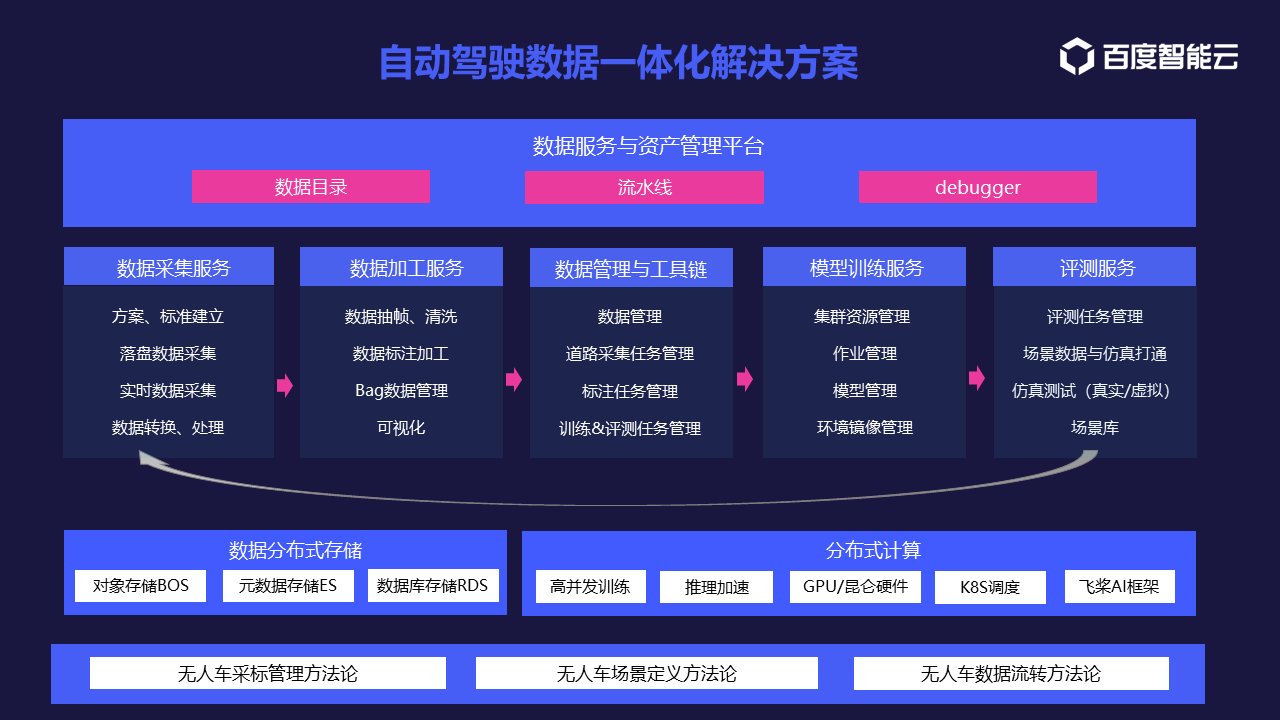
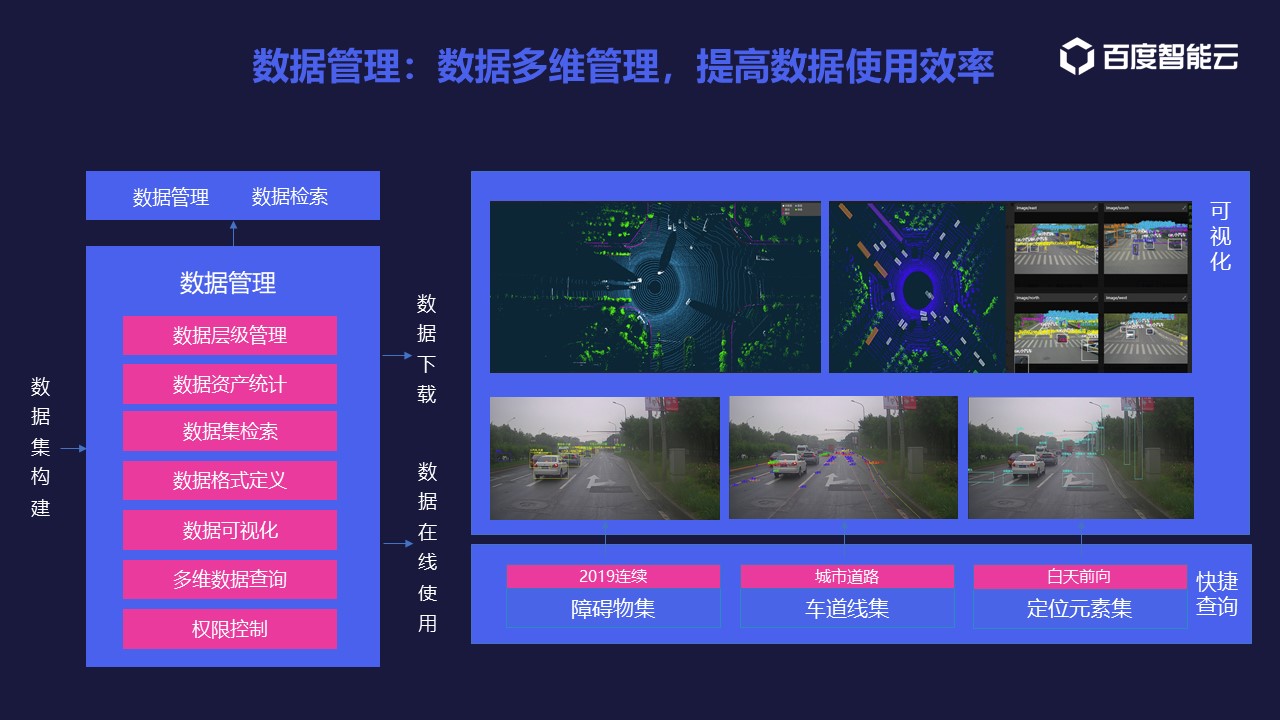
