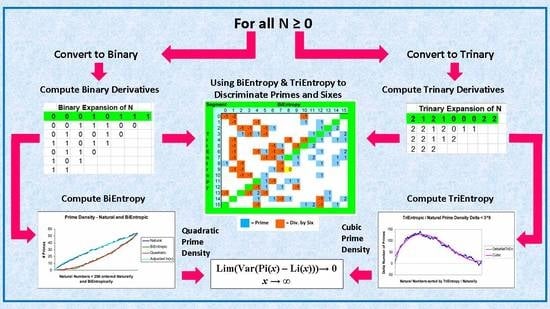
1.简介
我们开发了双熵函数[1]作为比较任意长度二进制字符串的数字的相对顺序和无序的一种方法。 我们最初在素数理论、人类视觉、密码学、随机数生成和定量金融等领域测试了该算法。作为素数研究的副产品,我们导出了两个很短的推论,重申了素数常数的不合理性[2]. 随后,我们使用双熵来确定9和10个交叉点的交替和非交替结之间的显著差异[三]在简单立方晶格中。我们的工作在密码学、互联网信息处理、移动计算和随机数生成领域被引用[4,5,6,7,8]. 最近,BiEntropy被重新实现、测试并在GitHub上公开[9]. 它在相关的美国政府专利中被显著引用[10]. 尽管双熵在不同领域(尤其是素数理论)的使用和应用有着这样的背景,但到目前为止,我们还未能进行最简单的测试来确定双熵和素性之间是否存在任何关系。数学中素性问题的历史重要性和深刻根源最终促使我们开始了我们的研究。有大量关于素数理论的文献。资源,如[11,12,13,14,15]其中的参考文献提供了一个有用的背景。 在本文中,我们实证研究了8位和32位二进制字符串中的双熵和素性之间的关系。然后我们发展了三熵函数,并研究了它与9个三元弦内素性的关系。我们简要地研究了双熵和三熵之间的关系。最后,我们讨论了这项工作背后的理论基础,并展示了它是如何推广到所有自然数的。
本文中的所有研究、实验和计算工作都是在Microsoft Excel电子表格环境中进行的[16]. 这使我们在创作过程中具有极大的灵活性、高开发生产率以及显著的计算和图形功能。已经观察到这些属性[17,18]并可能促进这项工作的可及性和深入性,特别是在教育领域[19,20]. 本文的布局反映了实验和理论工作的发生顺序,除了费马和梅森素数的工作被转移到附录B。我们在线提供了一套完整的电子表格,用于执行本文中的计算和图形。有关访问这些电子表格的详细信息,请参阅补充材料部分. 2.双熵
双熵算法使用香农熵的加权平均值[21]字符串和除最后一个二元导数以外的所有二元导数[22]字符串的。 2.1. 香农熵
二进制字符串的Shannon熵秒=秒1, …,秒n个其中P(秒我= 1) =第页(和0日志20被定义为0)是: 对于全部为1或全部为0的完全有序字符串,即。,第页=0或第页= 1,H(H)(第页)返回0。在哪里?第页=0.5,H(p)返回1,反映最大变化。但是,对于字符串(例如01010101),其中第页=0.5,H(p)也返回1,完全忽略字符串的周期性。
我们可以通过字符串的二进制导数来发现二进制字符串的周期性。
2.2. 二元导数和周期性
的第一个二元导数秒,天1(秒),是长度为的二进制字符串n个−1由相邻的数字对进行异或运算形成。我们指的是k个的th导数秒,d日k个(秒)作为的二元导数d日k个−1(s) ●●●●。有n个−1的二元衍生物秒.第页(k个)是1的比例d日k个.
大约五十年前,内森[22],跟随Goka的工作[23],定义了任意二进制字符串中的周期和最终周期的概念,并分别和集体概述了二进制字符串及其导数的相关属性。在许多有用的结果中,我们发现二进制字符串具有周期2米对一些人来说米≥0当且仅当d日k个某些情况下为0k个≥ 1. 2.3. 双熵定义
双熵,简称BiEn,是字符串和第一个字符串的Shannon熵的加权平均值n个弦的−2个二元导数。有多种方法来加权香农熵。在这一系列实验中,我们使用2的幂来加权香农熵: 最终导数d日n个−1没有使用,因为在其两个二进制状态中,对总熵的贡献没有变化。最高权重分配给最高导数d日n个−2.
