Node is not a panacea! But it does solve some key problems.
Learning Node is not easy, but the rewards you receive are worthy of your efforts. Because JavaScript is the only way to solve many problems in current Web application development.
catalog
1. Warnings from experts!
- Node: Several small examples
- Node is not JavaScript. Node can run JavaScript
- Interaction with node server 5 Quick Start Manual 6 The puzzle of the interpreter
- Event based web application
- Use of Node
"Are you cool enough? Use me!"
Node.js provides a series of cool APIs and toolkits for the latest programming languages. It can be directly applied to traditional Rails, Ajax, Hadoop, and even iPhone development and HTML5 to some extent.
If you have attended some large technical conferences, you will always hear some keynote speeches about Node.js, although these topics are still difficult for ordinary developers to reach.
You may have heard that Node.js (sometimes referred to as "Node" for short) is a server-side solution that can run JavaScript and process HTTP requests as a Web service. If these things don't make you dizzy, the discussion about ports, sockets and threads will become the hottest topic again in a twinkling of an eye. You will feel dazzled by these things. Does this really belong to JavaScript? Why do so many people in the world prefer to run JavaScript away from the browser, let alone run JavaScript on the server side?
The good news is that everything you hear about Node is correct. Node really belongs to the category of network programming, which is used to process requests and responses from the server.
The bad news is that, like the previous Rails, Ajax and Hadoop, there are too few really practical technical materials. After the "excellent" framework based on Node matures, the technical materials will certainly keep up, but why wait until the technical books and tutorials are available before trying to use Node? Using Node now may bring unexpected changes to your code, or even make your program easier to implement.
Special warning!
Like most technologies, Node is an old wine in a new bottle: it looks opaque and strange, but it is favored by small development teams. If you have not touched the node, you need to learn some server side scripts that are easy to use. You need to take time to figure out Node, because even JavaScript running on the server side is very different from client-side JavaScript. The truth is that you have to brainwash yourself to re learn and understand the event processing mechanism, asynchronous IO and some basic network knowledge around JavaScript.
Unfortunately, this means that if you have used Node for development for more than two years, you will find the content of this article boring and too simple. You will start looking for new "stimuli", such as running the Node on the client, or trying event I/O, reflector mode, and npm. You will find that the world of Node is so interesting, and even many advanced technologies of Node have some kind of epic beauty, which is still difficult for beginners to reach. Therefore, perhaps you should share your knowledge with your peers, especially those who do not know Node. When they become interested in Node, they should share and teach them the advanced technology of Node.
First of all, you should realize that Node is used to run independent JavaScript programs, rather than running in an HTML fragment in the browser. It is a real file stored in the file system. It is executed by the Node program, runs in a daemon mode, and opens listening on some ports.
Skip hello world
The most classic example is of course "Hello World", on the official website of Node( http://nodejs.org/docs/latest )Source code is available on. Almost everyone started to contact Node from Hello World.
Now let's skip this simplest example and look at some more interesting examples: implementing a program that can send files from the server to the client (rather than just sending a piece of text to the client).
var sys = require("sys"), http = require("http"), url = require("url"), path = require("path"), fs = require("fs"); http.createServer(function(request, response) { var uri = url.parse(request.url).pathname; var filename = path.join(process.cwd(), uri); path.exists(filename, function(exists) { if(! exists) { response.writeHead(404, {"Content-Type": "text/plain"}); response.end("404 Not Found\n"); return; } fs.readFile(filename, "binary", function(err, file) { if(err) { response.writeHead(500, {"Content-Type": "text/plain"}); response.end(err + "\n"); return; } response.writeHead(200); response.end(file, "binary"); }); }); }).listen(8080); console.log("Server running at http://localhost:8080/ ");
Thanks to Mike Amundsen, who gave a similar implementation of this code. This example is a piece of code submitted by Devon Govett on Nettuts+. Although it has been updated according to the new version of Node, Devon's entire post is a very good introductory learning material, especially for beginners.
If you are a novice, you can save the above code to a text file named NodeFileServer.js. Before running, you need a node running environment. The latest node version can download this file from the official website or get the source code from github. You need to compile the source code. If you have not used Unix and are not familiar with make and configure, you need to consult the online compilation manual for help.
Node is not JavaScript. Node can run JavaScript
Just now you saved NodeFileServer.js as a file. Don't worry, we will run it later.
Now, let's move to reality and execute typical configuration and compilation commands in Unix:
./configure make make install
This makes us convinced of the fact that Node is not JavaScript. Node is a program that can run JavaScript, but it is absolutely not JavaScript. In fact, Node is a program written based on C.