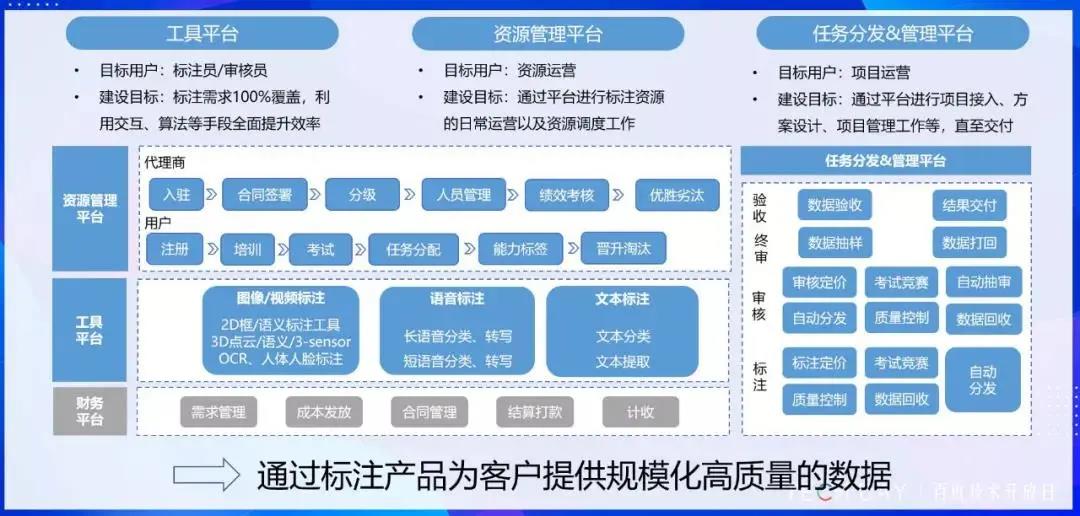
