In Linux, the shell script combined with the system task planning crontab can easily realize the work that can only be completed by some complex programs. The development cost is low, and it is easy to learn.
Zhang Ge's blog has also shared many wonderful applications of shell in website operation before, such as:
CCKiller: Linux lightweight CC attack defense tool, second level check, automatic blackout and release
SEO skill: Shell script automatically submits website 404 dead link to search engine
Linux/vps local 7-day circular backup and 7-N remote backup script
Nginx log cutting and history log deletion script 7 days ago
Shell+Curl website health status check script, catch the lost website of China Blog Alliance
Those who are interested can choose and have a look.
This article continues to share a shell practical case: the whole site cache and scheduled pre cache, which further provides the website speed
Ps: At present, a more efficient Python pre caching tool has been launched. It is recommended to use: https://zhang.ge/5154.html

1、 What is pre caching
The webmaster who has used the WP Super cache plug-in must know that this plug-in has a pre caching function. After enabling this function, the plug-in will pre cache the entire site, and will update the cache regularly later.
Obviously, the advantage of the whole site pre cache is that the static cache has been generated before the user accesses, rather than being triggered by the user's access. Then almost all users access the static cache, and the average or overall speed will be improved qualitatively! Of course, the most important thing is to optimize the speed of spiders!
When you go to Baidu webmaster platform to check the crawl frequency, you can see the average time consuming data of spiders. My blog has made a static cache, and it is reasonable to say that each crawl will not exceed 500 ms, but there will still be some requests of more than ten or twenty seconds:
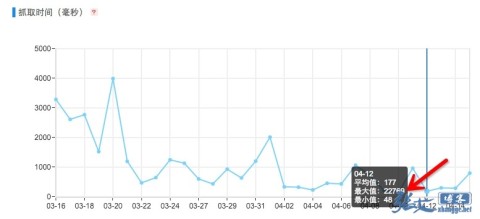
Excluding network latency or concurrent load when spiders crawl, another possible reason is that spiders just crawl a page whose cache has expired or does not exist. That is to say, when spiders crawl, the page cache has just expired and been deleted, so it is a dynamic page when it crawls, so the time is up!
Therefore, it is necessary to pre cache the whole site.
2、 Precache predecessor
Seeing the importance of pre caching, it's time to find a way to implement it. Before sharing methods, let's talk about the source of inspiration!
I remember that my blog shared various WordPress caching schemes before, including the php code version, the fast cig cache of nginx, etc. At that time, someone asked, is there any way to make the sitemap also statically cache (the pure code version of sitemap)?
At that time, sitemap.php was pseudostatically transformed into sitemap.xml, so it was dynamic data and placed in the root directory, so it was also possible to directly access sitemap.php. Because it was the data of the whole site, this file ran slowly!
Later, I used the Linux command+crontab to solve this problem: put sitemap.php in an unknown directory, then regularly use wget to request this file, and save the data as sitemap.xml to the root directory of the website! For example:
#Generate a sitemap.xml diypath as the actual location of sitemap.php in the root directory of the website every day 0 1 * * * wget -O /home/wwwroot/zhang.ge/sitemap.xml https://zhang.ge/diypath/sitemap.php >/dev/null 2>&1
Ps: To use this method, pay attention to the requirement ('./wp blog header. php') in sitemap. php; Change to require ('../wp blog header. php'); That is, pay attention to the relative position!
In this way, the problem that sitemap.xml is dynamic data is solved!
3、 Whole site pre cache
With the above case, it is really too simple to implement the whole site pre caching.
There are several implementation forms as follows:
① Blogs with cache function
For blogs with caching functions, such as installing a caching plug-in or using the nginx cache, you only need to pull out all article IDs or aliases from the database, then form a page address, and finally use wget or curl to request all of them once to achieve caching, such as:
#! bin/bash #My blog uses an alias, so it is select post_name. If the fixed link is ID, then it is select ID For post in $(mysql - uroot - p database password - e "use database name; select post_name from wp_posts where post_type='post 'and post_status='publish';" | sed - n'2, $p ') do #Use wget to request the page and throw the data to the "black hole file", that is, do not save it, but trigger the caching function of the blog wget -O /dev/null " https://zhang.ge/ ${post}.html" Sleep 0.5 # pause for 0.5s to avoid high load done
However, the fixed address of each blog may be different, so this splicing of ID or alias cannot be copied, and the classification, tag, etc. are not covered in place, which is a pity.
I was too lazy to study how to get all the pages from the database. Finally, I used a lazy method: get the page address from sitemap. xml!
Almost every website will have a sitemap.xml file. If your website does not have one, you should first Refer to the previous article Get one!
So the script can be changed to the following code:
#/bin/bash #Enter the root directory of the website, please fill in according to the actual situation cd /home/wwwroot/zhang.ge/ #Get all page addresses from sitemap.xml, request every 0.5 seconds, and trigger the cache. for url in $(awk -F"<loc>|</loc>" '{print $2}' sitemap.xml) do wget -O /dev/null $url sleep 0.5 done
Save this code as g_cache.sh after actual modification, and upload it to the Linux system, for example, place it in the/root directory. Execute it manually first to see if it succeeds:
bash /root/g_cache.sh
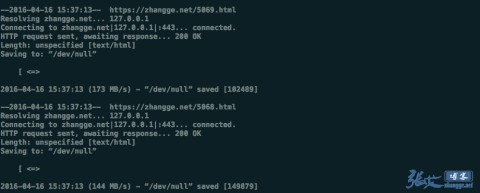
As shown in the figure, if there is no error report (the shocking speed in the figure needs no attention and is related to disk IO), finally add a task plan:
#Pre cache all stations at 3:00 every morning 0 3 * * * bash /root/g_cache.sh >/dev/null 2>&1
Duang, you can do it!
