总结
导出了整值随机变量的有效概率预测。通过在给定的广义模型类上非参数地估计预测分布,并证明在该设置下的渐近(非参数)效率,可以实现最优化。该方法是在整数自回归模型类的上下文中开发的,该类适用于任何可以解释为队列、股票、生死过程或分支过程的计数数据。模拟结果补充了渐近效率的理论证明,证明了在大但有限的样本中,非参数估计器相对于指定错误的参数替代方案的总体优越性。该方法被应用于股票市场冰山订单的计数。采用子抽样方法评估全估计预测分布中的抽样变化,并证明了其有效性。
1.简介
本文提出了一种预测由整数自回归(INAR)类建模的计数时间序列数据的方法。与离散样本空间一致并量化与未来计数相关的所有不确定性的预测是通过估计预测生成的分配在所有范围内。安事前通过对到达过程进行非参数化处理,并证明估计的预测分布的渐近(非参数)效率,导出了INAR类的最优估计。子采样(Politis等人。,1999)用于提供一种新的技术,用于评估和可视化整个预测分布的采样变化。该技术与标量点预测的传统预测区间类似,但自动确保概率的非负性和1之和属性保持不变。证明了子抽样方法的理论有效性。
INA类是一个非常大的计数数据时间序列集合的行为或结构模型。简言之,任何可能被认为是队列成员数量(例如,人、公司或订单)、库存或库存单位数量、出生和死亡过程的结果或移民分支过程的数据系列都可以由INAR类建模。因此,课程范围足够广泛,足以保证开发定制的预测策略,供从业者使用。INAR模型的最新应用包括:Franke和Seligmann(1993)Pickands和Stine(1997)和红衣主教等人。(1999)(医学);博肯霍尔特(1999)(营销);蒂雷戈德等人。(1999)Pavlopoulos和Karlis(2008)(环境研究);Brännäs和Hellstrom(2001)和Rudholm(2001)(经济学);古里鲁和贾西亚克(2004)(保险)。
作为一个观测驱动类,INAR模型允许似然函数的闭式表示,预测分布的非参数估计是通过经验似然最大化产生的。因此,从实用的角度来看,该方法的实现相对简单。特别是,完全避免了在离散(非高斯)状态空间设置中生成概率预测通常需要的计算要求更高的模拟方法。
本文组织如下。在第2节我们概述了计数时间序列的INAR模型的结构,并讨论了非参数最大似然估计(NPMLE)在该环境中的应用。然后证明了基于NPMLE的预测分布估计的渐近效率,并证明了定义预测分布的映射的可微性附录A还提供了与估算方法实施相关的计算细节。预测分布的渐近有效估计量(AEE)在INA类中的有限样本性能通过模拟记录在第3节特别是,在大样本但有限样本中,说明了AEE相对于基于错误指定的模型参数最大似然估计量(PMLE)的预测分布估计量的总体优势。在第4节描述了子采样方法,并证明了其理论有效性。然后将AEE应用于德国股市“冰山”订单的时间序列,该订单构成队列中元素随时间变化的数量记录,并适当建模为INAR过程。第5节得出结论。
本文中报告的所有数值结果都是使用GAUSS9.0软件包生成的。用于生成经验结果的程序可以从http://www.blackwellpublishing.com/rss
2.整数自回归类中的概率预测
INAR模型是由Al-Osh和Alzaid首次推出的(1987)和麦肯齐(1988). 杜和李等人对此进行了进一步调查(1991),迪翁等人。(1995),拉图尔(1998),伊斯帕尼等人。(2003)、弗里兰和麦卡贝(2004),郑等人。(2005)、McCabe和Martin(2005)、席尔瓦和奥利维拉(2005)、Jung和Tremayne(2006)、朱和乔(2006)Neal和Subba Rao(2007)、Bu和McCabe(2008),布等人。(2008)和Drost等人。(2008,2009). 麦肯齐(2003)提供了对模型类的回顾。在第2.1节我们概述了INA类和NPMLE的属性。接下来是,在第2.2节通过证明基于NPMLE的预测分布估计量的渐近效率。
2.1. 整数自回归类中的非参数极大似然估计
本着杜丽的精神(1991)我们定义了INA(第页)类将被创新在哪里{ɛt吨}是一个具有分布的独立同分布过程G公司.分布G公司= {克对}是集合上概率的离散序列.条件启用X(X)t吨−k,k∈ {1,2,…,第页}、细化运算符αk∘X(X)t吨−k,k∈ {1,2,…,第页},为二项式,定义为其中每个集合{B我,k,t吨,我= 1,2,…,X(X)t吨−k}由具有细化参数的独立分布贝努利随机变量组成(概率为B我,k,t吨= 1)αk和集合是相互独立的。假设αk∈[0,1),对于所有k∈ {1,2,…,第页},还有那个。这些创新被视为独立于所有稀释操作。初始值(X(X)0,X(X)−1,…,X(X)−第页)是模型平稳分布的独立图,因此,在上述条件下,X(X)t吨也是一个严格稳定的过程。模型的无限维参数为θ= (α1,…,α第页,G公司). 时间t吨,每个细化操作符执行以下操作之一第页带参数的二项式实验(X(X)t吨−k,αk),k∈ {1,2,…,第页},以确定从该时间段起在系统中存活的数量。什么时候?αk接近0,预计几乎没有幸存者t吨−k年份,相应地,当αk接近1。考虑年份X(X)t吨。在t吨+1,X(X)t吨被稀释了α1而且,当时t吨+2,X(X)t吨再次变薄,但使用α2因此X(X)t吨分布在未来时代t吨+1,t吨+2,…根据滞后的数量和细化参数的大小。这考虑到了X(X)t吨跨多个时间段传播。更正式地说,当第页>1、迪翁等人。(1995)表明INA(第页)这个过程通常可以被视为一个特殊的具有移民的多类型分支过程。
什么时候?第页= 1,X(X)t吨行为就像一个队列,按时到达t吨由代表ɛt吨以及队列中剩余的幸存者t吨-1至t吨,由α1∘X(X)t吨−1或者,该模型可以被认为是一个生与死或库存过程,其附加(出生)由ɛt吨和损失(死亡)(X(X)t吨−1−α1∘X(X)t吨−1). 什么时候?G公司是泊松和第页=1,该模型称为泊松自回归,因为在这种情况下X(X)t吨也是泊松。
对于任何一组值我0,我1,…,我第页在里面定义函数哪里和 空和取0,因此.表达式(2)给出了概率P(P)(X(X)t吨=我0|X(X)t吨−1=我1,…,X(X)t吨−第页=我第页;θ)模型下(1)是的卷积第页二项式与到达分布G公司= {克对}. 给定观察计数x个1,x个2,…,x个T型,经验可能性(给定初始观察值)为哪里P(P)(X(X)t吨=x个t吨|X(X)t吨−1=x个t吨−1,…,X(X)t吨−第页=x个t吨−第页;θ)=(f)x个t吨|x个t吨−1,…,x个t吨−第页(θ). 什么时候?第页=1,这些表达式大大简化 参数空间为,其中是离散概率分布的空间为了获得NPMLE,方程式(4)在0⩽上最大化αk<1,k= 1,2,…,第页、和哪里和克+=最大值t吨=第页+1,…,T型(x个t吨). NPMLE表示为包含一个向量,它是α= (α1,…,α第页)′、和序列,它是分布的估计量G公司= {克对}. (为了简化符号,我们抑制了估计量的依赖性,如,关于样本量T型). 序列估计器只包含有限个数,克+−克−,有限样本中的非零值,但当T型→∞. 让第页-表示维欧几里德空间并让绝对可和序列的Banach空间为我1.参数空间Θ是Banach空间的子集以及任何已分区小时= (小时,小时G公司). 我们使用和范数哪里和、和小时α,j个和小时G公司,j个分别是j个第个元素小时和小时G公司因此,被认为是空间的随机元素.
