十多年前,GitHub.com与当时的许多其他web应用程序一样,都是基于Ruby on Rails开发的,只有一个MySQL数据库来存储大部分数据。
多年来,该架构经历了多次迭代,以支持GitHub的增长和不断发展的弹性需求。例如,我们开始为一些功能存储数据(例如状态)在单独的MySQL数据库中,我们添加了读取副本以将负载分散到多台机器上,并开始使用ProxySQL来减少针对主MySQL实例打开的连接数。
然而,GitHub.com的核心仍然是围绕一个主数据库集群(称为优衣库1)它包含了GitHub核心功能所使用的大部分数据,如用户配置文件、存储库、问题和请求。
随着GitHub的发展,这不可避免地带来了挑战。我们努力保持我们的数据库系统足够大,总是转移到更新和更大的机器上以扩大规模。任何负面影响的事件mysql1将影响在此群集上存储其数据的所有功能。
2019年,为了应对我们面临的增长和可用性挑战,我们制定了一项计划,以改进我们的工具和划分关系数据库的能力。可以想象,这是一个复杂的挑战,需要引入和创建如下所述的各种工具。
我们在2021年看到的结果是,存储数据的数据库主机上的负载减少了50%mysql1这大大减少了数据库相关事件的数量,提高了GitHub.com对所有用户的可靠性。
我们引入的第一个概念是数据库模式的虚拟分区。在物理移动数据库表之前,我们必须确保它们是分开的实际上在应用程序层,这必须在不影响团队处理新的或现有特性的情况下进行。
为此,我们将属于一起的数据库表分组到模式域中,并使用SQL linter在域之间加强边界。这允许我们稍后安全地对数据进行分区,而不会以跨分区的查询和事务结束。
架构域是我们用来实现虚拟分区的工具。模式域描述了一组紧密耦合的数据库表,这些表经常在查询(例如,当使用表联接或子查询时)和事务中一起使用。例如胃肠道间质瘤模式域包含支持GitHub Gist特性的所有表–like的胃肠道间质瘤,注册表注释和星级酒店桌子。既然他们属于一起,就应该呆在一起。模式域是对其进行编码的第一步。
模式域设置了明确的边界,并在某些时候暴露了特性之间的依赖关系。在Rails应用程序中,信息存储在一个简单的YAML配置中,该配置位于数据库/schema-domains.yml。下面是一个说明该文件内容的示例:
要点:-注册表注释-注册表-星级酒店存储库:-问题-拉动_请求-存储库用户:-化身-gpg密钥-公共密钥-用户
linter确保此文件中的表列表与我们的数据库模式匹配。反过来,相同的linter强制为每个表分配一个模式域。
在架构域的基础上,两个新的SQL linter加强了域之间的虚拟边界。它们通过添加查询注释并将其视为例外来识别跨架构域的任何违反查询和事务。如果一个域没有冲突,那么它实际上是分区的,可以物理地移动到另一个数据库集群。
查询过梁验证同一数据库查询中只能引用属于同一架构域的表。如果它检测到来自不同域的表,则会抛出异常并显示一条有用的消息,以供开发人员避免此问题。
由于linter仅在开发和测试环境中启用,因此开发人员在开发过程的早期会遇到违规错误。此外,在CI运行期间,过梁确保不会意外引入新的违规行为。
linter可以通过用特殊注释注释SQL查询来抑制异常:/*跨架构-域-查询-免除*/
我们甚至为ActiveRecord构建并上传一种新方法为了更容易添加这样的评论:
Repository.joins(:owner).nannotate(“cross-schema-domain-query-exempted”)#=>选择*FROM`repositories`INNER JOIN`users`ON`users`。`id`=`repositories.owner_id`/*跨schema-domain-query-exempted*/
通过注释所有导致失败的查询,可以构建需要修改的积压查询。以下是我们常用的两种方法来消除豁免:
- 有时,可以通过触发单独的查询而不是联接表来轻松解决豁免问题。一个例子是使用
活动记录的预加载方法而不是包括.另一个挑战是has_many:通过导致加入跨不同架构域的表。为此,我们开发了通用解决方案也升级到Rails:has_many(有很多)现在有一个禁用联接 通知活动记录不执行任何操作的选项加入跨基础表的查询。相反,它会运行几个传递主键值的查询。
-
将数据连接到应用程序中而不是数据库中是另一种常见的解决方案。例如,更换内部连接语句,其中包含两个单独的查询,而不是在Ruby中执行“union”操作(例如,A.pull(:b_id)和b.其中(id:…)).