2.4. 双熵属性
BiEntropy提供一个介于0和1之间(含0和1)的数字,表示长度为二进制字符串的数字的相对顺序和无序性n个> 1. 最短的完全有序字符串是00和11,它们的BiEntropy为0。唯一完全无序的字符串是01和10,它们的双熵为1。例如,有序(即周期性)字符串(如01010101)的BiEntropy很低,为0.01。像10000110这样的无序字符串的BiEntropy很高,例如0.95。
3.自然数的双熵和素数<256
我们展示了图1小于256的自然数的双熵。行对应于最高有效数字,列对应于其二进制表示的最低有效数字。行和列分别按最高和最低有效数字的4位BiEntropy排序。双熵的颜色编码为白色<0.15、黄色<0.25、橙色<0.5和红色<1.0。注意图中对角线的对称性。底漆是紫色的。例如,5=00000101的8位双熵为0.23,根据对称性,它将被涂成黄色,但编码为紫色,因为它是(费马)素数。费马素数17=00010001由于其数字的周期性,其双熵较低,为0.05。它将被染成白色,但由于它的原始性而被染成紫色。此外,127=01111111的双熵为0.92,颜色为红色,但它不仅是素数,而且是梅森素数,颜色为紫色。注意,0和1只是“非素数”。 很容易看出,大多数素数都位于红色象限中,只有一个素数(费马素数)位于白色对角线上。注意,<256的自然数的素性与双熵的自然对称性存在差异,如图1. 四个素数比例之间的差异表1以下内容在第页< 0.01. 因此,我们发现了一种基于双熵或更普遍的二元导数的素数分割方法。在红色部分寻找8位素数的效率大约是在白色或黄色部分寻找的效率的九倍。 我们展示了表2下面是素数、非素数和复合奇数的双熵之间的明显区别第页自然数<256时<0.0001。四个梅森素数<256和33个孪生素数<256的双熵与所有<256的素数的双熵相似。因此,素数和小于256的复合比数为129,其中包括偶数素数。 如果我们按照BiEntropies对<256的自然数进行排序,并将其分为八个部分,如表3,最低和最高双熵段之间的素密度差异显著增大。 素密度π(x个),素数小于或等于x、,大约为x个/在(x个)由于1896年雅克·哈达玛和查尔斯·德拉瓦莱·普桑的素数定理。双熵似乎将素密度修改为O(运行)(x个2)对于非常小的整数。因此,使用双熵或其他素数密度函数,我们可以有效地谈论q个(x个,年,我)它是我第个年按大小排序的间隔<x个.因此q个(256,32,8)等于14,如上所述。当然,π(256)=q个(256, 256, 1) = 54.
最后,我们用图形描述了双熵和素性之间的连续关系图2这揭示了一种几乎确定的关系。我们拟合了相关的自然对数和二次曲线,并显示了图3我们调整了自然对数曲线,使Log(256)与π(x个)在极限内完成。注意,双熵是二进制字符串的香农熵和第一个香农熵的加权平均值n个−字符串的2个二进制导数。未进行(显式)试算除法以计算BiEntropy。素数<256=54,素数<256的总双熵=42.64。 手段图3由于我们进行了小的乘法调整,结果是一致的。误差的标准偏差几乎相同,自然对数为0.93,二次方为0.98。因此,整数的双熵素数密度的实际误差x个<256表示<√x个日志(x个)显然是高斯分布。正如我们将看到的那样,误差收敛到0x个→ ∞. 4.自然数的双熵和素性<232
4.1. 素数和二元导数
而π(x个)~x个/在(x个),计算长度字符串的双熵时使用的二进制导数的数量米(其中米=对数2(x个))仅增加为(米2−米)/2. 我们展示了表4π之间的关系(x个),素数和二元导数d日用于各种x个. 因此,d日/π(x)很快趋于0,这可能会使BiEntropy对较长字符串长度的素性不太敏感。
4.2. 香农熵的高次幂
有一些研究起源于算法信息理论[24]这表明,原始性与无序性有关,这当然是双熵设计用来衡量的。另一项工作不涉及在此过程中使用二进制导数。注意,对角线上只有一个素数图1,这是最大阶的区域。 我们可以改变双熵,以提高其对检测二元导数中任何偏离完美无序的情况的灵敏度。这很容易做到,特别是在电子表格环境中,因为我们可以简单容易地将每个二元导数的香农熵提高到大于1的幂。
