NAMD公司,是一个广泛使用的并行分子动力学模拟引擎,是CUDA加速的首批应用之一。在NAMD对CUDA支持的早期发展过程中,NVIDIA GPU和CUDA在性能和功能方面都有了巨大的增长。有关更多信息,请参阅使用图形处理器加速分子建模应用程序和使消息驱动的并行应用程序适应GPU加速的群集.
沃尔特GPU一代的到来使NAMD承担起橡树岭国家实验室(ORNL)Summit系统的创纪录模拟规模。有关更多信息,请参阅将NAMD和VMD分子模拟和分析软件移植到GPU加速的OpenPOWER平台的早期经验和Summit系统上具有NAMD的可伸缩分子动力学.
然而,由于主机CPU和PCIe的性能提升与同期GPU的性能提升不相匹配,原始NAMD软件设计成为小分子和中等分子动力学模拟进一步提高性能的障碍。Volta GPU提供的性能有效地使NAMD v2 CPU绑定,消除此性能限制需要不同的方法。
预测预期的GPU性能增益,并预测各种密集GPU HPC平台的可用性不断增加,NAMD团队开始了战略的重大转变,从传统的“GPU加速”计划转向NAMD v3的完全“GPU驻留”操作模式
NAMD v3的新GPU驻留模式针对单节点单GPU模拟,以及GPU集群上所谓的多副本和复制交换分子动力学模拟,以及DGX-2和DGX-A100等密集型多GPU系统。NAMD v3 GPU驻留的单节点计算方法大大降低了NAMD对CPU和PCIe性能的依赖性,为在最先进的NVIDIA安培GPU和DGX-A1等密集型多GPU平台上进行中小型仿真带来了巨大的性能
这篇文章中介绍的早期结果非常令人兴奋,但我们必须指出,还有更多的工作要做。随着NAMD v3的成熟,我们预计性能将进一步提高,我们稍后将开始使用NVLink和NVSwitch连接系统进行强大的扩展。
切换到“GPU-resident”模式后,NAMD v3变为GPU-bound。这使得在相同的GPU上,v3比v2.13快1.9倍。绑定GPU也使v3从使用更新的GPU中受益匪浅:新A100上的v3比V100上的快1.4倍。最后,GPU绑定使得v3在多GPU系统上进行多副本仿真时具有更好的伸缩性。随着这些软件和硬件进步的综合结果,在8-GPU DGX系统上,您可以看到A100上的v3吞吐量比V100上的v2.13高出9倍。
NAMD使用时间步进算法来及时传播分子系统。每个时间步长通常为1或2飞秒,要观察的现象通常发生在纳秒到微秒的范围内。需要执行数百万次的时间步长。
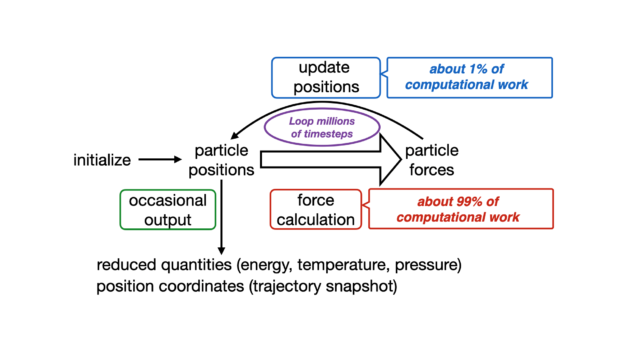 图1。NAMD时间步长细分。
图1。NAMD时间步长细分。传统的时间步长通常由四个主要的计算瓶颈组成:
- 短范围非结合力:原子的力和能项的评估在指定的截止范围内,并被认为是直接相互作用≈90%的总FLOPS。
- 长范围力通过颗粒米埃瓦尔德(PME):长程静电相互作用的快速近似是在倒数空间上进行的,这涉及到几个傅里叶变换≈5%的整体FLOPS。
- 结合力:对来自分子拓扑的键合项进行计算、加权,并将其应用于对应原子≈4%的总FLOPS。
- 数值积分:计算的力应用于原子速度,系统通过速度verlet算法≈1%整体FLOPS。
作为最早采用GPU加速的科学代码之一,NAMD的最新版本(2.13和2.14)可以卸载所有力项,并将结果返回到进行数值积分的CPU主机。该方案使NAMD能够有效地使用所有机器资源,并且能够提取Maxwell和更早的GPU代的全部性能。然而,在Pascal GPU体系结构发布后,NAMD在工作中无法完全占用GPU。
