1.简介
精确的土地利用/土地覆盖(LULC)地图的制作在遥感领域提供了独特的监测能力[1]. LULC地图被用于多种应用,从环境监测、土地变化检测、自然灾害评估到农业和水/湿地监测[2]; 因此,准确、及时地制作LULC地图具有重要意义。LULC地图通常由两个主要程序生成:人眼的照片判读,这既耗时又耗资源,不适合大面积的操作性LULC地图;第二,利用遥感数据和不同的分类算法进行自动制图。 高质量卫星遥感数据的可用性和快速更新在提供最新和准确的土地覆盖信息方面取得了巨大进展。特别是,多光谱图像是构建LULC地图的重要资源,允许使用分类算法自动生成。尽管在将监督学习技术用于自动图像分类方面取得了重大进展[三],获取标记的训练集仍然是一个瓶颈[4]. 为了建立准确和稳健的监督分类器,拥有足够大的训练数据集至关重要。通常,问题是不同的土地覆盖类型具有非常不同的区域覆盖水平,这导致其中一些土地覆盖类型在训练数据集中频繁出现,而其他土地覆盖类型则受到限制[5]. 发生这种现象的一个特殊案例是LUCAS数据集:由欧盟委员会统计局(Eurostat)协调的土地利用和覆盖面积框架调查[6]. 自2006年以来,LUCAS调查每三年进行一次,可免费访问。对于本次统计抽样调查,实施了一个2km的常规网格,2015年在欧盟境内观测到超过1000000个点。虽然LUCAS数据集是为统计估计而设计的,但一些现有的研究使用这些数据成功地训练机器学习分类器进行土地覆盖分类[7,8],因为每次观察都是在现场进行经验记录的。这种抽样策略对本研究特别有趣,因为它导致给定区域的数据集中不同土地覆盖类别的表示不均匀。 上述类别分布的不对称性对分类器的性能产生了负面影响。在机器学习社区中,这个问题被称为不平衡学习问题[9]. 不平衡学习问题通常是指在二进制和多类问题中跨类数据的倾斜分布[10]. 尤其是后者,似乎是一项更具挑战性的任务[11]. 在这两种情况下,在学习阶段,少数类对最小化准确性(典型的目标函数)的贡献较小,导致对多数类的偏见。因此,由于典型的分类算法设计用于处理合理平衡的数据集,学习不同类之间的决策边界成为一项非常困难的任务[12]. 处理阶级不平衡问题的可能方法可以分为三大类[13]: 成本敏感的解决方案。他们引入了一个成本矩阵,将较高的误分类成本应用于少数群体的示例。
算法级解决方案。他们修改了算法程序,以加强少数群体的学习。
重新采样解决方案。它们通过从多数类中删除实例或为少数类生成人工数据来重新平衡类分布。
后一种方法构成了一种更通用的方法,因为它可以用于任何分类算法,并且不需要任何类型的领域知识来构建成本矩阵。
有几种重采样解决方案可用于处理不平衡学习问题,也可分为三类:
本文比较了EUROSTAT公开的土地利用/覆盖面积统计调查(LUCAS)数据集上各种过采样算法的性能[14]使用Landsat 8数据。实验过程包括使用五个分类器和三个评估指标对五个过采样进行比较。具体来说,过采样算法是Geometric-SMOTE(G-SMOTE)[15]合成少数过采样技术(SMOTE)[16],边界-SMOTE(B-SMOTE)[17]自适应合成采样技术(ADASYN)[18]和随机过采样(ROS),而没有过采样作为基线方法。结果表明,对于选定的评估指标,G-SMOTE优于其他过采样技术。 本文分为五个部分:第2节分析了重采样方法,第3节描述了建议的方法,第4节显示结果和讨论,以及第5节给出了本研究得出的结论。 2.重新采样方法
通过重采样进行数据修改是解决机器学习特别是遥感中不平衡学习问题的最常用方法[5]. 如上所述,通过将不平衡问题与分类算法解耦,重采样允许用户在完成重采样预处理步骤后应用任何标准算法。这种策略对于不是机器学习专家并且想要使用多个分类器的用户来说特别方便。此外,重采样方法可以自然地应用于多类不平衡数据,这与LULC分类有关。在本节中,我们介绍了重采样方法在非平衡遥感数据分类中最相关的应用。 2.1. 随机重新采样