我们展示了图4基于的Shannon熵幂从1提高到10的效果第页、品种。在图表中间变化最大的区域中,第页=0.5,Shannon熵最高。当使用更高的Shannon熵幂时,我们可以更有力地区分偏离最大无序。 4.3. 研究x<2的双熵和素性32
我们使用基于电子表格的蒙特卡罗计算来研究自然数<2的样本32。使用一个简单的Excel数据表,对于10000次迭代中的每一次,我们生成一个随机的32位整数,然后使用每个导数的香农熵的十次幂(P10 BiEntropy)计算其二次双熵。我们使用基于电子表格的详尽试分计算来确定每个随机32位整数的素数。然后,我们将采样的自然数及其双熵排序为双熵序,并将该有序区间的素数密度与样本的自然素数密度进行比较。我们展示了样本的自然质密度和双熵质密度之间的关系图5以及两种密度之间的差异图6. 4.4. 双熵和原始性的蒙特卡罗检验
我们决定仔细研究蒙特卡罗模拟产生的自然质密度和双熵质密度之间的微小差异,如图5以上。该模拟由10000个整数样本组成x个在0范围内<x个< 232由Excel RAND函数生成,我们之前已经仔细检查过[1]. 由于随机数将在给定范围内均匀生成(即线性生成),因此我们可以使用素数定理计算在给定范围生成10000个随机整数期间可能生成多少素数。然后,我们能够计算蒙特卡罗模拟的理论素数密度,以与蒙特卡罗仿真的实际素数密度进行比较。 我们显示了自然素数密度和双熵素数密度之间的实际差异或δ,以及理论预期差异或δ图6理论上的Delta(以橙色显示)仅占差异的一部分。双熵素数密度和自然素数密度之间的差异并不是由蒙特卡罗模拟中素数的线性产生率和自然素数密度之间的差别来解释的。差别要大得多。将预期差异平方并除以二(Delta2/2) 与蒙特卡洛模拟的实际结果更加接近。经检查图6大致正常(平均值1.22和圣德芙6.17),为简洁起见省略了。对于以下整数,双熵素数密度似乎也是二次的O(运行)(232). 我们报道的蒙特卡罗模拟中实际产生的素数是391,而预期的素数为473。预计会有变化。
5.三熵
我们在以前的工作中注意到,BiEntropy函数对3的周期性不敏感(参见中18、27、36和54的条目表A1属于附录A). 例如,001001001001001的18位二次双熵为0.9484,表示无序,但字符串显然是周期性的。我们曾认为,发展一个与双熵等价的三元数可能会解决这个问题,但我们之前并没有这样做的动机。考虑到双熵和前几节中概述的素数之间的联系,以及所有≥5的素数都是6的形式k个±1,有明确的调查动机。 5.1. 两两加法与差分模3
对三熵的严格测试是,它在一个三元字符串中提取了3的周期性。我们设计了一个简单的双向两两三元加法表,如所示表5. 我们使用的两两三元加法表将我们的8位二进制双熵计算器电子表格转换为9三元三熵计算器电子表表5以上。这只花了几分钟。不幸的是,它不起作用。然后我们发现,在一个3三元字符串ABC中,我们需要计算三对AB、BC、AC、模3之间的三元两两三元差值(PTD)。因此,我们在里面展示的表6。在电子表格中又花了几分钟的时间来证明这确实有效。三个trit字符串各自的TriEntropies看起来并不乐观,但我们坚持我们的分析。注意,PTD函数在两两置换下是不变的,A、B或C都没有优先级。 5.2. 计算三熵
为了计算三元字符串的香农熵,我们需要第页我所有可能的符号。对于衍生品,如表6上面第页我对于0、1、2,分别为0.111(3/27)、0.444(12/27)和0.444(12-27)。重要的是,由于三熵必然会计算原始字符串的香农熵,请注意第页我输入字符串的0,1,2的值是0.333、0.333和0.333,因为它们是等概率的。此外,请注意,只有(n个−1)/2−1衍生物是可能的(其中n个奇数),因为需要三个输入trit来计算导数的每个输出trit。最后,请注意,在双熵中,一旦检测到周期性,进一步的导数就会自动降为0。三熵并非如此,因此,降为0的导数必须有专门的非使用编程。注释n个很奇怪。 我们展示了表7一个简单的Excel电子表格的布局,用于计算9 trit字符串的多项式(即三次)TriEn。我们使用表7计算导数的每个trit。 我们详尽地计算了所有的TriEnx个< 39并显示生成的自然和三熵素数密度图7。在等效的BiEntropy图中x个< 216,BiEntropy几乎是相同的,为了简洁起见,之前省略了它。我们显示了三熵素数密度和自然素数密度之间的差异或Delta图8. 因此x个< 39约为立方。差分的误差近似于高斯分布,如图所示图9平均误差为0.00,标准偏差为7.34。 6.双熵与三熵的相互作用
