
Introduction : TFBOYS' "Daylight Travel" 7th Anniversary Concert was successfully held recently, with the highest number of simultaneous online people reaching 786000, and the public praise and box office were both good. The large-scale live broadcast solution of Netease Yunxin has supported this activity of Netease Cloud Music in the whole process. This article will share with you the story behind this stable, smooth and clear online concert.
Article | Feynman
Netease Smart Enterprise Server Development Engineer
On August 22, TFBOYS' "Daylight Travel" 7th Anniversary Concert met with fans on Netease Cloud Music Platform. According to official data, the highest number of people online at the same time in this concert reached 786000, breaking the world record for online paid concerts and achieving a double harvest of public praise at the box office.
This concert adopted Online real-time interaction and multi scene guide switching of concert scene , provides host bit and three artist exclusive slot streams, and each slot stream transcodes four definition files in real time. Users can choose what they want to see according to their preferences.
The large-scale live broadcast solution of Netease Yunxin has supported the activity of Netease Cloud Music in the whole process. Today, let's talk about the story behind a stable, smooth and clear online concert.
I Large live broadcast architecture
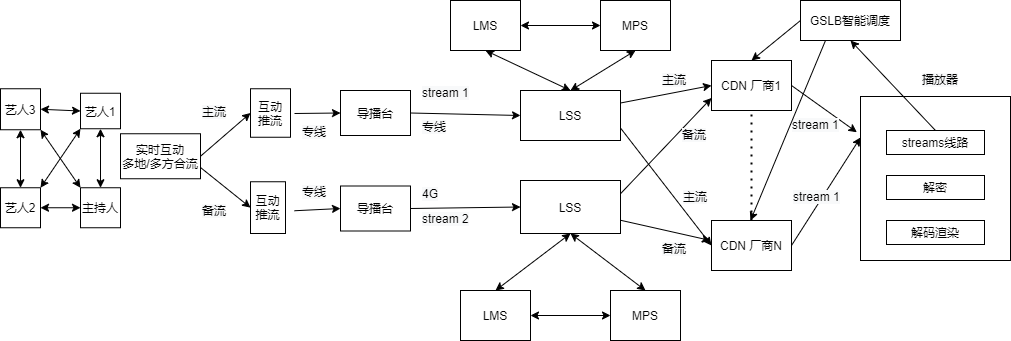
The above figure is the live media architecture diagram of the TFBOYS online concert. It can be seen that the live broadcast of a large-scale event covers a very complex technical solution. Here we will first introduce the large-scale live broadcast solution of NetEase Cloud by pushing and pulling the streaming link, global intelligent scheduling, accurate traffic scheduling and unit deployment.
- Push pull streaming link
The large-scale live broadcast technical architecture of Netease Yunxin is divided into several parts:
- Video live broadcast center (LMS, Live Manage Service), Responsible for the logical management and operation control of the live stream, including the storage and distribution of real-time transcoding, encryption and other media processing configuration information 。
- Real time interactive live broadcasting service, It is composed of two parts, namely, Lianmai interaction and live broadcast. The audio and video data of the anchor and Lianmai player are combined into a stream on the interactive live broadcast high-performance server and then pushed to the live streaming media server.
- Live source service (LSS, Live Source Service), Netease Yunxin's self built live streaming media server node, combined with the global intelligent scheduling system, provides the best link selection for the first kilometer, while integrating support for accessing multiple CDN manufacturers.
- Media processing service (MPS, Media Processing Service), It provides powerful streaming media processing capabilities such as real-time watermarking, real-time transcoding, and media data encryption.
- Integrating CDN and global intelligent scheduling (GSLB, Golabal Server Load Balancing), Provide an agile and intelligent CDN scheduling strategy and allocation algorithm, combined with full link, end-to-end streaming media control, to achieve an excellent end user experience.
- Client SDK , providing the ability to push, pull, and schedule up and down streams, so that users can quickly access and use the one-stop audio and video solution of NetEase Yunxin platform.
- Integrating CDN and intelligent scheduling

NetEase Yunxin provides an end-to-end service. It implements a scheduling similar to HTTPDNS through the platform SDK, so as to truly make the nearest access based on the user's IP address 。 In view of the relatively complex network environment of domestic operators, Yunxin can more accurately control the selection of network links through the BGP network and cooperation with relevant operators in network access in the aspect of live broadcast uplink. For the downlink, Netease Yunxin also provides SDK access at the player end, and selects the appropriate downlink nearby through the end-to-end scheduling strategy.