Drost公司等人。(2009)建立了INAR类中NPMLE的渐近正态性和有效性。(参见Drost等人。(2008)相关工作)让α*和是表达式中二项式概率和到达分布的真值(1)、和θ*=(α*,G公司*). 什么时候?G公司*具有有限的第页+4个力矩和、Drost等人。(2009)表明NPMLE是定期的(范德法特(1998),第25节)和渐近高斯,即。哪里N个是一个第页-维零均值正态随机变量,是一个以高斯为中心的过程我1和''表示弱收敛。此外,Drost等人。(2009)证明了哈耶克卷积定理意义上的渐近效率(参见范德法特(1998),定理25.20)。让是一个正则估计量;然后哪里W公司和是独立于高斯过程的“噪声”过程因此,任何其他常规估计量的协方差结构都“超过”NPMLE,而NPMLE是最佳的常规估计量。这就是理解非参数渐近效率的意义。 2.2. 整数自回归类中的有效预测
首先,我们处理一步到位的预测,然后处理米-阶梯式案例。在模型中(1)一步预测概率P(P)(X(X)T型+1=我0|X(X)T型=x个T型,…,X(X)T型−(第页−1)=x个T型−(第页−1);θ),对于任何,又是一个卷积第页二项式和创新分布以及这个卷积更简洁地写为通过使用函数(2)因此,一步预测分布和是来自巴拿赫空间的映射到巴纳赫空间我1,定义见第2.1节在概率预测中,目标是估计一步一头分布。在应用程序中,θ在里面方程式(7)将由NPMLE取代,在以下意义上是渐近有效的第2.1节。这表明可以继承并且也是渐近有效的,如果映射足够平滑。平滑度要求存在导数映射在相同的两个空间之间。为了激发这种映射的结构,请考虑函数的全微分(2)关于αk,k= 1,2,…,第页和有限数量的概率克对这包括指定偏导数,用增量线性加权并求和。表达式(9)在下面的定理1中,执行该计算并允许无限多的概率。然后定理显示了该表达式(9)实际上是一个导数映射。证据见附录A. 定理1。定义如中所示方程式(8),地图Fréchet可与导数微分吗,其中是具有典型元素的有界线性算子 特别是对于我们有.
自NPMLE以来在Drost条件下渐近有效等人。(2009)中指定的第2.1节由于Fréchet可微性意味着Hadamard可微性,因此van der Vaart的命题2(1995)和定理1一起意味着对于一步一头分布也是渐近有效的。因此,是预测分布的AEE(对于米=1)在INAR类中。
我们可以通过哈耶克卷积定理更具体地解释渐近有效预测分布的含义。因为,在表达式中(6),因为空间和我1是线性空间,它是范德法特定理20.8的结果(1998)那个 根据上面的定理1也是一个高斯过程因此,任何其他适当标准化的预测映射,基于θ,必须具有协方差过程不小于的极限分布根据哈耶克卷积定理。
什么时候?第页=1,对于,作为其中二项式概率,第页j个|x个T型(α1),在表达式中给出(3).估计分布,哪里是NPMLE,对于分布是渐近有效的在Drost条件下等人。(2009). 治疗米-阶梯式机箱,用于米>1,由于模型(1)也可以被视为来自到。这种解释允许米-递归定义的阶跃预测分布(例如,请参见Resnick(1992),第2.3节、Bu和McCabe(2008),除了下节提供的计算细节外),即。和 对于任何米,那个是Banach空间之间的映射。这个映射也是足够光滑的,这是下面定理的结果,定理的证明在附录A.
