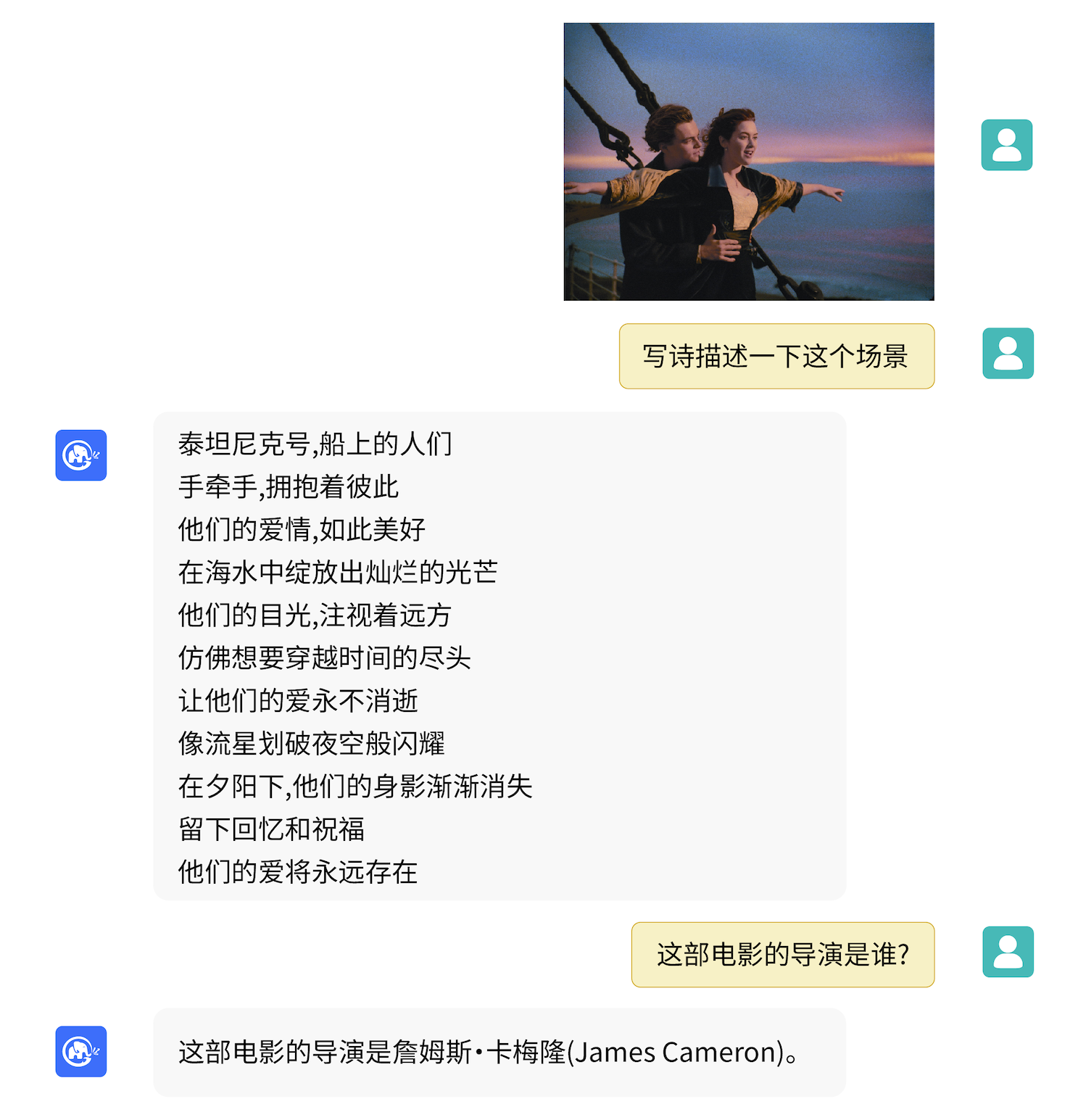
According to the exclusive news of the Science and Technology Innovation Board Daily, Ant Group's technology research and development team is developing a language and multi-modal large model - named "Zhenyi" internally. The project has been highly valued by Ant Group's management and has been launched for several months. Multimodal large model refers to a model that combines multimodal information such as text, image, video, audio and so on for training. Previously, Ilya Sutskever, the co-founder of OpenAI, said, "The long-term goal of AI is to build a multimodal neural network, that is, AI can learn the concepts between different modes, so as to better understand the world. ”It's worth one ..