D类 米特里·马利奥托夫(mitry Malioutov)对自己建造的东西说不出多少。
作为IBM的一名研究科学家,马利奥托夫花费了部分时间构建机器学习系统,以解决IBM公司客户面临的难题。 其中一个项目是为一家大型保险公司设计的。 这是一项具有挑战性的任务,需要复杂的算法。 然而,到了向他的客户描述结果的时候,却出现了一个问题。 “我们无法向他们解释这个模型,因为他们没有接受过机器学习方面的培训。”
事实上,即使他们是机器学习专家,这可能也没有帮助。 这是因为该模型是一个人工神经网络,一个程序可以接收给定类型的数据——在这种情况下,保险公司的客户记录——并在其中发现模式。 这些网络已经实际使用了半个多世纪,但最近又出现了复兴,推动了从语音识别和语言翻译到Goplaying机器人和自动驾驶汽车等各个领域的突破。
隐藏含义: 在神经网络中,数据从一层传递到另一层,每一步都要进行简单的转换。 在输入层和输出层之间是隐藏层、节点组和连接,这些节点和连接通常没有人能理解的模式或与输入或输出的明显连接。 “深层”网络是指那些具有许多隐藏层的网络。 迈克尔·尼尔森/ NeuralNetworksandDeepLearning.com 尽管它们的性能提高令人兴奋,但现代神经网络有一个令人不安的事实:没有人知道它们是如何工作的。这意味着没有人能够预测它们何时会失败。
例如,机器学习研究人员Rich Caruana及其同事最近报道的一集。 他们描述了匹兹堡大学医学中心一个团队的经验,该团队正在使用机器学习来预测肺炎患者是否会出现严重并发症。 其目的是将并发症风险较低的患者送往门诊治疗,保留医院床位并引起医务人员的关注。 该团队尝试了几种不同的方法,包括各种神经网络,以及软件生成的决策树,这些决策树可以产生清晰的、人类可读的规则。
神经网络比其他任何方法都更为正确。 但是,当研究人员和医生看了一眼人类可读的规则后,他们发现了一些令人不安的事情:其中一条规则指示医生将已经患有哮喘的肺炎患者送回家,尽管事实上哮喘患者极易出现并发症。
模型按照要求做了:发现数据中的真实模式。 它给出的糟糕建议是由于数据中的一个怪癖造成的。 医院的政策是将患有肺炎的哮喘患者送往重症监护室,这项政策效果很好,哮喘患者几乎从未出现严重并发症。 如果没有塑造医院病历的额外护理,结果可能会大不相同。
医院轶事清楚地表明了可解释性的实际价值。 卡鲁阿纳和同事写道:“如果基于规则的系统了解到哮喘降低风险,那么神经网络当然也了解到了这一点。”但神经网络并不是人能理解的,它关于哮喘患者的奇怪结论可能很难诊断。 1 马利奥托夫警告说,如果没有一个可解释的模型,“你可能会意外杀人。”
这就是为什么这么多人不愿意在神经网络的奥秘上赌博。 当Malioutov向自己的公司客户展示他准确但难以理解的神经网络模型时,他还为他们提供了一个替代的、基于规则的模型,他可以用简单的术语交流该模型的工作原理。 第二个可解释的模型不如第一个模型准确,但客户决定无论如何使用它,因为这是一家数学复杂的保险公司,准确度的每一个百分点都很重要。 马利奥托夫说:“他们可能与(它)有更多的联系。”。 “他们非常重视直觉。”
甚至各国政府也开始对神秘的神经网络预言的影响越来越大表示担忧。 欧盟最近提议建立“解释权”,允许公民要求算法决策的透明度。 2 然而,这项立法可能难以实施,因为立法者没有明确规定“透明度”的确切含义。 目前尚不清楚这一遗漏是由于对问题的无知,还是由于对其复杂性的认识。
一些研究人员希望消除选择让我们拥有多层蛋糕的必要性,并理解它。
事实上,一些人认为这样的定义可能是不可能的。 目前,虽然我们可以了解神经网络正在做什么的一切——毕竟,它们只是计算机程序——但我们对它们是如何或为什么做的几乎一无所知。神经网络由许多,有时是数百万个称为神经元的单个单元组成。 每个神经元将许多数字输入转换为单个数字输出,然后将其传递给一个或多个其他神经元。 就像在大脑中一样,这些神经元被分成“层”,即从下层接收输入并将输出发送到上层的细胞组。
