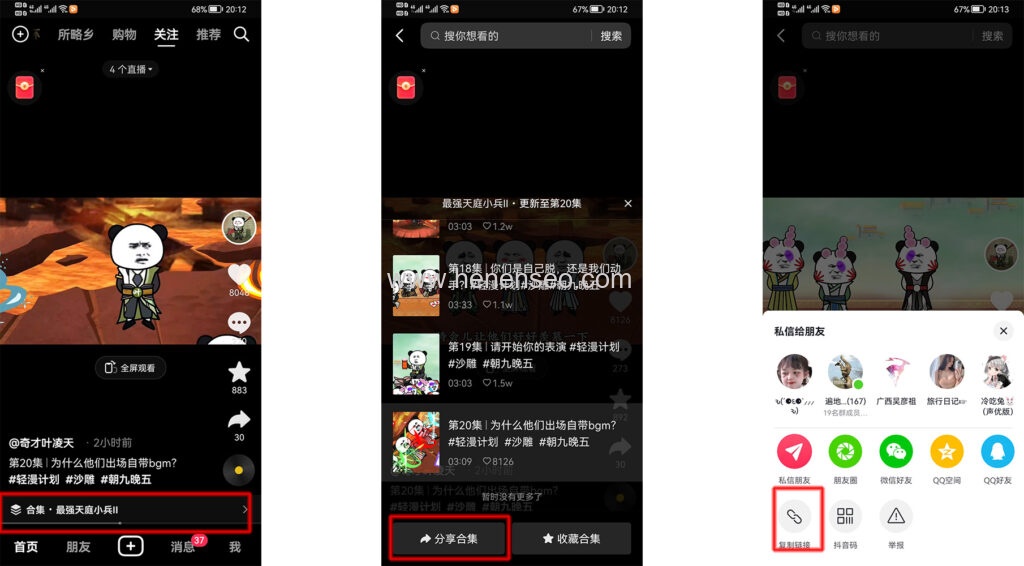
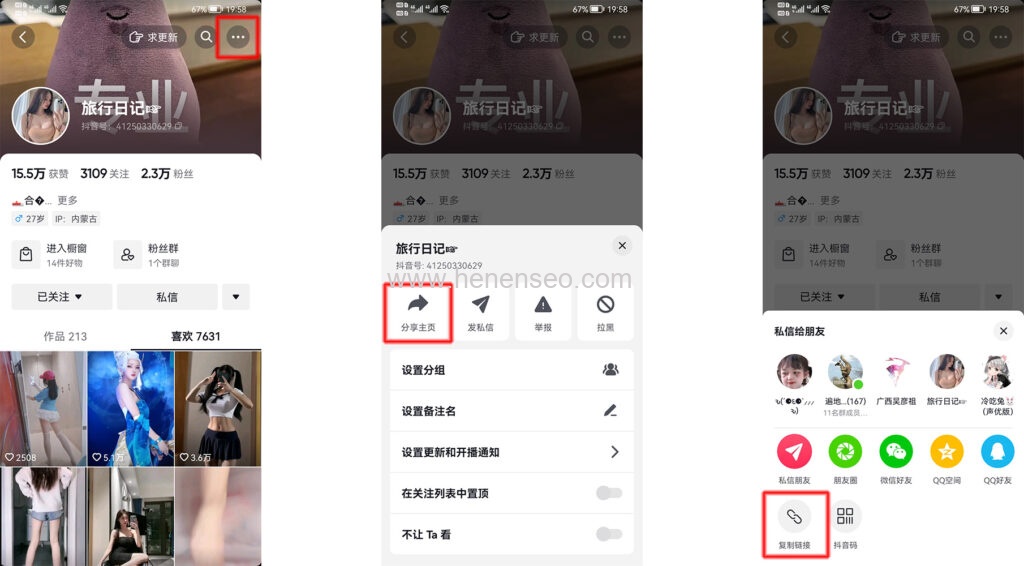
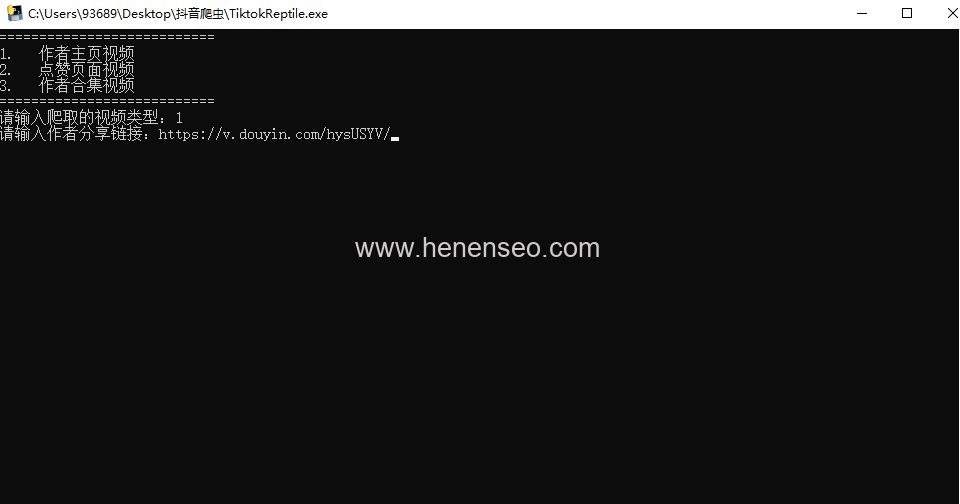
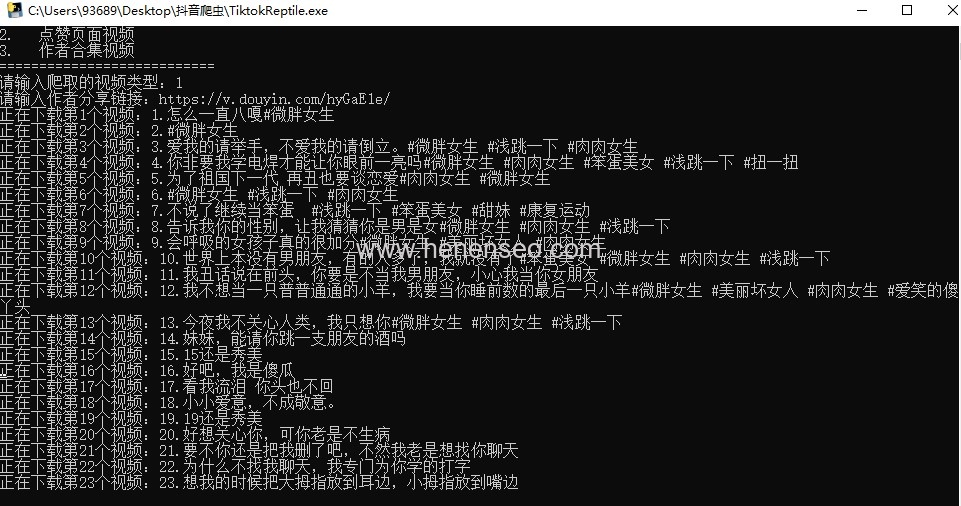
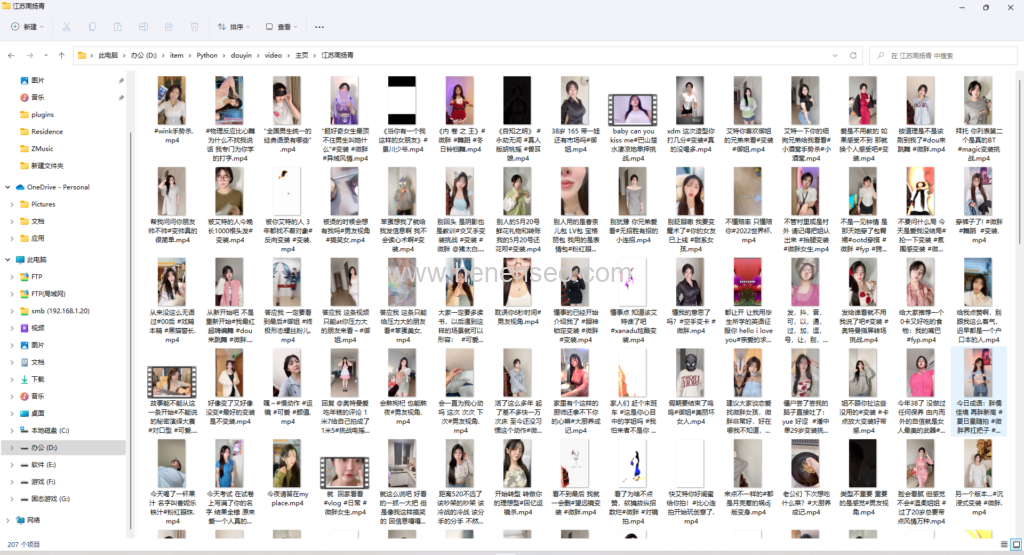
The codes are as follows (for reference only):
import os import requests from bs4 import BeautifulSoup #Initialize folder def ini(): #Determine whether the video folder exists if not os.path.exists('video'): os.mkdir('video') #Determine whether the home page folder exists If not os.path.exists ('video/home page '): Os.mkdir ('video/home page ') #Determine whether the favorite folder exists If not os.path.exists ('video/like '): Os.mkdir ('video/like ') #Determine whether the collection folder exists If not os.path.exists ('video/collection '): Os.mkdir ('video/collection ') #Link Redirection def redirect(url): header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' } response = requests.get(url, headers=header) return response.url #Replace special characters in title def replace(title): title = title.replace('\\', '') title = title.replace('/', '') title = title.replace(':', '') title = title.replace('*', '') title = title.replace('?', '') title = title.replace('"', '') title = title.replace('<', '') title = title.replace('>', '') title = title.replace('|', '') title = title.replace('\n', '') return title def operate(): Operation=input ('Continue crawling? (y/n)') if operation == 'y': start() elif operation == 'n': exit() def start(): while True: print('===========================') print('1. Author homepage video ') print('2. Like page video ') print('3. Author Collection Video ') print('===========================') Type=input ('Please enter the type of crawled video: ') if Type == '1': home() break elif Type == '2': like() break elif Type == '3': collection() break else: Print ('Input error, please input again! ') def home(): Url=input ('please enter the author sharing link: ') #Redirect url = redirect(url) sec_uid = url.split('user/')[1].split('?')