随机重采样是指从多数类中删除实例或从少数类中复制实例的非知情策略。因此,在不利用任何额外信息的情况下,随机选择数据。
一些现有的遥感研究采用了随机欠采样(RUS)方法[19]随机减少了大多数类训练样本的数量。然而,这种方法有信息丢失的缺点,因为它丢弃了大多数类中的样本[5]. 与RUS相反,ROS是一种可以被视为等同于Bootstrapping的方法,因为它可以避免信息丢失。然而,ROS只是复制随机选择的少数类实例,增加了过度拟合的风险[20]. 参考[21]报告称,使用ROS平衡数据会对不同分类器的分类性能产生不同的影响。在他们的研究中,使用六种不同的模型进行了数据高度不平衡的土地覆盖分类。ROS的应用略微提高了随机森林(RF)和支持向量机(SVM)分类器的性能。另一方面,它降低了决策树(DT)、人工神经网络(ANN)、k近邻(KNN)和增强型DT分类器的分类精度。 2.2. 知情重采样
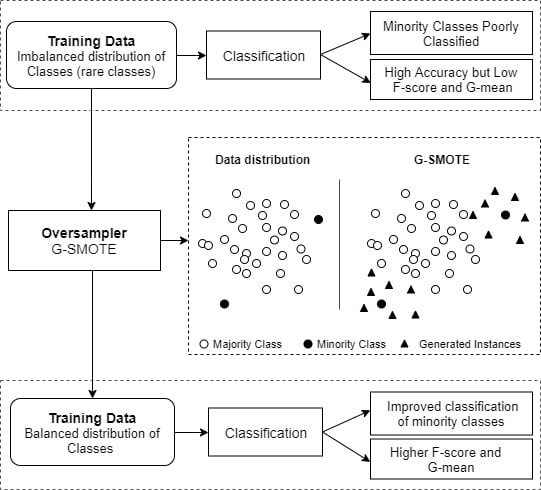
在上述部分中,已经指出了RUS和ROS的缺点。知情的重采样方法旨在克服这些不足。更具体地说,它们使用类分布的本地或全局信息来删除或生成实例。我们的重点是过采样算法,因为LUCAS数据集的大小不利于使用欠采样方法。此外,参考[22]利用旋转森林集成分类器对欠采样和过采样的土地覆盖分类性能进行了比较分析,表明过采样方法优于欠采样方法。 SMOTE是最流行的知情过采样方法,它已被成功地用于处理土地覆盖分类中的类别不平衡问题[23]. 在这种方法中,通过随机选择一个少数类实例,并沿着将其与其一个少数类邻连接起来的线段生成合成示例,对少数类进行过采样。许多研究报告称,使用SMOTE过采样可以显著提高LULC映射精度。例如,由[23]旨在解决LULC映射中的不平衡问题。VSSL是一个由深度生成模型组成的半监督学习框架。它可以在使用SMOTE平衡数据的同时,成功地从标记和未标记样本中学习。在[24]他们使用OpenStreetMap众包数据和Landsat时间序列进行LULC分类。同样,SMOTE的应用也提高了分类结果。SMOTE在遥感中成功应用的其他例子可以在[25,26]. 尽管最近的研究证明了SMOTE在遥感应用中的有用性,但它仍然存在一些缺点。SMOTE算法存在产生噪声数据的缺点[27]. 为了缓解这个问题,开发了许多SMOTE变体。B-SMOTE是最流行的基于SMOTE的过采样器之一。与SMOTE类似,它使用k个-最近邻选择策略。与原始算法的主要区别在于,它通过生成更接近决策边界的样本来修改数据生成机制。据报道,在一些研究中,B-SMOTE的表现也优于SMOTE[28,29]. ADASYN是SMOTE的另一个著名变体。它基于根据少数类实例的加权分布自适应生成少数类实例的思想:与更容易学习的少数类实例相比,更难学习的少数类实例会生成更多的实例[18]. SMOTE算法可以分解为两部分:少数类实例的选择策略和数据生成机制。第一部分是关于噪声实例的生成,因为SMOTE选择策略将所有少数样本视为等价的。上述SMOTE变体(B-SMOTE和ADASYN)旨在解决此问题。另一方面,第二部分负责人工实例的多样性。在某些情况下,SMOTE中使用的线性插值机制会生成几乎重复的实例,这可能会导致过拟合。G-SMOTE算法是SMOTE的扩展,旨在处理这两个问题。G-SMOTE围绕每个少数类实例定义了一个灵活的几何区域,用于合成数据生成。该区域的形状由一组超参数控制。此元素显著增加了生成的实例的多样性。此外,G-SMOTE设计用于避免产生噪声样本,因为它修改了SMOTE选择策略。对于各种分类器和评估指标,G-SMOTE在69个不平衡数据集上的表现优于SMOTE及其上述变体。图1描述了使用变形几何区域的SMOTE和G-SMOTE的数据生成机制。 3.方法
本节描述了G-SMOTE绩效评估过程。对研究区域、数据集、过采样、分类器、评估指标和实验过程进行了描述。图2表示此实验中应用的步骤的流程图。 3.1. 研究区域
