The visual language model can be learned from images and texts at the same time, so it can be used for multiple tasks such as visual question and answer, image description, etc. In this article, we will take you at a glance in the field of visual language models: give an overview, understand its working principle, figure out how to find the "model" of the "life", how to reason about it, and how to use the latest version of trl It's easy to fine tune.
What is a visual language model?
Visual language model is a multimodal model that can be learned from image and text at the same time. It belongs to the generation model, and the input is image and text, and the output is text. The large visual language model has good zero sample ability, good generalization ability, and can handle many types of images including documents, web pages, etc. It has a wide range of applications, including image based chat, image recognition based on instructions, visual question and answer, document understanding, image description, etc. Some visual language models can also capture spatial information in images. When prompted to detect or segment specific targets, these models can output bounding boxes or segmentation masks. Some models can also locate different targets or answer questions related to their relative or absolute positions. The existing large visual language models use many methods in training data, image coding methods, etc., so their capabilities are also very different.
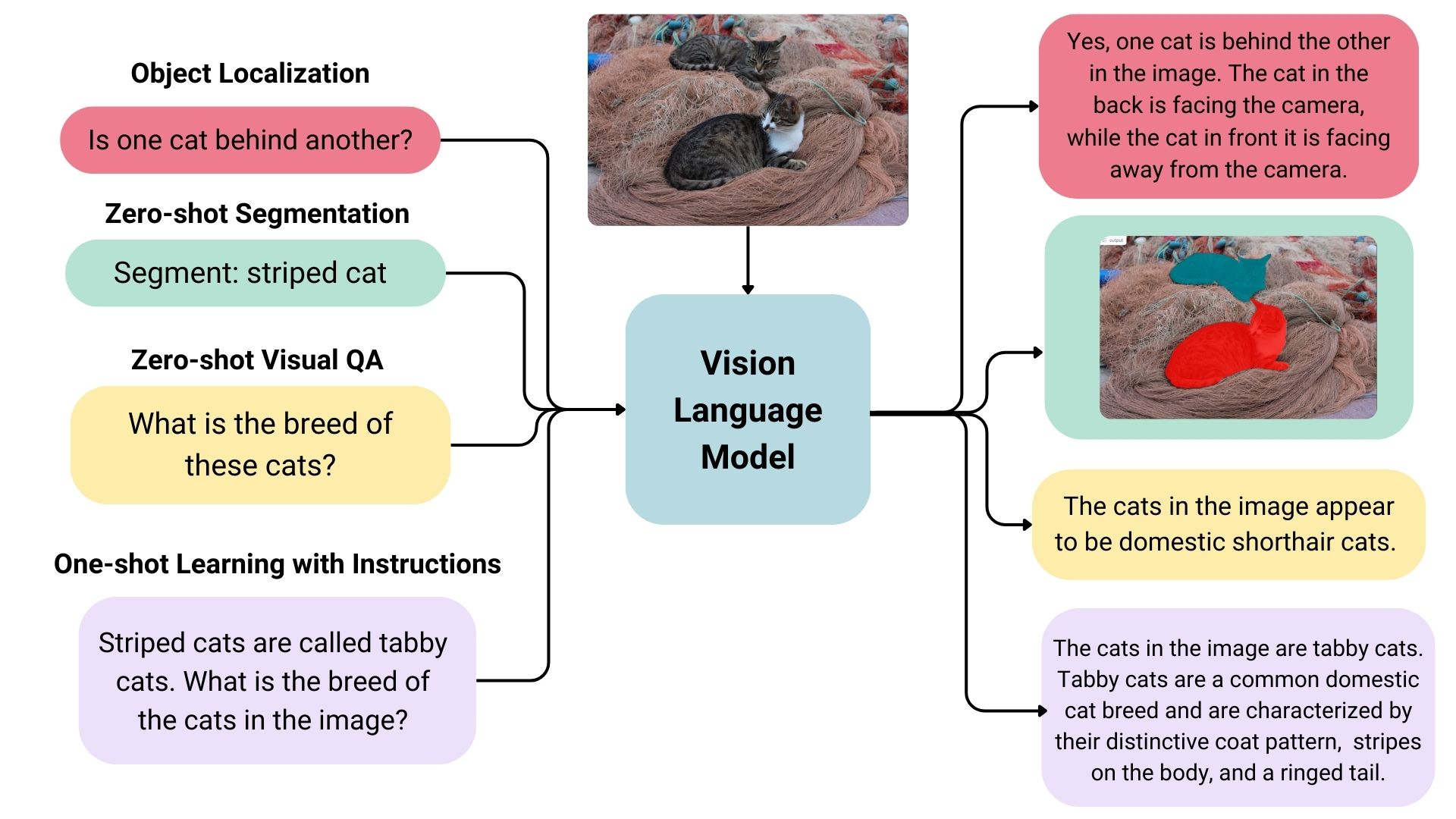
Overview of Open Source Visual Language Models
There are many open visual language models on the Hugging Face Hub, and the following table lists some of them.