神经网络的训练方法是输入数据,然后调整层之间的连接,直到网络计算的输出尽可能接近已知的输出(通常由类别组成)。 过去几年令人难以置信的结果要归功于一系列新技术,这些技术使快速训练深层网络成为可能,在第一次输入和最终输出之间有许多层。 一个名为AlexNet的流行深度网络用于对照片进行分类,并根据照片中是否包含Shih Tzu或Pomeranian等细微差别进行标记。 它由6000多万个“权重”组成,每个权重告诉每个神经元对每个输入的关注程度。 康奈尔大学和几何智能学院的计算机科学家杰森·尤辛斯基(Jason Yosinski)说:“要说你对网络有一些了解,你必须对这6000万个数字有一些了解。”
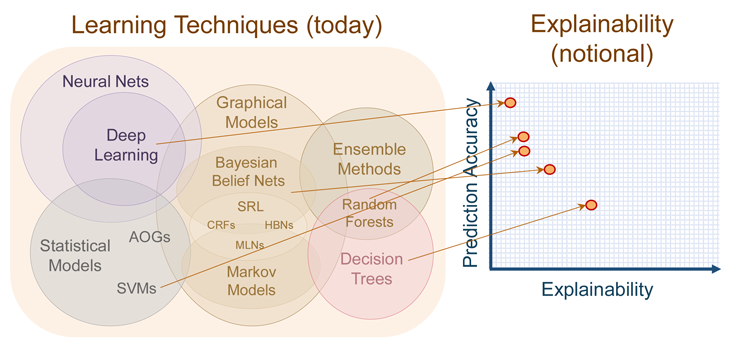
即使有可能强加这种可解释性,也未必总是可取的。 对可解释性的要求可以被视为另一组约束,使模型无法获得只关注给定输入和输出数据的“纯”解决方案,并可能降低准确性。 在今年早些时候的DARPA会议上,项目经理David Gunning在一张图表中总结了这种权衡,该图表显示了深层网络是最难理解的现代方法。 另一个极端是决策树,这是一种基于规则的系统,倾向于将解释放在效率之上。
什么与为什么: 现代学习算法在人类的可解释性或可解释性与其准确性之间进行了权衡。 深度学习是最准确的,也是最难解释的。 Darpa公司 结果是,现代机器学习提供了一种在预言中的选择:我们想知道吗 什么 将以高精度发生,或 为什么? 会发生什么事,以牺牲准确性为代价? “为什么”有助于我们制定战略、进行调整,并知道我们的模式何时会被打破。 “什么”帮助我们在不久的将来采取适当的行动。
这可能是一个很难做出的选择。 但一些研究人员希望消除选择的必要性,让我们拥有多层蛋糕,并理解它。 令人惊讶的是,一些最有希望的研究途径将神经网络视为实验对象,仿效了生物科学的风尚,这种风尚激励神经网络从比分析纯数学对象更原始的对象开始。 例如,Yosinski说,他正试图以“我们理解动物,甚至人类的方式”来理解深层网络。他和其他计算机科学家正从生物学研究中引进技术,仿效神经科学家研究大脑的方式来窥探网络内部:探测个体成分, 对其内部如何响应输入中的微小更改进行编目,甚至可以删除部分以查看其他部分如何进行补偿。
科学家们从头开始构建了一种新的智能,现在正在将其分解,并将其应用于这些虚拟生物,即显微镜和手术刀的数字等效物。
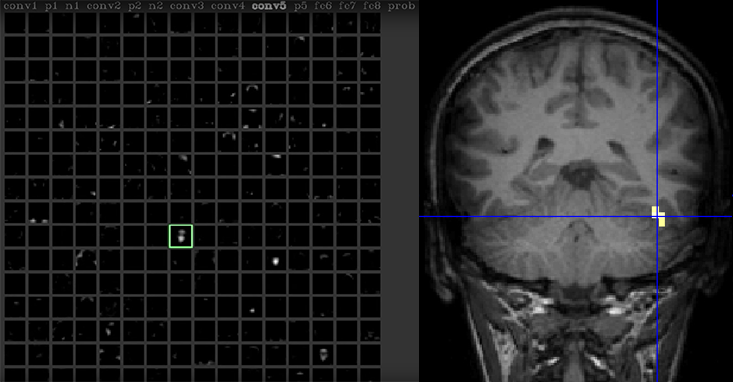
Y(Y) 奥辛斯基坐在电脑终端前对着摄像头讲话。 网络摄像头的数据被输入到一个深度神经网络中,而网络本身正在使用Yosinski和他的同事开发的一个名为“深度可视化工具包”的软件工具包进行实时分析。 通过点击几个屏幕,Yosinski放大了网络中的一个神经元。“这个神经元似乎对面孔做出反应,”他在互动视频记录中说道。 三 众所周知,人脑中也有这样的神经元,其中许多聚集在人脑中称为纺锤形面部的区域。 这个地区是在1992年开始的多项研究中发现的, 4, 5 已经成为人类神经科学中最可靠的观察之一。 但在这些研究需要正电子发射断层扫描等先进技术的地方,约辛斯基可以通过代码单独观察他的人工神经元。
大脑活动: 深层神经网络中的一个神经元(用绿色方框突出显示)对约辛斯基的脸做出反应,就像人脑的一个不同部分对脸做出可靠的反应一样(用黄色方框突出显示的)。 左图:杰森·尤辛斯基, 等。 通过深度可视化了解神经网络。 深度学习研讨会,机器学习国际会议(ICML)(2015)。 右图:乔治敦大学医学中心马克西米利安·里森胡伯 这种方法使他能够将某些人工神经元映射到人类可以理解的想法或物体,如人脸,这有助于将神经网络转化为直观的工具。 他的程序还可以突出图片的哪些方面对刺激面部神经元最为重要。 他说:“我们可以看到,如果我们的眼睛更黑,嘴唇更红润,它的反应会更强烈。”。