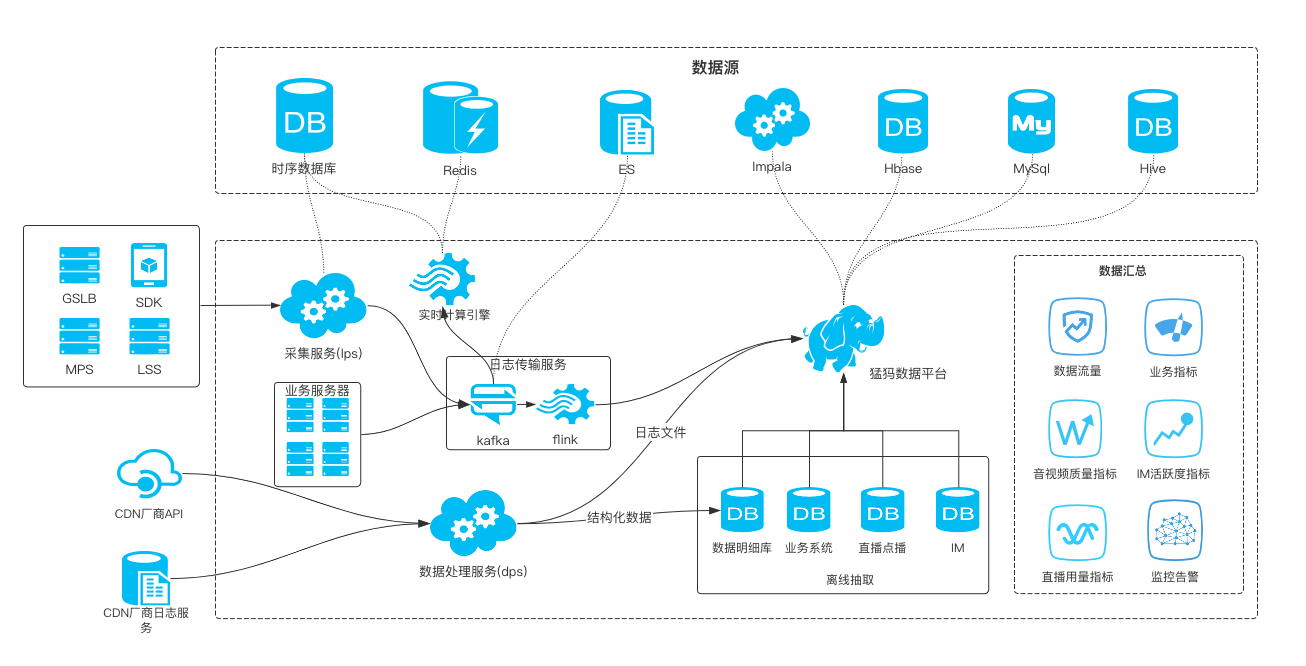
The accuracy and final effect of scheduling depend on timely and accurate data support. We have one Full link, three-dimensional data monitoring system , On the one hand, some real-time logs on the CDN are used; on the other hand, the self built node and client side report are combined to collect the data detected on the link, and then a real-time calculation is integrated to support the entire scheduling strategy.
