基于加权模型平均的中国土壤总氮精细分辨率制图



摘要
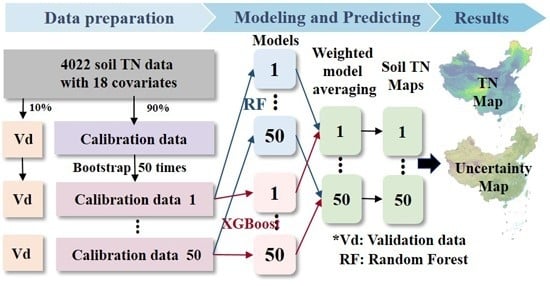
1.简介
2.材料和方法
2.1. 土壤数据
2.2. 环境协变量
2.3. 模型开发
2.3.1. 机器学习方法
2.3.2. 加权模型平均
2.3.3. 模型校准和验证
2.4. 不确定性评估
2.5. 单因素方差分析(ANOVA)检验
3.结果
3.1. 协变量的重要性
3.2. 方法评估
3.3. 土壤TN制图及其不确定性
3.4. 不同土壤类型和土地利用类型的土壤全氮
4.讨论
4.1. 预测的质量
4.2. 土壤TN的空间分布
4.3. 土壤TN预测的不确定性
4.4. 土地利用对土壤TN含量的影响
4.5. 局限性和观点
5.结论
使用这两个模型的加权平均值,得到了一个合理的结果,RMSE最低(1.15 g·kg −1 )和最高R 2 (0.41)与单个模型相比,这解释了41%的土壤TN含量的空间差异,并降低了预测的不确定性。 TN图显示出高度的空间异质性,空间变异受气候、地形和生物等变量的影响。 空间趋势与之前的TN图相似,分辨率较低,青藏高原东部和中国东北部TN较高,沙漠地区TN较低。 不确定性地图可以帮助决策者和利益相关者了解我们研究中绘制的地图的可靠性。 应该指出,通过使用更多的协变量或补充未来土壤剖面的数量,可以减少不确定性。
补充资料
作者贡献
基金
致谢
利益冲突
工具书类
辛菲尔德,J.V。; 法格曼,D。; Colic,O.耕地土壤中宏观营养物质实时检测的传感技术评估。 计算。 电子。 农业。 2010 , 70 , 1–18. [ 谷歌学者 ] [ 交叉参考 ] 里夫斯,M。; 拉尔·R。; 洛根,T。; Sigarán,J.土壤氮和碳对玉米种植系统、氮源和耕作的响应。 土壤科学。 美国社会期刊。 1997 , 61 , 1387–1392. [ 谷歌学者 ] [ 交叉参考 ] 维图塞克,P.M。; Porder,S。; B.Z.霍尔顿。; Chadwick,O.A.《陆地磷限制:机制、影响和氮磷相互作用》。 经济。 应用。 2010 , 20 , 5–15. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] [ 绿色版本 ] 莱德利,T.S。; 圣奎斯特,E.T。; 施瓦茨,S.E。; 霍尔,D.K。; 研究员,J.D。; 基林,T.L.,气候变化和温室气体。 EOS事务处理。 美国地球物理学。 2013 , 80 , 453–458. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] Li,C.S.《量化土壤温室气体排放:科学基础和建模方法》。 土壤科学。 植物营养。 2007 , 53 , 344–352. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] Carpenter,S.R。; 北卡罗来纳州卡拉科。; 科雷尔,D.L。; 霍沃思,R.W。; 夏普利,A.N。; Smith,V.H.,地表水磷和氮的非点源污染。 经济。 应用。 1998 , 8 , 559–568. [ 谷歌学者 ] [ 交叉参考 ] Batjes,N.H.世界土壤中的总碳和氮。 欧洲土壤科学杂志。 1996 , 47 , 151–163. [ 谷歌学者 ] [ 交叉参考 ] Arrouays,D。; Deslais,W。; Badeau,V.法国表层土的碳含量及其地理分布。 土壤使用管理。 2001 , 17 , 7–11. [ 谷歌学者 ] [ 交叉参考 ] McBratney,A.B。; 桑托斯,M.L.M。; Minasny,B.关于数字土壤制图。 Geoderma公司 2003 , 117 , 3–52. [ 谷歌学者 ] [ 交叉参考 ] H·詹妮。 