In November 2023, GF Securities became one of the first securities companies to obtain management quantification level (Level 4) through DCMM data management maturity capability maturity assessment. At present, tens of thousands of Kyuubi operations have become the core part of GF data comprehensive governance and key data system. Ben
This article is from Netease Hangyan big data technology expert, Apache Kyuubi PMC Member, and Apache Spark Committee You Xiduo. It focuses on Apache Spark and Native Engine, sharing what is Native Engine and why do Na
Yan Qing, a Netease Hangzhou Research Institute and Netease Sufan big data expert, has added a new title. This time, he is a member of Apache Incubator PMC. Recently, the Apache Incubator PMC (Apache Software Foundation Incubator Project Management Committee, referred to as IPMC) announced that it has accepted
Amoro is a hucang management system built on Apache Iceberg and other open data lake forms. It is open source launched by the big data team of Netease Sufan, and provides a set of pluggable data self optimization mechanism and management services, aiming to bring out of the box hucang users
Amoro is a warehouse management system built on Apache Iceberg and other open data lake forms, which provides a set of pluggable data self optimization mechanism and management services, aiming to bring users an out of the box warehouse use experience. On November 7, 2023, Amo
Apache Kyuubi [1] is a distributed multi tenant SQL gateway. Its main function is to accept the SQL submitted by users through JDBC/REST and other protocols and route it to the SQL engine under its management for execution according to the multi tenant isolation policy. In the latest version of Kyuubi 1.8, K
In the era of digital intelligence, open source software has gained unprecedented attention because it has become the core support for enterprise competitiveness. But today, the storm of cost reduction and efficiency increase has swept the world. It is difficult to stick to open source, and Netease Digital Fan has always been active in open source. Recently, Envoy community announced that it is
This article is compiled from Pan Cheng, a software engineer of Netease Digital Sail, who shared it in ASF CommunityOverCode Asia 2023 (Beijing). The main contents of this article are: 1) The benefits and challenges of Spark Cloud native; 2) How to build a unified Spark task network based on Apache Kyuubi
Background service discovery is the core of microservice governance. The traditional microservice architecture uses the Consumer/Provider model. The provider registers service information with the registry, and the consumer discovers the provider's service information through the registry. In the cloud native service grid system