- There are both basic models and chat fine-tuning models that can be used in conversation scenarios.
- Some of these models have the function of "grounding", so they can reduce model illusion.
- Unless otherwise specified, the training language of all models is English.
Looking for a suitable visual language model
There are many ways to help you choose the best model for yourself.
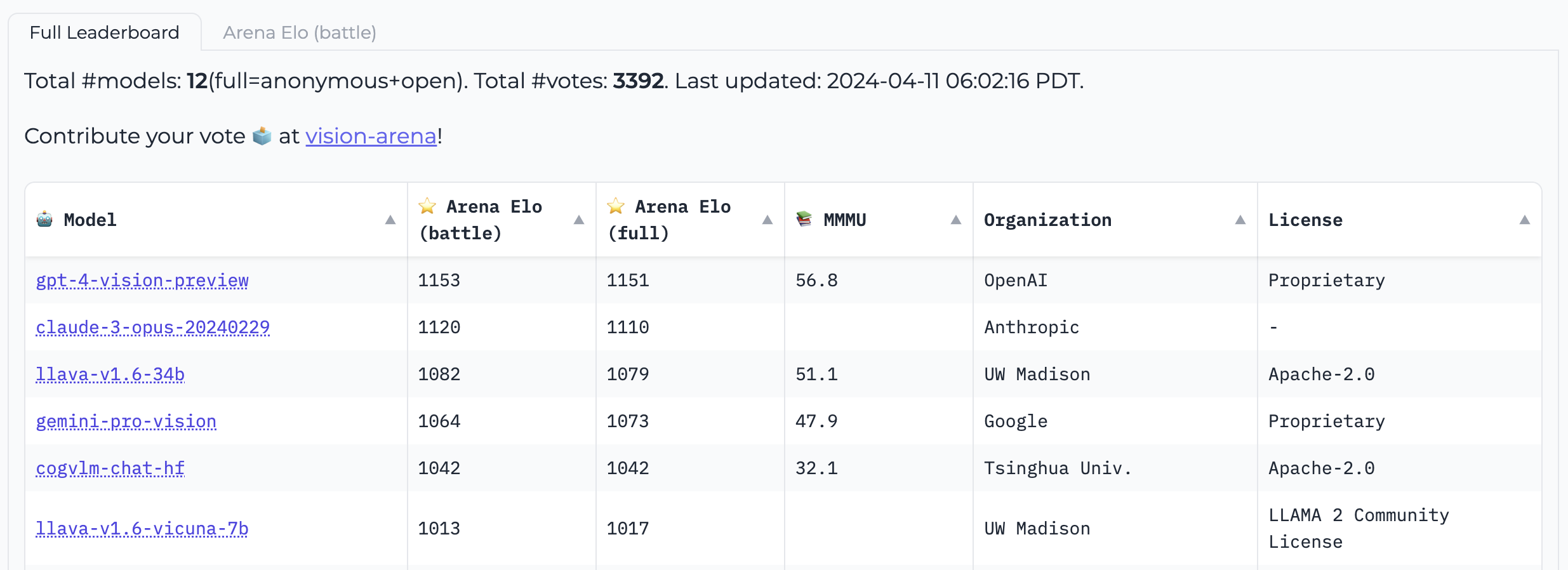
Vision Arena It is a leaderboard that conducts anonymous voting based on model output, and its ranking will be refreshed continuously. In this arena, when users input images and prompts, two anonymous different models will generate outputs for them, and then users can choose an output based on their preferences. The rankings generated in this way are entirely based on human preferences.