为了帮助您了解实际情况,我们使用了NVIDIA Nsight系统生成NAMD执行时间表,并在整个仿真过程中跟踪GPU活动。
 图2。NAMD时间表与Nsight Systems在单个Titan V GPU和多个CPU内核上进行ApoA1(92000个原子)模拟。
图2。NAMD时间表与Nsight Systems在单个Titan V GPU和多个CPU内核上进行ApoA1(92000个原子)模拟。当您跟踪GPU活动时,蓝色条带中的空白显示GPU在整个模拟中处于空闲状态,这是因为CPU上发生了剩余的任务:数值积分。值得注意的是,现代GPU的效率如此之高,以至于即使将整个FLOP的1%这样小的一部分委派给CPU,也会导致整个模拟出现瓶颈。为了继续受益于GPU处理能力,也将数值积分步骤转移到GPU。
为了实现可扩展的并行性,NAMD将分子系统在空间上分解为一系列子域,就像一个三维拼接被,其中每个补丁代表原子的子集。通常,补丁本身负责存储相关的原子信息,例如总力、位置和速度,并使用速度-垂直算法。
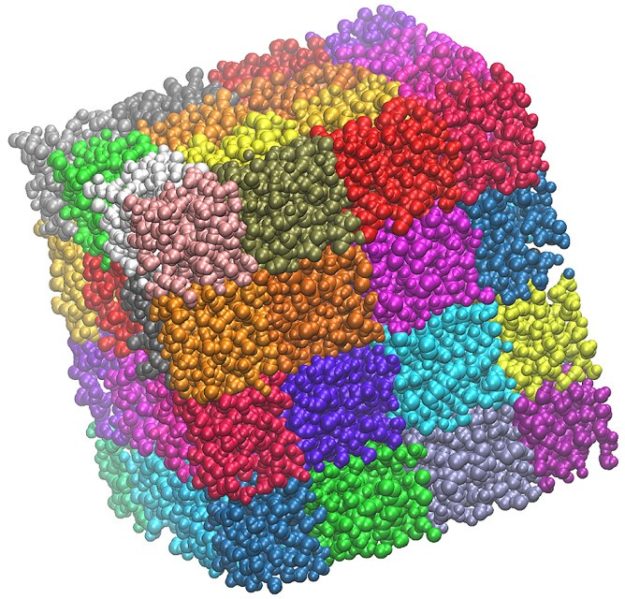 图3。NAMD中的三维区域分解。
图3。NAMD中的三维区域分解。将此代码移动到GPU需要处理补丁的组织方式。将数值积分运算盲目移植到CUDA上非常简单,因为它的大多数算法都是数据并行的。然而,由于对可伸缩性的关注,补丁过于细粒度,无法通过足够的集成操作完全占用GPU。此外,为了处理可能来自不同计算节点的远程力,NAMD包含一个默认基础设施,用于将GPU计算的力传递给远程节点上分配的补丁。
因此,要在集成期间受益于GPU功能,您不能依赖现有的NAMD补丁集成方案。然而,由于远程部队来自不同的节点,您必须通过该基础架构,因为需要通信信息。
为了解决这个问题,我们决定有一个特殊的代码路径来处理单节点模拟将是富有成效的,这样我们就可以避免必须通过CPU机制来通信部队。我们制定了一个方案,以实现以下目的:
- 从GPU力内核计算出力后立即获取力。
- 将它们格式化为阵列结构数据结构,以允许在集成期间使用常规内存访问模式。
- 聚合模拟中所有补丁的所有数据,以启动整个分子系统的单个集成任务(具有多个内核)。
补丁不再包含相关的原子信息,只是用来表示空间分解本身。
 图4。处理单节点仿真的工作流。
图4。处理单节点仿真的工作流。有了这个方案,就可以使用CPU来发布内核和仅处理I/O,同时完全使用现代GPU来执行相关的数学运算。
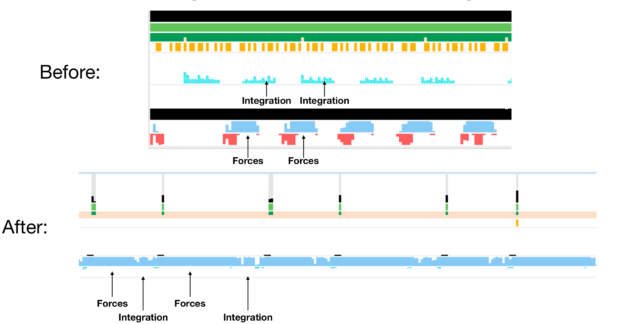 图5。Titan V上旧(a)和新(b)集成方案的比较。
图5。Titan V上旧(a)和新(b)集成方案的比较。如前所述,大多数集成内核都是数据并行操作。然而,其中一些在移植时需要谨慎。通常,如果用户需要更长的时间步长(2飞秒或更长),建议在模拟期间约束氢键长度(通常称为刚性键约束)。
此操作在数值积分过程中运行,如果操作不正确,可能会成为瓶颈。我们设计了一个单一内核来解决系统的所有约束设置处理水的算法和矩阵震动其他不属于水的氢键的变体。
此方案适用于NAMD3.0二进制的alpha版本,目前仅支持单GPU运行。目前正在开发使用多个完全互连的NVIDIA GPU的单弹道仿真支持。
要启用快速的单GPU代码路径,请将以下选项添加到NAMD config命令中:
--带单节点cuda
在NAMD配置文件中,设置CUDASOA集成到在.