研究区域位于葡萄牙西北部,对应于204号轨道和32行Landsat 8图像所覆盖的区域,如所示图3该区域包含LUCAS 2015定义的所有八种主要土地覆盖类型:人工土地、农田、林地、灌木丛、草地、裸地、水和湿地。 3.2. 遥感数据
遥感数据包括来自中等分辨率Landsat 8多光谱传感器的八幅图像。图像为二级表面反射率产品(OLI/TIRS);从2015年2月至9月,每月采集一张图像。采集模式正在下降。数据经过预处理,以去除云层覆盖的像素。每个图像中只使用了条带2、3、4、5、6和7。因此,LUCAS数据集中的每个参考点都有48个特征,代表每个图像每个光谱带的像素值。
3.3. LUCAS数据集
2015年LUCAS数据被用作模型训练和验证的参考数据。LUCAS点标签表示通过实地观测和高分辨率照片解释收集的同质类1.5米半径范围内和异质类(如灌木林)20米半径范围内的相应土地覆盖/利用类型(“扩展窗口”)[6]. 为了减少陆地卫星像素信息在野外被错误表示的风险,我们只保留了近距离(<100米)原位观测的点。出于同样的目的,我们删除了观测中具有线性特征的点(例如道路)。该程序完全不适用于“人造土地”类别,因为这会去除大部分样本。此外,Landsat数据中具有多云像素的点也被排除在外。这样,在2060个LUCAS积分中保留了1694个。该数据集包含八个类别,代表研究区域的主要土地覆盖类型。 该像素选择排除了大量不可接受的参考点,我们假设其余的参考点足以代表陆地卫星像素覆盖面积为30×30m的土地覆盖类型。此外,我们推测,如果这些像素在数据集中仍然可用,那么分类器能够克服由具有混合土地覆盖表示的像素引起的噪声。
每个类别的样本数量和不平衡率(IR),定义为多数类别的样本数量与任何少数类别的样本数量的比率,如表1. 表2介绍了LUCAS数据集的描述,包括关于大多数类别C和最小少数类别H的信息,以强调数据集的不平衡特征: 3.4. 评估指标
在分类器性能评估的可能选择中,准确性、用户的准确性(或精密度)和生产商的准确性(或召回)是LULC分类中最常见的[30,31]. 对于二进制分类任务,它们的计算是根据真正数给出的,真阴性,误报和假阴性[30]. 更具体地说,和对于多类情况,使用类之间的平均值,如下所述。 LUCAS数据集是高度不平衡的,不同少数群体的IR范围很广。因此,使用上述指标不是一个合适的选择,因为它们主要由大多数类别的贡献决定[32]. 适当的评估指标应考虑所有类别的分类准确性。对于多类情况,一种简单的方法是选择一个二进制类评估度量;将其应用于多类问题的每个二进制子任务,即考虑每个类与其余类的比较;最后,求其平均值。为此,F分数和G平均值指标被用作主要评估方法,而准确性供讨论: - -
这个准确性是正确分类的样本数除以所有样本的总和。假设各个类都由索引标记c(c),准确性由以下公式得出: - -
这个F分数是的调和平均值精密度和召回. The
F分数对于多类情况,可以使用每个类的平均值计算[32]: - -
这个G平均值是的几何平均值敏感和特异性.敏感与召回虽然特异性由公式给出因此,它们分别等于真正率和真负率。这个G平均值对于多类情况,可以使用它们的每个类的平均值来计算:
3.5. 机器学习算法
本文的主要目的是展示G-SMOTE在遥感应用的多类高度不平衡数据上使用时的有效性,并将其性能与其他过采样方法进行比较。实验中使用了四种过采样算法以及G-SMOTE。选择ROS是因为它简单。SMOTE被选为使用最广泛的过采样器。ADASYN和B-SMOTE被选为代表原始SMOTE算法的流行修改。最后,没有采用过采样作为额外的基线方法。
为了评估过采样方法,分类器逻辑回归(LR)[33],k-最近邻(KNN)[34],决策树(DT)[35],梯度增压分类器(GBC)[36]、和随机林(RF)[37]已选定。分类器的选择是根据以下标准进行的:学习类型、培训时间和在遥感社区中的受欢迎程度。所有这些算法的计算效率都很高,通常用于所提议的任务,但LR除外,它很少用于遥感应用[2,21]. 3.6. 实验设置