我们研究了自然数<256时双熵和三熵之间的相互作用。我们根据BiEntropy和TriEntropy为每个自然数分配了两个介于0和15之间(含0和15)的段数。将BiEntropy最低的16个自然数分配给BiEntropy0段,将BiEntopy最高的16个天然数分配给biEntropy15段,以此类推。我们展示了图10下面是蓝色素数和可被6整除的红色素数的出现频率图,这些素数由双熵段数排列在x个轴和上的TriEntropic段编号年轴。素数编码为正数,可被6整除的数编码为负数。第8-9段发生了一次碰撞,对应的数字是42和103,编码为黄色。 虽然数据量很小,但我们从我们早期的实验中预计,增加双熵和增加三熵将揭示更多的素数和更少的复合数。情况似乎就是这样。忽略从左下角到右上角的对角线,左上角的三角形中相对缺少质数(11/120对40/120,第页<0.0001),并且可被六整除的数字在右下三角形中相对不存在(11/120对30/120,第页<0.002),这与先前的预期相对应。只有一个片段发生碰撞,而如果素数和可被6整除的数在所有双熵和三熵片段中的分布是均匀的,则可能会有八个片段发生冲突(54*42/256)。请注意,202个非犯罪均分布在图10,为了简洁起见,不显示这些信息,但可以在补充资料. 7.理论基础
7.1. 介绍
现在我们来说明为什么周期性的概念在决定素性时如此重要。
7.2. 周期数和非周期数
考虑串联的二进制字符串ab公司其中,长度一和b条是n个和n个≥1,则长度ab公司是2n个.如果一=b条对一些人来说n个,那么ab公司是周期性的。周期数出现在从原点发出的对角线上图1(其中n个=4),大多为白色。 7.3. 周期二元素数
在哪里?一=b条=1,其中一些是费马数,其中只有5个已知为素数[25]. 费马数17出现在图1它是紫色的,因为它是上等的。我们在中详细讨论了费马数附录B. 7.4. 周期二元复合物
其余的数字,k个,在从原点发出的对角线上图1及其等价物n个形式如下: 第一个周期性二元复合物>0为1010,即10(十)。因此,梅森数(形式为2的数n个长度均匀的−1)(其中a=b)不能是质数。奇长梅森数,例如0111,seven,可能是素数,但不是周期数,因为a≠b。我们列出了周期性二元复合物<256 in附录A并在中详细讨论梅森数附录B. 7.5. N周期二元复合物
表格00111100和10010110等的编号,其中一是的2的补码b条即。,也是复合材料。这些数字以白色出现在图1这些数字的形式如下: 7.6. 周期M-Ary素数
所有素数k个>2个是这样的ab公司哪里一和b条长度为n个和a=b=1在一个底座中米=k个− 1.
除了费马素数,它们在基2中也是周期性的。
7.7. 周期性M元复合物
一般来说,数字k个,在等价于图1在任何基础上米形式如下: 7.8. 非周期数字
数字,其中一≠b条(n个≥1)在任何基中都是质数或非质数。
8.讨论
因此,双熵和三熵与素性有任何关系的主要原因是一个简单的事实,除了费马数(例如,23=1122)、定期和n个-周期数不能以任何基数为素数。因此图1(对于所有人x个,并且在所有的基中)几乎没有素数,并且在交叉对角线上没有素数。忽略费马素数,32/256=12.5%的自然数<256不能是素数,因为周期性或n个-最后八个二元导数中七个的周期性。 如果一个二进制字符串是周期的,那么一个,然后所有进一步的导数都降为0[22]. 双熵选择了这一点,因为香农熵为0。对称地,如果一个导数都是1,那么它也会有0香农熵,并且(除非它是最后使用的导数)在下一个导数中都会变成0。周期性观察得越早(即对于较短的周期),加权总数就越低,因为所有较高的权重都为0。非周期字符串以其他方式进行相应排序,其中导数最多的字符串位于或接近第页=0.5,获得最高的BiEntropy。双熵是素性的汉明距离。除非在某些情况下(例如。,秒=0000000 1),二进制导数的位是不可判定的。确定二元导数的位数是暂停问题的简单变体——如果最后一个二元导数是1,则例程会暂停,否则它不会停止。 而字符串是周期性的,当且仅当它的一个导数都是0[22],反之则不适用,因此素性是随机的。