为了获得良好的性能,正确设置以下性能调整参数非常重要:
每周期步数(NAMD 2.x默认值=20)每周期对数(NAMD 2.x默认值=2)边缘(名称2.x=0)
如果这些保留为未定义在模拟配置文件中CUDASOA集成启用后,NAMD会自动将其设置为建议的值,如下所示:
此外,频繁的输出限制了性能。最重要的是,输出能量(默认NAMD 2.x为1)应该设置得更高。如果保留为未定义在模拟配置文件中CUDASOA集成启用后,NAMD会自动将以下参数设置为与每周期步数,同样使用此默认值:
快速路径还不支持最小化。对于使用最小化的输入,应在两次单独的NAMD运行中执行最小化和动态。这个CUDASOA集成对于最小化运行,参数应设置为关闭。然后可以使用快速路径重新启动动态运行。
NAMD v3仍然在CPU上的周期之间运行原子重新分配。使用多个CPU内核仍然有一点好处。图6显示了使用不同CPU内核的v3性能卫星烟草花叶病毒(STMV)和APOA1号机组问题。
首先,不同CPU内核的性能变化不大。对于STMV,与单芯相比,使用10芯显示约10%的效益。然而,在约10个岩芯后,效益趋于稳定。这是意料之中的,因为原子分配只占总时间的一小部分,而且随着CPU内核的增多,回报也在逐渐减少。
另一方面,对于较小的APOA1问题,与使用一个内核相比,使用四个内核的好处约为5%。然而,使用四个以上的内核会稍微降低性能。这是因为更多的CPU线程会导致GPU计算部分的更多开销。对于较小的APOA1问题,当使用更多CPU内核时,这些开销可能变得不可忽略。
对于像STMV这样的大问题,它可以使用大约10个CPU内核。对于像APOA1这样的小问题,最好只使用几个CPU内核,例如四个。
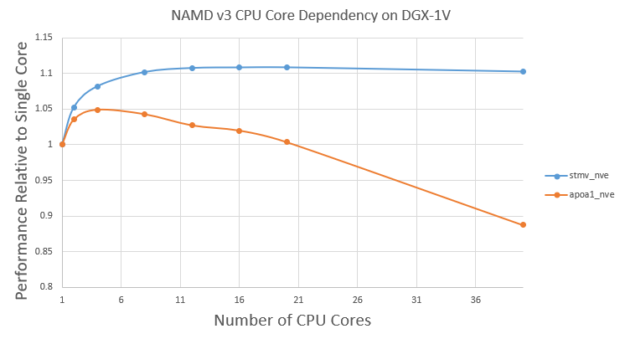 图6。DGX-1V上使用不同数量CPU内核的STMV和APOA1性能。
图6。DGX-1V上使用不同数量CPU内核的STMV和APOA1性能。对于v2.13,因为它是CPU绑定的,所以可以使用所有可用的CPU内核。对于v3,我们使用16核STMV和4核APOA1。
以下结果表明,在V100上,v3比v2.13快1.5-1.9倍。此外,对于STMV,A100上的v3比V100快约1.4倍,对于APOA1快约1.3倍。APOA1在A100上看到的好处较小,因为它不能充分利用所有的A100计算资源,因为原子数小得多。