[0] #Initialize cursor max_cursor = 0 #Number of initialized videos quantity = 0 #Number of videos downloaded successfully success = 0 #Number of videos that failed to download error = 0 #Request Header Settings header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' } #Start crawling while True: #Get video list url = f' https://m.douyin.com/web/api/v2/aweme/post/?reflow_source=reflow_page&sec_uid= {sec_uid}&count=21&max_cursor={max_cursor}' response = requests.get(url, headers=header) data = response.json() #Get video list aweme_list = data['aweme_list'] for aweme in aweme_list: #Update video quantity quantity += 1 #Get video title desc = aweme['desc'] #Get Author Name author = aweme['author']['nickname'] #Get video links video_url = aweme['video']['play_addr']['url_list'][0] #Determine whether the author folder exists If not os.path.exists (f'video/home page/{author} '): Os. mkdir (f'video/home page/{author} ') #Replace special characters in title desc = replace(desc) #Judge whether the video title is empty. If it is empty, use the video quantity+author name as the video title if desc == '': desc = f'{quantity}{author}' #Download Tips Print (f 'is downloading the {quantity} video: {quantity} {desc}') #Timeout processing try: #Start downloading With open (f'video/home page/{author}/ {quantity}_ {desc}.mp4', 'wb') as f: f.write(requests.get(video_url).content) #Download succeeded success += 1 except WindowsError: #Download failed error += 1 Ns=input (f '{quantity} video download failed, continue to download? (y/n)') if ns == 'y': continue elif ns == 'n': exit() #Determine whether there is another page if data['has_more']: #Update Cursor max_cursor = data['max_cursor'] else: #End the program if there is no next page Print ('Video download completed, cumulative number of videos downloaded: ', quantity,' Number of videos successfully downloaded: ', success,' Number of videos failed to download: ', error) operate() def like(): Url=input ('please enter the author sharing link: ') #Redirect url = redirect(url) sec_uid = url.split('user/')[1].split('?')[0] #Initialize cursor max_cursor = 0 #Number of initialized videos quantity = 0 quantity = 0 #Number of videos downloaded successfully success = 0 #Number of videos that failed to download error = 0 #Request Header Settings header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' } #Get collector information url = f' https://www.iesdouyin.com/web/api/v2/user/info/?sec_uid= {sec_uid}' response = requests.get(url, headers=header) data = response.json() #Get the name of the collector nickname = data['user_info']['nickname'] #Start crawling while True: url = f' https://m.douyin.com/web/api/v2/aweme/like/?reflow_source=reflow_page&sec_uid= {sec_uid}&count=21&max_cursor={max_cursor}' response = requests.get(url, headers=header) data = response.json() #Get video list aweme_list = data['aweme_list'] for aweme in aweme_list: #Update video quantity quantity += 1 #Get video title desc = aweme['desc'] #Get video links video_url = aweme['video']['play_addr']['url_list'][0] #Determine whether the favorite folder exists If not os. path. exists (f'video/like/{nickname} '): Os. mkdir (f'video/like/{nickname} ') #Replace special characters in title desc = replace(desc) #Judge whether the video title is empty. If it is empty, use video quantity+collector name as the video title if desc == '': desc = f'{quantity}{nickname}' #Download Tips Print (f 'Downloading the {quantity} video: {desc}') #Timeout processing try: #Start downloading With open (f'video/like/{nickname}/ {quantity}_ {desc}.mp4', 'wb') as f: f.write(requests.get(video_url).content) #Download succeeded success += 1 except WindowsError: #Download failed error += 1 Ns=input (f '{quantity} video download failed, continue to download? (y/n)') if ns == 'y': continue elif ns == 'n': exit() #Determine whether there is another page if data['has_more']: #Update Cursor max_cursor = data['max_cursor'] else: #End the program if there is no next page Print ('Video download completed, cumulative number of videos downloaded: ', quantity,', successful downloads: ', success,', failed downloads: ', error,') operate() def collection(): Url=input ('Please enter the collection sharing link: ') #Redirect url = redirect(url) mix_id = url.split('detail/')[1].split('/')[0] #Initialize cursor max_cursor = 0 #Number of initialized videos quantity = 0 #Number of videos downloaded successfully success = 0 #Number of videos that failed to download error = 0 #Request Header Settings header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' } #Get collection information url = f' https://www.iesdouyin.com/share/mix/detail/ {mix_id}' response = requests.get(url, headers=header) data = response.text #Get collection information soup = BeautifulSoup(data, 'html.parser') #Get collection name collection_name = soup.select('span[class="mix-info-name-text"]')[0].text #Start crawling while True: url = f' https://www.iesdouyin.com/web/api/mix/item/list/?reflow_source=reflow_page&mix_id= {mix_id}&count=10&cursor={max_cursor}' response = requests.get(url, headers=header) data = response.json() #Get video list aweme_list = data['aweme_list'] for aweme in aweme_list: #Update video quantity quantity += 1 #Get video title desc = aweme['desc'] #Get Author Name nickname = aweme['author']['nickname'] #Get video links video_url = aweme['video']['play_addr']['url_list'][0] #Determine whether the author folder exists If not os. path. exists (f'video/collection/{nickname} '): Os. mkdir (f'video/collection/{nickname} ') #Determine whether the collection folder exists If not os.path.exists (f'video/collection/{nickname}/{collection_name} '): Os. mkdir (f'video/collection/{nickname}/{collection_name} ') #Replace special characters in title desc = replace(desc) #Judge whether the video title is empty. If it is empty, use the video quantity+author name as the video title if desc == '': desc = f'{quantity}{nickname}' #Download Tips Print (f 'Downloading the {quantity} set: {desc}') #Update video title Desc=f '[the {quantity} set] {desc}' #Timeout processing try: #Start downloading With open (f'video/collection/{nickname}/{collection_name}/[the {quantity} collection] {desc}. mp4 ',' wb ') as f: f.write(requests.get(video_url).content) #Download succeeded success += 1 except WindowsError: #Download failed error += 1 Ns=input (the {quantity} set of f 'failed to download. Continue downloading? (y/n)') if ns == 'y': continue elif ns == 'n': exit() #Determine whether there is another page if data['has_more']: #Update Cursor max_cursor = data['cursor'] else: #End the program if there is no next page Print ('Video download completed, cumulative number of videos downloaded: ', quantity,', successful downloads: ', success,', failed downloads: ', error,') operate() if __name__ == '__main__': ini() start()