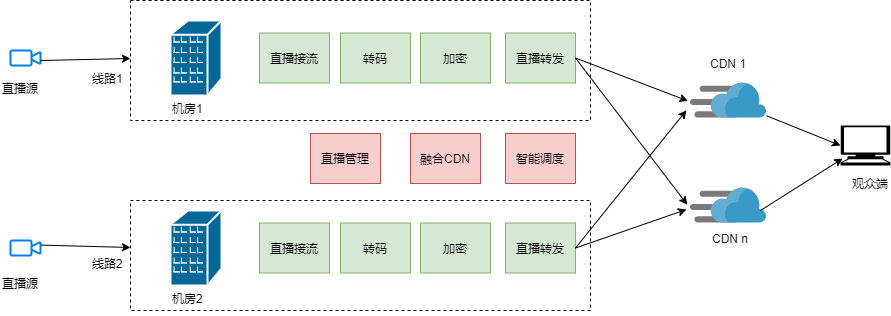
The CDN solution is integrated to solve the problems of CDN network through scheduling, monitoring, high availability and other technologies and means. However, for users on the Yunxin platform, there is no big difference as in using a traditional CDN network. These technical details are transparent and insensitive to users , Through simple and easy-to-use access to the sdk, users can have a highly available, full link controlled streaming media distribution service 。
- Accurate flow scheduling
Large live concert activities, especially in the entry stage when the official broadcast starts, will have very high peak burst traffic, which requires real-time and accurate intelligent scheduling strategy. The intelligent scheduling of cloud information integration cdn includes two parts : CDN allocation scheduling and node scheduling 。
Node scheduling is common DNS protocol resolution scheduling and IP scheduling (302/HTTPDNS) , The former scheduling takes effect slowly due to DNS protocol, while the latter can achieve request level scheduling, that is, it supports any proportion of load balancing and is more timely and accurate. In the Yunxin intelligent scheduling scenario, the IP scheduling will be followed under normal circumstances. When the IP scheduling resolution fails, the client will start the loacl DNS resolution logic. The combination of the two ensures the accuracy, stability and reliability of the scheduling.
| Don't put all your eggs in one basket.
Never put eggs in the same basket. From the perspective of risk management and control, CDN resources for large-scale activities need to be fully guaranteed. In addition to analyzing resource needs for user distribution before activities to ensure that the resources of operators in various regions are sufficient, NetEase Cloud's integrated CDN scheme is to integrate resources of multiple CDN manufacturers to achieve intelligent scheduling. The goal is to dynamically adjust the CDN weight through multiple dimensions such as quality and resource load, and ultimately ensure the user experience.
- Cellular deployment
As mentioned above, in large-scale live broadcast activities, the massive influx of user requests in a short period of time also poses higher concurrent processing challenges for related non media streaming link applications that focus on global intelligent scheduling services. In addition to the upstream streaming link, we have deployed the primary and standby units, and we have also adopted the unitized deployment scheme for services on the non media data link.
Under this deployment scheme, the availability of any unit machine room failure does not affect the overall availability, that is, multi live in different places. The unit deployment follows the following principles:
- Unitized dependency must also be unitized (core business)
- Unitize granularity to application, not api
- The cellular technology stack should not be intrusive to applications
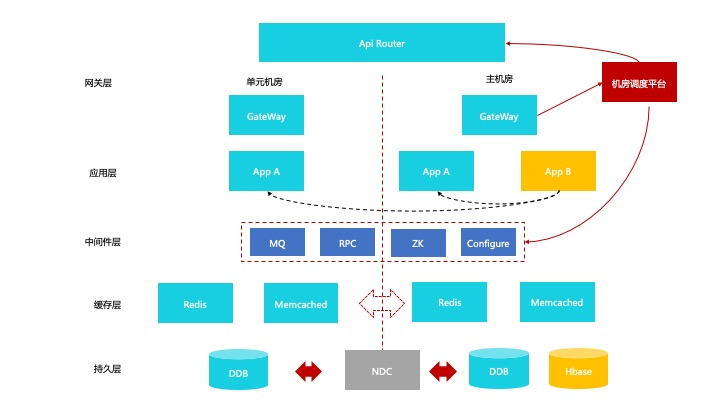
As shown in the figure above, non unitized services are deployed in the main machine room, and unitized services are deployed in the main machine room and unit machine room.