You can view the files in the node/src directory through ls. You can see the source code of the node:
Most people would think that JavaScript is a bad language, let alone using it to implement server-side functions. In fact, you are only half right. Yes, JavaScript may not be competent for socket and network programming at the operating system level. However, Node is not implemented in JavaScript. It is based on C. C language is perfect for network programming of any magnitude. JavaScript is fully capable of passing instructions to C programs, which then control the operating system "underground city". In fact, compared with the C language, JavaScript is more accessible to developers, which is worth noting. If you want to do some serious programming with Node, this reason will be mentioned again and again.
The basic usage of nodes further reflects how nodes work with JavaScript. Nodes are not JavaScript.
You can run it from the command line:
— ( bdm0509@Bretts-MacBook-Pro Sun, 29 May 11) — — — — — — — — — — (/Users/bdm0509/tmp/Node/src) — — (09:09 $)-> export PATH=$HOME/local/Node/bin:$PATH — ( bdm0509@Bretts-MacBook-Pro Sun, 29 May 11) — — — — — — — — — — (/Users/bdm0509/tmp/Node/src) — — (09:09 $)-> cd ~/examples — ( bdm0509@Bretts-MacBook-Pro Sun, 29 May 11) — — — — — — — — — — — — (/Users/bdm0509/examples) — — (09:09 $)-> Node NodeFileServer.js Server running at http://127.0.0.1:1337/
Now you must have a general understanding of Node. For this command line, there are still many knowledge points that need further explanation. For example, what happened on port 1337? But all you need to know here is that Node is just a program that allows you to run JavaScript. Readers don't have to worry about how Node works with JavaScript, nor will they talk too much about it here. It's enough to know that Node can run JavaScript. And you just need to learn JavaScript, a programming language, without worrying about not understanding C language. Remember that this is the most important point. It is not necessary to know C to write a node executable program.
Interaction with node server
Just now we ran on Node NodeFileServer.js 。 At this time, you can access your local 1337 port and see the normal output.
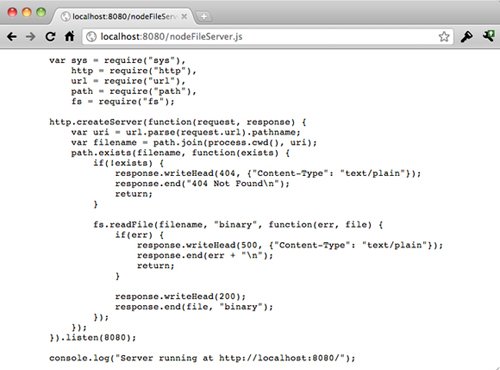
Yes, the output is not surprising. However, we should realize that we only need 20 lines of code to implement a file server. The output result is the text of the script source file you just saved, not in binary form. This file server can output any file on it. If you put an image in the same directory, write the image file name in the URL suffix, as follows: http://localhost:8080/my_image.png 。
Node can also display binary image files. When you look back at this short program, you must think it is too incredible. Wouldn't it be nice to write a service program you want with JavaScript? Moreover, suppose you want to write a service that can handle multiple requests (this is a prompt, and four or five or even ten browsers are opened at the same time to access the server). This is also easy to do.
The fascinating thing about Node is that you can use very simple and inconspicuous JavaScript programs to complete the results you want.
Quick Start Guide
The topic around Node is always worth spending more time discussing than the code running on the server. Anyway, let's start with a piece of code, take a look at the NodeFileServer.js file, and observe the code:
var http = require('http'); http.createServer(function (req, res) { res.writeHead(200, {'Content-Type': 'text/plain'}); res.end('Hello World\n'); }).listen(1337, "127.0.0.1"); console.log('Server running at http://127.0.0.1:1337/ ');
First called the function require() , require() It is one of the functions most commonly used by programmers. In fact, this function is also mentioned in the CommonJS specification. It was mentioned when discussing the concept of JavaScript module. In addition, Davd Flanagan also mentioned in a cool implementation in 2009. let me put it another way, require() It may be a new thing for you, but it is not a function that Node adds at will. It is the core concept of modular programming using JavaScript. Node gives full play to this feature.
Next, the http variable is used to create a server. This service uses a callback function to handle actions when a connection is generated. The callback function here does not modify the request too much, just text/plain Output a string in the format “Hello World” Respond as a request. This logic is very simple.
In fact, the standard mode of using Node is shown here:
- Define the interaction type and obtain a variable to handle this interaction (via
require() )。
- Create a new service (via
createServer() )。 * Bind a callback to the service to process the request. Functions including processing requests should include a request... and a response
- Notify the server to start the service. Here, you need to specify the IP and port (through listen).