为了评估每个过采样器的性能,形成了过采样器、分类器和度量的每个可能组合。通过n个-折叠交叉验证程序在开始训练每个分类器之前,以及在每个阶段的n个-折叠交叉验证程序,合成数据使用过采样器根据训练数据生成的褶皱,从而产生训练集变得非常平衡。这个增强的训练集反过来用于训练分类器。分类器的性能评估是根据验证数据进行的剩余褶皱的,虽然D类表示数据集。将上述过程重复三次,并对结果进行平均。
3.7. 软件实施
实验过程的实现基于Python编程语言,使用Scikit-Learn[38],不平衡-学习[39]和Geometric-SMOTE库。所有函数、算法、实验和报告的结果都在项目的GitHub存储库中提供。此外,Research-Learn库还提供了一个框架来实施比较实验,并与Scikit-Learn生态系统完全集成。 4.结果和讨论
本节介绍了LUCAS数据集上过采样的比较结果和分析。显示了实验中使用的过采样器和分类器的所有组合的分类结果。下一小节将详细介绍其解释。
4.1. 结果
对于分类器和度量的每个组合,中提供了所有过采样器的交叉验证分数表4。每行的最高分数突出显示: 每种过采样方法都有一个排名分数,表现最好和最差的方法分别得到1分或6分。表5呈现每个分类器和评估度量的排名分数。每行的最高排名突出显示: 对于度量和分类器的每个组合,G-SMOTE与NONE、ROS和SMOTE之间的百分比差异分别通过以下公式计算得出: 对于过采样器、分类器和度量的每个组合,上述公式的正值(负值)表示G-SMOTE相对于过采样器的相对性能增益(损失)。表6显示了上述计算的结果: Wilcoxon签名等级测试被用作配对学生t吨-当两个样本之间的差异分布不能假设为正态分布时进行测试。在我们的案例中,它被应用于检验无效假设,即G-SMOTE的分数和剩余过采样方法的分数之间的成对差异在零附近遵循对称分布;即,G-SMOTE的表现与他们类似。的值准确性在NONE情况下不包括度量,而对于其余的过采样方法,则使用所有度量。这一选择将在下一节中说明。表7显示第页-Wilcoxon试验值: 4.2. 讨论
发件人表4,我们可以观察到G-SMOTE在这两方面都优于所有其他过采样方法F分数和G平均值所有分类器上的度量。当G-SMOTE与LR和RF相结合时,可以获得绝对最佳的结果。重要的是要注意准确性分数显示了众所周知的对大多数阶级的偏见,如第3.4节。在数据集不平衡的多类分类问题中,所有类别的预测与许多遥感应用同等重要,准确性与更稳健的指标相比,应该是次要的,例如F分数和G平均值然而,即使对于准确性度量,G-SMOTE显示了过采样器中的最佳性能。 在表5给出了过采样器的排名,显示了G-SMOTE的优越性。虽然ROS和SMOTE是遥感应用中最流行的过采样方法,但从表中可以清楚地看出,它们产生的结果不是最佳的。表6直接比较G-SMOTE与ROS和SMOTE的性能,也包括NONE作为基线方法。 表7,提供了对先前结论的统计确认。使用Wilcoxon符号秩检验,在显著性水平为. 本研究首次对遥感中的过采样算法进行了系统比较。然而,之前的几项研究报告的结果与我们的发现一致。参考[25]报告增加了F分数和G-平均值应用过采样时,而准确性没有改善。类似地,在[5]证明了使用SMOTE时提高了分类性能。根据我们的实验,使用G-SMOTE可以进一步提高性能。其他一些研究[21,23]没有使用特定的不平衡指标;因此,它们不能直接与我们的结果进行比较。 5.结论
本文使用高度不平衡的多类数据集(LUCAS),将一种新的过采样算法G-SMOTE应用于LULC分类问题。对G-SMOTE的性能进行了评估,并与其他过采样方法进行了比较。更具体地说,ROS、SMOTE、B-SMOTE和ADASYN是选定的过采样器,而LR、KNN、DT、GBC和RF被用作分类器。