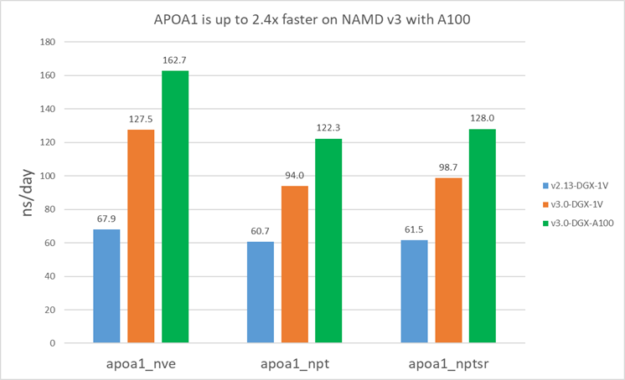 图7。单个V100和A100上的APOA1性能。
图7。单个V100和A100上的APOA1性能。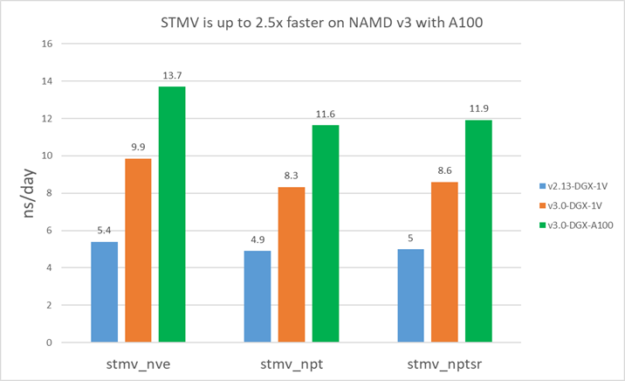 图8。单个V100和A100上的STMV性能。
图8。单个V100和A100上的STMV性能。正如我们在本文前面所讨论的,像APOA1这样的小问题无法完全使用所有A100资源。在这些情况下,您可以使用MPS在单个GPU上并发运行多个实例,以提高总吞吐量。
为了演示这一点,我们使用MPS在单个V100和A100上运行APOA1_NVE问题的多个实例。图9显示了V100和A100上的缩放。使用MPS运行多个实例可以将APOA1_NVE性能在V100上提高约1.1倍,在A100上提高大约1.2倍。A100获得了更多好处,因为它比V100拥有更多的流式多处理器,所以它的使用率更低。同样由于这个原因,V100需要大约两个实例来饱和,而A100需要大约三个实例来达到饱和。
值得注意的是,A100上APOA1_NVE的饱和性能是V100上的约1.4倍,这与预期的更大问题STMV类似。最后,值得注意的是,您还可以使用MPS运行不同输入问题的组合,以获得类似的好处。
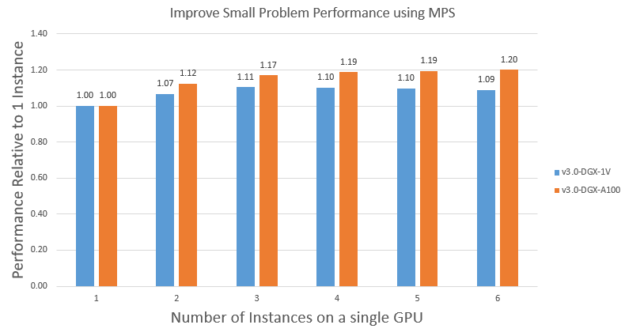 图9。APOA1_NVE使用MPS在单个GPU上聚合多实例性能扩展。这些数字分别缩放为V100和A100上运行的单个实例。
图9。APOA1_NVE使用MPS在单个GPU上聚合多实例性能扩展。这些数字分别缩放为V100和A100上运行的单个实例。A100引入了多实例GPU(MIG)。这为提高小问题的GPU利用率提供了另一种方法。MIG使用专用硬件资源将A100 GPU划分为多个实例:计算、内存、缓存和内存带宽。这允许并行执行具有硬件隔离的多个进程,以实现可预测的延迟和吞吐量。
MIG和MPS的主要区别在于,MPS不会为应用程序进程划分硬件资源。MIG提供了比MPS更多的安全性,因为一个进程不能干扰另一个进程。MIG支持将A100 GPU划分为1/2/3/7实例。图10显示了使用MIG在单个A100 GPU上运行1/2/3/7实例的聚合APOA1_NVE性能。
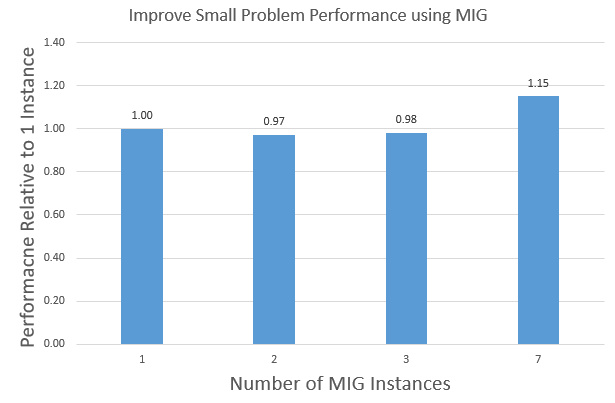 图10。使用MIG在单个A100上扩展APOA1_NVE聚合多实例性能.