土壤形成因素 ; 麦格劳·希尔:美国纽约州纽约市,1941年。 [ 谷歌学者 ] 王,S。; 王,X。; 欧阳,Z。中国北方密云水库上游流域土地利用、气候、地形和土壤性质对区域土壤有机碳和总氮的影响。 J.环境。 科学。 2012 , 24 , 387–395. [ 谷歌学者 ] [ 交叉参考 ] 乔,J。; Zhu,Y。; 贾,X。; 黄,L。; 邵,M。中国黄土高原临界区土壤全氮和全磷的垂直分布。 卡特纳 2018 , 166 , 310–316. [ 谷歌学者 ] [ 交叉参考 ] 塞利格,T。; Böhner,J。; Schmidhalter,U.在多元回归建模程序中使用高光谱图像和现场数据进行高分辨率表土制图。 Geoderma公司 2006 , 136 , 235–244. [ 谷歌学者 ] [ 交叉参考 ] 王凯。; 张,C。; Li,W.区域尺度下土壤总氮预测制图:地理加权回归和协克里格法的比较。 申请。 地质师。 2013 , 42 , 73–85. [ 谷歌学者 ] [ 交叉参考 ] Elbasiouny,H。; Abowaly,M。; Abu_Alkhier,A。; Gad,A.在埃及尼罗河三角洲北部地区使用普通克里金方法研究土壤碳和氮库的空间变化。 卡特纳 2014 , 113 , 70–78. [ 谷歌学者 ] [ 交叉参考 ] Kou博士。; 丁J.Z。; 李,F。; 魏,N。; 方,K。; Yang,G。; 张,B。; 刘,L。; 秦,S。; 陈,Y。; 等。西藏高山多年冻土区土壤氮储量的空间显式估计及其对土地模型的影响。 科学。 总环境。 2019 , 650 , 1795–1804. [ 谷歌学者 ] [ 交叉参考 ] Shahbazi,F。; 休斯,P。; McBratney,A.B。; 米纳斯尼,B。; Malone,B.P.评估伊朗西北部重要农业营养素——氮、磷和硼的空间和垂直分布。 卡特纳 2019 , 173 , 71–82. [ 谷歌学者 ] [ 交叉参考 ] B.E.汉森。 经济计量学 ; 威斯康星大学经济系:威斯康星州麦迪逊,美国,2019年; 第846页。 在线可用: http://www.ssc.wisc.edu/ ~bhansen/计量经济学/ (2019年8月19日访问)。 王,S。; 庄,Q.L。; 王,Q.B。; 金,X。; Han,C.绘制中国辽宁省土壤有机碳和土壤总氮储量图。 Geoderma公司 2017 , 305 , 250–263. [ 谷歌学者 ] [ 交叉参考 ] 王,S。; 金,X。; 阿迪卡里,K。; 李伟(Li,W.)。; Yu,M。; 卞,Z。; Wang,Q.从中国东北部的一个地点绘制土壤总氮地图。 卡特纳 2018 , 166 , 134–146. [ 谷歌学者 ] [ 交叉参考 ] 周,Y。; 韦伯斯特,R。; 维斯卡拉·罗塞尔,R.A。; 施,Z。; Chen,S.西藏20世纪80年代土壤有机碳基线图及其不确定性。 Geoderma公司 2019 , 334 , 124–133. [ 谷歌学者 ] [ 交叉参考 ] 努斯鲍姆,M。; 斯皮斯,K。; Baltensweiler,A。; 格罗布,美国。; 凯勒,A。; 格雷纳,L。; Schaepan,医学博士。; Papritz,A.使用大组环境协变量评估数字土壤制图方法。 土壤 2018 , 4 , 1–22. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 陈,S.C。; 梁振中。; 韦伯斯特,R。; 张,G.L。; 周,Y。; H.F.滕。; 胡,B.F。; Arrouays,D。; Shi,Z.通过稀疏土壤数据和环境协变量的混合建模绘制的中国土壤pH值的高分辨率地图及其对污染的影响。 科学。 总环境。 2019 , 655 , 273–283. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 不列颠哥伦比亚省博姆克。