一种用于PM预测的新型混合机器学习方法(OR-ELM-AR) 2.5 浓度及其预测性能评估



摘要
1.简介
2.方法和数据来源
2.1. 研究领域和数据源
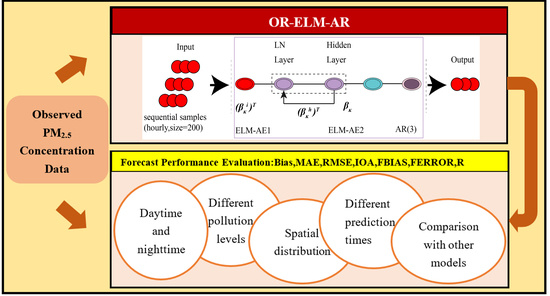
2.2. OR-ELM-AR模型框架及预测过程
2.3. 评价方法
3.结果
3.1. PM的一般时空模式 2.5 污染
3.2. 模型参数的优化
3.3. 日间和夜间预测性能的比较
3.4. 不同污染水平下的预测性能
3.5. 空间预测性能
3.6. 与其他模型的比较
4.结论
(1) 项目经理 2.5 OR-ELM-AR在夜间的预报能力略优于白天,主要是受多种影响因素的影响,如人为源较多,白天气象条件变化较大; (2) OR-ELM-AR模型对低水平和高水平PM具有更好的预测性能 2.5 污染程度高于中等污染水平。 特别是在重度和极端重度污染的情况下,该模型能够及时响应浓度的较大时间变化,预测值与观测值之间的相关系数较高。 与长江三角洲中部的中度污染城市相比,长江三角洲地区污染最严重的北部城市和污染最少的南部和西部城市的预测性能更好; (3) 通过嵌入式AR算法,OR-ELM-AR模型获得的RMSE和MAE值比OR-ELM模型小得多,FERROR值稍小。 OS-ELM模型的预测性能最差; (4) OR-ELM-AR模型比基于RMSE和MAE指标的LSTM模型具有更好的快速响应能力,预测时间提前1小时到6小时不等,尽管它们的IOA值很接近。
补充资料
作者贡献
基金
数据可用性声明
致谢
利益冲突
工具书类
Chang,X。; 王,S。; 赵,B。; Xing,J。; 刘,X。; Wei,L。; Song,Y。; Wu,W。; 蔡,S。; 郑浩。; 等。城际和区域交通对PM的贡献 2.5 北京-天津-河北地区的浓度及其对区域联合空气污染控制的影响。 科学。 总环境。 2019 , 660 , 1191–1200. [ 谷歌学者 ] [ 交叉参考 ] Cheng,N。; 张,D。; 李毅。; 谢,X。; 陈,Z。; 孟,F。; 高,B。; He,B.北京两次红色空气污染警报期间PM2.5浓度的时空变化和减排措施评估。 科学。 代表。 2017 , 7 , 8220. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] Huang,L.等人。; An,J。; 顾,B。; Yarwood,G。; Yan,R。; Wang,Y。; Huang,C.等人。; 冬季浓雾事件中Li,L.硫酸盐的形成及非均匀SO的潜在贡献 2 +否 2 中国长江三角洲地区的反应。 大气。 化学。 物理学。 2019 , 19 , 14311–14328. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 李凯。; 雅各布·D·J。; 廖,H。; 朱,J。; 沙阿,V。; 沈,L。; 贝茨,K.H。; 张,Q。; 翟,S.改善中国臭氧和颗粒物空气质量的双污染战略。 自然地质学。 2019 , 12 , 906–910. [ 谷歌学者 ] [ 交叉参考 ] Kan,H。; 陈,R。; Tong,S.中国的环境空气污染、气候变化和人口健康。 环境。 国际。 2012 , 42 , 10–19. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 李,Z。; Wang,Y。; 郭杰。; 赵,C。; 克里布,M.C。; Dong,X。; 范,J。; 龚,D。; 黄,J。; 江,M。; 等。东亚对流层气溶胶及其对区域云、降水和气候影响的研究(EAS-AIR CPC)。 《地球物理学杂志》。 Res.大气。 2019 , 124 , 13026–13054. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 林,H。; 马伟(Ma,W.)。; 邱,H。; 王,X。; Trevathan,E。; 姚,Z。; Dong,G.H。; 沃恩,M.G。; 钱,Z。; Tian,L.利用每日过量浓度小时数来探索香港环境PM2.5对短期死亡率的影响。 环境。 波卢特。 2017 , 229 , 896–901. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] [ 绿色版本 ] 黄,C.J。