杜克大学计算机科学、电子和计算机工程教授辛西娅·鲁丁(Cynthia Rudin)认为,这些“事后”解释本质上是有问题的。 她的研究重点是构建基于规则的机器学习系统,应用于监狱判刑和医疗诊断等领域,在这些领域中,人类可读的解释可能非常重要。 但对于视觉等领域的问题,她说,“解释完全在旁观者的眼中。”我们可以通过识别面部神经元来简化网络响应,但我们如何确定它真正在寻找什么? 鲁丁的担忧呼应了一句著名的格言:视觉系统可能没有比视觉系统本身更简单的模型。 她说:“对于复杂模型的作用,你可以有很多解释。”。 “你只是选择一个你“想要”正确的吗?”
Yosinski的工具包可以通过反向工作,发现网络本身“想要”纠正什么,这是一种人为的理想,从而在一定程度上解决这些问题。 该程序从原始静态数据开始,然后逐像素调整它,使用与训练网络的过程相反的方法对图像进行修改。最终,它会找到一张能够激发给定神经元最大可能响应的图片。 当这种方法应用于AlexNet神经元时,它会生成一些漫画,这些漫画虽然很可怕,但无疑会唤起被标记的类别。
理想化猫: 由Deep Visualization工具箱生成的合成理想猫脸示例。 这些脸是通过逐像素调整通用起始图像生成的,直到AlexNet的脸神经元获得最大响应。 杰森·尤辛斯基, 等。 通过深度可视化了解神经网络。 深度学习研讨会,机器学习国际会议(ICML)(2015)。 这似乎支持了他的说法,即在某种非常普遍的意义上,面部神经元确实在寻找面部。 但有一个陷阱。 为了生成这些图片,Yosinski的程序依赖于一个统计约束(称为自然图像先验),该约束将其限制为生成与现实世界物体图片中的结构类型相匹配的图像。 当他删除这些规则时,工具箱仍然会确定一个图像,并将其标记为最可靠的图像,但该图像是纯静态的。 事实上,Yosinski已经证明,在许多情况下,AlexNet神经元喜欢的大多数图像在人类看来都是静态的。 他欣然承认,“很容易找出如何让网络说出极端的话。”
为了避免这些陷阱,弗吉尼亚理工大学电子与计算机工程助理教授德鲁夫·巴特拉(Dhruv Batra)采用了一种更高级的实验方法来解释深层网络。 他没有试图在网络的内部结构中找到模式——“比我聪明的人已经在做了这件事”,而是反驳道,他本质上使用机器人版的眼动追踪来研究网络的行为。 他的团队在一个由研究生Abhishek Das和Harsh Agrawal领导的项目中,就图像提出了一些深层次的问题,比如在给定的房间图片中,窗户上是否有窗帘。 6 与AlexNet或类似系统不同,Das的网络设计为一次只关注一小块图像。 它在图片周围移动它的虚拟眼睛,直到它确定有足够的信息来回答这个问题。 经过足够的训练,深度网络表现得非常好,能够像最优秀的人一样准确地回答问题。
训练有素的机器非常适合其环境,并能适应任何其他环境。
达斯、巴特拉和他们的同事们随后试图通过调查网络在图片中选择的位置来了解网络是如何做出决定的。 他们的发现让他们感到惊讶:当回答关于窗帘的问题时,电视网甚至懒得找窗户。 相反,它首先会查看图像的底部,如果找到床就停止查看。 看起来,在用于训练神经网络的数据集中,卧室里可能会有带窗帘的窗户。
虽然这种方法确实揭示了深层网络的一些内部工作,但它也加强了可解释性带来的挑战。 巴特拉说:“机器捕捉到的并不是关于世界的事实。”。 “它们是关于数据集的事实。”由于机器对输入的数据进行了严格调整,因此很难提取关于它们如何工作的一般规则。更重要的是,他警告说,如果你不知道它是如何工作的,你就不知道它会如何失败。 根据巴特拉的经验,当他们这样做时,他们就会失败,“他们失败得非常可耻。”
研究人脑的科学家们将熟悉Yosinski和Batra等研究人员面临的一些障碍。 例如,关于神经影像学解释的问题,即使没有得到普遍关注,也在今天很常见。 认知神经科学家玛莎·法拉(Martha Farah)在2014年对该领域的一份评论中写道:“令人担忧的是,(大脑功能)图像更多的是研究人员的发明,而不是研究人员的观察结果。” 7 这些问题在不同的智能系统实现中的出现表明,它们可能是障碍,不是对这种或那种大脑的研究,而是对智能本身的研究。