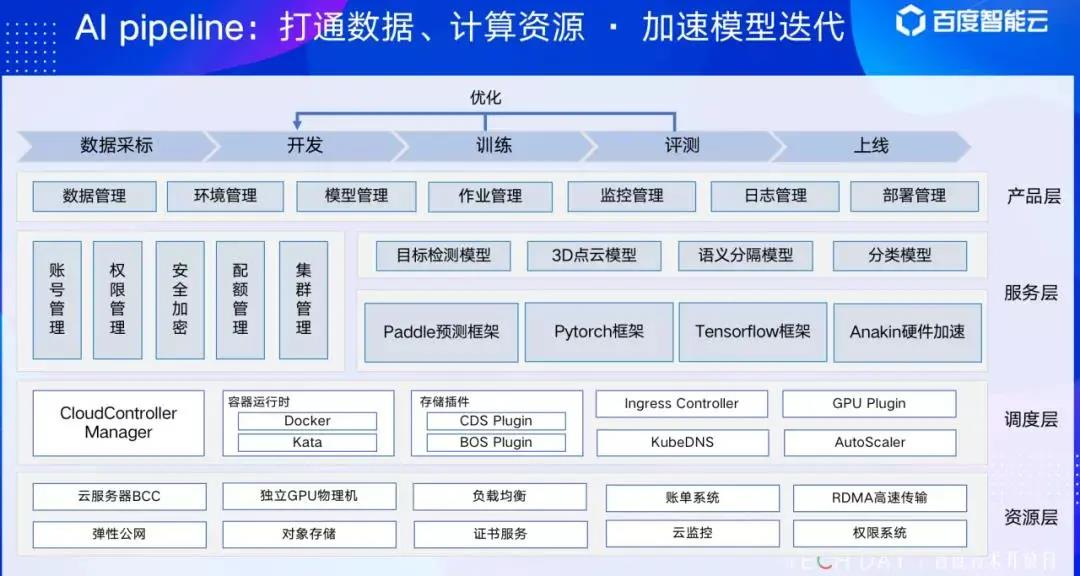
