上周,GitHub发生了几起可用性事件,包括长时间运行和短时间运行。自那时以来,我们已经缓解了这些事件,所有系统现在都运行正常。这些事件的根本原因是无关的,但总的来说,它们对组织和开发人员信任GitHub提供的服务产生了负面影响。这是不可接受的,也是我们坚持的标准。我们立即采取直接行动来纠正这种情况,我们希望对这些事件的原因以及我们在未来采取的缓解措施非常透明。请继续阅读以了解更多详细信息。
日期:2023年5月9日
事件:Git数据库由于配置更改而降级
影响:10项主要服务中有8项降级 |
详细信息:
5月9日,我们发生了一起事件,导致状态门户上10个服务中的8个受到重大(状态为红色)停机的影响。大多数停机时间只持续了一个多小时。在这一小时的时间内,许多服务无法读取新写入的Git数据,导致了广泛的故障。在这次停机之后,一些拉入请求和推送数据的事故后恢复时间延长了。
此事件是由服务Git数据的内部服务的配置更改触发的。此更改旨在防止连接饱和,之前已在Git后端的其他位置成功引入。
在推出后不久,集群发生了故障转移。我们恢复了配置更改,并尝试在几分钟内回滚,但由于内部基础结构错误,回滚失败。
一旦我们完成了逐步的故障转移,写入操作就恢复到数据库中,广泛的影响也就结束了。需要额外的时间来获得Git数据、网站可见内容和拉取请求,以使在停机期间收到的推送保持一致,从而实现完全解决。
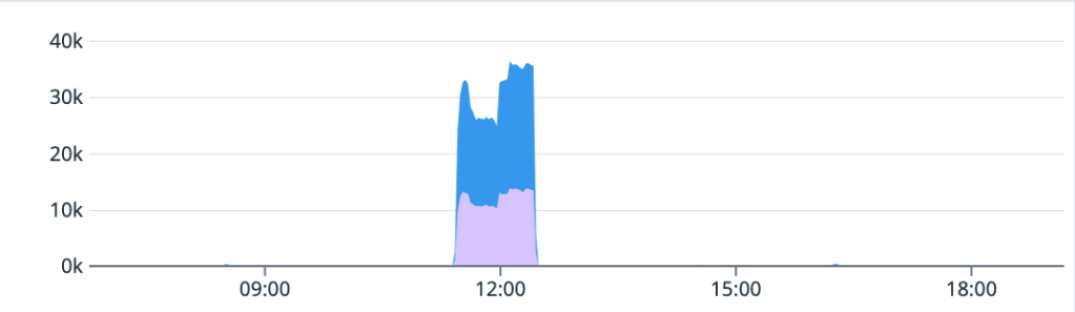 Git推送错误率
Git推送错误率
日期:2023年5月10日
事件:GitHub应用程序身份验证令牌颁发因加载而降级
影响:10项主要服务中有6项降级 |
详细信息:
5月10日,提供GitHub应用程序身份验证令牌的数据库集群发现GitHup应用程序权限的写入延迟增加了7倍(状态为黄色)。在这次事件的大多数时间里,这些身份验证令牌请求的失败率为8-15%,但在很短的时间内达到了76%的峰值。
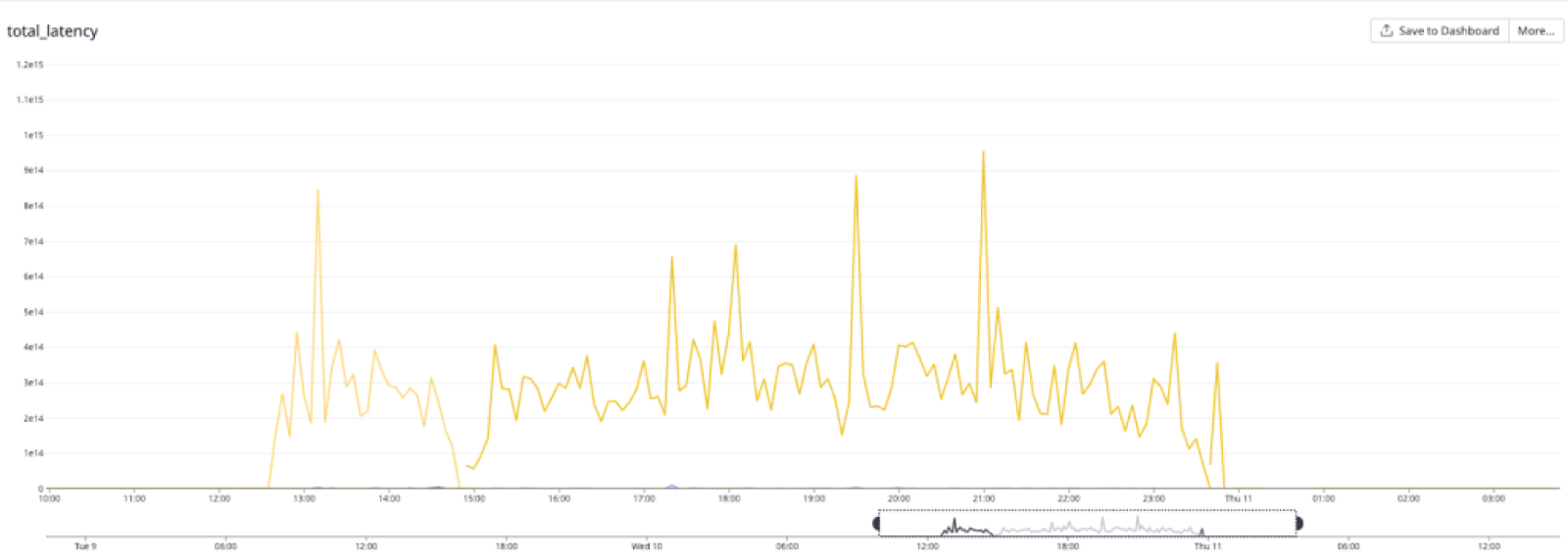 总延迟