我 追求可解释性是一件愚蠢的差事吗? 在2015年的一篇题为“模型可解释性的神话”的博客文章中,圣地亚哥加州大学的扎卡里·利普顿(Zachary Lipton)首先对解释神经网络背后的动机以及为大型数据集构建可解释的机器学习模型的价值提出了批判性观点。 在今年的机器学习国际会议(ICML)上,他向一个关于人类可解释性的研讨会(由马利奥托夫和他的两位同事组织)提交了一篇关于这个主题的挑衅性论文。 8
利普顿指出,许多学者对可解释性的概念本身存在分歧,这对他来说,要么是可解释性理解不足,要么是有许多同样有效的含义。 在这两种情况下,追求可解释性可能无法满足我们对神经网络输出进行简单、简明的英语描述的愿望。 在他的博客文章中,利普顿认为,当涉及到巨大的数据集时,研究人员可以选择抵制解释的冲动,而可以“相信经验的成功”。他认为,该领域的一个目的是, 就是“建立一个模型,它可以从比任何人都能有意识地解释的更多的特征中学习”,而可解释性可能会阻止这些模型发挥其全部潜力。
但这种能力既有特点,也有缺点:如果我们不了解网络输出是如何生成的,那么我们就不知道输入的哪些方面是必要的,甚至根本不知道什么可以被视为输入。 一个恰当的例子:1996年,苏塞克斯大学的阿德里安·汤普森(Adrian Thompson)使用软件,通过应用类似于当今深层网络训练的技术来设计电路。 该电路将执行一项简单的任务:区分两种音频音调。 经过数千次迭代、洗牌和重新排列电路组件,该软件找到了一种几乎完美地完成任务的配置。
然而,汤普森惊讶地发现,电路使用的元件比任何人类工程师使用的元件都少,其中包括一些没有与其他元件物理连接的元件,但电路正常工作仍有必要。
他开始剖析电路。 经过几次实验,他了解到它的成功利用了相邻组件之间微妙的电磁干扰。 断开的元件通过在局部电场中引起微小波动而影响电路。 人类工程师通常会防范这些交互,因为它们是不可预测的。 毫无疑问,当汤普森将相同的电路布局复制到另一批组件上,甚至改变了环境温度时,它完全失败了。
这条赛道展现了训练有素的机器的一个显著特征:它们尽可能地紧凑和简化,非常适合它们的环境,并且适合任何其他环境。 他们发现了工程师看不见的模式; 但不知道哪些模式在其他地方不存在。 机器学习研究人员竭尽全力避免这种被称为“过度拟合”的现象,但随着这些算法在越来越多的动态情况下使用,它们的脆弱性将不可避免地暴露出来。
对于普林斯顿大学计算机科学教授桑吉夫·阿罗拉(Sanjeev Arora)来说,这一事实是寻求可解释模型的主要动机,该模型允许人类干预和调整网络。 Arora指出了两个问题,在缺乏可解释性的情况下,这两个问题可能会对机器的能力造成严重限制。 一个是“可组合性”——当手头的任务涉及许多不同的决策时(例如围棋或自动驾驶汽车),网络无法有效地了解哪些是导致失败的原因。 他说:“通常,当我们设计东西时,我们了解不同的组件,然后将它们组合在一起。”。 这允许人类调整不适合给定环境的组件。
另一个未解决可解释性的问题是Arora所称的“领域适应性”,即灵活地将在一个环境中学习到的知识应用于另一个环境的能力。 这是一项人类学习者做得很好的任务,但机器可能会以令人惊讶的方式失败。 Arora描述了程序是如何灾难性地无法适应人类轻松处理的那种微妙的上下文变化的。 例如,一个通过阅读正式文档(如维基百科)来解析人类语言的网络,在更多的方言设置(如推特)中可能会完全失败。
根据这种观点,可解释性似乎至关重要。 但是我们明白我们所说的这个词的意思吗? 先驱计算机科学家马文·明斯基创造了“手提箱词”这个短语,用来描述我们在谈论自己的智力时使用的许多术语,例如“意识”或“情感”。 9 他提出,这些词反映了许多不同的底层过程的运作,这些过程被锁在“手提箱”里。只要我们继续研究这些词,作为更基本概念的替代品,我们的洞察力就会受到语言的限制。 在对智力的研究中,可解释性本身是否就是一个手提箱单词?
