Moore Thread and Wuwen Core Dome jointly announced today that the two sides have officially completed the training of "MT-infini-3B", a large-scale model based on the domestic full function GPU kilocalorie cluster, The model is based on the kilocalorie cluster composed of domestic full function GPU MTT S4000 of Moore Thread , as well as the AIStudio PaaS platform of the Core Free Dome.
It is reported that this MT-infini-3B model training took 13.2 days in total, and the whole process was stable and uninterrupted. The stability of cluster training reached 100%. Compared with single machine, the expansion efficiency of kilocalorie training exceeded 90%, It is said to have "fully verified the reliability of Kua'e thousand calorie intelligent computing cluster in the large model training scene, and also pioneered the new paradigm of in-depth cooperation between domestic big language models and domestic GPU thousand calorie intelligent computing cluster" in the industry.
This training fully verified the reliability of Kua'e thousand calorie intelligent computing cluster in the large model training scene, and also took the lead in opening a new paradigm of in-depth cooperation between domestic big language models and domestic GPU thousand calorie intelligent computing cluster in the industry.
At present, the MT-infini-3B performance that has been trained ranks first among models of the same scale. Compared with other models that have been trained on international mainstream hardware, the MT-infini-3B performance leads in C-Eval, MMLU, CMMLU and other three test sets.
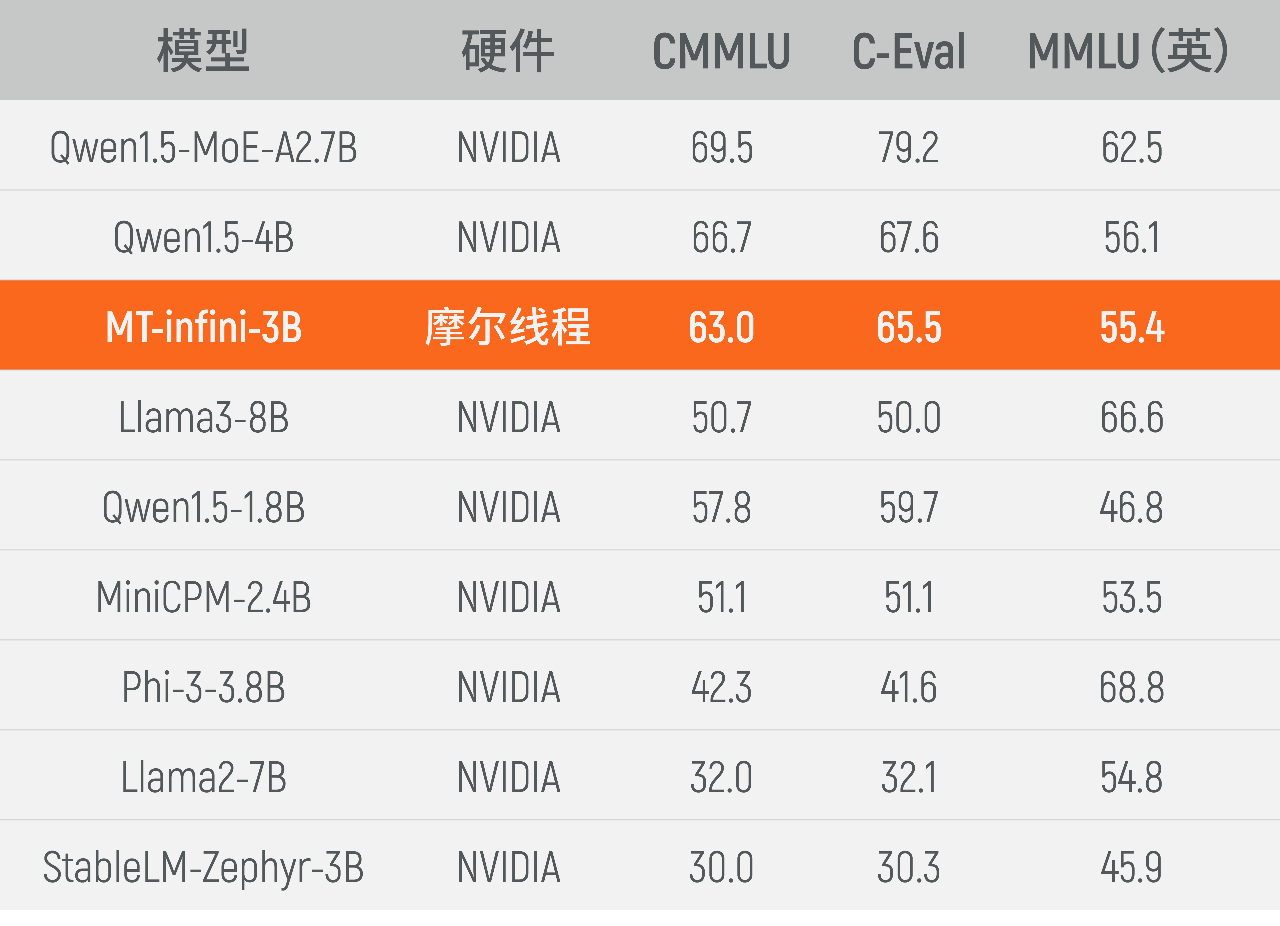
MT-infini-3B performance
Xia Lixue, co-founder and CEO of Wuwen Core Dome, said: "The ultimate goal of the coordinated development of domestic big models and domestic chip software and hardware is to build a mature ecosystem. Wuwen Core Dome is building an 'M × N' intermediate layer product between 'M models' and' N chips', to achieve efficient and unified deployment of multiple big model algorithms on multiple chips. Moore Thread is the first domestic GPU company to access the core free dome and conduct kilocalorie level large model training, and the 'MT-infini-3B' training is the first end-to-end large model training case based on domestic GPU chips from 0 to 1 in the industry. "
Zhang Jianzhong, the founder and CEO of Moore Threads, said: "The zero start large model training of Wuwen Core Dome on the Kua'e Qianka intelligent computing cluster is not only a powerful certification of Moore Threads' technical strength, but also a domestic closed loop of large model training. Based on a full function GPU, the Moore Thread Kuaeqianka intelligent computing cluster provides a full stack solution that integrates software and hardware. It has comprehensive advantages such as high compatibility, high stability, and high scalability. We are committed to becoming a solid and reliable advanced infrastructure for large model training in the AGI era. "
Previously, Moore Thread and Wuwen Core Dome had reached a deep strategic cooperation. The development and service platform "Infini AI without dome" and the Moore thread large model intelligent calculation kilocalorie cluster Kwa E have completed the system level integration adaptation. The platform can flexibly call Kwa E's cluster ability to complete the training, fine-tuning and reasoning tasks of the large model. In the future, the two sides will also carry out more adaptation and testing, promote the rapid development and application popularization of domestic large model technology, and contribute to the vigorous development of China's artificial intelligence industry.
▼ On the core dome without question
Infinity AI relies on the industry leading and proven AI computing optimization capability and computing power solutions to pursue the ultimate energy efficiency of large model landing. Create "M × N" intermediate layer products between "M models" and "N chips", and realize efficient and unified deployment of multiple large model algorithms on multiple chips. Link the upstream and downstream, jointly build the infrastructure of the AGI era model, and accelerate the implementation of AGI in thousands of industries.
▼ About Moore Threads
Moore Threads is an integrated circuit high-tech company focusing on the design of full function GPU chips. It can provide a strong computing acceleration capability for a wide range of scientific and technological ecological partners, and is committed to building a metacomputing platform that provides multiple computing power for the next generation of Internet.















