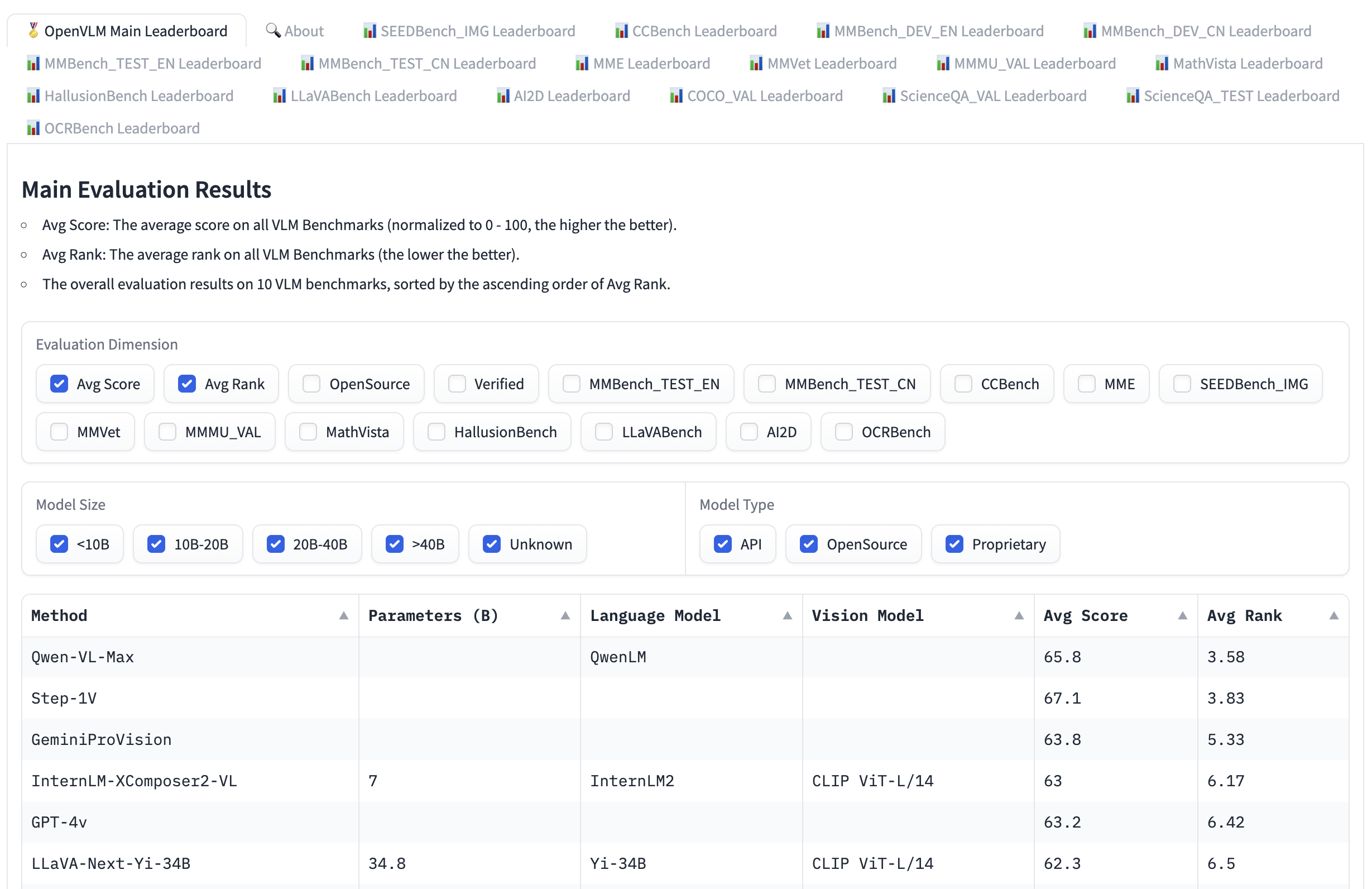
Open VLM Ranking Another option is provided. Various visual language models are ranked according to the average score of all indicators. You can also filter models according to model size, private or open source licenses, and rank them according to the indicators you choose.
