Green Pioneer Personal Technology
The purpose of Green Pioneer on this website is to share some things about personal technology, so as to remove some doubts for everyone.
Technology sharing
Python is a popular language now. It has great advantages in data processing. If you learn this language, it can help you a lot in your work. Share how to write a crawler
Basic process of crawler
How to obtain network data:
Method 1: The browser submits the request --->downloads the web page code --->parses it into a page
Mode 2: Simulate the browser to send a request (get web page code) ->extract useful data ->store it in a database or file;
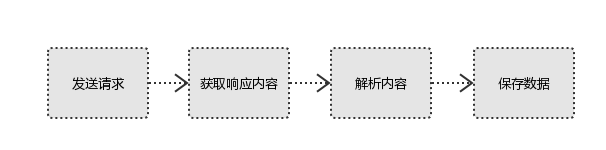
1. Initiate request
Send a request to the target site using the http library, that is, send a request
Request includes: request header, request body, etc
Request module defect: unable to execute JS and CSS code
2. Get response content
If the server can respond normally, it will get a response
Response includes: html, json, pictures, videos, etc
3. Parse content
Parsing html data: regular expressions (RE module), third-party parsing libraries such as Beautiful Soup, pyquery, etc
Parsing json data: json module
Parsing binary data: write files in wb mode
4. Save Data
Database (MySQL, Mongdb, Redis)
file
3、 Http protocol request and response
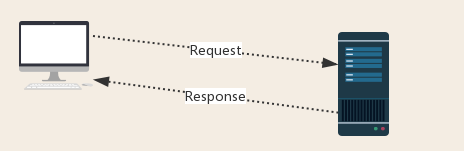
Request: users send their information to the server through the browser (socket client)
Response: The server receives the request, analyzes the request information sent by the user, and then returns the data (the returned data may include other links, such as pictures, js, css, etc.)
Ps: After receiving the response, the browser will parse its content to display it to the user, while the crawler program will extract useful data after simulating the browser to send a request and then receive the response.
4、 Request
1. Request method:
Common request mode: GET/POST
2. Requested URL
The URL global unified resource locator is used to define a unique resource on the Internet. For example, a picture, a file, and a video can be uniquely determined by the URL
Url encoding
https://www.baidu.com/s?wd= picture
The picture will be encoded (see the example code)
The web page loading process is:
To load a web page, you usually load the document document first,
When parsing the document document, if a link is encountered, a request to download the image will be made for the hyperlink
3. Request Header
User agent: If there is no user agent client configuration in the request header, the server may treat you as an illegal user host;
Cookies: Cookies are used to save login information
Note: Generally, crawlers add request headers
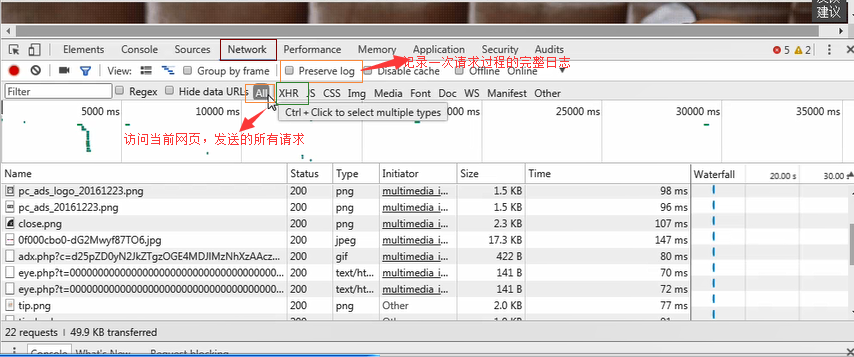
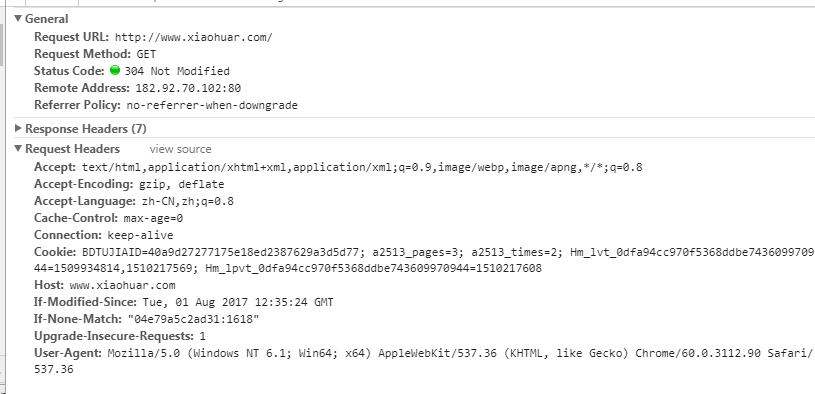
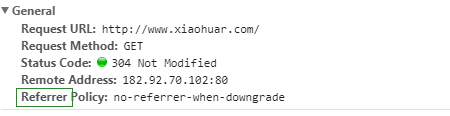
Parameters to be noted by the request header:
(1) Referrer: Where does the source come from? (Some large websites will use Referrer as a security chain strategy; All crawlers should also pay attention to simulation)
(2) User Agent: the browser visited (otherwise it will be regarded as a crawler)
(3) Cookie: the request header should pay attention to carrying
4. Requestor
Requestor
If it is the get mode, the request body has no content (the request body of the get request is placed in the parameter after the url, and can be seen directly)
If it is post mode, the request body is format data
ps:
1. Login window, file upload and other information will be attached to the request body
2. Log in, enter the wrong user name and password, and then submit, you can see the post. After correct login, the page will usually jump, and the post cannot be captured
5、 Response
1. Response status code
200: Success
301: delegate jump
404: File does not exist
403: No access
502: Server error
2、 respone header
Parameters to be noted in the response header:
(1)Set-Cookie:BDSVRTM=0; Path=/: There may be multiple cookies to tell the browser to save them
(2) Content Location: After the server response header contains Location and returns to the browser, the browser will revisit another page
3. Preview is the web page source code
JSO data
Such as webpage html and pictures
Binary data, etc
This is the working mode of the whole crawler. On the premise of understanding this mode, you can write a set of your own crawlers in python without too much discomfort, as long as you follow this set of logic.