2、 Guarantee of stability and safety
- Uplink stability
The core demand of the super large live broadcast scheme is the stability of live broadcast. We will focus on this online concert as an example Full link stability architecture of Netease Yunxin large-scale live broadcast 。
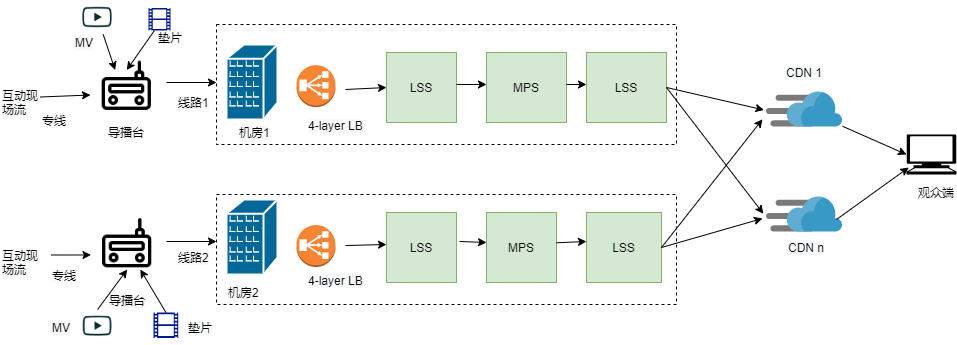
The above picture is a large-scale live broadcast of Yunxin Schematic diagram of media streaming link. The overall scheme can withstand any single node, single line, single room network outlet failure 。 For example, the live broadcast source station adopts a multi line strategy for stream collection, including the computer room dedicated line and 4G backpack scheme, with one active line and one standby line. At the same time, the source cluster of each cell has four layers of load balancing, and downtime of one machine will not affect the overall availability. LMS, LSS, and MPS are deployed across machine rooms. All service modules can be configured with proprietary resource pools for use, ensuring that they will not be affected by other tenants.
The whole streaming link adopts dual heat flow, which is the primary and standby unit, and is deployed as two independent units, which can support rack level fault disaster recovery. Dual heat flow realizes automatic active/standby switching, and there is no need to add application layer line switching logic on the end. When any link fails, the live stream of the audience will not be affected, The average stuck perception time on the end is within 1s 。
In addition to disaster recovery of the overall primary and standby units of the streaming link , The service of each unit will also have disaster recovery means 。 For example, UPS access can accept 30 min power failure. For example, when there is a problem with the real-time interaction flow, the guide station will push the shim flow to ensure that the link data is not interrupted.
- Downlink stability
In this activity, the global intelligent scheduling service will bear a large peak pressure. Based on the cellular deployment, we have undergone multiple rounds of pressure testing and performance tuning, The model can support tens of millions of users to enter the live broadcast room in half a minute 。
In addition to the high availability of streaming links mentioned above, the downlink also has related disaster recovery strategies. When the GSLB intelligent scheduling service is unavailable as a whole, we have embedded CDN integrated local DNS disaster recovery logic and proportional configuration in the client SDK, which will fail over the global intelligent scheduling of the cloud to the local backup scheduling of the client, and maintain the balance of traffic distribution among CDN manufacturers on the big data statistical level.
At the same time, the client will also have disaster recovery strategies in terms of playing experience, such as clarity degradation, line adjustment, etc.
- Live content security
Of course, besides the stability of the whole live broadcast link, live broadcast security is also very important. In this activity, Netease Yunxin provided a security guarantee mechanism for multiple links of TFBOYS activity links, such as security chain authentication, IP black-and-white list, HTTPS and other capabilities, as well as dynamic restrictions on regional, operator and other downlink scheduling, to achieve full link security.
On this basis, the event adopted end-to-end video stream data encryption, There are several basic requirements for encryption of live broadcast scenes: constant compression ratio, real-time performance and low computational complexity 。 In addition, in the context of multi cdn integration scheme, the video stream encryption must take into account the compatibility of CDN manufacturers, such as meeting the following requirements: do not destroy the streaming media protocol format, video container format; The header of metadata/video/audio tag is not encrypted; The avcSequenceHeader and aacSequenceHeader tags are not encrypted as a whole. Some stream encryption algorithms can be used for specific encryption algorithms, and we will not repeat them here.

3、 Monitoring alarm and plan
A large-scale live broadcast will involve a large number of computing nodes. In addition to the server nodes for media data processing and distribution, there are also a large number of clients distributed at home and abroad. Our perception of the health and quality of network links, service nodes, and device terminals is inseparable from the data monitoring system. At the same time, in the case of failure scenarios where the existing system is unable to automatically fail over, we need to intervene in the manual plan. The latter's decision judgment also strongly depends on the perfect full link data quality monitoring and alarm system.
- Full link monitoring
The monitoring of the entire live broadcast link includes Relevant monitoring data such as stream quality of uplink streaming link, real-time transcoding processing of media stream, end-to-end playback quality, availability of intelligent scheduling system, traffic level, etc 。 The common QoS indicators of uplink include frame rate, code rate, RTT, etc. Its dimensions include main and standby lines, export operators, CDN manufacturer nodes, etc. The QoS indicators on the end include streaming success rate, first frame duration, stuck rate, httpdns cache hit rate, and the dimensions cover CDN manufacturers, countries, provinces, operators, live streams, definition files, clients, etc.