VLMEvalKit It is a tool kit used to run benchmark tests on the visual language model. The open VLM ranking is based on this tool kit.
Another evaluation suite is LMMS-Eval , which provides a standard command line interface. You can use the dataset hosted on the Hugging Face Hub to evaluate the selected Hugging Face model, as shown below:
accelerate launch --num_processes=8 -m lmms_eval --model llava --model_args pretrained="liuhaotian/llava-v1.5-7b" --tasks mme, mmbench_en --batch_size 1 --log_samples --log_samples_suffix llava_v1.5_mme_mmbenchen --output_path ./logs/
Both the visual arena and the open VLM leaderboard are limited to the models submitted to them, and new models can only be added after being updated. If you want to find other models, you can find them in image-text-to-text Browse the Model 。
In the ranking list, you will see different benchmarks used to evaluate visual language models. Let's select some of them to introduce.
MMMU
A Massive Multi discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI (MMMU) It is the most comprehensive benchmark for evaluating visual language models. It contains 11.5K multimodal problems, which require university level discipline knowledge and interdisciplinary reasoning ability (such as art and engineering).
MMBench
MMBench It consists of 3000 single topics covering more than 20 different skills, including OCR, target positioning, etc. The paper also introduces a kind of CircularEval Each round of the evaluation strategy will make different combinations and shuffles of the options of the questions, and expect the model to give correct answers each round.
In addition, there are other more targeted benchmarks for different application fields, such as MathVista (visual mathematical reasoning), AI2D (chart understanding), ScienceQA (scientific question and answer) and OCRBench (document understanding).
Technical details
There are many ways to pre train the visual language model. The main technique is to unify the image and text representation to input them to the text decoder for text generation. The most common and best performing models are usually stacked by image encoders, embedded shadow models (usually a dense neural network) used to align images and text representations, and text decoders in order. As for the training part, different models adopt different methods.
For example, LLaVA is composed of CLIP image encoder, multi-mode shadow casting model and Vicuna text decoder. The author inputs a dataset containing images and descriptive text into GPT-4 to describe problems related to text and image generation. The author freezes the image encoder and text decoder, and trains the multi-mode projection model only by feeding images and problems to the model and comparing the model output with the description text, so as to achieve the purpose of aligning image and text features. After pre training the shadow model, the author keeps the image encoder in the frozen state, unfreezes the text decoder, and then continues to train the decoder and shadow model. This method of pre training and fine adjustment is the most common way to train visual language models.
