E-MapReduce Quick Start
prerequisite
Register an AliCloud account and complete real name authentication. Please refer to Account registration (PC side) 。 explain According to Alibaba Cloud ECS rules, when purchasing pay as you go instances, you need to ensure that the available balance (including cash, vouchers, coupons, etc.) in your AliCloud account is not less than 100 yuan. Complete granting the default EMR and ECS role permissions to the E-MapReduce service account. For details, see Alibaba Cloud account role authorization 。
Operation process
On the EMR console, quickly create a DataLake cluster. Step 2: Create and execute jobs After the cluster is created successfully, you can create and execute Spark type jobs. Step 3: View the job running record After submitting the job, you can view the job running record through the YARN UI. (Optional) Step 4: Release the cluster If the cluster is no longer used, you can release the cluster to save costs.
Step 1: Create a cluster
Enter the Create Cluster page. Sign in EMR on ECS console 。 In the top menu bar, select the region and resource group according to the actual situation. Region: The cluster created will be in the corresponding region, and once created, it cannot be modified. Resource Group: all resources of the account are displayed by default.
Click above Create cluster 。
On the Create Cluster page, complete the cluster related configuration. Configure Area Configuration Item Example describe software configuration region East China 1 (Hangzhou) The physical location of the ECS instance of the cluster node. important After the cluster is created, the region cannot be changed. Please select carefully. Business Scenario Data Lake Select a suitable business scenario. When you create a cluster, Alibaba Cloud EMR will automatically configure default components, services and resources for you to simplify cluster configuration and provide a cluster environment that meets the requirements of specific business scenarios. product version EMR-5.14.0 Current latest software version. High availability of services Do not open It is not enabled by default. open High availability of services After switching, EMR will distribute the master nodes on different underlying hardware to reduce the risk of failure. Option Service HADOOP-COMMON, OSS-HDFS, YARN, Hive, Spark3, Tez, Knox, and OpenLDAP. Select components according to your actual needs. The selected components will start the relevant service processes by default. explain In addition to the cluster default service, Knox and OpenLDAP services should also be selected. Allow collecting service running logs open It supports one click to enable or disable log collection for all services. On by default, your service running logs will be collected. These logs are only used for cluster diagnostics. After the cluster is created, you can Basic information Page, modifying Service running log collection status 。 important When log collection is turned off, the health check and technical support of EMR will be limited, but other functions can still be used normally. Please refer to How to stop collecting service logs? 。 metadata DLF unified metadata It indicates that metadata is stored in the data lake construction DLF. The system will select the default DLF Data Directory If you want to use different data directories for different clusters, click Create Data Directory 。 explain When this mode is selected, Alibaba Cloud data lake construction service needs to be activated. Cluster storage root path 1366993922****** When you select the OSS-HDFS service in the optional service area, you need to configure this parameter. If you select the HDFS service, you do not need to configure this parameter. explain Before choosing to use the OSS HDFS service, make sure that the region you choose supports the service. Otherwise, you can try to change the region or use HDFS services instead of OSS HDFS services. For the region information currently supported by the OSS HDFS service, see Activate and authorize access to the OSS HDFS service 。 EMR-5.12.1 and later versions, and EMR-3.46.1 and later versions of DataLake, DataFlow, DataServing, and Custom clusters support the selection of OSS HDFS services.
hardware configuration Payment type Pay as you go It is recommended to use Pay as you go After the test is normal, you can release the cluster and create a new one Monthly guarantee The production cluster of is officially used. Zone Zone I After the cluster is created, the zone cannot be changed directly. Please choose carefully. proprietary network vpc_Hangzhou/vpc-bp1f4epmkvncimpgs**** Select the VPC in the corresponding region. If not, click Create VPC Go to New. After creating the VPC, click Refresh , you can select the newly created VPC. Switch vsw_i/vsw-bp1e2f5fhaplp0g6p**** Select the switch in the zone under the corresponding VPC. If there is no switch available in this zone, you need to create a new one. Default security group sg_seurity/sg-bp1ddw7sm2risw**** important It is prohibited to use enterprise security groups created on ECS. If there is already a security group in use, you can directly choose to use it. You can also create a new security group. Node group Open the Attach the public network Switch, and use the default values for the rest. You can configure Master node group, Core node group or Task node group information according to business demands. For details, see Model selection and configuration description 。 Basic configuration Cluster name Emr-DataLake The cluster name is limited to 1~64 characters in length and can only use Chinese, letters, numbers, dashes (-) and underscores (_). identity certificate password. It is used to remotely log in to the master node of the cluster. Login Password and Confirm Password Custom password. Please record the configuration. You need to enter the password when logging into the cluster. Check Service Agreement , click Confirm Order 。 On the EMR on ECS page, when the cluster state Show as In operation When the cluster is created successfully. For more cluster parameter information, see Create cluster 。
Step 2: Create and execute jobs
Connect the cluster through SSH. For details, see Log in to the cluster 。 Execute the following command on the command line to submit and run the job. This article takes Spark 3.1.1 as an example, and the command examples are as follows. spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 512m --num-executors 1 --executor-memory 1g --executor-cores 2 /opt/apps/SPARK3/spark-current/examples/jars/spark-examples_2.12-3.1.1.jar 10 explain spark-examples_2.12-3.1.1.jar For the corresponding JAR package name in your cluster, you can Log in to the cluster , on /opt/apps/SPARK3/spark-current/examples/jars Path.