实验结果表明,使用G-SMOTE可以显著提高分类性能,导致较高的F分数和G平均值因此,当准确预测少数群体与准确预测多数群体同等或更重要时,读者应考虑使用G-SMOTE。上述案例包括土地覆盖变化检测和稀有土地覆盖类型分类。
G-SMOTE对于遥感研究人员和从业者来说是一个有用的工具,因为它在系统上优于目前广泛使用的过采样器。用户可以通过开源实现轻松访问G-SMOTE。
作者贡献
概念化,F.B。;方法论,G.D。;软件,G.D。;验证、F.B.、G.D。;形式分析,J.F.和M.K。;书面原稿编制,M.K.,J.F。;写作审查和编辑,F.B.、G.D.、J.F.和M.K。;监管,F.B。;资金收购,F.B。
基金
本研究由“Fundaçao para a Ciéncia e Tecnologia”(葡萄牙)资助,批准号为PCIF/SSI/0102/2017和DSAIPA/AI/0100/2018-IPSTERS。
致谢
作者感谢Direço Geral do Território(DGT)支持本研究中使用的数据。
利益冲突
作者声明没有利益冲突。资助者在研究设计中没有任何作用;收集、分析或解释数据;在撰写手稿时,或在决定公布结果时。
缩写
本手稿中使用了以下缩写:| 操作系统 | 过采样 |
| 个人简历 | 交叉验证 |
| LULC公司 | 土地利用/土地覆盖 |
| 卢卡斯 | 土地利用/覆盖面积统计调查 |
| SMOTE公司 | 合成少数人过采样技术 |
| 阿达欣 | 自适应合成采样技术 |
| G-打击 | 几何合成少数过采样技术 |
| B-SMOTE公司 | 临界合成少数过采样技术 |
| ROS公司 | 随机过采样 |
| 无 | 无过采样 |
| 左后 | 逻辑回归 |
| 千年网络 | K近邻 |
| DT公司 | 决策树 |
| GBC公司 | 梯度增压分类器 |
| 射频 | 随机森林 |
工具书类
- 梅勒,A。;Boukir,S。;海伍德,A。;Jones,S.探讨使用集合边缘进行大面积土地覆盖分类时训练数据不平衡和随机森林表现标记错误的问题。ISPRS J.摄影。远程传感器。 2015,105, 155–168. [谷歌学者] [交叉参考]
- 哈塔米,R。;Mountrakis,G。;Stehman,S.V.,基于监督像素的陆地图像分类过程遥感研究的元分析:从业人员和未来研究的一般指南。遥感环境。 2016,177, 89–100. [谷歌学者] [交叉参考] [绿色版本]
- 托克斯伯里,A.P。;A.J.Comber。;新泽西州泰特。;兰姆,A。;Fisher,P.F.遥感光学图像变化检测技术的关键综合。遥感环境。 2015,160, 1–14. [谷歌学者] [交叉参考] [绿色版本]
- Rajan,S。;Ghosh,J。;Crawford,M.高光谱数据分类的主动学习方法。IEEE传输。地质科学。远程传感器。 2008,46, 1231–1242. [谷歌学者] [交叉参考]
- 冯·W。;Huang,W。;Bao,W.采用基于SMOTE和不同采样率旋转森林的自适应集成方法进行非平衡高光谱图像分类。IEEE地质科学。遥感快报。 2019, 1–5. [谷歌学者] [交叉参考]
- 欧盟统计局。LUCAS 2015(土地利用/覆盖面积框架调查); 技术参考文件C1,测量员须知;欧盟统计局:法国斯特拉斯堡,2015年。[谷歌学者]
- Pflugmacher,D。;Rabe,A。;彼得斯,M。;Hostert,P.使用Landsat光谱时间指标和欧洲LUCAS调查绘制泛欧土地覆盖图。遥感环境。 2019,221, 583–595. [谷歌学者] [交叉参考]
- 麦克,B。;Leinenkugel,P。;库恩泽,C。;Dech,S.基于Landsat时间序列和Lucas现场数据为德国生成新土地利用和土地覆盖产品的半自动化方法。遥感快报。 2017,8, 244–253. [谷歌学者] [交叉参考]