; Kuo,P.H.智能城市颗粒物(PM2.5)预测的深度CNN-LSTM模型。 传感器(巴塞尔) 2018 , 18 , 2220. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] Wang,Y。; Bao,S。; 王,S。; 胡,Y。; 施,X。; Wang,J。; 赵,B。; 姜杰。; 郑,M。; 吴,M。; 等。重霾天气期间北京地区和区域对细颗粒物的贡献。 科学。 总体环境。 2017 , 580 , 283–296. [ 谷歌学者 ] [ 交叉参考 ] 郑,B。; 张,Q。; Zhang,Y。; He,K.B。; 王凯。; 郑国杰。; Duan,F.K。; Ma,Y.L。; Kimoto,T.非均相化学:解释2013年1月华北地区霾事件期间二次无机气溶胶形成的现有模型中缺失的机制。 大气。 化学。 物理学。 2015 , 15 , 2031–2049. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 刘,D。; Sun,K.基于CEEMD-RF的中国五个城市PM2.5短期预测。 环境。 科学。 波卢特。 Res.Int.公司。 2019 , 26 , 32790–32803. [ 谷歌学者 ] [ 交叉参考 ] X·冯。; 李强。; Zhu,Y。; Hou,J。; Jin,L。; Wang,J.使用基于地理模型和小波变换的空气质量轨迹人工神经网络预测PM2.5污染。 大气。 环境。 2015 , 107 , 118–128. [ 谷歌学者 ] [ 交叉参考 ] 王,D。; Wei,S。; 罗,H。; Yue,C。; Grunder,O。基于两相分解技术和改进的极值学习机的空气质量指数预测新混合模型。 科学。 总环境。 2017 , 580 , 719–733. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 帕克,J.-M。; Kim,J.-H.在线递归极端学习机及其在时间序列预测中的应用。 2017年5月14日至19日在美国阿拉斯加州安克雷奇举行的2017年国际神经网络联合会议(IJCNN)会议记录; 第1983-1990页。 [ 谷歌学者 ] [ 交叉参考 ] 玛莎,A。; N.K.Larkin,预测美国西部PM2.5的统计模型。 J.空气废物管理。 协会。 2019 , 69 , 1215–1229. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 冯,R。; 郑海杰。; 高,H。; 张,A.-R。; Huang,C.等人。; 张建新。; 罗,K。; Fan,J.-R.回归神经网络和随机森林用于大气污染物的分析和准确预测:中国杭州的案例研究。 J.清洁。 产品。 2019 , 231 , 1005–1015. [ 谷歌学者 ] [ 交叉参考 ] 毛,X。; 沈,T。; Feng,X.利用神经网络和卫星数据提前3天预测中国东部地面PM2.5小时浓度。 大气。 波卢特。 物件。 2017 , 8 , 1005–1015. [ 谷歌学者 ] [ 交叉参考 ] 高,S。; 黄,Y。; 张,S。; Han,J。; 王,G。; 张,M。; Lin,Q.使用GRU和LSTM网络进行短期径流预测,在样本生成期间无需时间步长优化。 J.水文学。 2020 , 589 , 125188. [ 谷歌学者 ] [ 交叉参考 ] Díaz-Robles,洛杉矶。; 奥尔特加,J.C。; Fu,J.S。; 里德,G.D。; 周,J.C。; Watson,J.G。; Moncada-Herrera,J.A.,预测城市地区颗粒物的ARIMA和人工神经网络混合模型:智利特穆科案例。 大气。 环境。 2008 , 42 , 8331–8340. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 周,Q。; 姜浩。; Wang,J。; 周,J.PM的混合模型(2)。 (5) 基于集合经验模式分解和通用回归神经网络的预测。 科学。 总环境。 2014 , 496 , 264–274. [ 谷歌学者 ] [ 交叉参考 ] 默里,N.L。; 霍姆斯,H.A。; 刘,Y。; Chang,H.H.一种贝叶斯集合方法,用于结合使用卫星图像和数值模型模拟的统计模型的PM2.5估计值。 