Step 3: View the job running record
Open port 8443. For details, see Manage Security Groups 。 New user, see Manage Users 。 When using Knox account to access YARN UI page, the user name and password of Knox account are required. stay EMR on ECS Page, click Cluster service 。 single click Access links and ports Tab. single click YARN UI Public network link of the bank. Use the user identity information in user management for login authentication to enter the YARN UI page. stay All Applications Page, click the ID of the target job to view the details of the job run. 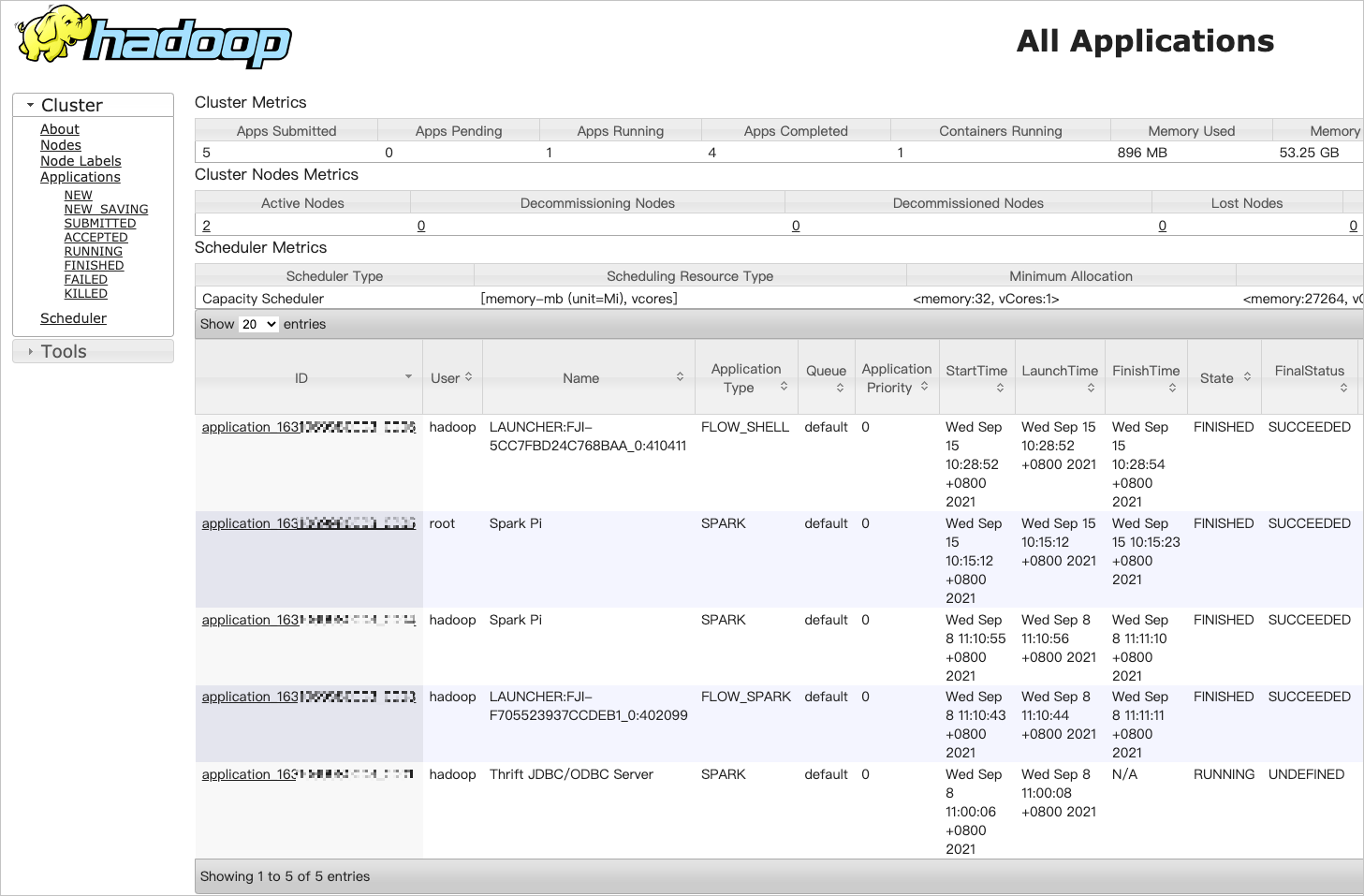
(Optional) Step 4: Release the cluster
Force termination of all jobs on the cluster. Terminate and release all ECS instances.
The pay as you go cluster can be released at any time, and the cluster can only be released after the expiration of the monthly package. Before releasing the cluster, ensure that the cluster status is initializing, running, or idle.
stay EMR on ECS Page, select the 
> release 。 You can also click the cluster name of the target cluster, and then click Basic information Page, select the 。 In the pop-up dialog box, click determine 。
Related Documents
Learn how to log in to the cluster: Log in to the cluster 。 Learn how to view the installation path of common files: Common file path 。 Learn about deployment set related operations: Open deployment set 。 Learn about label related operations: Set Label 。 Understand the operations related to resource groups: Use resource groups 。 Learn about security group related operations: Manage Security Groups 。 Learn how to use APIs to manage clusters and services, etc.: API overview 。
common problem
-
Introduction to this page (1)