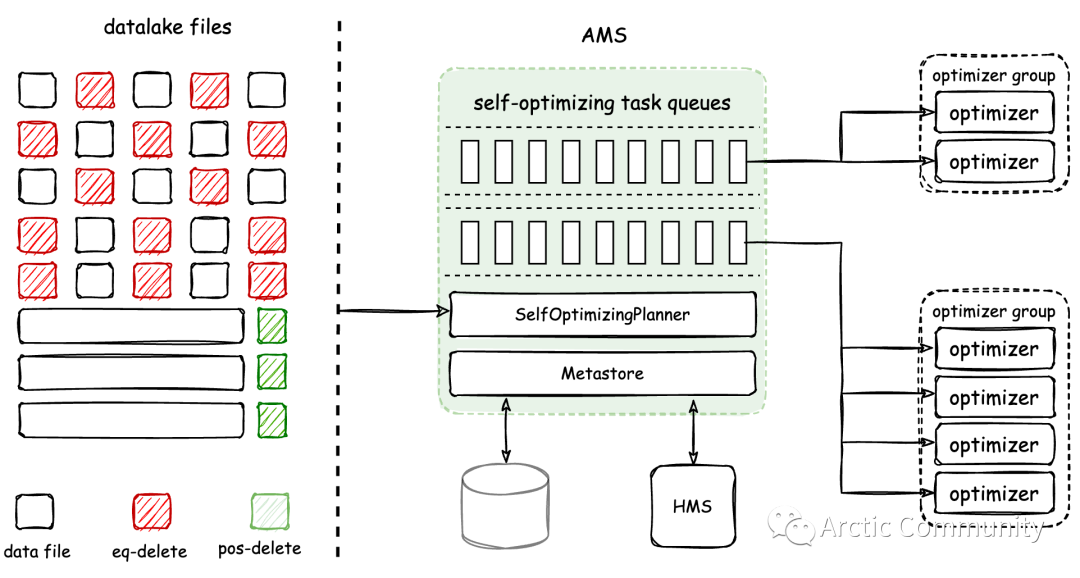
Arctic is an open architecture warehouse management system. On top of the open lceberg data lake format, it provides more optimization for flow and update scenarios, as well as a set of pluggable data self optimization mechanisms and management services. Background lake data and data warehouse are both common
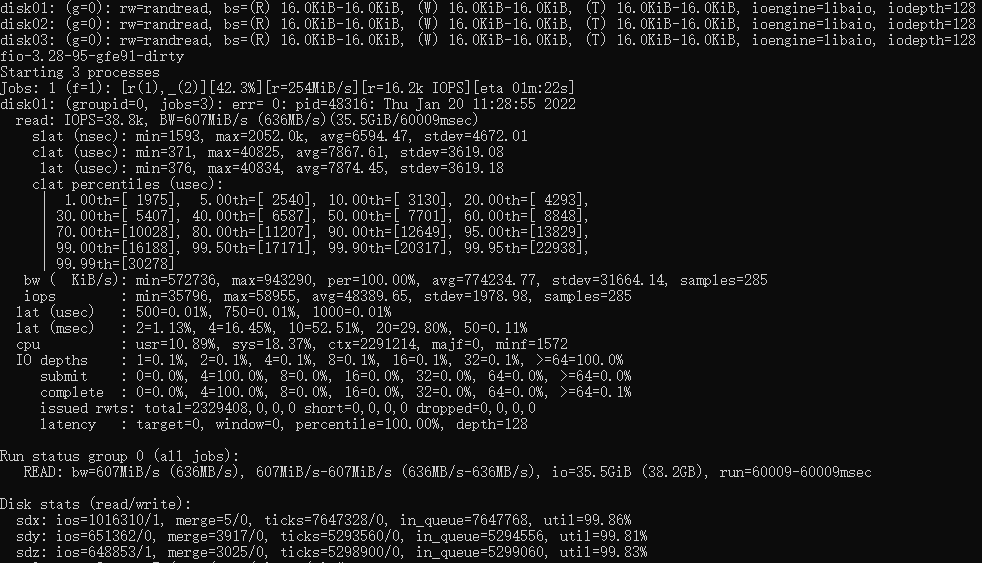
Elasticsearch is widely used in the production environment. This paper introduces a method based on NetEase's open source Curve file storage to achieve significant improvement in storage cost, performance, capacity and operation and maintenance of Elasticsearch. Four Benefits of ES Using CurveFS
Loggie sprouted from the actual needs of Netease's strict selection business, grew from the long-term co construction of strict selection and Dofan, and continued to develop in the close cooperation between Netease Dofan, Netease Media and ICBC. The extensive ecology enables the project to be constantly improved and mature based on business needs. Already
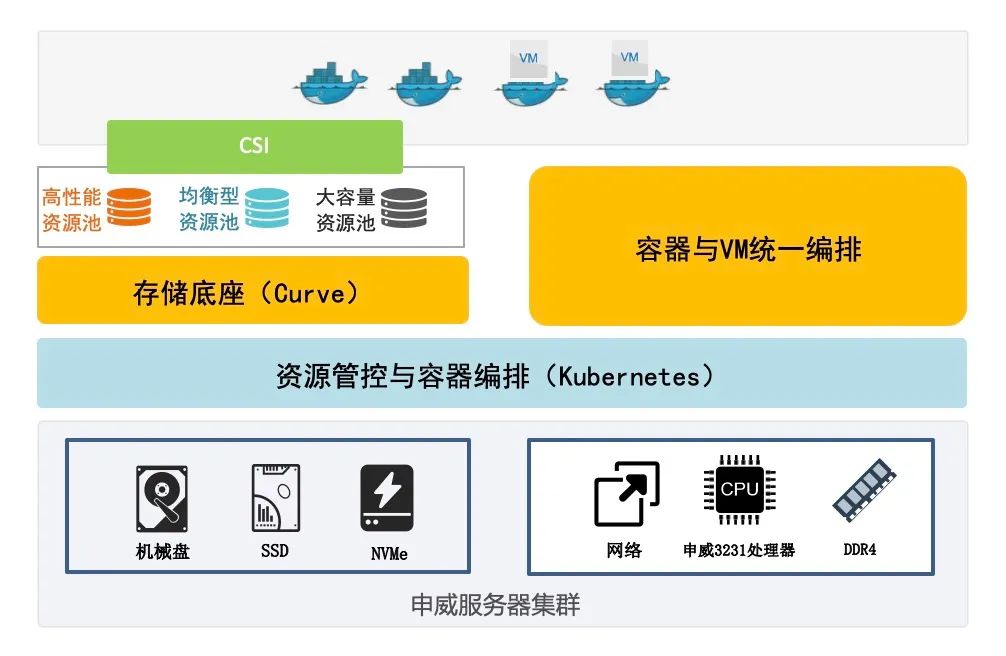
Background Yangzhou Wanfang Technology Co., Ltd. is mainly engaged in the scientific research and production of communication, computers and servers, intelligent vehicles, basic software and other products. It is a national high-tech enterprise, a small giant enterprise specializing in new technologies, and a unit undertaking the National Torch Plan. Business Introduction Shenwei Processor