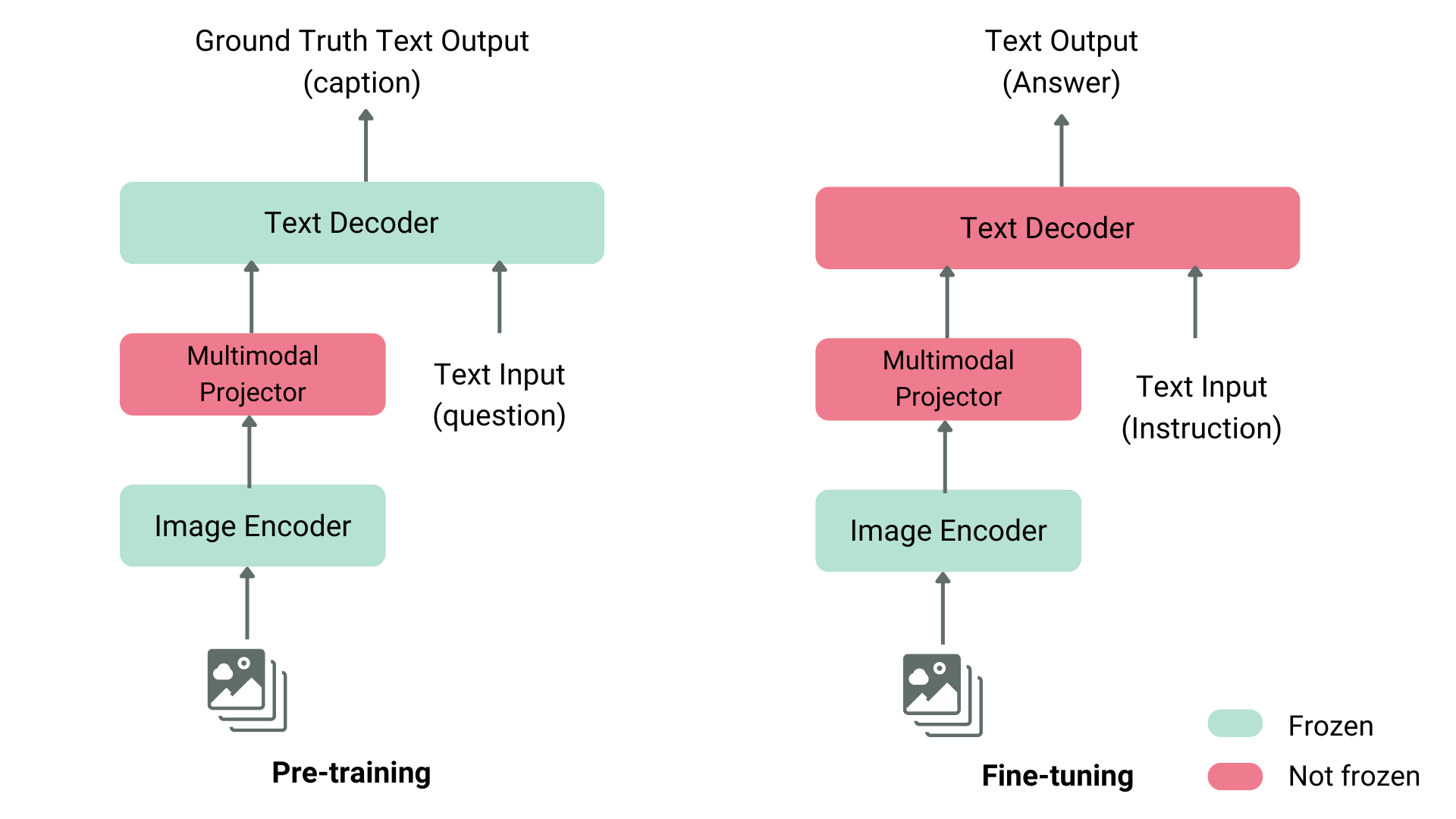
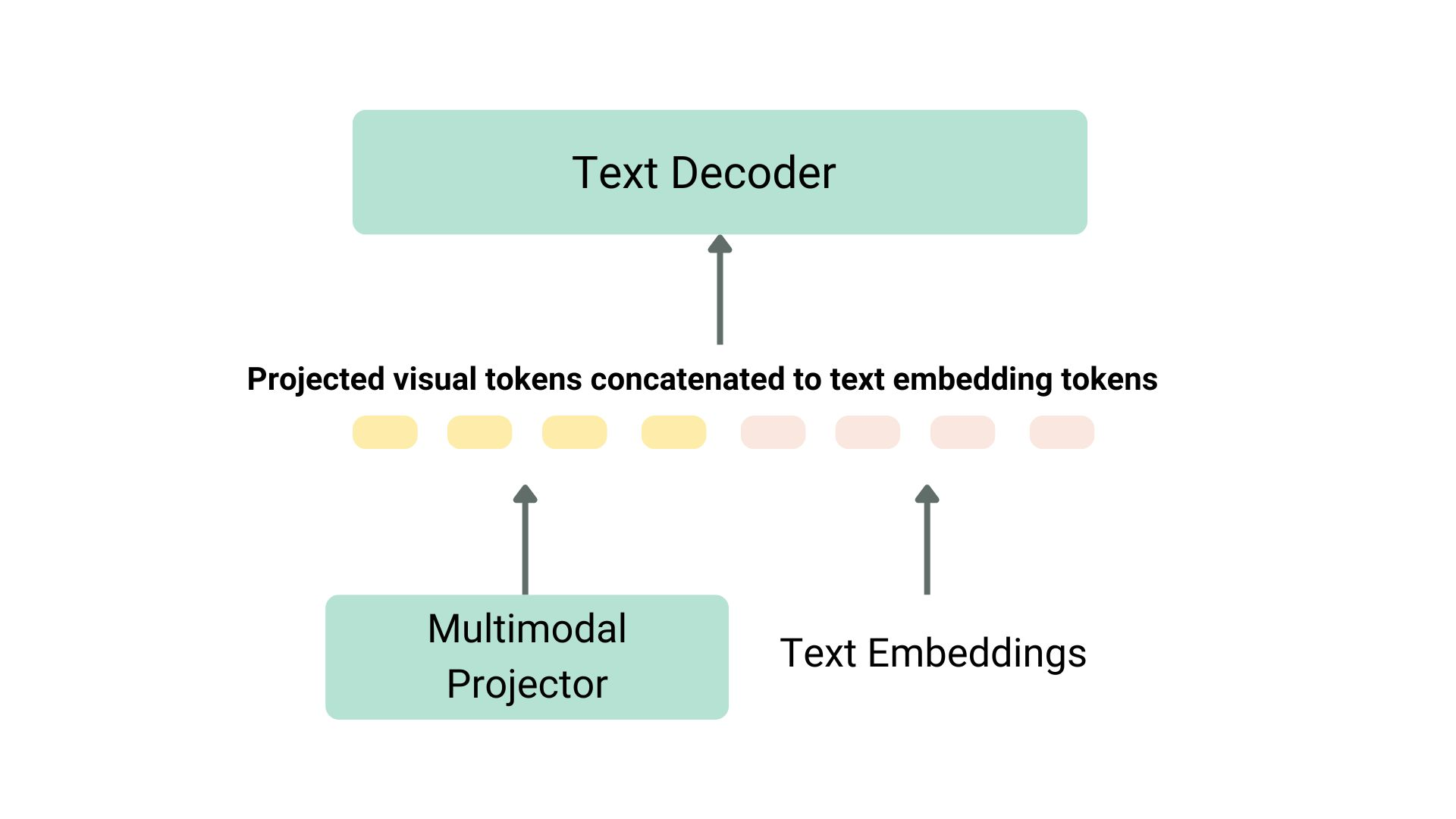
Taking another example of KOSMOS-2, the author chose the method of end-to-end complete training of the model. Compared with the LLaVA type pre training method, this method is computationally expensive. After the pre training is completed, the author also uses pure language instructions to fine tune the model to align. In another way, Fuyu-8B does not even have an image encoder. It directly feeds the image block to the projection model, and then directly concatenates its output and the text sequence to the autoregressive decoder.
Most of the time, we don't need to pre train the visual language model, just use the existing model for reasoning, or fine tune it according to our own scene. Next, we will introduce how to transformers And how to use these models SFTTrainer Fine tune them.
Using visual language model in transformers
You can use LlavaNext The model infers Llava, as shown below.
First, we initialize the model and data processor.