定理2。假设对一些人来说秒>1.对于每个,递归定义,使用方程式(7)和(12),并设置然后是地图Fréchet是可微的,即。是满足以下条件的有界线性算子对于任何米>1. 因此,是的AEE米-Hajek卷积定理意义上的提前预测分布,对于任何米⩾1.条件对于任何第页许多著名的分布(例如泊松分布和负二项分布),对于任何具有有限支持度的分布来说都是如此。对于带参数的泊松分布λ(磅/平方英寸(λ)),对于任何秒因为Pois(秒第页λ)分布有2个第页有限力矩。对于负二项分布,我们有对于任何秒<π−1/第页如将斯特林公式应用于求和中的伽马函数所示。 2.3. 计算细节
对于第页⩾1,似然函数(条件是第页初始值)是条件概率的乘积对于t吨=第页+1,…,T型一步预报分布的AEE,通过简单地替换θ= (αk;k= 1,2,…,第页,{克对})转换为表达式(15)并评估支持的条件概率我0= 0,1,…,K(K),使用K(K)选择以确保估计所有预测质量。然而,扩展Bu和McCabe(2008)对于非参数情况,此计算给出了另一种表示,这对于米>1步预测。具体而言,INAR(第页)这个过程可以看作是一个马尔可夫链X(X)t吨假设(实际上)值{0,1,…,K(K)}时间t吨,系统状态由第页-可能值的元组。因此,在当时T型,链条可能位于(K(K)+1)第页状态:作为(X(X)T型−(第页−1),…,X(X)T型)假设值(j个第页−1,j个第页−2,…,j个0) ∈S公司.定义(K(K)+1)第页×(K(K)+1)第页转移概率矩阵问具有元素和(K(K)+1)第页×1矢量πT型和πT型+1具有(分别)元素和条件分布(16)因此可以通过计算得到并从中选择πT型+1附加到的概率X(X)T型+1,结束我0= 0,1,…,K(K),取决于观测值X(X)T型=x个T型,X(X)T型−1=x个T型−1,…,X(X)T型−(第页−1)=x个T型−(第页−1)。对于米>向前一步,我们利用马尔可夫链理论来定义使用米-阶跃预报分布从中提取.AEE米-阶跃预测分布是通过简单替换生成的θ通过在所有计算中。 如果数据可以清楚地解释为排队(或股票或生死)过程的结果,则选择第页=1是合适的。在应用分支过程解释的情况下,可以选择第页需要在计算AEE之前进行。与在更标准的时间序列设置中选择滞后长度的情况一样,可以通过非正式的初步诊断测试,或通过某种更正式的模型选择标准(例如Akaike信息标准)来做出此决定。然而,考虑到此处对预测性能的关注,可能更合适的是,AEE可以计算为每个与不同值第页(在合理范围内)离职后预测准确性评估(使用实现值),然后用于选择一最优预测分布。
3.整数自回归类中的有限样本性能
在第2.2节我们证明了非参数估计的渐近有效性米-INA中的步进预测分布(第页)的模型米⩾1.在本节中,我们记录了非参数估计器的有限样本性能,并与分别基于正确和错误指定的PMLE的预测分布估计器进行了比较。我们认为INA(第页)模型中的数据生成过程(1)具有第页=1和α1= 0.6. 我们假设ɛt吨以泊松、泊松分布(λ=2),二项式,Bin(n个= 4;π=0.4)和负二项式,NBin(v(v)= 5;π=0.3)(质量函数如表达式所定义(14)). 这些分布分别代表了到达时间的等分散分布、欠分散分布和过分散分布。考虑到INAR(1)模型的结构,这些规范反过来产生了低计数数据,这些数据也分别是均匀分布、欠分散和过度分散的;参见Pavlopoulos和Karlis的示例(2008). 的价值α1选择近似于经验NPMLEα1用于中分析的数据第4节.我们专注于一步预测分布(即。米=1),为了便于记法,我们表示,(英寸方程式(11))由(f)我,,使用符号{(f)我}表示预测概率的完整序列.
将AEE的性能与{(f)我}基于PMLE对具有泊松到达的INAR(1)模型(即规范泊松自回归模型)的应用。当真实到达为泊松分布时,这种基于PMLE的预测分布估计器基于正确指定的模型,在这种情况下,预计其性能优于AEE。在真实到达为二项式或负二项式的情况下,基于PMLE的估计器基于错误指定的模型。这里的兴趣在于确定AEE是否以及在多大程度上优于基于PMLE的估计器。(为了简单起见,在下文中,我们使用缩写PMLE来表示预测分布基于在PMLE上,并在这些各自的情况下,将此估计预测分布称为“正确指定”和“错误指定”。)所有结果都基于10000次的复制{(f)我}。
修复的值我然后让是平方误差的简单平均值超过10000次复制,其中表示AEE值我。AV。MSE’-记录在第一中的结果行表1是平均误差的估计值,通过平均值计算在支架上方我= 0,1,…,K(K),使用K(K)选择以确保估计所有预测质量。下一行中记录的数字(括号中)给出了AV的比率。AEE的MSE与PMLE的相应度量。AV值。MSE比率小于1表明AEE在测量准确性方面更优越。
表1AEE和PMLE在预测支持的不同部分在不同分布下的有限采样性能ɛt吨(α1= 0.6)†
| ɛ的结果t吨∼泊松,λ= 2. | ɛ的结果t吨∼二项式,n个= 4,π= 0.4. | ɛ的结果t吨∼负二项式,v(v)= 5,π= 0.3. |
|---|
| T型= 100. | T型= 500. | T型=1000. | T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型=500. | T型= 1000. |
|---|
| AV.视频。AEE总MSE i |
| 0.0005 | 8.5×10−5 | 5.1×10−5 | 0.0005 | 0.0001 | 4.0×10−5 | 0.0005 | 0.0001 | 4.0×10−5 |
| (4.947) | (4.425) | (5.614) | (1.194) | (0.313) | (0.153) | (3.329) | (0.883) | (0.457) |
| AV.视频。上10%尾部AEE的MSE |
| 0.0002 | 3.1×10−5 | 3.4×10−5 | 0.0002 | 3.9×10−5 | 1.7×10−5 | 0.0002 | 2.9×10−5 | 1.2×10−5 |
| (5.231) | (4.343) | (10.274) | (1.396) | (0.374) | (0.188) | (4.080) | (1.385) | (0.737) |
| 平均值。下25%尾部AEE的MSE |
| 0.0006 | 0.0001 | 5.1×10−5 | 0.0005 | 0.0001 | 5.1×10−5 | 0.0007 | 0.0001 | 5.2×10−5 |
