一种新的基于叠加ELM和CCA方法的多模态生物特征识别模型

摘要
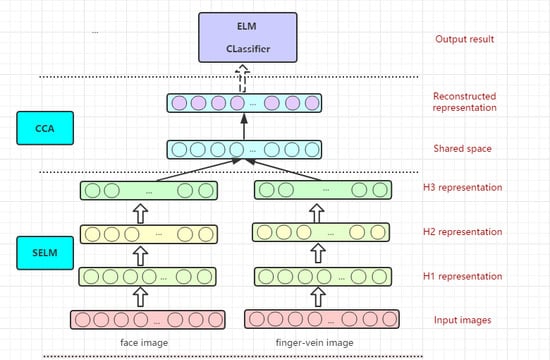
1.简介
2.材料和方法
2.1. 相关工作
2.1.1. ELM方法
2.1.2. CCA方法
2.2. 建议的方法
2.2.1. 堆叠ELM模型
2.2.2. 多生物量识别的S-E-C模型
3.结果
3.1. 数据库
3.1.1. 奥利维蒂研究实验室(ORL)人脸数据集
3.1.2. 人脸识别技术(FERET)人脸数据集
3.1.3. MMCBNU-6000 Finger-Vein数据集
(a) ORL+MMCBNU:共400组,每组采集10张人脸图像和60张指骨图像; (b) FERET+MMCBNU:共1000组,每组拍摄7张面部图像和60张指印图像。
3.2. 实验环境
3.3. 实验结果与分析
3.3.1. 能够表示堆叠ELM的隐藏层特征
3.3.2. CCA融合方法的分类效果比较
3.3.3. 不同方法在不同隐层节点上的实验性能
3.3.4. 参数对识别准确性的影响
4.讨论
鸣谢
作者贡献
利益冲突
工具书类
帕卡维,R。; K.R.C.巴布。; Kumar,J.A.用于用户身份验证的多模态生物识别。 《智能系统与控制国际会议论文集》,印度哥印拜陀,2017年1月5日至6日; 第501-505页。 [ 谷歌学者 ] Oquab,M。; 博图,L。; 拉普特夫,I。; Sivic,J.使用卷积神经网络学习和传输中级图像表示。 《IEEE计算机视觉和模式识别会议论文集》,美国俄亥俄州哥伦布,2014年6月23日至28日; 第1717-1724页。 [ 谷歌学者 ] 刘,Y。; X·冯。; Zhou,Z。使用堆叠收缩自动编码器的多模式视频分类。 信号处理。 2016 , 120 , 761–766. [ 谷歌学者 ] [ 交叉参考 ] Ngiam,J。; 科斯拉,A。; Kim,M.多模式深度学习。 2011年6月28日至7月2日在美国华盛顿州贝尔维尤举行的第28届国际机器学习会议记录; 第689-696页。 [ 谷歌学者 ] 北斯利瓦斯塔瓦。; Salakhutdinov,R.用深度信念网学习多模态数据的表示。 《机器学习研讨会国际会议论文集》,英国爱丁堡,2012年6月26日至7月1日。 [ 谷歌学者 ] 黄,G.B。; 朱Q.Y。; Siew,C.K.极限学习机:一种新的前馈神经网络学习方案。 2004年7月25日至29日在匈牙利布达佩斯举行的IEEE国际神经网络联合会议记录; 第985-990页。 [ 谷歌学者 ] 黄,G.B。; 朱Q.Y。; Siew,C.K.极限学习机器:理论与应用。 神经计算。 2006 , 70 , 489–501. [ 谷歌学者 ] [ 交叉参考 ] 保罗,P.P。; 加夫里洛娃,M.L。; Alhajj,R.使用社会网络分析的多模态生物特征识别决策融合。 IEEE传输。 系统。 曼赛本。 系统。 2017 , 44 , 1522–1533. [ 谷歌学者 ] [ 交叉参考 ] Haghighat,M。; Abdel-Mottaleb,M。; Alhalabi,W.特征级融合的判别相关性分析及其在多模态生物特征识别中的应用。 2016年IEEE声学、语音和信号处理国际会议论文集,2016年3月20日至25日,中国上海; 第1984-1996页。 [ 谷歌学者 ] 黄,G.B。; 王,D.H。; Lan,Y.极限学习机器:一项调查。 国际J·马赫。 学习。 赛博。 2011 , 2 , 107–122. [ 谷歌学者 ] [ 交叉参考 ] 谢,Z。; Xu,K。; Shan,W.多视图深度图像3D形状的投影特征学习。 在 计算机图形论坛 ; 约翰·威利父子公司:英国奇切斯特,2015年; 第34卷,第1-11页。 [ 谷歌学者 ] Akusok,A。; 比约克,K.M。; Miche,Y.高性能极端学习机器:大数据应用的完整工具箱。 IEEE接入 2015 , 三 , 1011–1025. [ 谷歌学者 ] [ 交叉参考 ] Hoteling,H.两组变量之间的关系。 生物特征 1936 , 28 , 321–377. [ 谷歌学者 ] [ 交叉参考 ] Borga,M.标准相关性教程。 2011.在线提供: https://web.cs.hacettepe.edu.tr/ ~aykut/classes/spring2013/bil682/supplemental/CCA_tutorial.pdf (2018年2月10日访问)。 哈东,D.R。; 塞德马克,S。; Shawe-Taylor,J.典型相关分析:学习方法应用概述。 神经计算。 2014 , 16 , 2639–2664. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 高,X。; 孙,Q。; Yang,J.MRCCA:一种基于CCA的新方法及其在矩阵数据特征提取和融合中的应用。 申请。 软计算。 2017 , 62 , 45–56. [ 谷歌学者 ] [ 交叉参考 ] 杨,X。; 刘伟。; Tao,D.二视图图像识别的典型相关分析网络。 信息科学。 2017 , 385 , 338–352. [ 谷歌学者 ] [ 交叉参考 ] 欧阳,W。; 朱,X。; Wang,X.人体姿势估计的多源深度学习。 《IEEE计算机视觉和模式识别会议论文集》,美国俄亥俄州哥伦布,2014年6月23日至28日; 第2329-2336页。 [ 谷歌学者 ]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}