Wolfram AudioIdentify V1(沃尔夫拉姆音频识别V1) 培训时间
AudioSet数据
训练集信息
-
音频集 包括632个音频事件类的扩展本体,以及从YouTube视频中提取的2084320个带有人标签的10秒声音片段的集合。 本体论涵盖了广泛的人类和动物声音、乐器和流派,以及常见的日常环境声音。
示例
资源检索
 |
NetModel参数
 |
 |
 |
基本用法
 |
 |
![实体值[NetExtract(网络提取)[NetModel[“Wolfram AudioIdentify V1 Trained on AudioSet Data”],“Output”][[“Labels”]],“Name”]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/07679e85b10bdfcc.png) |
 |
特征提取
 |
 |
![提取器=NetChain[{NetMapOperator[singleFrameFeatureExtractor],AggregationLayer[Max,1],FlattenLayer[]},“Input”->NetModel[“Wolfram AudioIdentify V1 Trained on AudioSet Data”][[“输入”]]]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/568d30c73beb55c1.png) |
 |
![audios=压扁[线程[WebAudioSearch[#,“Samples”,#Duration<5&,MaxItems->20]->#]//@{“cow”,“bird”,“cat”}];](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/7e4c117bc541709a.png) |
 |
转移学习
![种子随机[42];{trainSet,testSet}=TakeDrop[随机样本[选择[audios,MatchQ[#[2]],“cow”|“bird”]&]],30];](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/23fc909c982ca9aa.png) |
![featuresNet=NetChain[{NetMapOperator(网络地图操作员)[NetDrop[NetExtract(网络提取)[NetModel(网络模型)[“Wolfram AudioIdentify V1 Trained on AudioSet Data”],{1,“Net”}],-3]],AggregationLayer[Max,1],FlattenLayer[]},“Input”->NetModel[“Wolfram-AudioIdentify V1 Trainify on AudioSet Data”][[“输入”]]]](https://www.wolframcloud.com/obj/resourcesystem/images/d59/d5998df5-78c4-4160-88df-ebdc5672a403/610ad418b719166a.png) |
 |
 |
 |
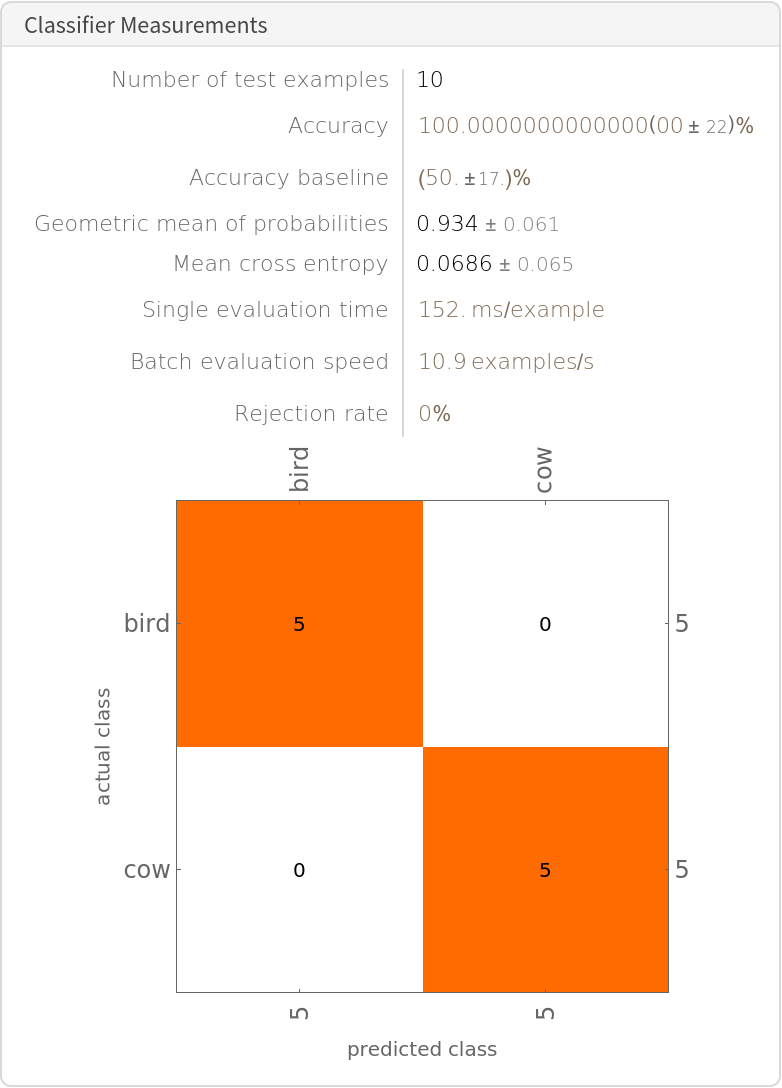 |
净信息
 |
要求
资源历史记录
参考
-
沃尔夫勒姆研究公司 可从以下位置获得: https://reference.wolfram.com/language/ref/AudioIdentify.html