| (4.051) | (3.647) | (3.742) | (0.775) | (0.202) | (0.101) | (2.625) | (0.530) | (0.251) |
| ɛ的结果t吨∼泊松,λ= 2. | ɛ的结果t吨∼二项式,n个= 4,π= 0.4. | ɛ的结果t吨∼负二项式,v(v)= 5,π= 0.3. |
|---|
| T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. |
|---|
| AV.视频。AEE总MSE i |
| 0.0005 | 8.5×10−5 | 5.1×10−5 | 0.0005 | 0.0001 | 4.0×10−5 | 0.0005 | 0.0001 | 4.0×10−5 |
| (4.947) | (4.425) | (5.614) | (1.194) | (0.313) | (0.153) | (3.329) | (0.883) | (0.457) |
| AV.视频。上10%尾部AEE的MSE |
| 0.0002 | 3.1×10−5 | 3.4×10−5 | 0.0002 | 3.9×10−5 | 1.7×10−5 | 0.0002 | 2.9×10−5 | 1.2×10−5 |
| (5.231) | (4.343) | (10.274) | (1.396) | (0.374) | (0.188) | (4.080) | (1.385) | (0.737) |
| AV.视频。下25%尾部AEE的MSE |
| 0.0006 | 0.0001 | 5.1×10−5 | 0.0005 | 0.0001 | 5.1×10−5 | 0.0007 | 0.0001 | 5.2×10−5 |
| (4.051) | (3.647) | (3.742) | (0.775) | (0.202) | (0.101) | (2.625) | (0.530) | (0.251) |
表1AEE和PMLE在预测支持的不同部分在不同分布下的有限采样性能ɛt吨(α1= 0.6)†
| ɛ的结果t吨∼泊松,λ= 2. | ɛ的结果t吨∼二项式,n个= 4,π= 0.4. | ɛ的结果t吨∼负二项式,v(v)= 5,π= 0.3. |
|---|
| T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. |
|---|
| AV.视频。AEE在所有i上的MSE |
| 0.0005 | 8.5×10−5 | 5.1×10−5 | 0.0005 | 0.0001 | 4.0×10−5 | 0.0005 | 0.0001 | 4.0×10−5 |
| (4.947) | (4.425) | (5.614) | (1.194) | (0.313) | (0.153) | (3.329) | (0.883) | (0.457) |
| AV.视频。上10%尾部AEE的MSE |
| 0.0002 | 3.1×10−5 | 3.4×10−5 | 0.0002 | 3.9×10−5 | 1.7×10−5 | 0.0002 | 2.9×10−5 | 1.2×10−5 |
| (5.231) | (4.343) | (10.274) | (1.396) | (0.374) | (0.188) | (4.080) | (1.385) | (0.737) |
| AV.视频。下25%尾部AEE的MSE |
| 0.0006 | 0.0001 | 5.1×10−5 | 0.0005 | 0.0001 | 5.1×10−5 | 0.0007 | 0.0001 | 5.2×10−5 |
| (4.051) | (3.647) | (3.742) | (0.775) | (0.202) | (0.101) | (2.625) | (0.530) | (0.251) |
| ɛ的结果t吨∼泊松,λ= 2. | ɛ的结果t吨∼二项式,n个= 4,π= 0.4. | ɛ的结果t吨∼负二项式,v(v)= 5,π= 0.3. |
|---|
| T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. |
|---|
| AV.视频。AEE总MSE i |
| 0.0005 | 8.5×10−5 | 5.1×10−5 | 0.0005 | 0.0001 | 4.0×10−5 | 0.0005 | 0.0001 | 4.0×10−5 |
| (4.947) | (4.425) | (5.614) | (1.194) | (0.313) | (0.153) | (3.329) | (0.883) | (0.457) |
| AV.视频。上10%尾部AEE的MSE |
| 0.0002 | 3.1×10−5 | 3.4×10−5 | 0.0002 | 3.9×10−5 | 1.7×10−5 | 0.0002 | 2.9×10−5 | 1.2×10−5 |
| (5.231) | (4.343) | (10.274) | (1.396) | (0.374) | (0.188) | (4.080) | (1.385) | (0.737) |
| AV.视频。下25%尾部AEE的MSE |
| 0.0006 | 0.0001 | 5.1×10−5 | 0.0005 | 0.0001 | 5.1×10−5 | 0.0007 | 0.0001 | 5.2×10−5 |
| (4.051) | (3.647) | (3.742) | (0.775) | (0.202) | (0.101) | (2.625) | (0.530) | (0.251) |
中两个下部面板中显示的数字表1分别对应于真预测值的上10%尾部和下25%尾部的支架段{(f)我}. AV。每个面板中的MSE数字记录平均支持的相关部分,并测量AEE估计非常大(或非常小)计数发生概率的准确性(绝对值和相对于PMLE)。
AV。BIAS’-图显示在表2记录平均支持上10%尾部和下25%尾部,并捕获低估或高估非常大(或非常小)计数概率的现象。(由于估计分布和真实预测分布都满足求和限制,计数变量完全支持的估计偏差等于0)。记录在AV正下方行中的数字(在括号中)。AEE的BIAS度量给出了AEE度量与PMLE相应度量的比率。同样,小于1的比率值表明AEE在测量准确性方面更优越。AV的正值。BIAS比率表明二者都AEE和PMLE要么低估要么高估了相关的尾部质量。
表2预测支持尾部AEE和PMLE在不同分布下的有限采样性能ɛt吨(α1= 0.6)†
| ɛ的结果t吨∼泊松,λ= 2. | ɛ的结果t吨∼二项式,n个= 4,π= 0.4. | ɛ的结果t吨∼负二项式,v(v)=5,π= 0.3. |
|---|