② , Blogs without cache
The blog without cache means that you don't like cache, and it may not be necessary to enable cache, so the following is just written to maintain the integrity of the article. It's good for you to have a selective look!
For the blog without cache, there are two ways to pre cache the whole site:
After installing the cache plug-in or enabling other caches, use method ① to implement
I won't open the cache, but I still want to use the whole site pre cache. What do you want to do!
The first way doesn't need to be wordy, just share how to implement the second way.
From step ①, we can see that we only request the page, but do not save the data, and throw all the black holes. What if I save the data as the corresponding html file and store it in the directory corresponding to the website? Then we can implement the same static cache as the cos real html plug-in?
Obviously, it's OK! The codes are as follows:
#!/ bin/bash #Please fill in the root directory of the website according to the actual situation base_dir=/data/wwwroot/zhang.ge #Do not cache the list, fill in the page address keywords that do not need to be cached, separated by the split number white_list="go.html|goto.html|liuyan.html" #Define Cache Folder Name cache_store=$base_dir/html_cache #Get all page addresses from sitemap.xml for url in $(awk -F"<loc>|</loc>" '{print $2}' $base_dir/sitemap.xml | sed '/^$/d' | egrep -v $white_list) do #Get the request path of the page address, such as cat/1.html cache_dir=${url#http*://*/} #Judge the homepage and delete the old cache file if echo $cache_dir | egrep "http.*://" >/dev/null ; then cache_dir=$cache_store #If the script is executed without parameters, the existing cache will be skipped, that is, if any parameters are taken, all caches will be rebuilt if [[ -z $1 ]]; then test -f $cache_store/index.html && continue fi else cache_dir=$cache_store/$cache_dir if [[ -z $1 ]]; then test -f $cache_store/index.html && continue fi fi #Create cache directory mkdir -p $cache_dir #Save the page content to the index.html file in the corresponding cache directory, similar to wp super cache curl -o $cache_dir/index.html $url sleep 0.5 done
According to the actual situation, modify the website root directory and cache whitelist in the code, save them as g_cache.sh, and upload them to the server. Then we need to add a Nginx pseudo static, which is just like the previous wp super cache:
location / { try_files $uri $uri/ /index.php?$ args; # WordPress default pseudo static rules. I can add the following rules below if (-f $request_filename) { break; } set $cache_file ''; set $cache_uri $request_uri; if ($cache_uri ~ ^(.+)$) { #Please note that the path of the following line of code corresponds to the path defined by CACHE_ROOT in the cache code: set $cache_file /html_cache/$1/index.html; } #Rewrite only when the cache file exists if (-f $document_root$cache_file) { #rewrite ^(.*)$ $cache_file break; rewrite ^ $cache_file last; } #All other requests are transferred to wordpress for processing if (!-e $request_filename) { rewrite . / index.php last; } }
After saving, reload overloads nginx to take effect.
Finally, create a new schedule task as follows and execute g_cache.sh regularly:
#Refresh the pre cache of the whole site at 3:00 a.m. every Monday (such as script comments, and rebuild the whole site cache with any parameters) 0 3 * * * bash /root/g_cache.sh all >/dev/null 2>&1 #Check the cache every hour. If there are articles without cache, generate (for new article publishing) 0 */1 * * * bash /root/g_cache.sh >/dev/null 2>&1
In this way, the wp super cache pre caching and cos real hmtl static caching functions are realized.
4、 The final wordiness
In fact, I think the biggest highlight of this article is the last script, which has implemented caching and pre caching. The Shenma cache plug-in and Shenma pseudo static can be thrown away! Moreover, as long as the website has a sitemap. xml file, you can achieve static caching, not limited to what the website building program is!
However, in addition to being cool, we still have some details to pay attention to. Please look carefully.
① , host resolution
Since it is captured locally in the whole server, in order to improve the speed and shorten the path, it is strongly recommended to resolve the website domain name to the server IP in hosts instead of external DNS resolution to reduce the resolution time or CDN consumption.
It is very simple. Edit the/etc/hosts file and insert a resolution in it, such as:
127.0.0.1 zhang.ge
Finally, save it.
② , generation interval
The planning tasks shared in the article are all once a day. If you think it is necessary to shorten the interval, you can modify the crontab statement by yourself. You can search the crontab configuration to understand the definition of time sharing days, months and weeks in the crontab, which will not be repeated here.
③ Cache deletion
This article only shares how to generate cache, not how to automatically delete cache. On the whole, crontab will regenerate the cache on a regular basis anyway, and in principle, it does not care about automatically refreshing the cache.
However, some obsessive-compulsive disorder often scratch their heads when they see that the comments do not refresh, and the articles are not refreshed after being modified. So here's a way out...
For websites with caching function, the use of this pre caching script will actually have no impact. If the cache was automatically refreshed before, it will still be refreshed now, and no operation is required.
For the website using the last script, it also implements the same function as the previously shared php generated html cache. If you want to delete the cache when updating articles or submitting comments, you can refer to the previous blog articles and modify the cache path:
WP Super Cache static cache plug-in code only version (compatible with multi domain websites)
Oh, share here, leave a word if you need to...
Latest supplement : Lazy use of sitemap.xml feels a little low, so I'd better provide a scheme without sitemap.xml! In order not to be confused with the above content, it is better to start a new page. If you need it, you can look at it. If you don't need it, please ignore it.