- 新墨西哥州查拉。;贾普科维奇,N。;Kotcz,A.编辑:关于从不平衡数据集学习的特刊。ACM SIGKDD探索。新闻。 2004,6, 1. [谷歌学者] [交叉参考]
- Abdi,L。;Hashemi,S.通过过采样技术解决多类不平衡问题。IEEE传输。知识。数据工程。 2016,28, 238–251. [谷歌学者] [交叉参考]
- 南卡罗来纳州加西亚。;张,Z.L。;Altalhi,A。;阿尔索姆拉尼,S。;Herrera,F.多类不平衡数据集的动态集成选择。信息科学。 2018,445–446, 22–37. [谷歌学者] [交叉参考]
- Sáez,J.A。;Krawczyk,B。;Woźniak,M.分析多类不平衡数据集中不同类别和类型示例的过采样。模式识别。 2016,57, 164–178. [谷歌学者] [交叉参考]
- 费尔南德斯,A。;洛佩斯,V。;加拉尔,M。;德尔·耶稣,M.J。;Herrera,F.用多类分析不平衡数据集的分类:二值化技术和特殊方法。知识-基于系统。 2013,42, 97–110. [谷歌学者] [交叉参考]
- 欧盟统计局。LUCAS 2015(土地利用/覆盖面积框架调查); 技术参考文件C3分类(土地覆盖和土地利用);欧盟统计局:法国斯特拉斯堡,2015年。[谷歌学者]
- 杜扎斯,G。;Bacao,F.Geometric SMOTE是SMOTE的一种几何增强型嵌入式替代品。信息科学。 2019,501, 118–135. [谷歌学者] [交叉参考]
- 新墨西哥州查拉。;K.W.鲍耶。;洛杉矶霍尔。;Kegelmeyer,W.P.SMOTE:合成少数过采样技术。J.阿蒂夫。智力。物件。 2002,16, 321–357. [谷歌学者] [交叉参考]
- Han,H。;Wang,W.Y。;Mao,B.H.Borderline-SMOTE:非平衡数据集学习中的一种新的过采样方法。《智能计算国际会议论文集》,中国合肥,2005年8月23日至26日;施普林格:柏林/海德堡,德国,2005年;第878–887页。[谷歌学者] [交叉参考]
- He,H。;Bai,Y。;加西亚,E.A。;Li,S.ADASYN:不平衡学习的自适应合成采样方法。2008年IEEE神经网络国际联合会议(IEEE计算智能世界大会)会议记录,中国香港,2008年6月1日至8日;第1322-1328页。[谷歌学者] [交叉参考] [绿色版本]
- 阿扎德巴赫特,M。;弗雷泽,C。;Khoshelham,K。使用全波形激光雷达改进城市场景分类。照片。工程远程传感器。 2016,82, 973–980. [谷歌学者] [交叉参考]
- Krawczyk,B.从不平衡数据中学习:开放的挑战和未来的方向。掠夺。Artif公司。智力。 2016,5, 221–232. [谷歌学者] [交叉参考] [绿色版本]
- 麦克斯韦,A.E。;T.A.华纳。;Fang,F.遥感中机器学习分类的实施:应用综述。《国际遥感杂志》。 2018,39, 2784–2817. [谷歌学者] [交叉参考] [绿色版本]
- 冯·W。;Huang,W。;Ye,H。;Zhao,L.基于旋转森林的合成少数民族过采样技术,用于非平衡高光谱数据的分类。2018年7月22日至27日,西班牙巴伦西亚,IGARSS 2018-2018 IEEE国际地球科学和遥感研讨会论文集;第2651-2654页。[谷歌学者]
- 曾戈罗,T.W。;Isa,S.M。;Kusuma,G.P。;Pardamean,B.使用变分半监督学习对不平衡土地利用/土地覆盖数据进行分类。《2017年创新和创意信息技术国际会议论文集:计算智能和物联网》,2017年ICITech,2017年11月2日至4日,印度尼西亚萨拉蒂加;第1-6页。[谷歌学者] [交叉参考]