Davies等人[26]证明了如果字符串的位以0.5的概率出现,则导数的位也以0.5的几率出现,并且二进制导数是独立的。因此,由于中心极限定理,二次和双熵素数密度之间的误差是高斯的,双熵素密度是导数每一位出现概率的二次函数。请注意,任何x个是有限的。 通过简单的归纳,每个二进制数都是一个数的二进制导数,它的位以0.5的概率出现。它的钻头已经过验证[26]独立于其早期衍生产品。因此,素数是高斯的,因为它们每一位的出现概率与其他二进制数和其他二进制导数没有差别。 双熵素数密度是平方的,因为双熵是二次的。例如,在8位版本的BiEntropy中,由于字符串都是1,所以任意字符串不是素数的概率,或者二进制导数为0的概率是:即,只有一个8位字符串(秒=d日0)这都是0,而上次使用的导数d日6长度为2时,64次均为0d日5长度为3时,32次都是0。双熵精确测量二进制字符串不能是素数或可能是素数的概率,其精度由d日0。三熵也是立方的,原因类似。 双熵与素性泛化之间的关系x个原因很简单x个≥256(例如)通过连续二进制微分最终成为8位(例如)字符串。确定所有数据的许多数学和统计特性x个可以通过观察最后的特性归纳得出米二元导数,当米很小。
因此,存在一组常量一k个,b条k个、和c(c)k个,因此 和另一组(类似的)常量u个k个,v(v)k个、和w个k个,因此 对于每个一k个,b条k个,c(c)k个和u个k个,v(v)k个、和w个k个,存在一组(米2−米)/二元导数,素数的分布是以已知的概率和可计算或可估计的方差导出的。自然素数密度的方差受到所有双熵素数密度方差的约束x个k个<x个因为相同的数据——自然数——是高斯分布在两个不同的中心测度上——二次被积函数和对数被积函数。
因此,在极限条件下,双熵/二次和对数积分/自然误差分布与几乎相同的误差分布一致,我们在图3此外,作为x个→∞, 由于二进制导数中的位数=(米2−米)/2,其中米=对数2(x个),双熵素数密度和二次素数密度之间的误差方差为O(运行)(日志(x个)/x个)由于中心极限定理。因此,对数积分和自然素数密度之间的误差迅速趋于0。这与von Koch明显不同[27]注定要证明黎曼假设。 一组类似的立方常数适用于三熵以及双熵和三熵的算术加法,我们将其表示为三双熵。我们举例说明了三重熵相交的立方π(x个)用于各种x个在里面图11. 9.结论
我们已经证明了自然数的双熵和素性之间存在明显的经验联系8.我们在统计上对<2的自然数重复了此分析32发现了类似的结果,包括剩余的素密度O(运行)(x个2). 我们开发了一个相关的三熵函数,并表明三熵将质密度改变为O(运行)(x个三)对于<3的自然数9此外,三熵解决了双熵函数中检测长度为3或其倍数的周期时的一个天然弱点。
由于双熵和三熵只是字符串有序性和无序性(即周期性)的度量,这意味着以二进制或三进制表示的素数具有更多无序表示。相反的含义是复合材料具有更有序的表示。这一结果已在算法信息理论的早期工作中提出。
我们已经展示了如何通过在双熵计算中增加香农熵的指数来提高双熵的灵敏度。我们已经证明了自然数中的双熵和三熵之间的重要联系8以及通过算术加法将双熵和三熵结合起来的实用性。我们简要概述了这项初始实验工作背后的理论基础,并说明了它是如何推广到所有自然数的。
我们已经展示了误差的方差π(x个)以及锂(x个)由于方差的高斯约束,趋向于0π(x个)由二元导数施加。这些约束比Von Koch在1901年证明的等价于黎曼假说的边界要严格得多。
我们提供了附录B费马素数和梅森素数的绝对收敛渐近线。 最后,由于二元导数导致素数的分布是高斯的,这意味着孪生素数猜想是正确的。
10.进一步工作
来自的注释图1以及早期的工作,即双熵、三熵等,尽管实是量子化的,不连续的,并且具有有限数量的状态。这可能与将双熵和三熵与物理域关联的尝试有关[28]. 有无数机会将首要性与其他领域联系起来[29]特别是要记住二进制、二进制导数、素性及其米-抽象概括。 11.专利
双熵函数在Gurieri,T.M.,Hamlet,J.R.,Bauer,T.M..,Helinski,R.,&Pierson,L.G.(2018)《美国集成电路物理不可测函数专利》(美国专利号10103733)中有突出引用[10]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