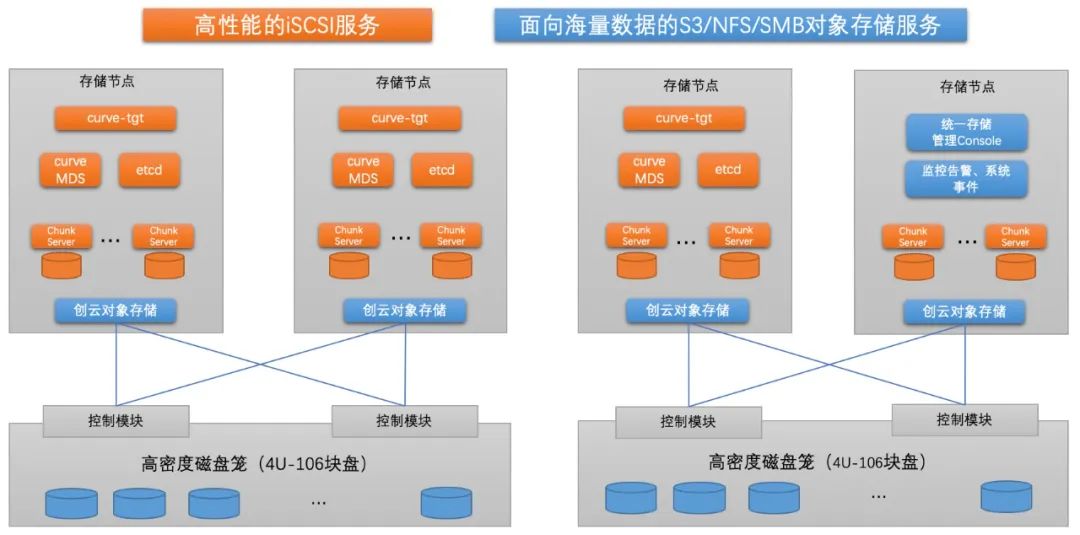
Curve is the Sandbox project of the Cloud Native Computing Foundation (CNCF), which is an open source high-performance, easy to operate and maintain, cloud native distributed storage system initiated by Netease Digital Fan. In order to make it easier for everyone to use and understand Curve, we look forward to the next series of application practice articles
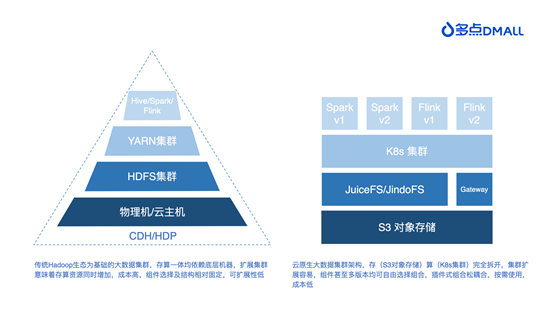
With the promotion of national industrial upgrading and the maturity of cloud native technology, the multipoint DMALL big data technology has also undergone structural adjustment and change from the integration of storage and computing to the separation of storage and computing. This article will describe the process of this exploration practice from the perspective of introducing Kyuubi to realize unified SQL proxy
Business background: Chuangyun Rongda is a high-tech enterprise focusing on the storage and management of massive data, based on the enterprise level private cloud construction capability, and providing data assets and data midrange products and solutions. In recent years, in order to optimize people's service experience of paying taxes, provinces
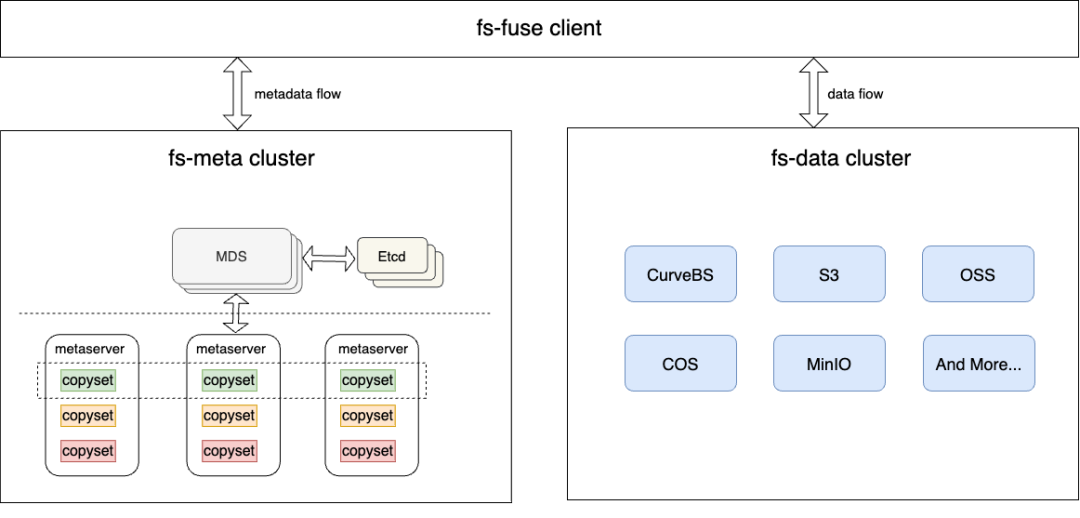