- 约翰逊,文学学士。;Iizuka,K.整合OpenStreetMap众包数据和Landsat时间序列图像以快速绘制土地利用/土地覆盖图:菲律宾Laguna de Bay地区的案例研究。申请。地理。 2016,67, 140–149. [谷歌学者] [交叉参考]
- 博格纳,C。;Seo,B.等人。;Rohner,D。;Reineking,B.稀有土地覆盖类型的分类:区分韩国农业集水区的一年生和多年生作物。公共科学图书馆 2018,13,电子0190476。[谷歌学者] [交叉参考] [绿色版本]
- 熊猫,A。;辛格,A。;库马尔,K。;库马尔,A。;乌迪什亚;Swetapadma,A.利用机器学习技术从卫星图像中预测土地覆盖。2018年4月20日至21日在印度哥印拜陀举行的2018年第二届发明通信和计算技术国际会议(ICICCT)会议记录;第1403-1407页。[谷歌学者]
- 杜扎斯,G。;用于不平衡数据集学习的自组织映射过采样(SOMO)。专家系统。应用。 2017,82, 40–52. [谷歌学者] [交叉参考]
- Nguyen,H.M。;库珀,E.W。;Kamei,K.不平衡数据分类的边界过采样。2009年11月10日至12日,日本广岛,第五届国际计算智能与应用研讨会(IWCIA2009)会议记录;2009年第卷,第24-29页。[谷歌学者]
- 雷蒙托,E。;卡巴列罗,Y。;贝洛,R。;Herrera,F.SMOTE-RSB*:一种基于过采样和欠采样的混合预处理方法,用于使用SMOTE和粗糙集理论的高度不平衡数据集。知识。信息系统。 2012,33, 245–265. [谷歌学者] [交叉参考]
- 刘,C。;弗雷泽,P。;Kumar,L.主题分类准确性度量的比较评估。遥感环境。 2007,107, 606–616. [谷歌学者] [交叉参考]
- Olofsson,P。;食品,通用。;Stehman,S.V.公司。;Woodcock,C.E.在土地变化研究中更好地利用准确性数据:估算准确性和面积,并使用分层估计量化不确定性。遥感环境。 2013,129, 122–131. [谷歌学者] [交叉参考]
- He,H。;Garcia,E.A.从不平衡数据中学习。IEEE传输。知识。数据工程。 2009,21, 1263–1284. [谷歌学者] [交叉参考]
- 麦卡拉,P。;J·奈尔德。广义线性模型; 查普曼和霍尔:英国伦敦,1989年;第532页。[谷歌学者] [交叉参考]
- 盖,T。;Hart,P.最近邻模式分类。IEEE传输。Inf.理论 1967,13, 21–27. [谷歌学者] [交叉参考]
- Salzberg,S.L.C4.5:J.Ross Quinlan编写的机器学习程序。摩根考夫曼出版社,1993年。机器。学习。 1994,16, 235–240. [谷歌学者] [交叉参考] [绿色版本]
- Friedman,J.H.Greedy函数近似:一种梯度增强机器。Ann.统计。 2001,29, 1189–1232. [谷歌学者] [交叉参考]
- Liaw,A。;Wiener,M.通过randomForest进行分类和回归。R新闻 2002,2, 18–22. [谷歌学者]
- 佩德雷戈萨,F。;瓦罗佐,G。;Gramfort,A。;米歇尔,V。;蒂里昂,B。;O.格栅。;布隆德尔,M。;普雷滕霍弗,P。;韦斯,R。;杜堡,V。;等。Scikit-learn:Python中的机器学习。J.马赫。学习。物件。 2011,12, 2825–2830. [谷歌学者]
- Lemaître,G。;Nogueira,F。;Aridas,C.K.Imbalanced-learn:机器学习中解决不平衡数据集诅咒的Python工具箱。J.马赫。学习。物件。 2017,18, 1–5. [谷歌学者]







{kind=link}
{kind=link}
{kind=link}
{kind=link}