语义学者的文学图形建构
@正在进行{Ammar2018ConstructionOT, title={语义学者中文学图形的构建}, 作者={Waleed Ammar、Dirk Groeneveld、Chandra Bhagavatula、Iz Beltagy、Miles Crawford、Doug Downey、Jason Dunkelberger、Ahmed Elgohary、Sergey Feldman、Vu A.Ha、Rodney Michael Kinney、Sebastian Kohlmeier、Kyle Lo、Tyler C.Murray、Hsu-Han Ooi、Matthew E.Peters和Joanna L。 Power、Sam Skjonsberg、Lucy Lu Wang、Christopher Wilhelm、Zheng Yuan、Madeleine van Zuylen和Oren Etzioni, booktitle={计算语言学协会北美分会}, 年份={2018年}, url={https://api.semanticscholar.org/CorpusID:19170988} }




353引文
开放式研究知识图中语义谓词的聚类
2022
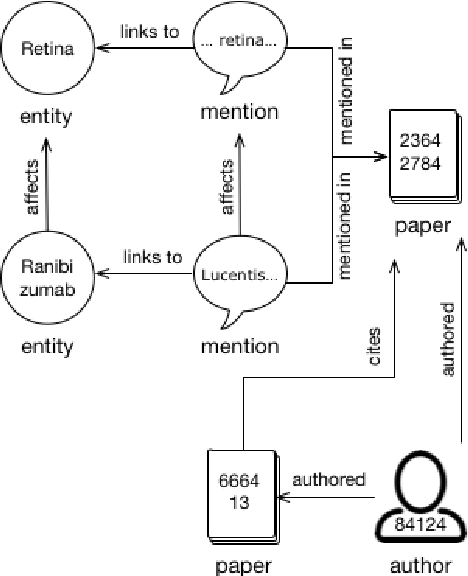
图形:查询语义学者的文学图形
2019
学术知识图完成的三重分类
2021
从书籍到知识图表
2023
科学文献中结构化信息的可扩展、半监督提取
2019
NLP知识图的端到端构造
2021
引文意图分类及其对构建引文图的支持证据提取
2023
26参考文献
Swanson链接重温:使用概念影响图加速跨领域基于文献的发现
2017
表EL:Web表中的实体链接
2015
TAGME:简短文本片段的即时注释(由维基百科实体提供)
2010
实体链接的设计挑战
2015
CiteSeerX:数字图书馆搜索引擎中的人工智能
2015
2017年夏季评估任务10:科学IE-从科学出版物中提取关键词和关系
2017
利用MEDLINE中的MeSH索引生成词义消歧数据集
2010