| T型= 100. | T型= 500. | T型=1000. | T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. |
|---|
| AV.视频。上10%尾部AEE的偏差 |
| −0.0001 | −1.2×10−5 | 1.4×10−5 | −0.0004 | −0.0001 | −2.2×10−5 | 0.0002 | −2.5×10−5 | −1.7×10−5 |
| (−1.494) | (−1.580) | (−1.222) | (−0.943) | (−0.197) | (−0.077) | (−0.187) | (0.025) | (0.018) |
| AV.视频。下25%尾部AEE偏差 |
| −0.0003 | 0.0002 | 0.0001 | 1.9×10−4 | 1.8×10−4 | −1.6×10−5 | −0.0008 | 7.6×10−5 | −1.6×10−5 |
| (−0.278) | (0.778) | (0.799) | (0.022) | (0.022) | (−0.002) | (0.150) | (−0.011) | (0.002) |
| ɛ的结果t吨∼泊松,λ= 2. | ɛ的结果t吨∼二项式,n个=4,π= 0.4. | ɛ的结果t吨∼负二项式,v(v)= 5,π= 0.3. |
|---|
| T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. |
|---|
| AV.视频。上10%尾部AEE的偏差 |
| −0.0001 | −1.2×10−5 | 1.4×10−5 | −0.0004 | −0.0001 | −2.2×10−5 | 0.0002 | −2.5×10−5 | −1.7×10−5 |
| (−1.494) | (−1.580) | (−1.222) | (−0.943) | (−0.197) | (−0.077) | (−0.187) | (0.025) | (0.018) |
| AV.视频。下25%尾部AEE偏差 |
| −0.0003 | 0.0002 | 0.0001 | 1.9×10−4 | 1.8×10−4 | −1.6×10−5 | −0.0008 | 7.6×10−5 | −1.6×10−5 |
| (−0.278) | (0.778) | (0.799) | (0.022) | (0.022) | (−0.002) | (0.150) | (−0.011) | (0.002) |
表2预测支持尾部AEE和PMLE在不同分布下的有限采样性能ɛt吨(α1= 0.6)†
| ɛ的结果t吨∼泊松,λ= 2. | ɛ的结果t吨∼二项式,n个= 4,π= 0.4. | 的结果t吨∼负二项式,v(v)= 5,π=0.3. |
|---|
| T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. |
|---|
| AV.视频。上10%尾部AEE的偏差 |
| −0.0001 | −1.2×10−5 | 1.4×10−5 | −0.0004 | −0.0001 | −2.2×10−5 | 0.0002 | −2.5×10−5 | −1.7×10−5 |
| (−1.494) | (−1.580) | (−1.222) | (−0.943) | (−0.197) | (−0.077) | (−0.187) | (0.025) | (0.018) |
| AV.视频。下25%尾部AEE偏差 |
| −0.0003 | 0.0002 | 0.0001 | 1.9×10−4 | 1.8×10−4 | −1.6×10−5 | −0.0008 | 7.6×10−5 | −1.6×10−5 |
| (−0.278) | (0.778) | (0.799) | (0.022) | (0.022) | (−0.002) | (0.150) | (−0.011) | (0.002) |
| ɛ的结果t吨∼泊松,λ= 2. | 的结果t吨∼二项式,n个= 4,π= 0.4. | ɛ的结果t吨∼负二项式,v(v)= 5,π= 0.3. |
|---|
| T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. | T型= 100. | T型= 500. | T型= 1000. |
|---|
| AV.视频。上10%尾部AEE的偏差 |
| −0.0001 | −1.2×10−5 | 1.4×10−5 | −0.0004 | −0.0001 | −2.2×10−5 | 0.0002 | −2.5×10−5 | −1.7×10−5 |
| (−1.494) | (−1.580) | (−1.222) | (−0.943) | (-0.197) | (−0.077) | (−0.187) | (0.025) | (0.018) |
| AV.视频。下25%尾部AEE偏差 |
| −0.0003 | 0.0002 | 0.0001 | 1.9×10−4 | 1.8×10−4 | −1.6×10−5 | −0.0008 | 7.6×10−5 | −1.6×10−5 |
| (−0.278) | (0.778) | (0.799) | (0.022) | (0.022) | (−0.002) | (0.150) | (−0.011) | (0.002) |
如第一行中的所有数字所示表1AV。根据估计量的理论一致性,AEE的MSE随样本大小单调下降。这一结果也适用于下25%的尾部,在所有情况下,除一种情况外,适用于上10%的尾部。正如所料,AV。每个面板第二行(以及表的最左边部分)中的MSE比率表明,当真实分布为泊松时,根据这种精度测量,(正确指定的)PMLE在有限样本中比AEE更准确。在这种情况下,MSE比率超过1。
当真正的数据生成过程具有二项式到达时(记录在表1),AEE的AV较低。MSE比错误指定的PMLET型=500和T型=1000,在全支撑(顶部面板)和上下尾翼(下部两个面板)上。AEE的准确度仅略低于AV。以下三种情况中,有两种MSE比率略高于1T型= 100. AEE相对于PMLE的优势随着T型对于二项式到达下记录的所有案例。
在真负二项到达的情况下(记录在表1)对于两个较大的样本量,AEE优于错误指定的PMLE,无论是在完全支持还是在较低的25%尾部。最大样本量(T型=1000),AEE需要显示较小的AV。MSE比上部10%尾部的PMLE高。根据这一度量,估计值的准确性低于PMLET型所有情况下=100,AV。MSE比率从2.625(底部25%尾部)到4.080(顶部10%尾部)不等。