; B.M.格林维尔。 使用R进行实际机器学习 第1版。; CRC出版社:美国佛罗里达州博卡拉顿,2019年; 出版中; 在线可用: https://bradleyboehmke.github.io/主页/ (2019年12月6日访问)。 马龙,B.P。; 米纳斯尼,B。; Odgers,N.P。; McBrantney,A.使用模型平均法结合传统土壤地图和点数据中的土壤特性栅格。 Geoderma公司 2014 , 232–234 , 34–44. [ 谷歌学者 ] [ 交叉参考 ] Xu,Y。; S.E.史密斯。; Grunwaldb,S。; Abd-Elrahman,A。; 瓦尼,S.P。; Nair,V.D.使用遥感光谱指数和回归克立格法估算小农农场环境中的土壤总氮。 卡特纳 2017 , 163 , 111–122. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 徐,G。; Cheng,S。; 李,P。; 李,Z。; 高,H。; Yu,K。; 卢克。; Shi,P。; Cheng,Y。; 赵,B。中国黄土高原一个小流域生态建设条件下筑坝农田的土壤总氮来源。 经济。 工程师。 2018 , 121 , 19–25. [ 谷歌学者 ] [ 交叉参考 ] 赵,Z。; 张,X。; Dong,S。; Wu,Y。; 刘,S。; 苏,X。; 王,X。; Zhang,Y。; Tang,L.中国干旱地区阿尔金山国家级自然保护区高山生态系统土壤有机碳和总氮储量。 环境。 莫尼特。 评估。 2018 , 191 , 40. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 刘,H。; 曹,L。; 曾静。西藏东南部色季拉山沟壑坡地土壤氮素的空间分布。 《经济学报》。 罪。 2016 , 36 , 127–133. [ 谷歌学者 ] 国家土壤调查局。 中国土壤属志 ; 中国农业出版社:北京,中国,1993; 第1卷,(中文)。 国家土壤调查局。 中国土壤属志 ; 中国农业出版社:北京,中国,1994; 第二卷,(中文)。 国家土壤调查局。 中国土壤属志 ; 中国农业出版社:北京,中国,1994; 第三卷(中文)。 国家土壤调查局。 中国土壤属志 ; 中国农业出版社:北京,中国,1995; 第四卷,(中文)。 国家土壤调查局。 中国土壤属志 ; 中国农业出版社:北京,中国,1995; 第五卷,(中文)。 国家土壤调查局。 中国土壤属志 ; 中国农业出版社:北京,中国,1996; 第六卷,(中文)。 Gregorich,E.G。; M.R.卡特。; Angers,D.A。; Monreal,首席执行官。; Ellert,B.H.建立评估农业土壤中土壤有机质质量的最小数据集。 可以。 土壤科学杂志。 1994 , 74 , 367–385. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 毕晓普,T.F.A。; 麦克布拉特尼,A.B。; Laslett,G.M.使用等面积二次平滑样条建模土壤属性深度函数。 Geoderma公司 1999 , 91 , 27–45. [ 谷歌学者 ] [ 交叉参考 ] 马龙,B.P。; 麦克布拉特尼,A.B。; 米纳斯尼,B。; Laslett,G.M.绘制土壤碳储量和有效水容量的连续深度函数。 Geoderma公司 2009 , 154 , 138–152. [ 谷歌学者 ] [ 交叉参考 ] 康拉德,O。; Bechtel,B。; 博克,M。; 迪特里希,H。; Fischer,E。; Gerlitz,L。; 韦伯格,J。; 维奇曼,V。; Böhner,J.自动化地球科学分析系统(SAGA)v.2.1.4。 地质科学。 模型。 开发。 2015 , 8 , 1991–2007. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 塔克,C.J。; Pinzon,J.E。; M.E.布朗。 全球库存建模和映射研究 ; NA94apr15b.n11-VIg,2.0; 马里兰大学全球土地覆盖设施:美国马里兰州大学帕克分校,2004年。 [ 谷歌学者 ] 普林斯,S.D。; 斯莫尔,J。 1981–2000年AVHRR全球生产效率模型 ; 马里兰大学全球土地覆盖设施:美国马里兰州大学帕克分校,2003年。 [ 谷歌学者 ] Goovaerts,P.使用海拔帮助绘制降雨侵蚀力的地质统计图。 卡特纳 1999 , 34 , 227–242. [ 谷歌学者 ] [ 交叉参考 ] 施X.Z。; Yu,D.S。; 华纳,E.D。; 平移,X.Z。; 彼得森,G.W。; 龚,Z.G。; Weindorf,D.C.中国遗传土壤分类系统1:1000000数字土壤调查和参考系统的土壤数据库。 土壤水平。 2004 , 45 , 129–136. [ 谷歌学者 ] [ 交叉参考 ] IUSS工作组WRB。 2014年世界土壤资源参考基地,更新2015年国际土壤分类系统,用于命名土壤和创建土壤地图图例 ; 联合国粮食及农业组织:意大利罗马,2015年。 [ 谷歌学者 ] 施X.Z。; Yu,D.S。; Xu,S.X。; 华纳,E.D。; 王海杰。; 太阳,W.X。; Zhao,Y.C。; 龚志东。中国土壤遗传分类与不同尺度WRB相关的交叉参照。 Geoderma公司 2010 , 155 , 344–350. [ 谷歌学者 ] [ 交叉参考 ] Breiman,L.《随机森林》。 机器。 学习。 2001 , 45 , 5–32. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 弗里德曼,J.H.贪婪函数近似:梯度增强机。 Ann.统计。 2001 , 29 , 1189–1232. [ 谷歌学者 ] [ 交叉参考 ] R核心团队。 R: 统计计算语言与环境 ; R统计计算基金会:奥地利维也纳,2013年。 [ 谷歌学者 ] Kuhn,M.Caret:分类和回归训练。 R软件包版本6.0-84。 2019.在线提供: https://CRAN.R-project.org/package=插入符号 (2019年4月27日访问)。 Friedman,J.Glmnet:Lasso和Elastic-Net正则化广义线性模型。 R软件包版本3.0-2。 2019.在线提供: https://cran.r-project.org/web/packages/glmnet/index.html (2019年12月11日访问)。 国家土壤调查局。 中国土壤 ; 中国农业出版社:北京,中国,1998; (中文)。 费尔南德斯·德尔加多,M。; Cernadas,E。; 巴罗,S。; Amorim,D.我们需要数百个分类器来解决现实世界的分类问题吗? J.马赫。 学习。 物件。 2014 , 15 , 3133–3181. [ 谷歌学者 ] 上官,W。; 戴,Y。; 刘,B。; 朱,A.X。; Q.Y.段。; Wu,L.Z。; 季德扬。; Ye,A.Z。; 袁,H。; 张,Q。; 等。中国土地表面建模土壤特性数据集。 J.高级模型。 地球系统。 2013 , 5 , 212–224. [ 谷歌学者 ] [ 交叉参考 ] Li,Q.Q。; 岳,T.X。; 范,Z.M。; 杜,Z.P。; 陈,C.F。; Lu,Y.M.中国国家尺度表土TN的空间模拟。 地理。 物件。 2010 , 29 , 1981–1992. (中文)[ 谷歌学者 ] Arrouays,D。; Grundy,医学博士。; A.E.哈丁克。; 亨佩尔,J.W。; 尤夫林,G.B.M。; S.Y.洪。; 拉加切里,P。; Lelyk,G。; McBratney,A.B。; 新泽西州麦肯齐。