图10。使用MIG在单个A100上扩展APOA1_NVE聚合多实例性能.基于多GPU的多副本仿真缩放
尽管到目前为止,v3中的GPU优化仅适用于单个GPU,但它确实有利于一些多GPU用例,如多副本模拟。当您在多GPU系统上并发启动多个副本模拟时,与只运行一个模拟相比,每次运行的可用CPU内核会减少。由于NAMD v2.13是CPU-bound的,因此多副本可扩展性预计并不理想。另一方面,由于v3性能对CPU的依赖性小得多,因此它的伸缩性会更好。
为了证明这一点,我们在多个GPU上同时启动了多个独立的STMV_NVE运行。每次运行使用所有可用CPU内核除以GPU数。图11比较了v2.13和v3从一个GPU到八个GPU的可扩展性。您可以看到v2.13的扩展性不太好:8个V100比1个V100快2.2倍。另一方面,v3在八台V100和八台A100上基本实现了线性加速。因此,在八个A100上,v3的多副本仿真性能比八个V100上的v2.13高出约9倍。
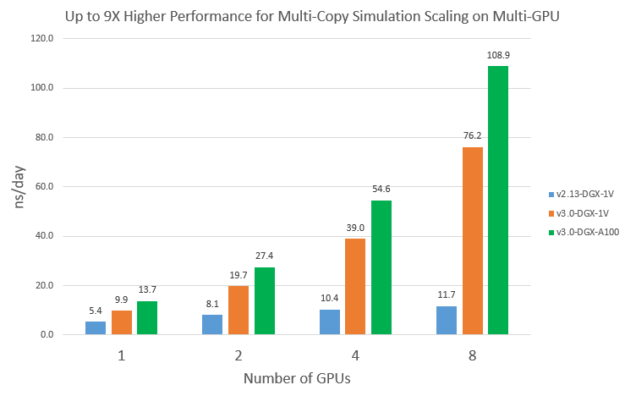 图11。DGX-1V和DGX-A100上的STMV_NVE多副本模拟多GPU缩放。
图11。DGX-1V和DGX-A100上的STMV_NVE多副本模拟多GPU缩放。NAMD v3是GPU绑定的,因此它有望在不同的CPU架构上执行类似的操作。为了证明这一点,我们在HPE阿波罗70系统上对v3进行了基准测试。该系统有两个ThunderX2 ARM64 28核CPU,GPU是V100-PCIE。V100-PCIE的时钟频率低于DGX-1V系统中的V100-SXM2。
为了公平比较,我们还使用V100-PCIE在x86系统上进行了基准测试。此x86系统上的CPU是Xeon E5-2698 v3。图12显示,NAMD v3在ARM系统上的性能基本上与x86系统相同。
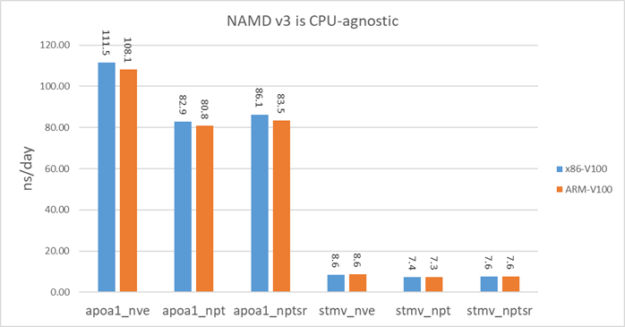 图12。x86-V100-PCIE和ARM-V100-PCIE上的NAMD v3性能。
图12。x86-V100-PCIE和ARM-V100-PCIE上的NAMD v3性能。接下来的步骤
要试用NAMD v3,下载容器来自NVIDIA NGC。
基准体系
我们在NVIDIA DGX-1V和DGX-A100系统上对NAMD v3进行了基准测试。DGX-1V系统有两个Intel Xeon E5-2698 v4 20核CPU和八个V100 GPU。DGX-A100系统有两个AMD Rome 7742 64核CPU和八个A100 GPU。
有关NAMD v3中更改的更多信息,请参阅基于NAMD的CPU和GPU体系结构上的可伸缩分子动力学.
有关伊利诺伊大学如何使用NVIDIA Nsight Systems优化NAMD分子动力学程序以进行GPU加速的更多信息,请参阅GTC 2020:平衡负载:使用Nsight系统对现代GPU的NAMD分子动力学程序进行轮廓引导优化.