虽然我采访过的许多研究人员都乐观地认为,理论家们总有一天会打开手提箱,发现一套统一的原理或定律,来指导机器(也许还有人类)的学习,类似于牛顿的 普林西米亚 其他人警告称,没有什么理由预期会出现这种情况。 纽约城市大学(City University of New York)哲学教授马西莫·皮格利乌奇(Massimo Pigluicci)警告说,自然科学中的“理解”,以及由此引申出的人工智能观,是路德维希·维特根斯坦(Ludwig Wittgenstein)在明斯基(Minsky)之前所称的“集群概念”,它可以接受许多部分不同的定义。 他说,如果这一领域的“理解”真的出现了,那么它可能不是物理学中的那种,而是进化生物学中的那种。 而不是 普林西米亚 他说,我们可以预期 物种起源 .
当然,这并不意味着深层网络是某种新型自主生活的预兆。 但事实证明,它们可能和生活一样难以理解。 该领域的增量、实验性方法和事后解释可能并不是在黑暗中绝望的感觉,希望理论能发光。 相反,它们可能是我们能期待的唯一一种光。 可解释性可能是零星出现的,作为一组“物种”的原型示例,按照推理和偶然的上下文特定解释定义的分类法排列。
在ICML研讨会结束时,一些主持人出现在一个小组中,试图定义“可解释性”。 经过一些讨论,该小组似乎达成了共识,即“简单性”对于模型的解释是必要的。 但是,当被要求定义简单性时,这一群体又出现了分歧。 “最简单”的模型是依赖最少功能的模型吗? 最明显的区别是什么? 它是最小的程序吗? 研讨会结束时,没有达成一致的答案,一个早期概念的定义被另一个概念所取代。
正如马利奥托夫所说,“简单并不是那么简单。”
Aaron M.Bornstein是普林斯顿神经科学研究所的研究员。 他的研究调查了我们如何利用记忆来理解现在和规划未来。
工具书类
1.卡鲁阿纳,R。, 等 医疗保健智能模型:预测肺炎风险和医院30天再入院。 第21届ACM SIGKDD知识发现和数据挖掘国际会议论文集 1721-1730 (2015).
2.Metz,C.人工智能正在建立互联网,以应对与欧洲的巨大冲突。 Wired.com(2016)。
3.Yosinski,J.、Clune,J.,Nguyen,A.、Fuchs,T.和Lipson,H.通过深度可视化了解神经网络。 arXiv:1506.06579(2015)。
4.Sergent,J.、Ohta,S.和MacDonald,B.面部和物体处理的功能神经解剖学。 正电子发射断层成像研究。 大脑 115 , 15–36 (1992).
5.坎维瑟。 N.,McDermott,J.和Chun,M.M.纺锤形面部区域:人类纹状体外皮层中专门用于面部感知的模块。 神经科学杂志 17 , 4302–4311 (1997).
6.Das,A.、Agrawal,H.、Zitnick,C.L.、Parikh,D.和Batra,D.视觉问答中的人类注意力:人类和深层网络是否关注相同的区域? 自然语言处理实证方法会议(2016年)。
7.Farah,M.J.大脑图像、婴儿和洗澡水:功能神经成像的批判评论。 解读神经影像:技术简介及其局限性 45 ,S19-S30(2014)。
8. 模型可解释性的神话。 arXiv:1606.03490(2016)。
9.布罗克曼·J·意识是一个大箱子:与马文·明斯基的谈话。 Edge.org(1998年)。
获取Nautilus时事通讯 尖端科学,由最聪明的在世思想家揭开。