The puzzle of the interpreter
Although this method can easily implement a service using JavaScript (no matter whether the virtual machine running code actually runs C programs or other programs), this approach avoids the question: Do you need to write a server using JavaScript? To find the answer to this question, let's consider a very typical scenario.
JSON processing
This is a very typical web application. The foreground uses HTML and CSS, and JavaScript is used for data verification and data interaction with the background. Since you are at the top of the web interaction, you use Ajax to submit data to the background and obtain data from the background, rather than relying solely on form submission. If you do this, you will also like to use JSON. JSON is the most popular data transmission format today.
Therefore, this Ajax can also be compared to "sending me some guitar information from the online auction website". This request reaches a server running PHP programs through the network. The PHP server has to return a lot of information to JavaScript, and the information must be sent to the client in some form of data package, which can be parsed by JavaScript.
Therefore, the data can be packaged into arrays and then converted to JSON, as follows:
$itemGuitar = array( 'id' => 'itemGuitar', 'description' => 'Pete Townshend once played this guitar while his own axe ' . was in the shop having bits of drumkit removed from it.', 'price' => 5695.99, 'urls' => array(' http://www.thewho.com ', ' http://en.wikipedia.com/wiki/Pete_Townshend ') ); $output = json_encode($itemGuitar); print($output);
Back to the client, JavaScript gets the returned data package. After conversion, the data is programmed in JSON format. Like this:
{ "id": "itemGuitar", "description": "Pete Townshend once played this guitar...", "price": 5695.99, "urls": [" http://www.thewho.com ", " http://en.wikipedia.com/wiki/Pete_Townshend "] }
This conversion is standard, and is equivalent to each other before and after the conversion. Next, you can convert this string into a JavaScript object and call eval() , like this:
var itemDetails = eval('(' + jsonDataString + ')');
The calculation result is a common JavaScript object whose properties are consistent with the data structure of JSON array. Of course, since jsonDataString is usually returned by the server, the returned results usually need to be parsed as follows:
var itemDetails = eval('(' + request.responseText + ')');
This is the most typical JSON processing, but there is a very serious problem.
Subtle destructiveness to entity code
(Note: This subtitle is really puzzling. The author explains one of the advantages of Node here in a roundabout way, that is, the front-end and back-end use the same language JavaScript, which is barrier free when doing JSON parsing. While the current side uses JavaScript for JSON encoding, and the background uses PHP for JSON decoding, the implementation of JSON parsing in multiple languages will bring some differences Compatibility issues)
First of all, a major problem with this kind of code is that it relies heavily on the interpreter. In the previous example, the interpreter refers to the built-in JSON parser or the code that implements parsing JSON, which actually depends on two things: and eval() The operation of parsing response text is the same as that of Java based JSON parser and PHP based JSON parser. The JSON parser has been included in PHP 5.2.0, but it is provided in the form of external dependencies, not built into the PHP kernel.
But this is not to publicize the interpreter. After all, there are still many problems with the interpreter itself. For example, "I" is parsed into "i", and the element 1 in the array is interpreted as 2. Of course, before the official release of the JSON tool, there will be a lot of tests to ensure that no errors will occur in various complex scenarios, including the resolution results on the client side and the server side. In any case, this requires a lot of testing.
However, JSON still has many practical problems.
The choice of JSON parser based on a certain language (based on JavaScript or PHP) is a big problem. In other words, the problem is not "translation" but "translator" (the author means that there is no problem with the rules of JSON itself, but the quality of JSON implementations in various languages is uneven, even with many bugs).
When the version of a language is relatively stable, the application and promotion of JSON parsers based on this language will be faster. As a result, the JSON parser has become more and more powerful, so that it can parse any complex data structure, even if such a complex data structure is not actually used. On the contrary, in each iteration (the combination of the path and data type of each calculation iteration), it is also very likely that data structures (or very deep JSON paths) that cannot be parsed by the JSON interpreter will occur.
This is not to say that JSON itself is terrible. In fact, we believe that the popularity of JSON is due to its application in new fields.
For the new field, we can't help asking: "Does this new thing support JSON?" Therefore, JSON needs to evolve, test and be compatible with new platforms. As a programmer, you may need to reorganize your data structure, wait for a new version to meet your needs, or hack JSON directly. These are exactly what we call the waste of programming resources.
Suppose you can implement an interpreter by yourself. Even so, you don't get cheap by "cutting corners", but use JavaScript to repeatedly build wheels.
Node avoids such problems. The text you just read about PHP 5.2.0 for embedded JSON, about converting objects into arrays, about using new structures to organize data, and about the implementation of new features in JSON all these disturbing problems will disappear in Node, because the front end uses JavaScript for JSON encoding and the back end uses JavaScript for JSON decoding, There will never be a problem.