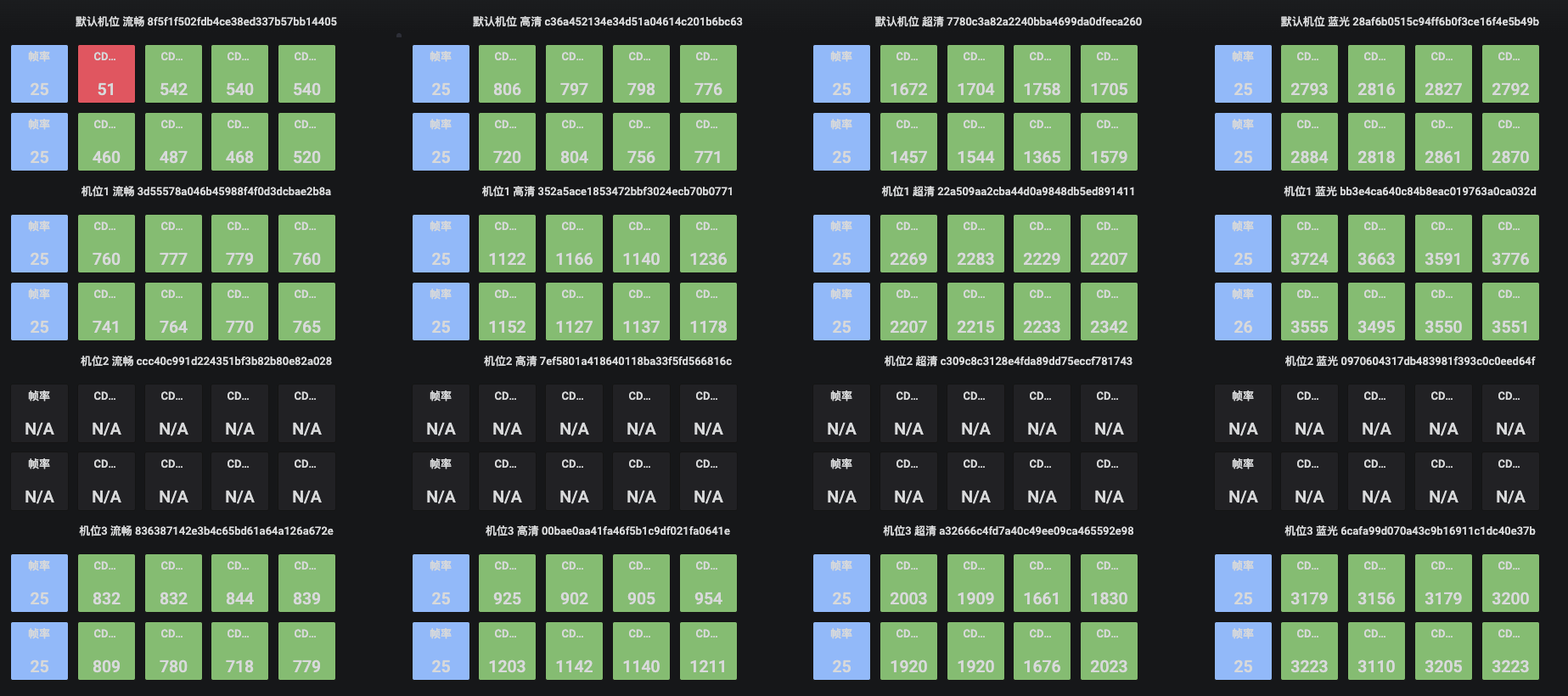
This live broadcast supports Multiple bit streams and multiple definition transcoding output streams , At the same time, it is distributed through multiple CDN manufacturers. We intuitively display the code rate and frame rate of nodes in the uplink on a single big disk page through N indicator cards, and increase the alarm value for abnormal display and pop-up message alarm. On the scene of the activity war room, we have adopted multiple large screens for display, which is very intuitive Display the real-time frame rate and code rate of the current active and standby dual streaming links , It provides strong data decision support for on-site command and support.
The following figure is an example: blue indicates the uplink frame rate, green indicates the normal uplink code rate, red indicates that the code rate value is too low, and N/A indicates that there is currently no uplink streaming data.
