我一直在玩城市:天际线最近,超级流行的SimCity淘汰赛。处理流量是游戏的核心主题(应该如此)。交通往往在十字路口聚集,众所周知,单行道的交通流量较高。那么,合乎逻辑的结论是,尝试建立一个只有一条超长单行道的城市……不幸的是,我们不得不在这个完美的愿景上妥协,因为人们想下班回家等等。
 希尔伯特维尔:充满太空的城市。
希尔伯特维尔:充满太空的城市。
空间填充曲线快速入门
与此同时空间填充曲线是19世纪的一项数学发明,也是分形的早期例子之一。基本思想是定义一条通过正方形每个点的路径,同时连续的这是通过定义一系列日益扭曲的路径(H1、H2、H3…)来实现的,以使H∞定义良好且连续。当然,我们并不想要一条无限曲折的道路,但空间填充曲线的模型仍然对我们有用。
在空间填充曲线中有几个重要的想法。第一个概念是,通过在曲线H1、H2、H3…的序列中获得某些性质,我们将能够将这些性质推广到极限曲线H∞。
 摩尔曲线是(连续!)填充空间曲线的一个示例。当您沿着路径移动时,颜色变化会跟踪时间;请注意,在非常曲折的第六条路径中,时间上的一个小变化仍然会使你保持在同一个(块状)邻里。
摩尔曲线是(连续!)填充空间曲线的一个示例。当您沿着路径移动时,颜色变化会跟踪时间;请注意,在非常曲折的第六条路径中,时间上的一个小变化仍然会使你保持在同一个(块状)邻里。
第二个主要想法是如何获得连续性。将曲线视为一个函数,在时间0处开始,在时间1处结束,我们需要一个H∞,其中时间的微小变化会产生位置的微小变化这里需要注意的是,当我们试图填充正方形时,路径本身会变得越来越长,这可能会使连续性很难满足……当路径长度加倍时,您的移动速度是原来的两倍。
事实上,由于连续性,您还可以“向后走”:给定正方形中的一个点,您可以以任意精度近似地估计通过极限曲线H∞上的点的时间。这直接证明了曲线实际上覆盖了整个正方形。
下面是一个空间填充曲线的示例不连续。将Bk定义为根据以下说明获得的曲线:
- 从左下角开始。
- 走到正方形的顶部,然后向右移动1/k。
- 移到方框底部,向右移动1/k。
- 重复步骤2和3,直到到达正方形的右侧。
这里的问题是,一个非常小的时间变化可能会把我们从方块的顶部一直带到方块的底部。我们需要更加紧张,以确保我们不会在广场上乱跳。上图所示的摩尔曲线很好地表达了他的意思:时间(颜色)上的微小变化不会将你从正方形的一边移到另一边。
实际模拟城市
如果我们尝试使用空间填充曲线在“城市:天际线”中建造城市,会发生什么?
我建造“Hilbertville”的第一次尝试是建造大型街区,使用(二阶)Hilbert曲线的设计,修建一条单行、蜿蜒的单行道。不过,除了道路之外,我还设置了一些人行道,让步行的人可以直接进出这些社区。我喜欢认为这有力地鼓励了步行交通,尽管很难从游戏中的统计数据中判断出人们实际的总体通勤选择是什么。