在某些情况下,这会导致令人惊讶的性能改进。根据数据结构和基数,MySQL的查询规划器有时可以创建次优的查询执行计划,而应用程序端连接的性能成本更稳定。
与几乎所有与可靠性和性能相关的更改一样,我们将其发布在后面科学家实验它为请求子集执行旧的和新的实现,允许我们评估每个更改的性能影响。
除了查询之外,事务也是一个问题。现有的应用程序代码是根据特定的数据库模式编写的。MySQL事务保证了数据库中表之间的一致性。如果事务包含对将移动到单独数据库的表的查询,那么它将无法保证一致性。
为了了解需要审查哪些事务,我们引入了一个事务过梁。与查询linter类似,它验证给定事务中一起使用的所有表是否属于同一模式域。
此短绒在生产中大量采样,以将性能影响降至最低。收集和分析linting结果以了解大多数跨域事务发生的位置,从而允许我们决定更新某些代码路径或调整数据模型。
在事务一致性保证至关重要的情况下,我们将数据提取到属于同一模式域的新表中。这可以确保它们保持在同一数据库集群上,从而继续保持事务一致性。这种情况经常发生在多态表存储来自不同模式域的数据(例如反应存储问题、请求、讨论等不同功能的记录的表)
虚拟隔离的架构域可以物理地移动到另一个数据库集群。为了动态地移动表,我们使用了两种不同的方法:Vites和自定义的write-cutover进程。
维特斯是MySQL之上的一个扩展层,有助于切分需求。我们使用它垂直切分功能在生产中不停机地将多组表移动到一起。
为此,我们部署了VitesVT门在我们的Kubernetes集群中。这些VTGate进程成为应用程序要连接到的端点,而不是直接连接到MySQL。它们实现了相同的MySQL协议,与应用程序端没有区别。
VTGate进程知道Vites设置的当前状态,并通过另一个Vites组件与MySQL实例对话:VT平板电脑。在幕后,Vitess的桌子移动功能由V复制,它在数据库集群之间复制数据。
因为在2020年初,Vites的采用仍处于早期阶段,我们开发了一种替代方法,可以一次性移动大型桌子。这降低了依赖单一解决方案来确保GitHub.com持续可用的风险。
我们使用MySQL的常规复制功能将数据提供给另一个集群。最初,新集群被添加到旧集群的复制树中。然后,脚本会快速执行一系列更改以实现剪切。
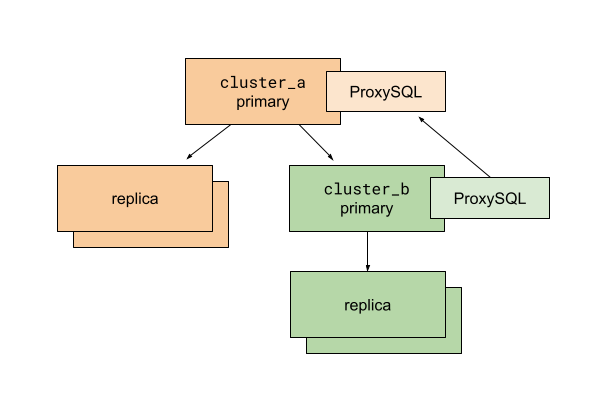 执行write-cutover进程之前的MySQL数据库集群设置
执行write-cutover进程之前的MySQL数据库集群设置
在运行脚本之前,我们准备应用程序和数据库复制,以便目标集群调用群集_b是现有的集群a.代理SQL用于多路复用客户端连接到MySQL主目录。上的ProxySQL实例集群b配置为将所有流量路由到集群a初级。ProxySQL的使用允许我们快速更改数据库流量路由,并且对数据库客户端(在我们的示例中是Rails应用程序)的影响最小。
通过此设置,我们可以将数据库连接移动到群集_b没有分裂任何东西。所有读取流量仍然流向从集群a初级。所有写流量都保持在集群a初级的。
在这种情况下,我们运行一个cutover脚本,执行以下操作:
- 为启用只读模式
集群a初级。此时,所有写入集群a和群集_b被阻止。所有试图写入这些数据库主数据库的web请求都会失败并导致500次。
- 读取上次执行的MySQL GTID来自
集群a初级。
- 轮询
群集_b主要用于验证最后执行的GTID是否已到达。
- 停止上的复制
群集_b主要来自集群a.
- 更新上的ProxySQL路由配置
群集_b将交通引导至集群b初级。
- 禁用的只读模式
集群a和群集_b初选。
- 庆祝一下!
经过充分的准备和练习,我们了解到,对于最繁忙的数据库表,这六个步骤只需几十毫秒即可执行。由于我们在一天中流量最低的时间执行这种切换,因此只会因为写入失败而导致少数用户加速错误。这种方法的结果比我们预期的要好。
write-autover进程用于拆分优衣库1,我们原来的主数据库集群。我们一次移动了130张最繁忙的表,这些表支持GitHub的核心功能:存储库、问题和请求。这一过程是作为一种风险缓解策略创建的,以便我们可以使用多种独立的工具。此外,由于部署拓扑和读写支持等因素,我们并没有在任何情况下都选择Vites作为移动数据库表的工具。不过,我们预计将来有机会将其用于大多数数据迁移。
主数据库集群mysql1介绍中提到,GitHub的许多最重要的功能(如用户、存储库、问题和pull请求)使用了大量数据。自2019年以来,我们实现了扩展此关系数据库的能力,结果如下:
- 2019年,
mysql1平均每秒回答950000个查询,副本上回答900000个查询,主服务器上回答50000个查询。
- 现在,在2021年,相同的数据库表分布在多个集群中。在两年内,他们看到了持续增长,逐年加速。这些集群的所有主机平均每秒回答1200000个查询(副本上1125000个查询,主服务器上75000个查询)。与此同时,每个主机上的平均负载减少了一半。
负载减少大大减少了数据库相关事件的数量,并提高了GitHub.com对所有用户的可靠性。
除了垂直分区来移动数据库表外,我们还使用水平分区(也称为分片)。这允许我们跨多个集群拆分数据库表,从而实现更可持续的增长。我们将在未来的博客文章中详细介绍与此相关的工具、linter和Rails改进。
在过去10年里,GitHub一直在学习根据需要进行扩展。我们经常选择利用已经证明在我们的规模下有效的“枯燥”技术,因为可靠性仍然是首要考虑的问题。但是,经过业界验证的工具与对生产代码及其依赖项的简单更改相结合,为我们未来数据库的持续增长提供了一条道路。