In the downlink playback link, the commonly used indicator is the stuck rate. The following is our description of Carton:
- Once stuck: the buffer of the player is empty for 2s, that is, the player is not pulled to the stream for 2s
- One minute user is stuck: within one minute window, if a user is stuck once, the user will be counted as a stuck user
- One minute user stuck rate: number of stuck users/total number of users in one minute window
- Zero stuck rate of users in one minute: (total number of users - stuck users)/total number of users in one minute window
Why choose the user's stuck rate instead of the overall stuck sampling points/total samples? This is because we want to see how many users have not experienced the "stuck" phenomenon, which can more intuitively reflect the overall proportion of high-quality networks. By observing the zero jam rate, user ranking, and user jam rate of each province, we can intuitively find the regions with serious jam, so as to focus on and optimize resource scheduling.
- Live broadcast emergency plan
| Hardware faults,software bugs, and operator errors, such failures are a fact of life:not a problem that will someday be solved once and for all, but a reality that we must live with.
Armando Fox.2002.Torward Recovery-Oriented Computing. VLDB 2002.
Any system, no matter how robust you claim it is designed, will still have a failure time. Hardware failures, software bugs, human operation errors, and so on are inevitable. They are not necessarily problems that must be solved within a certain period of time. They are a fact that we must recognize and accept coexistence.
Therefore, plan management is an indispensable part of large-scale live broadcast activities , We follow the following principles of the plan:
- Clear plan information : The automatic monitoring of the overall market is not ambiguous to ensure that the information source of the plan is correct, and the conditions for triggering the implementation of the plan are clear and have numerical constraints.
- Simple operation of the plan : All plan operations have concise and clear (switch type) operation input 。
- Plan operation safety : All plans should be fully rehearsed, and the rehearsal operation itself needs to have a clear confirmation mechanism to ensure that it will not be triggered by mistake under normal circumstances.
- Impact of the plan : Clearly clarify the impact of plan operation, and QA needs to fully verify the relevant impact in the rehearsal stage.
In the early preparation of this activity, we conducted a total of three live broadcast simulation drills of the whole link, two rehearsals of the whole process level of the activities in the joint interaction site and the guide station site, and a total of ten drills of various risk plans, large and small. All problems found during the drill will be specially solved.
The risk plan includes Various resource failures, uplink and downlink quality, regional network failures, CDN abnormal flow levels The resource failure includes machine downtime, overall rack power failure, stack switch downtime, and unavailability of the computer room's external network outlet. We have all carried out risk plan drills. The following are some of the plan mechanisms in the large-scale live broadcast solution of Netease Yunxin:
- If abnormal decryption is caused by misoperation, etc , Netease Yunxin can dynamically stop stream encryption without interrupting streaming, and the client has no perceived impact 。
- A CDN has a large area of failure and paralysis in an operator in a region, and the QoS indicators of the corresponding operator's lines in the region will drop significantly and trigger an alarm. Netease Yunxin will blacklist the failed CDN in the operator in the region , Dynamically stop its scheduling, and schedule the traffic to the CDN vendor that normally provides services 。
- Under the condition that the two heat flows are normal, but the one being distributed has quality problems, the scheme can support manually triggering the active/standby switch, so that the other flow with better monitoring data quality can participate in the distribution , The client perception time is within 1s 。
- Because of some irresistible factors, a large area of failure occurs in one machine room and the whole machine room is unavailable, triggering the link alarm. At this time, we will urgently switch the flow to another machine room , Fault awareness and recovery time is within one minute 。
4、 Conclusion
Relying on the ten million level large-scale live broadcast scheme of Netease Yunxin, this activity was successfully completed, the overall streaming link was reliable and stable, the downlink traffic was allocated reasonably, and the relevant failure plans were complete, full and effective. There are thousands of dry goods and short stories. Please consult Netease Yunxin's large-scale live broadcast plan immediately for more technical details.
Author Introduction
Feynman is a development engineer of NetEase Smart Enterprise server. Graduated from the Department of Telecommunications of Huazhong University of Science and Technology, he joined NetEase Yunxin in 2016. He is keen on large-scale distributed systems and audio and video related technologies, and loves literature, sports and movies.
*The source and author of articles reproduced in various channels shall be indicated
















