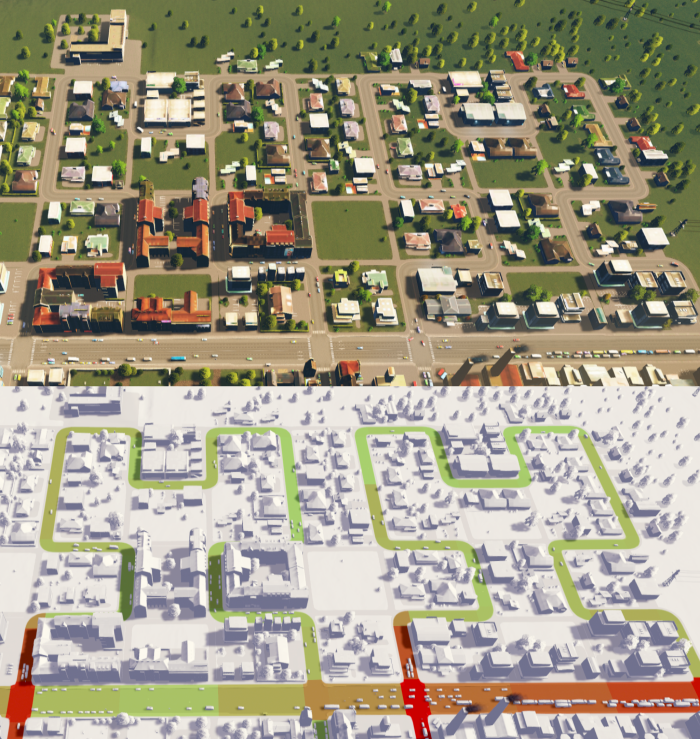 希尔伯特维尔,两个街区。下面的视图突出显示了道路所在的位置,并对每个路段的拥堵程度进行了彩色编码。由于汽车在十字路口等待,每个街区的出口都有点拥堵。
希尔伯特维尔,两个街区。下面的视图突出显示了道路所在的位置,并对每个路段的拥堵程度进行了彩色编码。由于汽车在十字路口等待,每个街区的出口都有点拥堵。
天际线只允许建筑物直接面向道路;角落往往会导致空旷的空间。你可以在上图所示的两个街区中间看到一个巨大的空广场。在这两个方块的内部还有两个较小的长方形和两个小的空方块。使顶部的“循环”稍微长一点,消除了大部分内部空白。从游戏的角度来看,这个内部空间很糟糕;理想情况下,我们仍然可以在空地上建一个公园,让人们有更多的空间,但即使是公园也需要道路。
与主要连接道路的交叉口最终成为所有交通拥堵的“汇”。因此,我们应该尝试减少此类交点的数量……摩尔曲线是希尔伯特曲线上的一个微小变化,它将路径的“起点”和“终点”放在一起。如果我们将起点和终点合并成一条宽阔的双向道路,我们会得到:
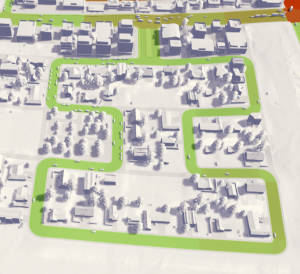 基于摩尔曲线的填空道路。
基于摩尔曲线的填空道路。
我们仍然可以在邻里之间得到浪费的广场,但在一定程度上减少了室内空间的空置量。潜在地,我们可以开发一个稍微不同的模式,并在块之间交替,以消除块之间丢失的空间。此外,由于街区的入口和出口重合,我们可以将与主干道的十字路口数量减半,这对于交通拥堵来说是一个巨大的胜利。
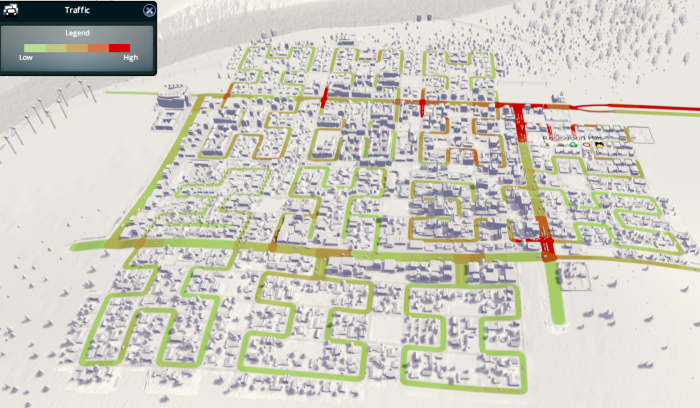
这是整个城市的景色;它还不是超级大,人口约为25000人。尽管与我之前建造的一些城市相比,主要环路上的拥堵情况要轻得多,但我们仍然面临着相当严重的拥堵。特别是,工业区(有大量的卡车交通)在这些长而曲折的单行道上表现得更好。
希尔伯特维尔全景,人口25000。这里有十四个街区;请注意底部的两个摩尔曲线块,以及左下角稍微修改过的希尔伯特曲线块,这以稍微较长的道路为代价减少了空余空间。
空荡荡的空间实际上是由道路上所有的转弯造成的;更少的角落意味着更少的荒地。解决这一问题最简单的方法就是使用“来回”的单行道,而不需要所有花哨的弯路。
这种道路设计的另一个主要问题是获得服务。尤其是消防车要到达街区尽头还有很长的路要走;“火灾危险”指标似乎认为这是个坏主意。不过,我不确定这是否真的是个问题,因为一个街区内的交通量几乎为零,尽管路途遥远,但应急响应速度却相当快。
总的来说,我认为这是一个喜忧参半的成功。没有强有力的理由支持扭曲的空间填充曲线,而不是简单的来回单行道,无论哪种情况,消防车和垃圾车的通行似乎都是一个问题。填充曲线的扭曲度主要用于获得正确的局部量,以确保极限曲线的连续性;然而,这在城市设计中并没有明确的目的,许多转弯最终导致难以进入的角落空间。然而,好的一面是,城市的设计减少了交通量,大力鼓励步行交通。