根据偏差结果表2,AEE是均匀地在二项式和负二项式到达下,优于(指定错误的)PMLE,PMLE具有AV。BIAS数字的范围是AEE对应值的670倍。中间部分的数字表2可以用来推导出PMLE一致高估当真实到达为二项式且数据(无条件)分散不足时,上10%和下25%的尾部概率都会出现。当真实到达为负二项式且数据(无条件)过度分散时,PMLE一致低估上10%和下25%的尾部概率。有趣的是,在泊松到达情况下,在正确指定PMLE的情况下,AEE在估计低25%尾部时的偏差为较小的对于所有样本大小,与PMLE相关的值。在估计上10%尾部的情况下,这种优势并不存在。在任何到达过程中,AEE都没有表现出低估或高估预测分布尾部的系统趋势。
4.实证应用
4.1. 数据的描述
在本节中,我们将AEE应用于计数数据的经验系列。该系列包括T型=每10分钟在德意志交易所的XETRA系统上收集的德国电信(DT)股票订单簿中的480个冰山销售订单(“sks”)(最多包括第五个最佳订单)。数据记录在2004年第一季度最后10个交易日(最后两个交易周)的每个交易日的8小时内。
冰山订单之所以被称为冰山订单,是因为订单中只显示了订单量的一部分,或“冰山一角”。此类订单仅占限额账簿订单总数的一小部分,例如,Frey和Sandas分析的德国股票组合中提交的订单仅占9%(2009). 然而,事实证明,它们对交易行为以及随后的交易价格动态行为产生了重大影响,因为交易员面对与冰山相关的“隐藏流动性”调整了他们的买入(或卖出)价格。交易员不仅不知道冰山订单的隐藏量有多大,而且交易所在交易时也没有明确表示此类订单的存在。因此,交易员自己需要采取各种策略来确定冰山订单的数量和规模;见Frey和Sandas(2009)供进一步讨论。
在任何10分钟的时间段内t吨冰山订单数量,X(X)t吨,是前10分钟内剩余的等待执行的订单数量的总和,α1∘X(X)t吨−1以及账簿中新的冰山订单数量(或“到达”),ɛt吨。交易日结束时,所有冰山订单都会从账簿中删除,即使没有执行。请注意,虽然订单簿每10分钟扫描一次,直到达到最佳五个订单的深度,但冰山交易很可能在10分钟内的任何时候都是最佳五个交易订单之一,导致在任何10分钟间隔后都会记录超过五个冰山交易。然而,由于冰山订单很少发生,因此在这个特定样本期内的DT数据仅假设值为0到5(包括0到5)。与值{0,1,2,3,4,5}关联的样本比例为{0.479,0.323,0.119,0.058,0.017,0.004}。样本计数的平均值和标准偏差分别为0.823和1.009,这导致了一些过度分散,而待建模数据中没有明显的日内(昼间)模式。DT数据的样本自相关函数显示了短记忆自回归过程的特征指数下降,一阶自相关系数为0.576,显著系数达到并包括滞后12,表明数据中确实存在建模依赖性和预测能力。鉴于数据可以明确地解释为队列或股票变量的时间序列观测值,INAR(1)规范在本质上是合适的;NPMLEα1假设值为0.551。
4.2. 抽样误差评估
除了在给定时间范围内生成预测分布的有效点估计外,我们还提出了一种评估抽样变化影响的方法。特别是,我们旨在描述完整预测分布中的变化,并以易于理解的方式呈现此信息。为此,我们使用重采样方法,以可视化估计预测分布中采样波动的影响,同时保留概率的非负性和总和为1的属性。
我们采用政治学的子抽样方法等人。(1999). 虽然与Carlstein的自助方法没有什么不同(1986)、昆士(1989)刘和辛格(1992)对于平稳时间序列,子抽样方法更为普遍适用,而且在抽象的巴拿赫空间设置(如上述定理1和2中的设置)中更容易验证。首先,我们描述了子采样过程,包括用于选择数字的数据相关方法b条这是子样本的大小。然后,我们给出了一个定理,证明在当前设置中使用子采样过程是正确的。
子采样方法的实现包括以下步骤。
第1步:获取T型−b条+1个子样本年1===============================================================(X(X)1,…,X(X)b条),年2= (X(X)2,…,X(X)b条+1),…,年T型−b条+1==========================================================(X(X)T型−b条+1,…,X(X)T型).
第2步:使用的NPMLEθ,,计算自年t吨,t吨= 1,2,…,T型−b条+1和观察值,x个T型,x个T型−1,…,x个T型−(第页−1),计算米-提前预测分布,米⩾1.
步骤3:计算度量,其中是基于经验数据的估计预测分布NPMLE。
第4步:找到的第95个百分位{d日b条,1,…,d日b条,T型−b条+1},以及相应的分布F类0.95.
然后,相对于复制的分布和‖·‖1距离,将分布视为或更“极端”的可能性F类0.95为5%。
选择b条实际上,我们遵循《政治》中的建议等人。(1999)(第9章)。
- (a)
对于每个b条∈ {b条小的,…,b条大的}执行上面的步骤1-4进行计算.
- (b)
对于每个b条计算不及物动词b条作为2的标准偏差k+1个相邻值(用于k= 2).
- (c)
选择最小化不及物动词b条.
证明子抽样(和引导)程序有效性的本质是证明基于复制分布的概率声明与基于实际抽样分布的概率陈述(渐近)相同。因此,对于合适的规范(例如d日b条,t吨定义复制的经验分布和问T型(x个)成为的抽样分布规律,θ*是真正的参数值。在表达式中(17),我{·}是指示符函数。子采样方法的有效性要求问T型,b条(x个)负极问T型(x个)在适当的意义上收敛到0。这种收敛性是以下定理的内容,其证明在附录A. 定理3。假设该模型(1)为进程保留X(X)t吨.何时b条→∞和T型→∞具有b条/T型→0,哪里ρL(左)是有界Lipschitz度量。 根据定理3,对于足够大的T型,基于经验分布的报表相当于基于以下(未知)抽样分布的语句因此,我们可以使用子采样过程生成如下语句
“看到估计的与真的预测分布与或更极端F类0.95(计算自问T型,b条(x个))为5%。
4.3. 实证预测结果
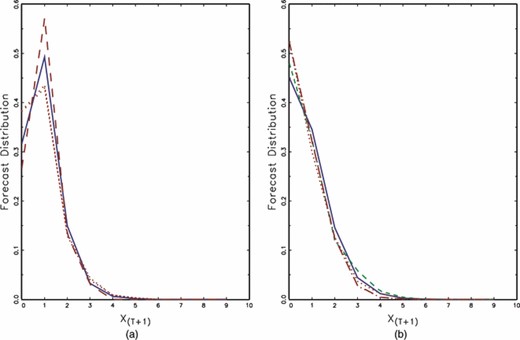
在图1(a)我们重现了估计的一步法水头(米=1)DT数据的预测分布,以及根据B=T型−b条+1个复制,带有b条=235(通过上述步骤(a)-(c)选择)。考虑到度量的极值可能与预测分布中的不同形状相关,我们记录了第95个百分位处的(子抽样)预测分布以及排名在第95个百分点两侧的分布。
图1
DT冰山数量的一步预测分布和五步预测分布(T型=480):(a)估计的一步预测分布加上子样本分布( ,AEE;--,第95百分位;····,第95百分位±1);(b) 估计的五步预测加子样本分布和样本比例(