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration import torch device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf") model = LlavaNextForConditionalGeneration.from_pretrained( "llava-hf/llava-v1.6-mistral-7b-hf", torch_dtype=torch.float16, low_cpu_mem_usage=True ) model.to(device)
Now, send the image and text prompt to the data processor, and then send the processed input to generate method. Please note that each model has its own prompt template. Please select the correct template according to the model to avoid performance degradation.
from PIL import Image import requests url = " https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true " image = Image.open(requests.get(url, stream=True).raw) prompt = "[INST] <img src="">\nWhat is shown in this image? [/INST]" inputs = processor(prompt, image, return_tensors="pt").to(device) output = model.generate(**inputs, max_new_tokens=100)
call decode Decode the output lexical elements.
print(processor.decode(output[0], skip_special_tokens=True))
Fine tune the visual language model using TRL
We are pleased to announce that, as an experimental function, TRL Of SFTTrainer Visual language model is now supported! Here, we give an example to show how to llava-instruct SFT is performed on the dataset, which contains 260k image dialog pairs.
llava-instruct The dataset organizes the interaction between the user and the assistant into a message sequence format, and each message sequence is paired with the image that the user question refers to.
To use the VLM training function, you must use pip install -U trl Install the latest version of TRL. You can here Find the complete sample script.
from trl.commands.cli_utils import SftScriptArguments, TrlParser parser = TrlParser((SftScriptArguments, TrainingArguments)) args, training_args = parser.parse_args_and_config()
Initialize the chat template for command tuning.
LLAVA_CHAT_TEMPLATE = """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. {% for message in messages %}{% if message['role'] == 'user' %}USER: {% else %}ASSISTANT: {% endif %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<img src="">{% endif %}{% endfor %} {% if message['role'] == 'user' %} {% else %}{{eos_token}}{% endif %}{% endfor %}"""
Now initialize the model and the word breaker.
from transformers import AutoTokenizer, AutoProcessor, TrainingArguments, LlavaForConditionalGeneration import torch model_id = "llava-hf/llava-1.5-7b-hf" tokenizer = AutoTokenizer.from_pretrained(model_id) tokenizer.chat_template = LLAVA_CHAT_TEMPLATE processor = AutoProcessor.from_pretrained(model_id) processor.tokenizer = tokenizer model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16)
Build a data organizer to combine text and image pairs.
class LLavaDataCollator: def __init__(self, processor): self.processor = processor def __call__(self, examples): texts = [] images = [] for example in examples: messages = example["messages"] text = self.processor.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=False ) texts.append(text) images.append(example["images"][0]) batch = self.processor(texts, images, return_tensors="pt", padding=True) labels = batch["input_ids"].clone() if self.processor.tokenizer.pad_token_id is not None: labels[labels == self.processor.tokenizer.pad_token_id] = -100 batch["labels"] = labels return batch data_collator = LLavaDataCollator(processor)
Load the dataset.
from datasets import load_dataset raw_datasets = load_dataset("HuggingFaceH4/llava-instruct-mix-vsft") train_dataset = raw_datasets["train"] eval_dataset = raw_datasets["test"]
initialization SFTTrainer , pass in the model, data subset, PEFT configuration and data organizer, and then call train() 。 To push the final checkpoint to the Hub, call push_to_hub() 。
from trl import SFTTrainer trainer = SFTTrainer( model=model, args=training_args, train_dataset=train_dataset, eval_dataset=eval_dataset, dataset_text_field="text", # need a dummy field tokenizer=tokenizer, data_collator=data_collator, dataset_kwargs={"skip_prepare_dataset": True}, ) trainer.train()
Save the model and push it to the Hugging Face Hub.
trainer.save_model(training_args.output_dir) trainer.push_to_hub()
You can here Find the trained model. You can also play with our model through the interview on the following page ⬇️。
thank
We thank Pedro Cuenca, Lewis Tunstall, Kashif Rasul and Omar Sanseviero for their comments and suggestions on this article.
Original English: https://hf.co/blog/vlms Original author: Merve Noyan, Edward Beeching Translator: Matrix Yao, Intel deep learning engineer, working in the application of transformer family model in various modal data and training reasoning of large-scale models.


















































