The author of this article starts from specific work practice and combines case They shared the very practical knowledge of category prediction in a wide range of sorting for your reference and learning.
In the previous chapter, we briefly introduced the specific process of the next search. From the moment you enter keywords and click the search button to the blink of an eye when the search results page is presented to users, what steps and processes have gone through before it is presented to us.
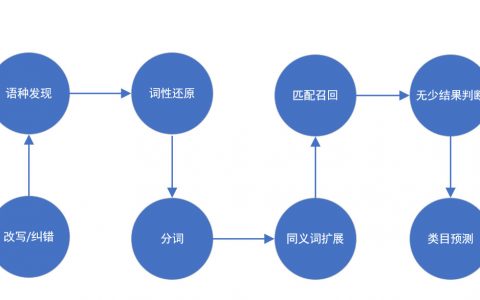
There are some steps that I think can be explained in depth, but after sleeping, I think it may be related to the product operate You are a bit too obscure and boring. Even if you know the secret of it, it will not help your future operations, such as word segmentation algorithm.
Therefore, in order to save your time, I'd like to focus on the key points. This chapter focuses on the category prediction in the large-scale sorting. As well as some sand carving operations in my current unit at the beginning, I will also give you some suggestions on product design and communication for young people who are determined to enter the product circle. I don't want to say anything about methodology. It's too empty. Let's go straight to the operation.
Category prediction
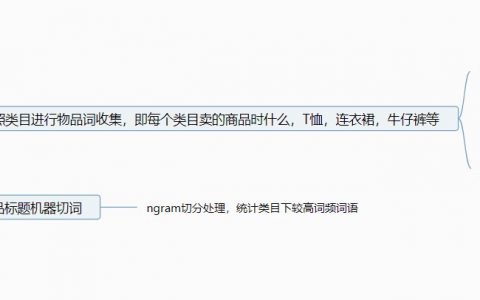
What is category prediction? Take a simple example. If you enter the keyword "mobile phone" and the category of mobile phone comes out first instead of the category of mobile phone shell, this is the category prediction.
According to the principle of full word matching, as long as the product title or attribute or category name and other products with the "mobile phone" keyword are recalled, the role of category prediction is to sort these recalled products according to category priority.
It's easy to say, but hard to do! If only from Marketing To sort by data, the price of mobile phone case is low, and the number of goods is large. Compared with the high price of mobile phone category, the number may be far less than accessories.
So if I am a sorting machine without feelings, which should I prioritize?
The mobile phone case must be at the front, because the comprehensive data of the mobile phone case category is better than that of the mobile phone category. Why not arrange the mobile phone case? Very reasonable. However, from the perspective of consumer intention, users want mobile phones, not mobile phone cases. No matter how beautiful your data is, it must be inaccurate for consumers.
Therefore, for consumers, the effect of category prediction is an entry-level indicator to measure the accuracy of search. At present, domestic e-commerce giants have passed the early stage of manual collection, machine algorithm assistance, or through third-party search solution providers to provide relatively complete prediction algorithms and solutions.
So this article is meaningful for those enterprises that are newly founded or are not satisfied with the search results page and have their own optimization. (In the last issue, I will introduce how to build a relatively complete and economical On site search Product plan)
Category prediction is explained in two parts, Manual and machine algorithms
artificial
It is very simple to directly set up a keyword and category association table in the product background. When making this product, product manager The following problems should be noted:
(1) Who is the user of this product? It must be a search operator. First of all, it is convenient for users to import and export in batches.
(2) What is the main content of the product operation? Keywords, so we should distinguish languages for keywords. If the app involves multiple language regions and countries, it should be operated separately, and the interoperability between different languages takes effect; And for phonemic characters, it needs to be effective for a variety of tenses and synonyms.
The same keywords also take effect after changing positions, such as "Mobile Apple" and "Apple Mobile". This can reduce the amount of words maintained manually. (My current unit still uses the logic of absolute matching, and the pit is still not filled. This also gives me an inspiration that when doing product planning, we must deal with details in advance. Although we don't need to be 100% comprehensive, the main contradictions should be considered at least.)
(3) Exact full word matching or central word matching has always been a debate since I entered the office. Since the establishment of an internal search system, artificial full word matching has always been the favorite of the leadership. Because we can achieve faster results, we only need a few people to maintain the top word every day to achieve the effect of data improvement.
① Accurate whole word matching prediction
