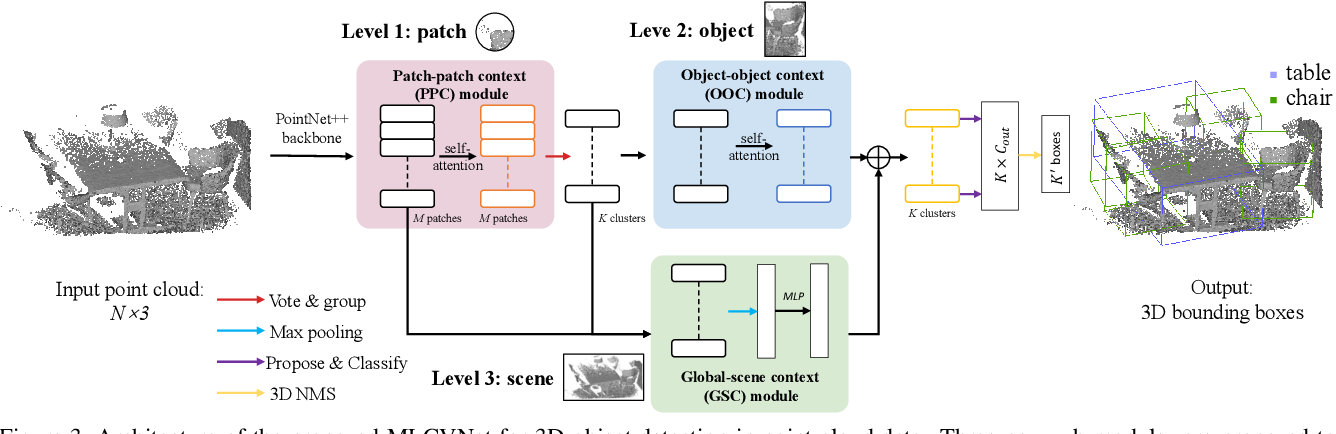
MLCVNet:用于三维目标检测的多级上下文投票网
@第{Xie2020 MLCVNetMC条, title={MLCVNet:3D对象检测的多级上下文投票网}, author={谢谦、赖宇坤、吴静、王周涛、张一鸣、徐凯、王军}, journal={2020 IEEE/CVF计算机视觉和模式识别会议}, 年份={2020年}, 页码={10444-10453}, 网址={ https://api.semanticscholar.org/CorpusID:214816776 } }











138引文
MCGNet:用于三维物体检测的多级上下文软件和几何软件网络
2022
CMR3D:三维目标检测的上下文化多级细化
2022
基于表面的多层上下文三维目标检测
2023
用于少快照三维点云目标检测的原型VoteNet
2022
SA-Det3D:基于自我注意的上下文软件3D对象检测
2021
3DLG-Detector:通过同步局部-全局特征学习进行三维目标检测
2022
ImGeo VoteNet:用于RGB-D对象检测的图像和几何体共同支持的VoteNet
2023
51参考文献
PanoContext:用于全景场景理解的全空间三维上下文模型
2014
基于Deep Hough投票的点云三维目标检测
2019
结构推理网:使用场景级上下文和实例级关系的对象检测
2018
用于自动驾驶的多视点三维目标检测网络
2017
用于自动驾驶的单目三维目标检测
2016
上下文在野外目标检测和语义分割中的作用
2014
用于点云中三维物体检测的关注点网
2019
上下文选择在目标检测中的作用
2016