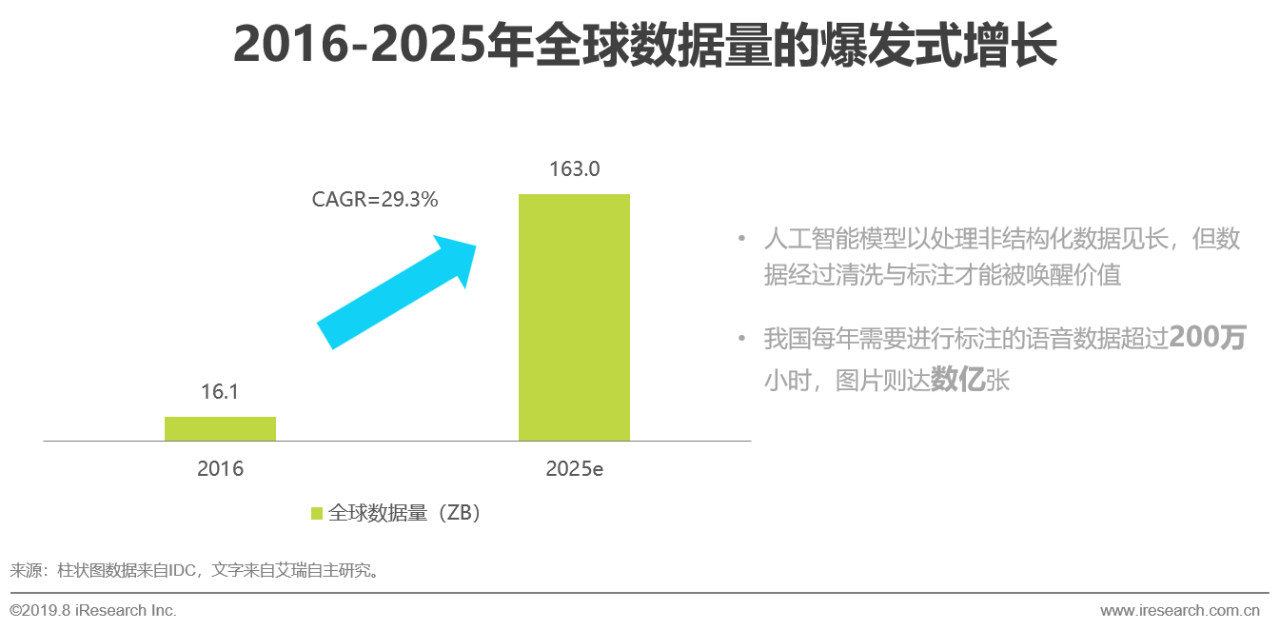
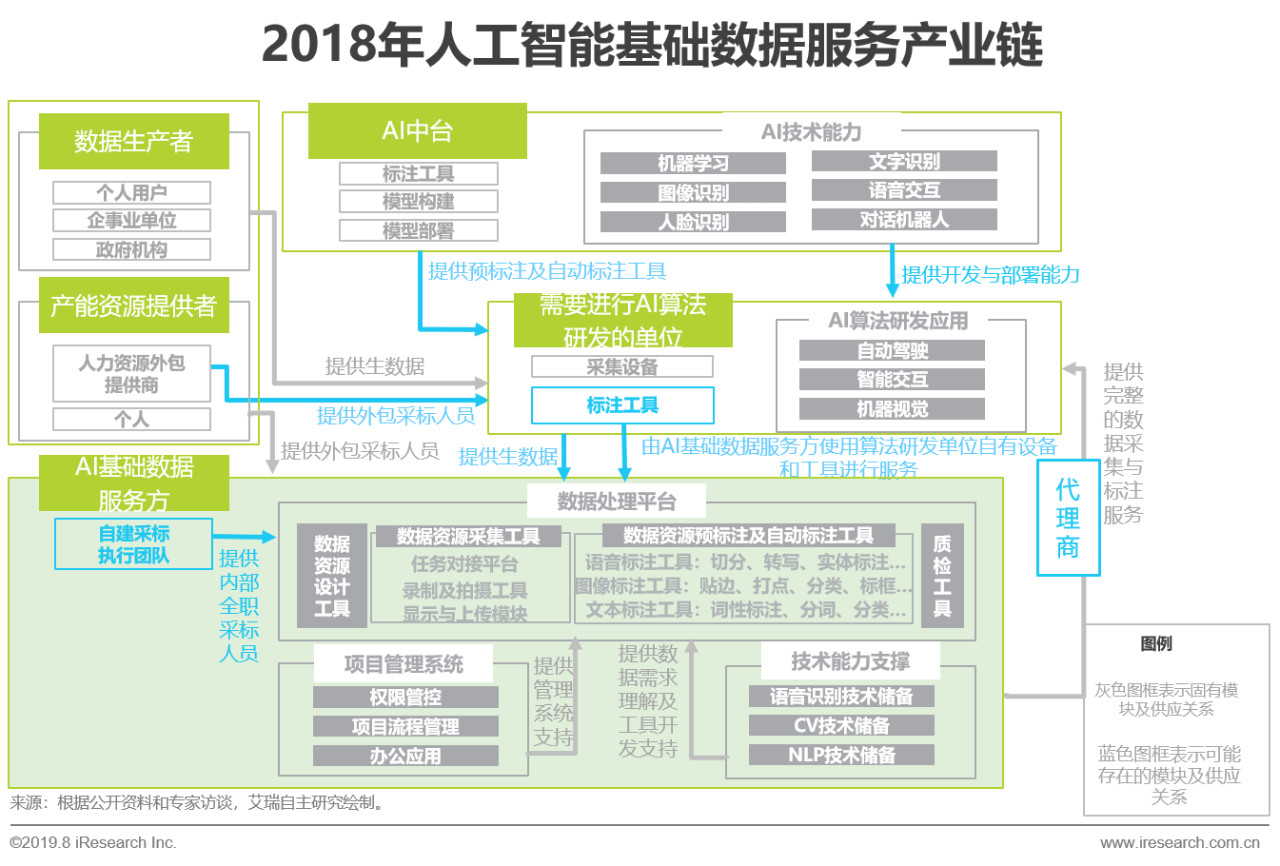