What is accurate full word matching prediction? If I search for "iPhone 128g" in the manually maintained thesaurus, only the word "iPhone" will fail to hit the artificial category prediction. Therefore, the number of manually maintained full word matching words is extremely large.
Moreover, the keywords entered by users have no rules to follow, and no order can be predicted. Therefore, the word function can only be used as a function to quickly repair keywords and present bugs.
② Head word matching prediction
What is called headword matching prediction is actually based on a reasonable assumption, that is, e-commerce websites are for shopping, and users' app browsing and searching are based on the needs of certain items or brands, so we have reason to believe that only a limited collection of item words and brand words can cover most search category prediction needs, Then these item words or brand words are our central words.
For example, if a user searches for "mobile phone 128g", then "mobile phone" is the central word. The manual central word thesaurus only needs to maintain the front end/back end category corresponding to "mobile phone" to achieve the effect of category prediction, and good results will be achieved from point to area.
Some people may say that if the user enters the "mobile phone shell", it is also predicted that the mobile phone category is wrong. Therefore, the n-gram strategy needs to be introduced here. Generally speaking, the phrase priority is higher than the word. That is to say, the lexicon is preferred to match the long word. If the long word is not available, then match the short word.
The logic of category prediction is that as long as a keyword has been predicted by algorithm or manually, it will first query and recall the predicted category, and then query and recall the non predicted category.
That is to say, if no products can be found in the predicted category, the prediction is useless. Or wrong category. (There are exceptions, of course. When a user searches for a particularly tricky word "the gift from Apple Tuhaojin 128g to his mother" algorithm or the category predicted manually is the category of mobile phones, but the and query has no results in this category, in this case, the word reduction algorithm can be used for intelligent word reduction to extract the keyword backbone for users to choose.).
Machine algorithm
The so-called machine algorithm is based on the user's behavior data and the inherent information of the commodity itself.
Then the logic of machine algorithm is based on word frequency and user's click behavior is based on Bayesian theory (Baidu means: if you see a person always doing something good, that person will probably be a good person. That is to say, when you cannot accurately know the essence of a thing, you can judge the probability of its essential attributes by the number of events related to the specific essence of the thing. In mathematical language, it means that the more events that support an attribute occur, the more likely the attribute will be established).
Bayesian algorithm needs a certain data training set, and these data training sets need commodity data and keywords corresponding (keywords and the probability of users clicking on category commodities).
Through continuous optimization and evaluation of training set training results, a better Bayesian model is finally obtained. In this way, keywords are combined with commodity data to become our machine category prediction.
However, there are still many algorithms for category prediction. This is just for you to mention that if I highlight the formula, it will appear as "x", because I can't understand it.
Well, let's call it a day.
Preview the content of the next issue, the formation and principle of the search algorithm.
#Columnist#
Author: Wang Huan, WeChat: wanghuan314400, a small piece of operation ash.
Operation article of last year and today
- 2023: "It's bread, it's air, it's a miracle" communication plan (0)
- 2023: Exploring the framework construction of knowledge system (0)
- 2023: 100 Thinking Models 046. Reverse Thinking Model (0)
- 2023: People's Daily recommends: 9 good ways to get out of the slump, and it is recommended to collect them forever! (0)
- 2023: The Tomato Working Method of the World's Top Ten Learning Methods (0)
This article is reproduced in Wang Huan , this article does not represent the love operation position, please contact the original source for reprinting. If there are any copyright problems with the content and pictures, please contact Love Operation.

![[Dry goods] Do you know how to use WeChat to maintain customers when you are doing e-commerce?](https://www.iyunying.org/wp-content/uploads/2019/09/2019091801215525-480x300.png)



![[At a glance] Easy to understand e-commerce operation](https://www.iyunying.org/wp-content/uploads/2023/05/yunying7-1683786404-480x300.jpeg)


![[Customer service criteria] Talking about the importance of service differentiation to transformation](https://www.iyunying.org/wp-content/uploads/2022/09/2022090803264748-480x300.png)