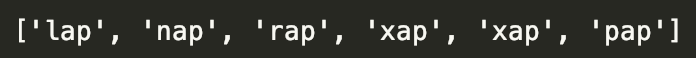Recently, when making the evaluation corpus, the editor involved in filtering and extracting some complex strings. For example, to find the words in a sentence under a specific sentence structure can be solved by using statements such as loops and if else, but it is troublesome and convenient to use regular expressions.
Regular expression definition
Regular expression, also known as regular expression (RE), uses a single string to describe and match a series of strings that conform to a certain syntax rule. In many text editors, regular expressions are usually used to retrieve and replace text that matches a certain pattern.
For example, suppose you use a crawler to get an HTML source code, one of which is:
str1=r" < html > < body > < h1 > hello.world < h1 > </ body > </ html > < h1 > hello:world < h1 > < h1 > helloAworld < h1 > "
At this time, if you want to extract all the hello (x) worlds, you usually need to split the string. But when the second<h1>becomes</h1>, the problem becomes complicated. The following regular expression can directly translate hello (x) Word extracts:
import re p1 = r"hello.world" pattern =re.compile(p1) print(re.findall(pattern, str1))
Where p1 is Regular expression string, Between hello and the world Of “ . ”It is an object that can match any character Metacharacter (introduced later) , pattern is obtained after compiling Regular expression object The purpose of this is to facilitate reuse in later matching. The result of the above expression is:
Regular expression matching method
In addition to the findall method described above, the common matching methods for regular expressions are match and search. The difference between the three methods is:
match: Match the regular expression from the start of the string. If it matches, the result of successful matching will be returned; If it does not match, it returns None;
search: When matching, it scans the whole string and returns the first successful matching result. If the search is complete and the result is not found, it returns None;
findall: This method will search the entire string, and then return a list that matches all the contents of the regular expression.
Regular expression range matching
Within a string, we can select some characters or not within a range, such as the following strings:
str2 = r"lap &ap nap rap xap xap pap"
For str2, we want all normal strings except&ap to be completed by the following expression:
p2 = r"[lnrxp]ap" pattern = re.compile(p) print (re.findall(pattern,str2))
The result of the above code is:
In the above regular expression, for the (x) ap with fewer categories in str2, it is obviously unrealistic to use this statement when there are 26 letters and case sensitive, Python has many simple regular expressions built in to avoid the need to write the desired letters one by one during the extraction process. Common ones are:
[0-9] 0123456789 Any one of
[a-z] Any one of the lowercase letters
[A-Z] Any one of capital letters
\D is equivalent to [0-9]
\D is equal to [^ 0-9], that is, it matches non numbers
\W is equivalent to [a-z0-9A-Z] matching uppercase and lowercase letters, numbers and underscores
\W is equal to the previous item
Therefore, for the above regular expression p2, using r " wap" and r "[a-z] ap" gives the same result. In addition, we have already introduced“ . ”Metacharacters, in p2“ [] ”It is also a metacharacter, which indicates that the current expression matches any character in []. Python also has many built-in metacharacters, which makes it easier for us to write regular expressions more succinctly. Readers can visit the following website to view the definition: https://www.runoob.com/regexp/regexp-metachar.html 。
Greed and Laziness of Regular Expression
Assume the following string:
str3 = r" sogoutest@sogou-inc.com.cn "
If we want to match the contents in str3 from @ to ".", we can do this
p3 = r"@.+\. " pattern= re.compile(p3) print (re.findall(pattern,str3))
Among them, "+" is also a metacharacter, which means matching the nearest character before it one or more times. As you can see, at this time, the expression matches as many as possible, and matches the "." after com, that is, greedy pattern. If you only want to match to the end of the first point, you can use the following statement to change to lazy mode.
p3 = r"@.+?\. " pattern= re.compile(p3) print (re.findall(pattern,str3))
At this point, we can see that the result ends when it matches the "." after inc.
Reference link:
one https://www.py.cn/spider/guide/14488.html
two https://www.py.cn/faq/python/12021.html
three https://www.runoob.com/regexp/regexp-metachar.html
Regular expressions play a very important role in string processing. Combined with the metacharacter list provided by Python, more complex statements can be realized. There may be many solutions to the same problem, which need to be mastered in ordinary use.