌入向量,该嵌入向量是以下内容的串联: 原子群的学习嵌入 原子周期的学习嵌入 一组已知物理特性的固定或学习嵌入,如 门捷列夫 对于OC20数据集,原子标签的学习嵌入(吸附质、催化剂表面或催化剂亚表面)
基于标签 图形重新布线 OC20数据集的策略: -
删除标签节点 删除图形中与标记0关联的所有节点并重新计算边 -
一个超级节点每个图形 用单个新原子替换所有标记0原子 -
一个超级节点每个原子类型 替换所有标记0原子 给定元素的 有自己的超级节点 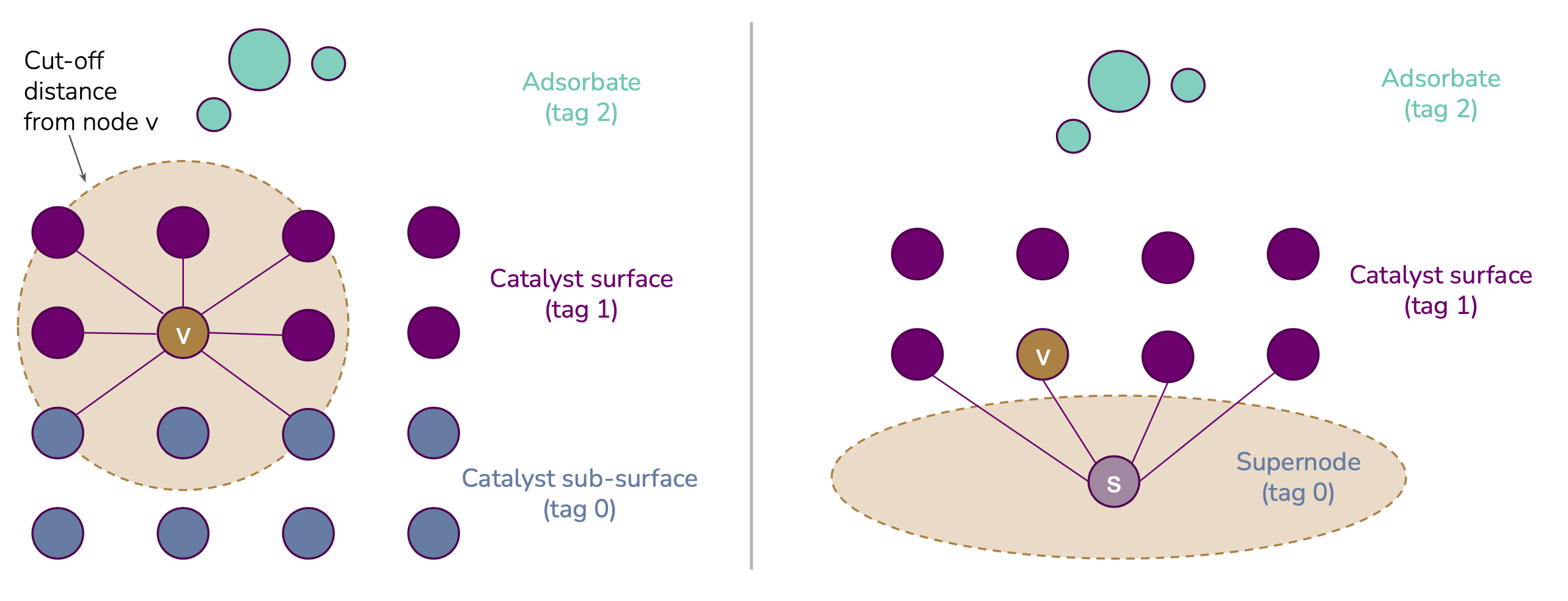
-
pip安装阶段 ![]()
进口 火炬
从 相位 . 嵌入 进口 物理嵌入
z(z) = 火炬 . 兰丁 ( 1 , 85 , ( 三 , 12 )) #一批3个图,每个图有12个原子
物理_嵌入 = 物理嵌入 ( z _ emb _大小 = 32 , #默认
周期_大小 = 32 , #默认
组_ emb _大小 = 32 , #默认
属性_项目_大小 = 32 , #默认值为0->无学习投影
n个元素 = 85 , #默认 ) 小时 = 物理_嵌入 ( z(z) ) #h.形状=(3,12,128)
标签 = 火炬 . 兰丁 ( 0 , 三 , ( 三 , 12 )) 物理_嵌入 = 物理嵌入 ( 标记_ emb _大小 = 32 , #默认值为0,这是OC20特有的
最终_项目_大小 = 64 , #默认值为0,没有投影,只有凹面。 嵌入式。 ) 小时 = 物理_嵌入 ( z(z) , 标签 ) #h.形状=(3,12,64)
#假设安装了torch_geometry:
数据 = 火炬 . 负载 ( “examples/data/is2re_bs3.pt” ) 小时 = 物理_嵌入 ( 数据 . atomic_numbers(原子编号) . 长的 (), 数据 . 标签 ) #h.shape=(261,64) 
从 复制 进口 深度复制
进口 火炬
从 相位 . graph_rewiring(图形_布线) 进口 ( 删除标签节点 , 一个超级节点每个图形 , 一个超级节点每个原子类型 , ) 数据 = 火炬 . 负载 ( “./examples/data/is2re_bs3.pt” ) #3批OC20 IS2RE数据样本
打印 ( 数据最初包含{}图、总共{}个原子和{}条边 . 格式 ( 伦恩 ( 数据 . 北约 ), 数据 . 脉冲重复频率 [ - 1 ], 伦恩 ( 数据 . 单元格偏移(_O) ) ) ) 重新布线数据 = 删除标签节点 ( 深度复制 ( 数据 )) 打印 ( 没有tag-0节点的数据包含{}图、总共{}个原子和{}条边 . 格式 ( 伦恩 ( 重新布线数据 . 北约 ), 重新布线数据 . 脉冲重复频率 [ - 1 ], 伦恩 ( 重新布线数据 . 单元格偏移(_O) ) ) ) 重新布线数据 = 一个超级节点每个图形 ( 深度复制 ( 数据 )) 打印 ( “每个图有一个超级节点的数据总共包含{}个原子和{}条边” . 格式 ( 重新布线数据 . 脉冲重复频率 [ - 1 ], 伦恩 ( 重新布线数据 . 单元格偏移(_O) ) ) ) 重新布线数据 = 一个超级节点每个原子类型 ( 深度复制 ( 数据 )) 打印 ( “每个原子类型有一个超级节点的数据总共包含{}个原子和{}条边” . 格式 ( 重新布线数据 . 脉冲重复频率 [ - 1 ], 伦恩 ( 重新布线数据 . 单元格偏移(_O) ) ) ) 数据最初包含3个图形,共261个原子和11596条边 没有tag-0节点的数据包含3个图形,共64个原子和1236条边 每个图有一个超级节点的数据总共包含67个原子和1311条边 每个原子类型有一个超级节点的数据总共包含71个原子和1421条边 git克隆 git@github.com :vict0rsch/phast.git 诗歌安装--使用dev pytest--cov=phast--cov报告项忽略 mendelev(0.14.0)需要Python>=3.8.1,<3.12