; 等。全球土壤图:走向土壤特性的精细分辨率全球网格。 Agron高级。 2014 , 125 , 93–134. [ 谷歌学者 ] 福列特,R.F。; C.E.斯图尔特。; 普鲁斯纳,E.G。; Kimble,J.M.。气候变化对美国大平原土壤碳氮储量的影响。 J.土壤水利。 2012 , 67 , 331–342. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 徐家川。; 陈,Z.S。; Hsieh,C.F.台湾南部低地雨林土壤特性与坡度位置之间的关系。 Geoderma公司 2004 , 123 , 131–142. [ 谷歌学者 ] [ 交叉参考 ] R.A.麦克米伦。; Moon,D.E。; 库佩,R.A。; Phillips,N.《820万公顷林地的预测生态系统制图》(PEM)。 在 数字土壤制图:衔接研究、环境应用和操作 ; Boettinger,J.L.,Howell,D.W.,Moore,A.C.,Hartemink,A.E.,Kienast-Brown,S.,Eds。; 施普林格:多德雷赫特,荷兰,2010年; 第2卷,第337-356页。 [ 谷歌学者 ] 周,Y。; A.E.哈丁克。; 施,Z。; 梁振中。; Lu,Y.L.中国北方和东北地区土地利用和气候变化对土壤有机碳的影响。 科学。 总环境。 2019 , 647 , 1230–1238. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 梁振中。; 陈,S.C。; Yang,Y.Y。; 赵R.Y。; 施,Z。; Rossel,R.A.V.中国20世纪80年代表层土有机质及其相关不确定性的国家数字土壤地图。 Geoderma公司 2019 , 335 , 47–56. [ 谷歌学者 ] [ 交叉参考 ] 胡,M.Q。; 毛,F。; 孙,H。; Hou,Y.Y.三江源区归一化差异植被指数变化及其与气候因子的相关性研究。 国际期刊申请。 地球观测地理信息。 2011 , 13 , 24–33. [ 谷歌学者 ] [ 交叉参考 ] H.F.滕。; 胡,J。; 周,Y。; 周立群(Zhou,L.Q.)。; Shi,Z.中国土壤侵蚀潜力建模与制图。 J.整合。 农业。 2019 , 18 , 251–264. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 彭J.T。; 李,G.S。; Fu,W.L。; Yi,X.S。; 兰,J.C。; Yuang,B.青海省三江源地区退化草地总氮的时空变化。 环境。 科学。 2012 , 33 , 2490–2496. [ 谷歌学者 ] 陈,S.C。; 马丁,医学博士。; Saby,新泽西州。; 沃尔特,C。; Angers,D.A。; Arrouays,D.法国表层和底层碳封存潜力的精细分辨率地图。 科学。 总环境。 2018 , 630 , 389–400. [ 谷歌学者 ] [ 交叉参考 ] 休伊特,A。; 巴林格,J。; Forrester,G。; McNeill,S.J.《新西兰数字土壤制图的土壤景观基础》。 在 数字土壤制图:衔接研究、环境应用和操作 ; Boettinger,J.L.,Howell,D.W.,Moore,A.C.,Hartemink,A.E.,Kienast-Brown,S.,Eds。; 施普林格:多德雷赫特,荷兰,2010年; 第2卷,第297-307页。 [ 谷歌学者 ] 梁振中。; 陈,S.C。; Yang,Y.Y。; 周,Y。; Shi,Z.中国土壤有机碳的高分辨率三维制图:SoilGrids产品对国家建模的影响。 科学。 总环境。 2019 , 685 , 480–489. [ 谷歌学者 ] [ 交叉参考 ] Murty,D。; Kirschbaum,M.U.F。; R.E.麦克默特里。