Potential pitfalls of eval() in JavaScript
Just as we don't treat Node as a new language, executing a piece of code through eval() in Node is the same as eval() in JavaScript (not recommended).
It is well known that eval() is very dangerous. Eval() is used to execute the code logic represented by a piece of text, which can be understood as "directly typing SQL code to execute query" in the text box. This is unsafe, which is actually malicious SQL injection. Every time eval() executes a string, a dog in the Midwest will shiver, and a mother on the eastern beach will be stabbed and cursed on her toe. Eval() is very dangerous. There are a lot of information about this on the Internet, so I will not repeat it here. You can use Google to query "eval JavaScript evil" or "eval JavaScript injection" for more information.
Of course, eval() is allowed to be used in the node without any other context constraints, so the hidden danger of eval() still exists in the node. After all, the purpose of Node is not to completely solve the eval() problem. Node is called event based JavaScript or event based I/O. Event based I/O is a very important concept in Node. But to thoroughly understand what is event based and why event based can help you avoid the danger of eval(), you need to understand how JSON works in applications, and also know the unique data structure suitable for typical web application architecture.
Event based web application
Traditional Web form submission is a typical event based mode. In other words, a lot of data is entered in the Web form (the user enters the text box, clicks the check box, selects some items from the list, etc.), and then these data are submitted to the server.
This scenario is actually a single program event: submit the form data in POST mode. This is also the working principle of Ajax based Web applications.
Send a large amount of data at one time
For Ajax, it can be related to event based programming. Some interactions between the client and server can be considered event based. A typical scenario is to enter a province code and send a request to the server to obtain the name of the city and province. Here, Ajax through XmlHttpRequest does not need to throw a lot of data to the server at once. However, this does not change the current situation that most web applications are based on page refresh. Ajax has been more widely used for many interesting visual related interactions. It can quickly perform form validation and submit data without refreshing, so that you can avoid reloading the page. Therefore, although a real POST request is not initiated by submitting the form, Ajax can simulate POST form submission.
Frankly speaking, this traditional Ajax interaction mode also hinders the innovation of Ajax programmers. Every time a request is sent (no matter how small the requested data is), it will go back and forth in the network. The server must respond to this request, usually by starting a new process.
Therefore, if you are really developing in an event model environment, you may need to maintain the connection between your page and the server by launching 10 to 15 separate small requests. The server will also create 10 to 15 threads for it (perhaps less, depending on the strategy of allocating thread pools when the server processes new requests), When this number is multiplied by 1000 or 10000 or 100000, problems such as memory overflow, conflicts caused by logic interleaving, network paralysis, and system crash will occur.
As a result, in most scenarios, Web applications need to maintain minimal dependency on events. There is a compromise, that is, the response of the server-side program returns not a tiny piece of data, but a packet with more redundant data structures, usually JSON data. At this time, we encounter the eval() problem. Of course, the problem lies in eval(), but it is also closely related to the Web itself and server thread control, including the HTTP request and response strategy (at least in this scenario) between pages and servers.
Maybe some people are not satisfied with the problems mentioned above, because you know that there are many ways to avoid the problems caused by direct eval(), and you will use JSON. parse() instead of eval(). There are also many convincing arguments encouraging us to use eval() carefully. These things are worthy of further discussion.
However, if you take a look at eval(), there are too many problems like stack overflow. You will find that most programmers do not use eval() correctly or safely. This is really a problem. Because too many novice programmers don't seem to realize how serious the problem of eval() is.
Constantly send a small amount of data
Node brings a new idea of building applications. We can use event models based on Node to build Web applications, or "small" event models. In other words, you should send a large number of requests based on a large number of events. The data packets of each request are very small, or grab a small amount of data from the background as needed, instead of sending a small number of requests. Each request contains a large amount of data.
In many scenarios, you need to wake up GUI programs in most cases (Java Swing programmers' GUI knowledge reserves can be used). Therefore, when the user enters his/her last name and first name, he/she moves to the next input box. At this time, a request has been sent to verify whether the entered user name already exists. The same is true for the verification of provincial codes, addresses, and phone numbers. Every time that occurs on the page, a request and response will be generated.
Is there any difference? Why can Node do this and avoid existing thread problems? In fact, Node is not so mysterious, and its official website fully explains its philosophy:
Node aims to provide a solution to build scalable network applications. In the hello world example, the server can handle many client connections at the same time. There is a contract between the node and the operating system. If a new link is created, the operating system will notify the node and then go to sleep. If someone creates a new link, it (Node) executes a callback, and each link only consumes a very small (memory) stack overhead.
