Hadoop is generally deployed on the Linux platform. If you want Hadoop to execute our written programs, you need to first write the program package locally, then upload it to Linux, and finally execute the packaged program by specifying commands; One or two times is OK. If frequent debugging is inconvenient, it is better to connect Hadoop directly through the IDE; The following summarizes three ways to connect Hadoop for analysis:
1. Use Hadoop's local mode to perform local data calculation in Eclipse 2. Eclipse connects to remote Hadoop, and uses the local mode of Hadoop to analyze the data in hdfs in Eclipse 3. Eclipse connects to remote Hadoop and submits local programs to remote Hadoop to analyze data in hdfs
Software version
Operating system: win7 64 bit
Eclipse:Indigo Service Release 2
Java:1.7
Hadoop:2.5.1
Linux:Centos7
1、 Use Hadoop's local mode to perform local data calculation in Eclipse
It is necessary to submit the written program to the remote server for data analysis before the local test is completed, which requires the use of the local mode provided by Hadoop
1. Unzip hadoop-2.5.1.tar.gz to local, such as D: software hadoop-2.5.1
2. Configure environment variable HADOOP_PATH=D: software hadoop-2.5.1
3. Download the hadoop2.6 plug-in package for windows 64 bit platform( hadoop.dll,winutils.exe )
In hadoop 2.5.1 source code hadoop-common-project\hadoop-common\src\main\winutils Next, there is a vs.net project. Compiling this project can get this pile of files. The output files include hadoop.dll and winutils.exe
Or directly download the compiled: http://pan.baidu.com/s/1nuP6CGT
Copy winutils.exe to the directory% HADOOP_PATH%/bin, and copy hadoop.dll to C:\Windows\System32 Contents
4. New Maven project
Pomx.xml file:
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.0.2</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.5.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.5.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.5.1</version> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.7</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> </dependencies>
Right click ->Maven ->Update Project
5. To display the output log of messages, provide log4j.properties The file is in the classpath path
6. Add a test class and directly %HADOOP_HOME%\share\hadoop\mapreduce\sources\hadoop-mapreduce-examples-2.5.1-sources.jar In WordCount.java Copy to project
Overall code structure:

7. Run As ->Run Configurations... Specify input and output
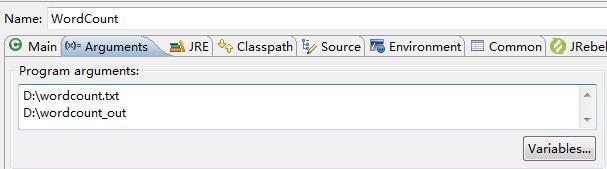
there wordcount.txt Just write a few words in it
8. Execution procedure
D: Analysis results are generated in wordcount_out

open part-r-00000 :
hello 3 world 3
2、 Eclipse connects to remote Hadoop, and uses the local mode of Hadoop to analyze the data in hdfs in Eclipse
1. Ensure that remote Hadoop starts normally
reference resources: Pseudo distributed mode of Hadoop
The following two methods require remote connection to Hadoop, and the Eclipse plug-in of Hadoop is required
2. Download hadoop-eclipse-plugin plug-in unit
Hadoop eclipse plugin is a hadoop plug-in specially used for eclipse. You can view the directory and file contents of hdfs directly in the IDE environment
Source code: https://github.com/winghc/hadoop2x-eclipse-plugin
Or download directly: http://pan.baidu.com/s/1bI149g
Copy hadoop-eclipse-plugin-2.5.1. jar download to the eclipse/plugins directory, and then restart eclipse
3. Configure the hadoop eclipse plugin
Window ->preferences ->Hadoop Map/Reduce specifies the hadoop root directory on win7
windows->show view->other
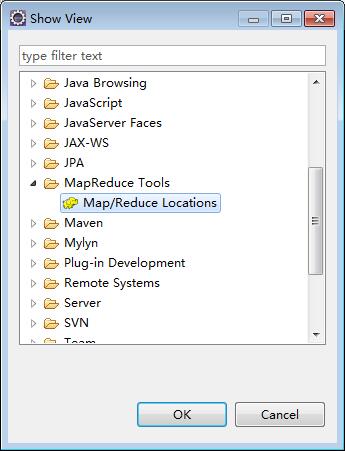
Open Map/Reduce Locations