,AEE;--,第95百分位;····,第95百分位±1);(b) 估计的五步预测加子样本分布和样本比例( ,AEE- - - - - -, 样本比例;--,第95百分位;······,95%±1)
,AEE- - - - - -, 样本比例;--,第95百分位;······,95%±1)
估计的预测分布仅为以下事件分配了32%的概率不DT冰山订单被列入2004年第一季度最后一个交易日最后10分钟的五个最佳订单。这表明一些隐藏流动性的程度很可能是可用的(Prob(X(X)T型+1⩾1)=0.68),需要在交易决策中得到满足。第95个百分位两边的“极端”分布表明零级事件的概率增加,存在某种程度的隐藏流动性的概率相应降低。然而,极端分布在第95百分位分配较少的概率质量为零级,相应地,更多出现至少一个冰山订单的概率。这些结果说明了抽样可变性如何改变关于预测分布支持的概率质量,从而改变从分析中得出的结论的定性性质。
在图1(b),我们重现了米=向前5步,以及以第95个百分位为中心的三个子样本分布(基于b条= 260). 使用中描述的马尔可夫链方法估计五步前向分布第2.3节由于模型的平稳性,根据样本比例(记录在图1(b)同时)。
5.讨论
本文提出了一种预测整值时间序列数据的方法。该方法涉及估计离散随机变量的预测分布,从而生成相干预测,量化与未来计数相关的全部不确定性。对于广泛的INAR类,通过似然方法生成预测分布的渐近(非参数)有效估计。对INAR(1)模型的模拟结果表明,即使在中等大小的样本中,AEE也表现良好。最值得注意的是,对于样本大小为500和1000的样本,在估计预测分布的尾部时,AEE的偏差明显小于错误指定的参数比较器,因此,在未来时间段内,极值计数(低计数和高计数)的概率也是如此。对于此类样本量,AEE总体上更准确二者都偏差和均方误差,比预测分布的参数估计值指定错误。
我们还提出了一种有效的子抽样方法,用于评估AEE中抽样变化的影响,该方法结合了所涉及概率的非负性和总和属性。分析了一组可能被解释为INAR结构输出的数据,通过子抽样技术估计了预测分布并量化了抽样变化。
这个事前当然,这里采用的预测方法不同于预测文献中通常采用的方法,在预测文献中,通过以下方式(从一组备选方案中)选择预测分布事后根据观察结果进行评估(见Dawid(1984)、泰和沃利斯(2000)、啃食等人。(2007)、啃食(2008)Geweke和Amisano(2010)示例和一般性讨论,以及Czado等人。(2009)用于将此类评估技术广泛应用于离散计数数据)。然而,我们的方法不应被视为是对利用已实现结果评估分配预测这一基本原则的竞争。事实上,这两种方法是相辅相成的。合适的模型类的存在提供了优化的优势,而经验验证可以防止不可预见的情况,例如数据生成过程中意外的结构中断。事实上,即使在课堂上内在地对于特定的计数数据集,在比较之前,在INAR类中生成(非参数)有效的预测分布仍然是明智的第一步事后方法-使用课堂外的相关替代方法。
最后,在一般的INA模型中包含协变量对于一些经验应用可能很重要。特别是,在到达的非参数规范中纳入协变量效应,如季节性,是一个公开的问题,目前作者正在探索。
致谢
这项研究得到了澳大利亚研究委员会发现拨款的支持。第二位作者还得到了澳大利亚研究委员会未来奖学金的支持。作者感谢联合主编、副主编和两位审稿人对该论文早期草稿提出了非常详细和建设性的意见。经德意志银行许可,Joachim Grammig、Robert Jung和Andy Tremayne友好地提供了经验数据。
工具书类
Al-Osh公司
,文学硕士。
和阿尔扎伊德
,答:A。
(
1987
)一阶整值自回归(INAR(1))过程
.J.时间序列。分析。
,8
,261
–275
.博肯霍尔特
,美国。
(
1999
)混合INAR(1)泊松回归模型:分析纵向计数数据的异质性和序列相关性
.《经济学杂志》。
,89
,317
–338
.布伦纳斯
,英国。
和赫尔斯特伦
,J。
(
2001
)广义整值自回归
.经济计量学。版次。
,20
,425
–443
.日分
,R。
,哈德里
,英国。
和麦卡贝
,下午2点。
(
2008
)高阶整值自回归过程的最大似然估计
.J.时间序列。分析。
,29
,973
–994
.日分
,R。
和麦卡贝
,下午2点。
(
2008
)INAR(p)模型中的模型选择、估计和预测:基于似然的马尔可夫链方法
.国际期刊预测。
,24
,151
–162
.红衣主教
,M。
,罗伊
,R。
和兰伯特
,J。
(
1999
)积分时间序列模型在疾病发病率分析中的应用
.统计师。医学。
,18
,2025
–2039
.卡尔施泰因
,E.公司。
(
1986
)使用子序列值估计平稳时间序列的一般统计方差
.安。统计师。
,14
,1171
–1179
.Czado公司
,C、。
,格奈廷
,T。
和持有
,L。
(
2009
)计数数据的预测模型评估
.生物识别
,65
,1254
–1261
.达维德
,A.P.公司。
(
1984
)统计理论:优先方法
.J.R.统计。社会学硕士
,147
,278
–292
.迪翁
,J.-P.公司。
,更高的
,G.公司。
和拉图尔
,答:。
(
1995
)具有移民和积分值时间序列的分支过程
.塞尔德郡。数学。J。
,21
,123
–136
.杜康
,第页。
(
1994
)混合:特性和示例
,第1版。柏林
:施普林格
.Drost公司
,F.C.公司。
,范登·阿克
,R。
和韦尔克
,B.J.M.博士。
(
2008
)INAR(p)模型的局部渐近正态性和有效估计
.J.时间序列。分析。
,29
,783
–801
.Drost公司
,F.C.公司。
,范登·阿克
,R。
和韦尔克
,B.J.M.博士。
(
2009
)半参数整值AR自回归参数和新息分布的有效估计(第页)模型
.J.R.统计。Soc.B公司
,71
,467
–485
.杜
,J·D·。
和锂
,年。
(
2001
)积分值自回归(INA(p))模型
.J.时间序列。分析。
,12
,129
–142
.弗兰克
,J。
和塞利格曼
,T。
(
1993
)INR(1)过程的条件最大似然估计及其在癫痫发作计数建模中的应用。在时间序列的发展
(编辑)。T。
苏巴·拉奥
),第页。310
–330
.伦敦
:查普曼和霍尔
.弗里兰
,R。
和麦卡贝
,下午2点。
(
2004
)低计数时间序列数据的泊松自回归分析
.J.时间序列。分析。
,25
,701
–722
.格威克
,J。
和阿米萨诺
,G.公司。
(
2010
)比较和评估资产收益的贝叶斯预测分布
.国际期刊预测。
,26