Curve file storage is a POSIX compatible distributed file system, which is suitable for private cloud, public cloud and hybrid cloud environments. We can easily access 10 billion level files through Curve file storage. First, give a brief introduction to the architecture of Curve file storage. File
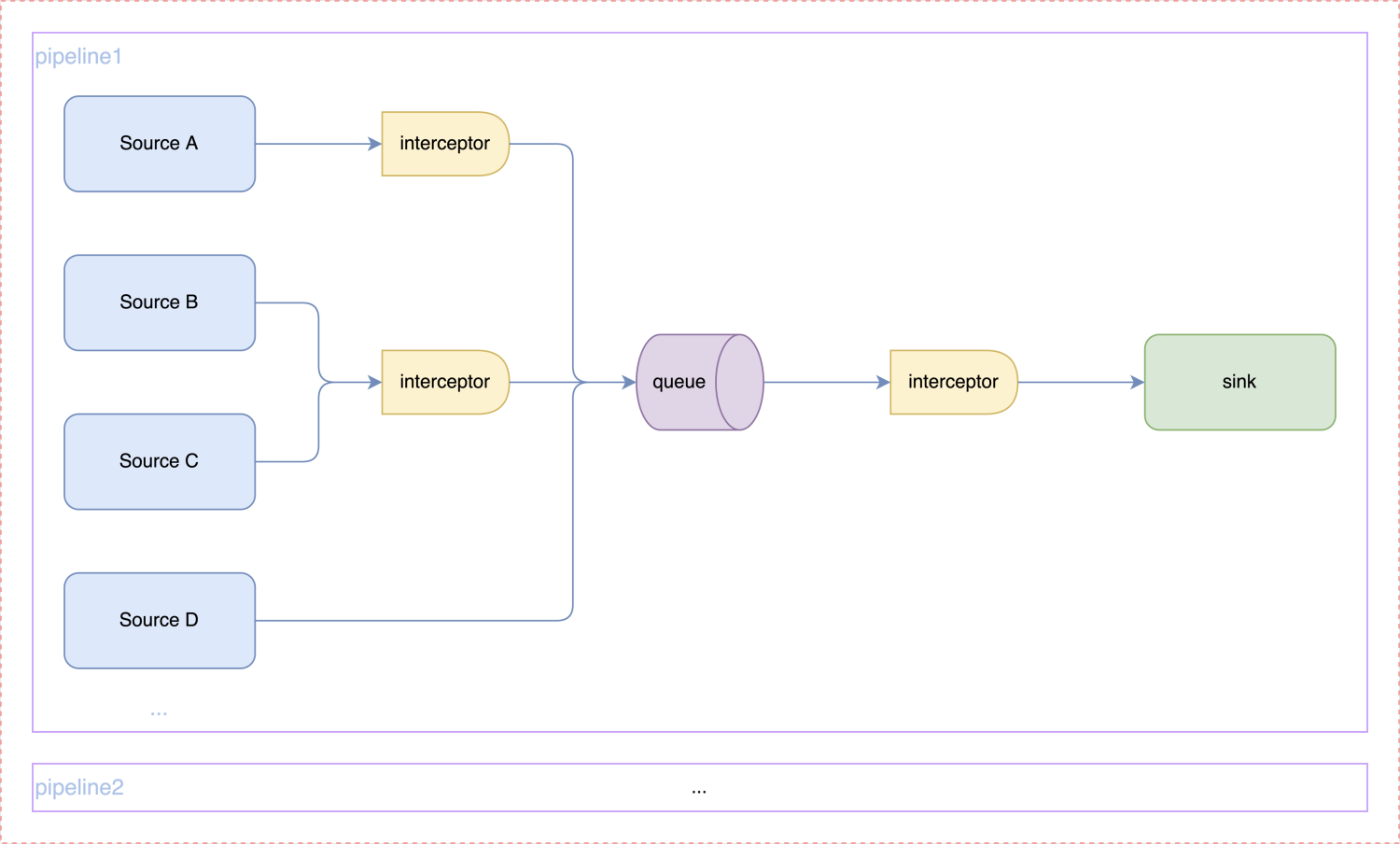
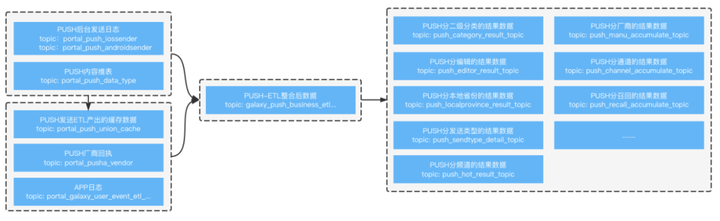
In the actual big data business of NetEase Media, there are a lot of quasi real-time computing demand scenarios, and the business side's requirements for data effectiveness are generally minute level; In this scenario, the traditional offline data warehouse solution cannot meet the user's requirements in terms of effectiveness. Instead, the full link solution is used
01 Background With the rapid development of B station business in recent years, the amount of data continues to increase. The scale of offline computing cluster has grown from the initial 200 to nearly 10000, and from single room to multi room architecture. At present, we mainly use Spark, Presto, H
Background With the development of big data business, Hive based digital warehouse system is gradually unable to meet the growing business needs. On the one hand, there are a large number of users, but it is seriously lacking in real-time and functionality; On the other hand, systems like Hudi and Iceberg are transactional
No more
Loading failed, please refresh the page
Load more