总延迟
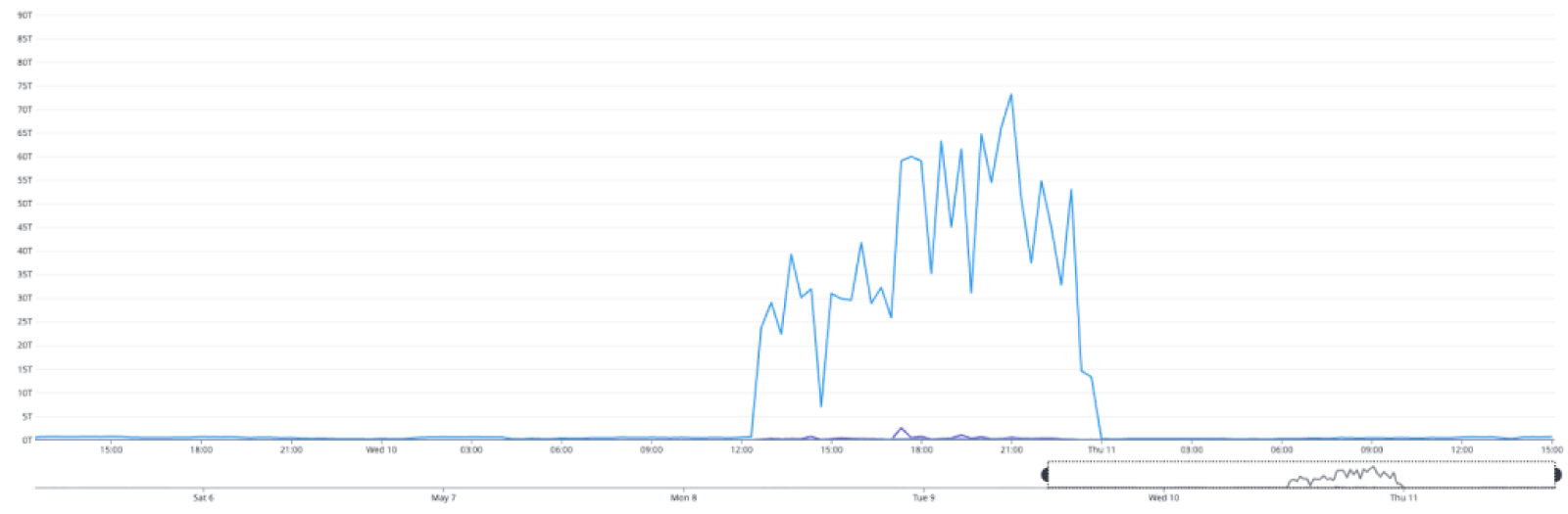 获取延迟
获取延迟
我们确定用于管理GitHub应用程序权限的API实现效率低下。当在特定情况下调用时,它会导致非常大的写操作和超时失败。此API由超时重试的新调用方调用,从而触发事件。在努力确定根本原因、改进数据访问模式和解决新调用模式的来源的同时,我们还采取了一些步骤来减少内部和外部路径的负载,减少对关键路径(如GitHub Actions工作流)的影响。恢复后,我们重新启用了所有挂起的源,然后状态为绿色。
虽然我们更新备份数据模型以完全避免这种模式,但我们正在更新API以检查安装状态的变化,如果作为临时措施触发这些大写操作,则请求将失败。
除了查询性能的问题外,我们的可观察性大多针对识别高容量模式进行了优化,而不是低容量高成本模式,这使得很难识别导致集群运行状况下降的特定情况。展望未来,我们将优先考虑在这起事件中应用我们的调查经验,以确保我们对未来类似案件有快速明确的答案。
日期:2023年5月11日
事件:Git数据库由于丢失读取副本而降级
影响:10项主要服务中有8项降级 |
详细信息:
5月11日,一个提供git数据的数据库集群崩溃,触发了自动故障转移。主服务器的故障切换成功,但在此实例中未附加读取副本。主服务器无法处理完整的读/写负载,因此平均有15%的Git数据请求失败或速度较慢,事件开始时的峰值影响为26%。我们通过重新附加读取副本和恢复的核心场景来缓解这一问题。与5月9日的事件类似,恢复拉请求推送更新需要额外的工作,但我们最终能够实现完全解决。
除了立即的缓解工作外,正在进行的顶级工作流还集中于确定和解决是什么导致集群崩溃,以及为什么故障没有使集群处于良好状态。我们想澄清的是,该团队已经在努力了解和解决之前发生的集群碰撞事件,这是最近另一起事件的维修项目的一部分。此故障切换副本故障是新出现的。
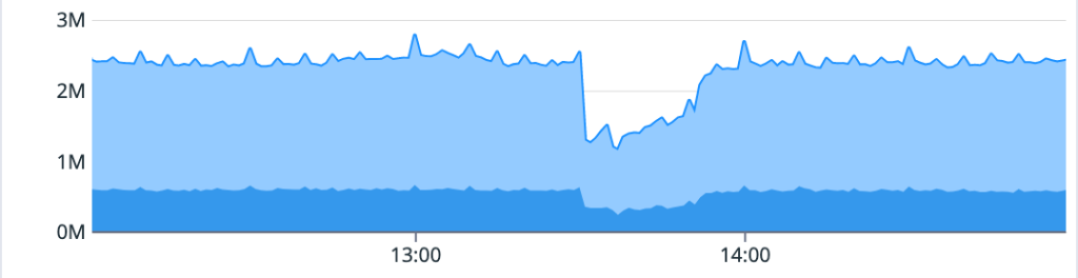 Git操作成功率
Git操作成功率