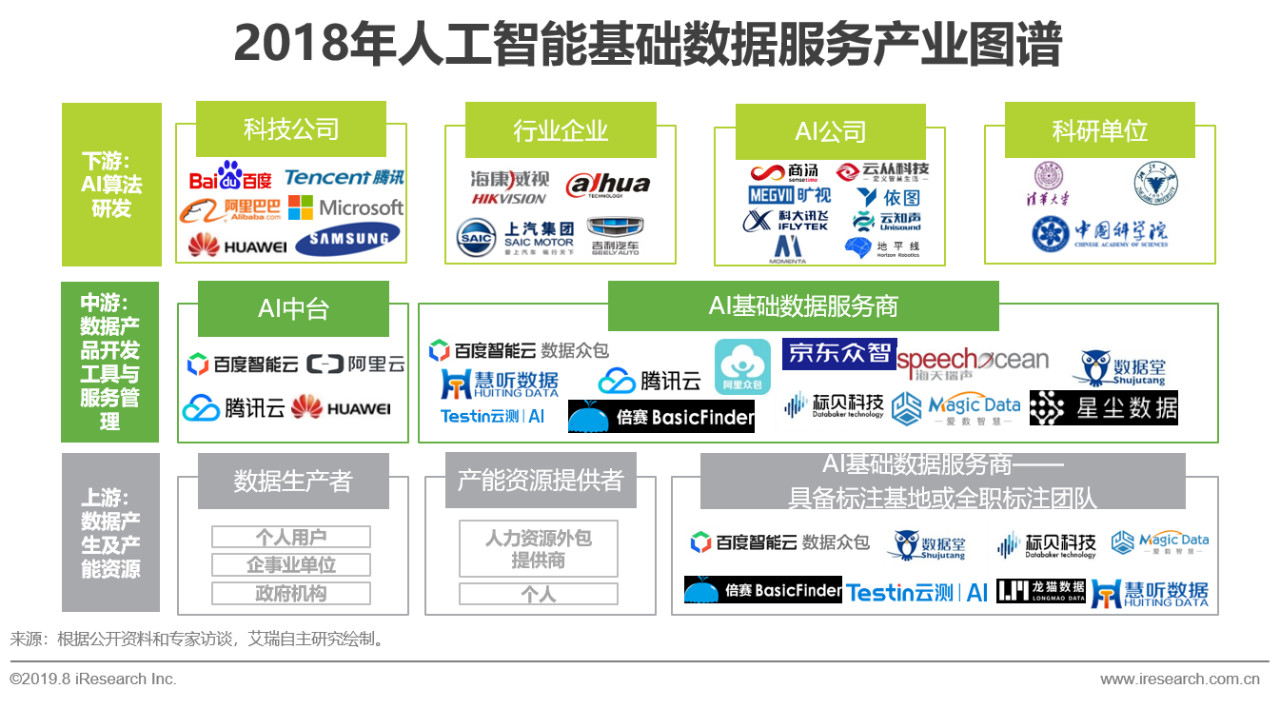
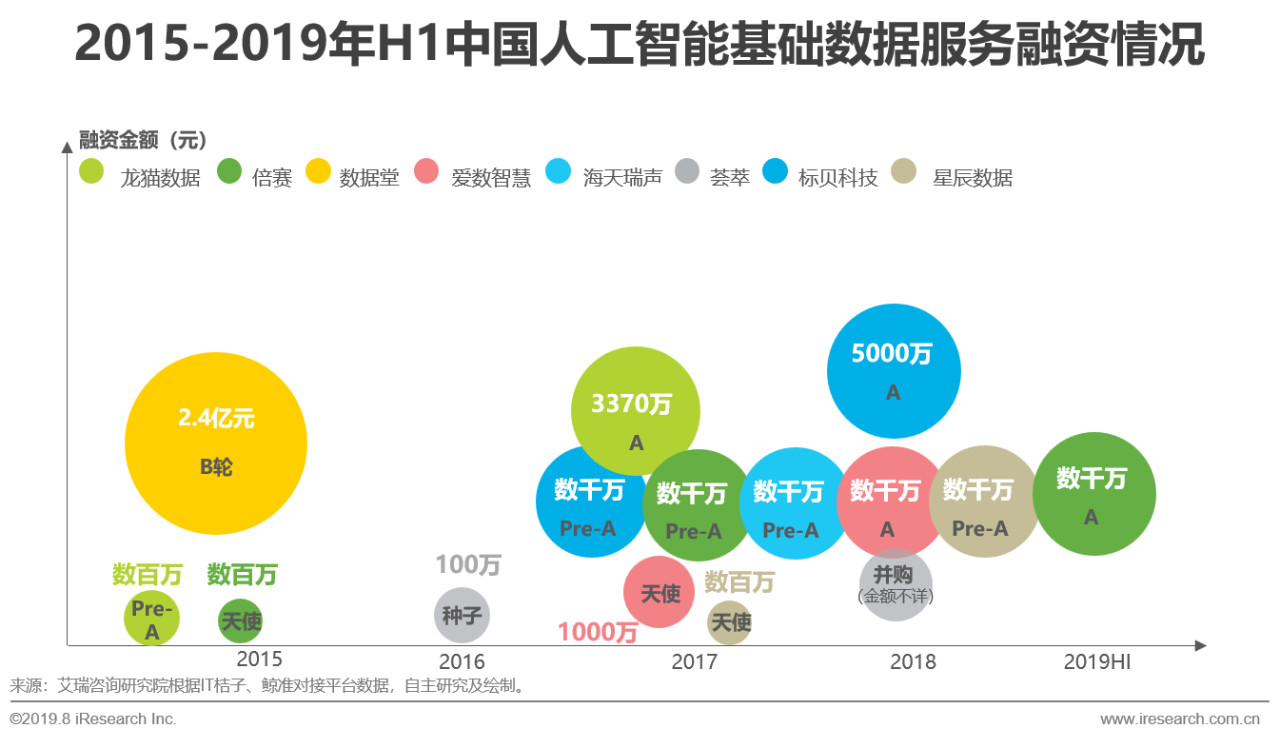