Add a Location
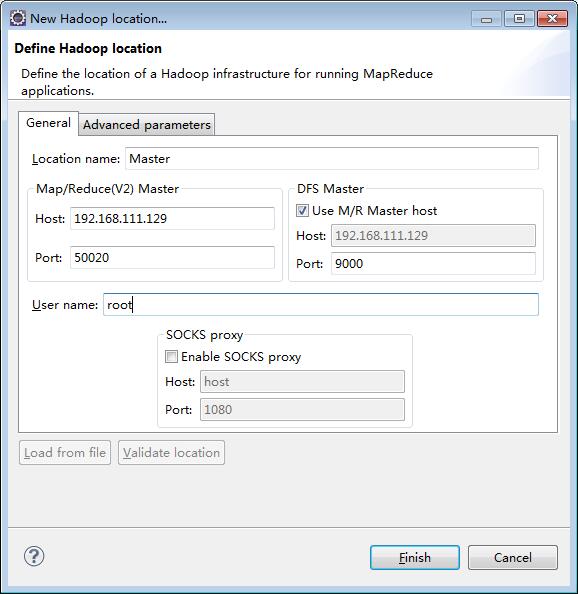
Location name : Give me a name
Map/Reduce(V2) Master Host : Here is the IP address corresponding to the hadoop master in the remote. The port corresponds to the port specified by the dfs.datanode.ipc.address attribute in hdfs-site.xml
DFS Master Port : corresponds to the port specified by fs.defaultFS in core-site.xml
User name : User name for running remote hadoop, such as root
4. If everything goes well, you can see the directory and files in hdfs in the Project Explorer panel

Question 1: If you cannot see the file in hdfs, try telnet 192.168.111.129 9000 locally first, and then try to modify the configuration if you cannot connect Core-site.xml (server side) :
<configuration> <property> <name>fs.defaultFS</name> <value> hdfs://192.168.111.129:9000 </value> </property> </configuration>
Question 2: Delete the file in hdfs in Eclipse, and the Insufficient permissions Questions for
stay Hdfs-site.xml (server side) Set dfs.permissions.enabled in:
<property> <name>dfs.permissions.enabled</name> <value>false</value> </property>
If it still fails, you can directly set the following settings on the server side for more convenient testing (definitely not allowed in the formal environment)
hadoop dfsadmin -safemode leave hadoop fs -chmod 777 /
5. Create Map/Reduce Project

After creation, directly %HADOOP_HOME%\share\hadoop\mapreduce\sources\hadoop-mapreduce-examples-2.5.1-sources.jar In WordCount.java Copy to the project;
Add the same log4j.properties Documents, convenient for error checking
6. Run As ->Run Configurations... Specify input and output
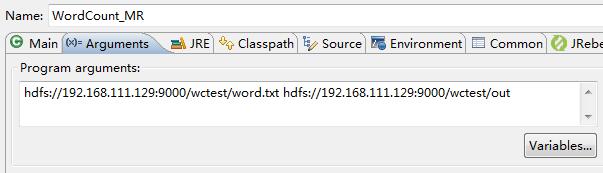
7. Execution procedure

Open part-r00000
hadoop 1 hello 3 java 1 world 1
Question 3: User=Administrator does not have permission
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=EXECUTE, inode="/tmp":hadoop:supergroup:drwx------ at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:234) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:187) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:150) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5433) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5415)
Because the user of the local computer is the Administrator, and hdfs can only be operated by related users, such as root, in two ways:
1. You can change the computer name to the root user name 2.hadoop fs -chown -R Administrator:Administrator /tmp
3、 Eclipse connects to remote Hadoop and submits local programs to remote Hadoop to analyze data in hdfs
The configuration in this way is basically the same as that in the second way, except that we need to add a hadoop-remote.xml file under the classpath path
<?xml version="1.0" encoding="UTF-8"? > <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.111.129</value> </property> <property> <name>mapreduce.app-submission.cross-platform</name> <value>true</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.111.129:10020</value> </property> </configuration>
At the same time, set Configuration in the code
conf.addResource("hadoop-remote.xml");
Note 1: The configured mapreduce. jobhistory. address needs to start the history server on the server side
mr-jobhistory-daemon.sh start historyserver mr-jobhistory-daemon.sh stop historyserver
Note 2: Mapreduce. app-submission.cross platform. By default, map reduce does not enable cross platform (win to linux) task submission. If it is not set to true, the following error will occur
ExitCodeException exitCode=1: /bin/bash: line 0: fg: no job control at org.apache.hadoop.util.Shell.runCommand(Shell.java:538) at org.apache.hadoop.util.Shell.run(Shell.java:455) at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702) at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:195) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:300) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:81) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745)
Note 3: yarn.resourcemanager.hostname, If the specific IP address is not set, the following problems will occur:
Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
In this way, the local MapReduce program can be sent to the remote Hadoop for execution, and the test results are the same as those of the second method
summary
The three methods summarized above generally need to be used, and have a certain order:
1. First use the test data to execute on the local Hadoop. If there is no problem, go to the second step
2. Use the replica of official data to execute locally. If there is no problem, go to the third step
3. Submit the program to remote Hadoop for execution




