,216
–230
.格奈廷
,T。
(
2008
)概率预测
.J.R.统计。社会学硕士
,171
,319
–321
.格奈廷
,T。
,巴拉巴多伊
,F、。
和拉夫特里
,答:E。
(
2007
)概率预测、校准和清晰度
.J.R.统计。Soc.B公司
,69
,243
–268
.古里鲁
,C、。
和贾西亚克
,J。
(
2004
)异构INA(1)模型及其在汽车保险中的应用
.保险。数学。经济。
,34
,177
–192
.伊斯帕尼
,M。
,巴普
,G.公司。
和范祖伊伦
,M。
(
2003
)近不稳定INA(1)模型的渐近推断
.J.应用。普罗巴伯。
,40
,750
–765
.荣格(Jung)
,R。
,Ronning公司
,G.公司。
和特雷梅恩
,答:。
(
2005
)离散支持下条件一阶自回归的估计
.统计师。巴普。
,46
,195
–224
.荣格(Jung)
,R。
和特雷梅恩
,答:。
(
2006
)整数时间序列的二项细化模型
.统计师。莫德林
,6
,81
–96
.昆士(Kunsch)
,H.R.公司。
(
1989
)一般平稳观测的折刀和自举
.安。统计师。
,17
,1217
–1241
.拉图尔
,答:。
(
1998
)一类非负整值自回归过程的存在性和随机结构
.J.时间序列。分析。
,19
,439
–455
.刘
,R.Y.公司。
和辛格
,英国。
(
1992
)移动块jackknife和bootstrap捕获弱依赖性。在探索引导的极限
(编辑R。
LePage(LePage)
和L。
比亚尔
),页。225
–248
.纽约
:威利
.麦卡贝
,B。
和马丁
,G.公司。
(
2005
)低计数时间序列的贝叶斯预测
.国际期刊预测。
,21
,315
–330
.麦肯齐
,E.公司。
(
1988
)泊松计数相关序列的ARMA模型
.高级应用程序。普罗巴伯。
,20
,822
–835
.麦肯齐
,E.公司。
(
2003
)离散变量时间序列。在统计手册
,第21卷(编D.编号。
香巴格
和C.R.公司。
饶
),第页。573
–606
.阿姆斯特丹
:爱思维尔
.尼尔
,第页。
和苏巴·拉奥
,T。
(
2007
)积分值ARMA过程的MCMC
.J.时间序列。分析。
,28
,92
–110
.帕夫洛普洛斯
,H。
和卡利斯
,D。
(
2008
)具有环境应用的过分散计数序列的INAR(1)建模
.环境计量学
,19
,369
–393
.皮克兰德
,J。
和斯蒂恩
,R。
(
1997
)不完全信息M/G/1排队的估计
.生物特征
,84
,295
–308
.波利蒂斯
,D.编号。
,罗马诺语
,J.P.公司。
和狼
,M。
(
1999
)子采样
.纽约
:施普林格
.雷斯尼克
,S.I.公司。
(
1992
)随机过程中的冒险
.波士顿
:Birkhä用户
.鲁德霍姆
,N。
(
2001
)瑞典药品市场的进入和公司数量
.工业评论。Organizn公司
,19
,351
–364
.席尔瓦
,M。
和奥利维拉
,五、。
(
2005
)INA(p)模型的高阶矩和累积量的差分方程
.J.时间序列。分析。
,26
,17
–36
.泰伊
,A.S.公司。
和沃利斯
,英国。
(
2000
)密度预测:一项调查
.J.预测。
,19
,235
–254
.甲状腺
,第页。
,卡斯滕森
,J。
,马德森
,H。
和阿恩杰格·尼尔森
,英国。
(
1999
)倾卸斗降雨量测量的整值自回归模型
.环境计量学
,10
,395
–411
.范德法特
,A.W.公司。
(
1995
)无穷维M-估计的有效性
.统计师。尼尔兰。
,49
,9
–30
.范德法特
,A.W.公司。
(
1998
)渐近统计
.剑桥
:剑桥大学出版社
.朱
,R。
和乔
,H。
(
2006
)基于二项稀疏的马尔可夫过程计数数据时间序列建模
.J.时间序列。分析。
,27
,725
–738
.附录A
下面的初步引理用于下面的证明。如有要求,作者可提供证据。
引理1。如果第页j个|我(α)是二项式概率和小时那么是一个常数和如果|小时|<1然后绑定(19)可以减少到 我们还使用了关于二项式细化的著名结果α∘(x个1+x个2)=d日α∘x个1+α∘x个2和 A.1、。定理1的证明
简单的重新安排表明因此 上面的最后一步使用重新排列和我们现在可以在表达式中应用引理1的二项式边界(21)–(23). 使用的条件是小时α,k-位移绝对值和符号小于1D类=最大值1⩽u个⩽第页(我u个),我们发现这个表达式(21)有界,即。同样,我们发现(22)等于同样,表达式(23)有界因此,对于有限常数 为了表明这一点是有界的,我们写根据需要。 A.2。定理2的证明
我们将证明对于一些足够小的和D类=最大值1⩽u个⩽第页(我u个)其中C类米是一个有限常数。这意味着根据衍生工具的要求。定理1已经表明方程式(25)等待米=1,所以我们通过归纳法进行,假设它适用于米某些情况下为-1米⩾2.使用表达式(12)通过加减法我们获得 在定理1中,表达式(20)由表达式限定(21),(22)和(23)从而导致表达(24)这足以约束表达式(26b)。当我们考虑到下标时,相同的步骤序列约束表达式(26a)我0|我1,…,我第页被替换为我0|u个,我1,…,我第页−1所以D类=最大值1⩽k⩽第页(我k)由替换D类∨u个因此C类米−1表示一个常数,取决于米−1,表达式(26a)和(26b)的边界为哪里常量C类米是有限的,因为使用这是有限的足够小,以至于哪里秒>1是常数,因此.因此C类米足够小时为常数,这就完成了不等式的证明(27). 衍生产品在中是线性的小时通过归纳注意到了显然是线性的。地图也可以证明是有界的归纳法。特别是我们展示了对于某个有限常数B米如定理1的证明所示,这适用于米=1与B米= 1. 现在假设满足这个界限。由此可见哪里B米是一个常数。这个常数是有限的,因为在可和条件下克u个. 答3。定理3的证明
定理3的证明遵循Politis的定理7.3.1等人。(1999). Politis假设7.3.1等人。(1999)根据以下事实(连续高斯过程),这又是定理2的结果我1是可分度量空间;这对应于J型n个(P(P)) =问T型汇聚到J型(P(P)) =问关于的可分子集S公司(用Politis的符号表示等人。(1999)). 根据模型的马尔可夫链特性X(X)t吨完全有规律地混合(β混合)(参见Doukhan(1994)和Drost等人。(2009),命题2.1),这意味着X(X)t吨是α混合。最后τb条=b条1/2和τT型=T型1/2政治的所有规则性条件等人。(1999)都很满意。
©2011皇家统计学会







{kind=link}