The node is non blocking and does not compete for threads from the same source (the node is very happy to handle immediate requests. Let it happen if anything happens). When a new request arrives at the server, there is no need to do anything for the request alone. The node just sits there and waits (the occurrence of the request), and processes the request when there is one. It can be implemented with very simple code, without spending the programmer's precious energy to implement a whole set of server-side logic.
Yes, chaos is inevitable
It is worth mentioning that the problems caused by non blocking systems also occur in this programming mode: a process (non thread) waits for a data storage operation, and then another operation is generated to grab irrelevant data, This unexpected operation will affect the existing waiting. Note, however, that most event based web programming patterns are "read-only"! You probably haven't encountered the case of modifying data through "micro request", or it is very rare. On the contrary, it is very common to verify the validity of data and query data through such requests. In this case, it is better to respond directly to the request. The database itself can be locked. Generally speaking, an excellent database can effectively lock and unlock data operations without having to do more with server code. The node is more efficient than the operating system to maintain and release threads, so the server does not have to create a process for "web response".
In addition, Node also plans to implement "process forking". The HTML5 Web Workers API provides engine (specification) support for more complex process control.
Similarly, if you adopt an event based model to build web applications, your application may have at least 100 scenarios that require thread support.
Finally, you will find that your programming ideas and ways of thinking about problems have changed. Your attention will be focused on the logic of server processing requests, and you don't need to care about how Node works.
Use of Node
Here we discuss another web development mode. It doesn't matter whether Node or event based programming mode is adopted, because this mode is too important.
In short: suit the remedy to the case! Generally speaking, different solutions are adopted for different problems, regardless of whether such solutions solve other problems.
Thinking set
Not only in the field of web design, but also in all programming, there is a certain mindset. This thinking pattern can be described as follows: the more you learn and master, the more problems you can solve, and the more application scenarios of skills you have mastered.
This seems natural unless you dig deeper into the technology. Yes, learning new languages and tools and using them widely is not a bad thing. But it often leads to a misunderstanding that you use it because you know it, not because the skills and tools you have mastered are "most suitable" for your business.
Let's take a look at Ajax. There has been too much discussion about Ajax. As we know, Ajax provides a reliable solution for fast query requests without refreshing. Now, because of the abuse of Ajax, it has excessively replaced the traditional form submission. We encounter a new technology, learn it, master it, apply it, and then "abuse it". After all, many business scenarios only require traditional form submission, not Ajax. It's simple to say that there are actually thousands of cases of Ajax abuse, just because the development engineer of an application has blind respect for Ajax.
Similarly, Node also faces such a problem. When you first know Node and find its advantages, you want to use it everywhere. The PHP or Perl program will be replaced with Node. What's the result? It's terrible. In fact, you have been suffering from obsessive-compulsive disorder, and always want to use Node in scenarios that go against its original design intent: use JavaScript to submit a large amount of data to Node, or use Node to return a large amount of JSON data to JavaScript through Node, and send it to the front end for eval(), or simply use Node as a file server to return HTML pages or do HTTP redirects.
However, these scenarios are not good at Node. Node is better at handling small requests and event based I/O. Node is used to solve the rapid communication between client and server, form submission is used to send a large amount of data to the server, and PHP and Perl are used to handle heavy database operations and the generation of dynamic HTML pages. The node is used to run on the server side to process small requests. Whether you use Rails, Spring, or various server containers, just ask for them on demand.
Be sure to understand what problems you need to solve, and take the best solution based on this, rather than solving problems based on your current skills.
Node's simple original intention
One last thing to note is that as you go deeper and deeper into your programming, you will find that you do not need to be proficient in every tool, API, and framework you use. Use the knife on the blade, do not use the hammer as a drill bit. Understand the applicable scenarios and problems that can be solved for each tool, and then find the most suitable application scenarios for this tool.
If you want to become a superman generalist (programmers often want to know everything), you will be farther and farther away from "experts". The so-called expert means to be very proficient in one or two aspects. Of course, every boss hopes to find superman generalists, but such people are often hard to find.
It may be hard to learn Node, but it is worth it. Why? Because you are looking for solutions for JavaScript based web applications. This means that your existing JavaScript programming skills will not be lost. When you need to use PHP or Perl, you must learn a new language again, and Node does not have to make such a big fight. Learning new languages brings more problems than benefits.
The challenge of learning Node is that you need to think more actively, break the program into small pieces of low coupling, and then assemble them like an array. However, node and event based I/O cannot solve all problems, but it is certain that many key problems can only be solved by nodes.















