环境。 物件。 2019 , 178 , 108601. [ 谷歌学者 ] [ 交叉参考 ] Yu,L。; 戴,W。; Tang,L.一种新的带有扩展极值学习机的原油价格预测分解集成模型。 工程应用。 Artif公司。 因特尔。 2016 , 47 , 110–121. [ 谷歌学者 ] [ 交叉参考 ] 张,N.N。; 马,F。; 秦,C.B。; Li,Y.F.2013-2017年PM2.5水平时空变化趋势及中国大气污染联合防治区域划分。 化学圈 2018 , 210 , 1176–1184. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 刘,B。; Yan,S。; 李,J。; Qu,G。; 李毅。; 朗·J。; Gu,R.基于n步递归预测的逐序空气质量预报器。 IEEE接入 2019 , 7 , 43331–43345. [ 谷歌学者 ] [ 交叉参考 ] 布埃诺,A。; 科尔霍,G.P。; Bertini,J.R.基于极端学习机的在线序贯学习用于颗粒物预测。 2017年10月2日至5日在巴西乌伯兰迪亚举行的2017年巴西智能系统会议(BRACIS)会议记录; 第169-174页。 [ 谷歌学者 ] [ 交叉参考 ] 黄,G。; 梁,N。; 荣,H。; 萨拉昌德兰,P。; Sundararajan,N.在线顺序极端学习机器。 2005年7月4日至6日,加拿大阿联酋卡尔加里,IASTED国际计算智能会议记录。 [ 谷歌学者 ] 刘,H。; Xu,Y。; Chen,C.基于集合方法的改进污染预测混合算法。 申请。 数学。 模型。 2019 , 73 , 473–486. [ 谷歌学者 ] [ 交叉参考 ] James,J.简单趋势导向策略的稳健性。 数量。 财务。 2003 , 三 ,C114–C116。 [ 谷歌学者 ] [ 交叉参考 ] 卡纳达,M。; 董,L。; Fujita,T。; Fujii,M。; 井上,T。; Y.平野。; 多哥,T。; Geng,Y.,中国区域差异与成本效益高的二氧化硫污染控制:以5个特大城市为例。 能源政策 2013 , 61 , 1322–1331. [ 谷歌学者 ] [ 交叉参考 ] 李,J。; 杜,H。; 王,Z。; 孙,Y。; 杨伟(Yang,W.)。; 李,J。; 唐,X。; Fu,P.华北平原特大城市群上空严重区域性冬季雾霾事件的快速形成。 环境。 波卢特。 2017 , 223 , 605–615. [ 谷歌学者 ] [ 交叉参考 ] 王,Q。; Kwan,M.P。; 周,K。; 范,J。; Wang,Y。; Zhan,D.城市化对细颗粒物(PM2.5)浓度的影响:来自全球135个国家的经验证据。 环境。 波卢特。 2019 , 247 , 989–998. [ 谷歌学者 ] [ 交叉参考 ] 翟,S。; 雅各布·D·J。; 王,X。; 沈,L。; 李凯。; Zhang,Y。; 桂,K。; Zhao,T。; 廖,H.中国细颗粒物(PM2.5)趋势,2013-2018:从人为排放和气象学中分离贡献。 大气。 化学。 物理学。 2019 , 19 , 11031–11041. [ 谷歌学者 ] [ 交叉参考 ] [ 绿色版本 ] 张,Q。; Quan,J。; 领带,X。; 李,X。; 刘,Q。; 高,Y。; Zhao,D.中国北京重霾事件期间气象和二次粒子形成对能见度的影响。 科学。 总环境。 2015 , 502 , 578–584. [ 谷歌学者 ] [ 交叉参考 ] 赵,B。; 王,S。; 丁·D。; Wu,W。; Chang,X。; Wang,J。; Xing,J。; Jang,C。; Fu,J.S。; Zhu,Y。; 等。北京-天津-河北地区空气污染物排放与PM2.5相关健康影响之间的非线性关系。 科学。 总环境。 2019 , 661 , 375–385. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ] 赵,J。; 邓,F。; 蔡,Y。; Chen,J.用于PM2.5浓度预测的长短期记忆全连接(LSTM-FC)神经网络。 化学圈 2019 , 220 , 486–492. [ 谷歌学者 ] [ 交叉参考 ] [ 公共医学 ]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}