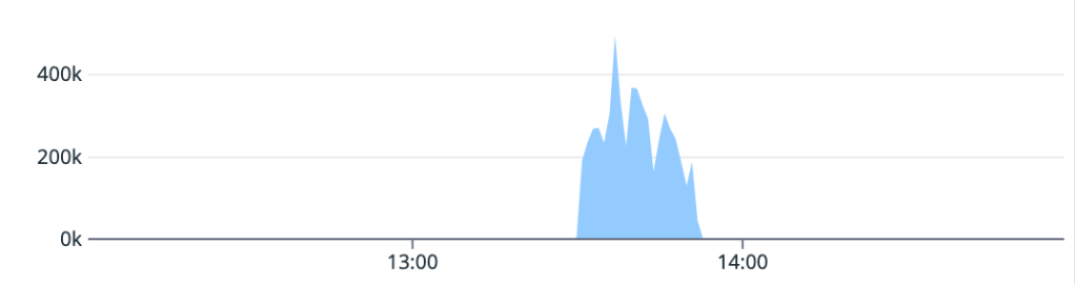 Git操作错误率
Git操作错误率
为什么这些事件会影响其他GitHub服务?
我们希望我们的服务能够尽可能地抵御失败。分布式系统中的故障是不可避免的,但它不应导致跨多个服务的严重中断。我们看到所有这三起事件都普遍恶化。在Git数据库事件中,Git读写是许多GitHub场景的核心,因此延迟和失败的增加导致GitHubActions工作流无法拉取数据或拉取请求不更新。
在GitHub应用程序事件中,对令牌发布的影响也影响了依赖令牌进行操作的GitHup功能。这是GITHUB Actions中每个GITHUB_TOKEN的源代码,以及用于授予GitHubCodespace访问存储库权限的标记。它们也是访问私人GitHub页面的安全方式。当令牌颁发失败时,GitHub Actions和GitHup Codespace无法访问它们需要运行的数据,因此无法启动。
我们正在采取什么行动?
- 我们正在仔细审查内部流程并进行调整,以确保始终安全部署更改。并非所有这些事件都是由生产变化引起的,但我们认为这是一个需要改进的领域。
- 除了标准的事故后分析和审查外,我们正在分析这些事故对各服务的影响程度,以确定我们可以在哪里减少未来类似故障的影响。
- 我们正在努力提高高成本、低容量查询模式的可观察性,以及快速诊断和缓解此类问题的一般能力。
- 我们正在解决Git数据库崩溃问题,该问题目前已导致多起事件。这项工作已经在进行中,我们将继续优先考虑这项工作。
- 我们正在解决数据库故障切换问题,以确保故障切换始终能够在无需干预的情况下完全恢复。
作为我们对透明度承诺的一部分,我们发布了导致我们的GitHub服务性能下降的所有事件的摘要月度可用性报告考虑到最近这些事件的范围和持续时间,我们认为现在与社区一起解决这些问题很重要。五月的报告将包括这些事件和我们掌握的任何进一步的细节,以及关于提高GitHub可用性进展的总体更新。我们坚定地致力于提高现场可靠性,并将继续为实现这一承诺负责。