; McGilvray,A.森林转为农业用地会改变土壤碳和氮吗? 文献综述。 手套。 青稞酒。 生物。 2002 , 8 , 105–123. [ 谷歌学者 ] [ 交叉参考 ] 王晓杰。; 龚志东。中国亚热带地区十一年开垦后土壤质量变化的评估与分析。 Geoderma公司 1998 , 81 , 339–355. [ 谷歌学者 ] [ 交叉参考 ] Wang,Y。; 王,S。; 阿迪卡里,K。; 王,Q.B。; Sui,Y.Y。; Xin,G.耕作历史对东北地区耕地土壤有机碳状况的影响。 大地测量仪 2019 , 342 , 55–64. [ 谷歌学者 ] [ 交叉参考 ] 赵文忠。; Xiao,H.L。; 刘,Z.M。; Li,J.中国北方半干旱坝上地区土地利用变化对土壤退化和恢复的影响。 卡特纳 2005 , 59 , 173–186. [ 谷歌学者 ] [ 交叉参考 ] 郭,L.B。; Gifford,R.M.土壤碳储量和土地利用变化:一项综合分析。 手套。 青稞酒。 生物。 2002 , 8 , 345–360. [ 谷歌学者 ] [ 交叉参考 ] 萨哈尼,美国。; Behera,N.森林砍伐对热带土壤物理化学特性、微生物生物量和微生物活性的影响。 土地退化。 开发。 2001 , 12 , 93–105. [ 谷歌学者 ] [ 交叉参考 ] Berihu,T。; Girmay,G。; Sebhatleab,M。; Berhane,E。; Zenebe,A。; Sigua,G.C.埃塞俄比亚森林砍伐后的土壤碳氮损失。 阿格隆。 维持。 开发。 2017 , 37 , 1. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 胡,Y。; 张学忠。; 毛,R。; Gong,D.Y。; 刘,H.B。; Yang,J.模拟了1980年代至2000年代中国东部夏季气候对实际土地利用/覆盖变化的响应。 地球物理学杂志。 Res.大气。 2015 , 120 , 167–179. [ 谷歌学者 ] [ 交叉参考 ] Zinda,J.A。; Trac,C.J。; 翟,D。; Harrell,S.《退耕还林工程中的双功能森林与中国环境政策的灵活性》。 地理论坛 2016 , 78 , 119–132. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] Song,Y。; 姚,Y.F。; 秦,X。; Wei,X.R。; 贾,X.X。; Shao,M.G.在两种无机碳浓度不同的半干旱农田土壤上,碳和氮对0-5m深度造林的响应。 大地测量仪 2020 , 357 , 113940. [ 谷歌学者 ] [ 交叉参考 ] 姜瑜。; Rao,L。; Sun,K。; 韩,Y。; Guo,X.鄱阳湖生态经济区(华南)土壤氮的时空分布。 科学。 总环境。 2018 , 626 , 235–243. [ 谷歌学者 ] [ 交叉参考 ] 1999年中国统计年鉴。 在线可用: http://www.stats.gov.cn/yearbook/indexC.htm (1999年9月20日查阅)。 Ju,X.T。; 邢,G.X。; 陈,X.P。; Zhang,S.L。; 张,L.J。; 刘晓杰。; 崔,Z.L。; 尹,B。; 克里斯蒂,P。; 朱,Z.L。; 等。通过改善中国集约农业系统中的氮管理来降低环境风险。 程序。 国家。 阿卡德。 科学。 美国 2009 , 106 , 8077. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 邢,G.X。; Zhu,Z.L.中国及其主要流域的区域氮预算。 生物地球化学 2002 , 57 , 405–427. [ 谷歌学者 ] [ 交叉参考 ]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}