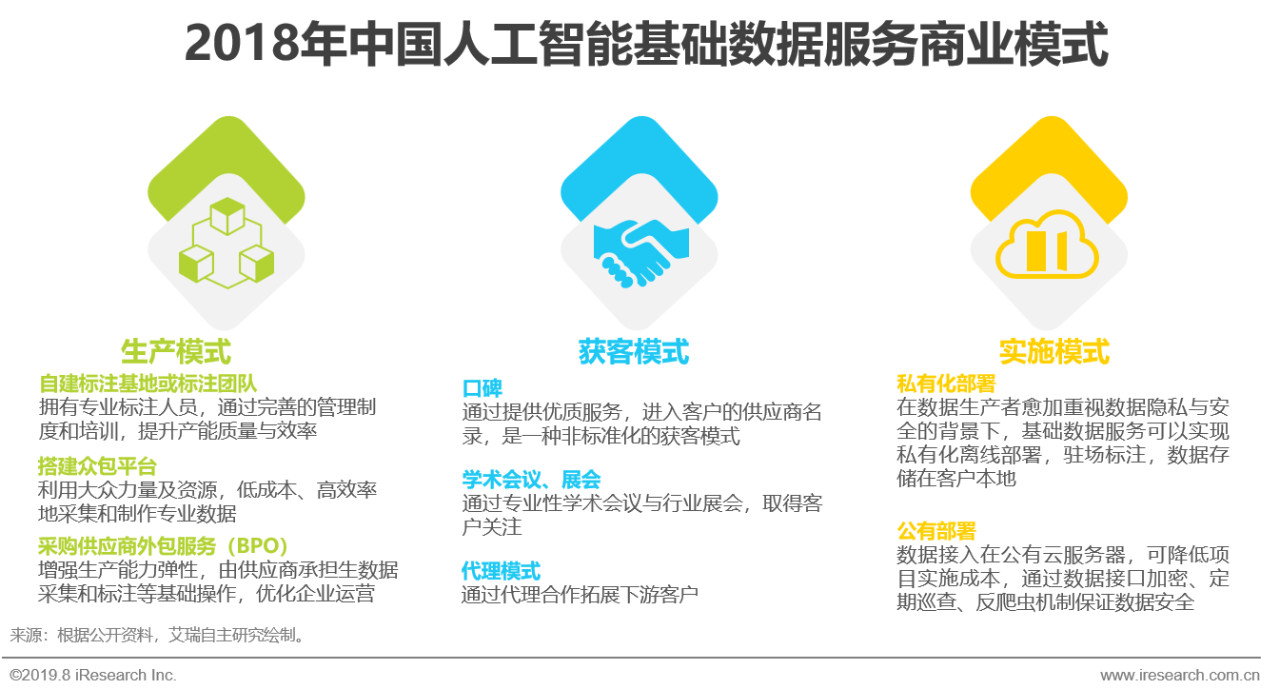
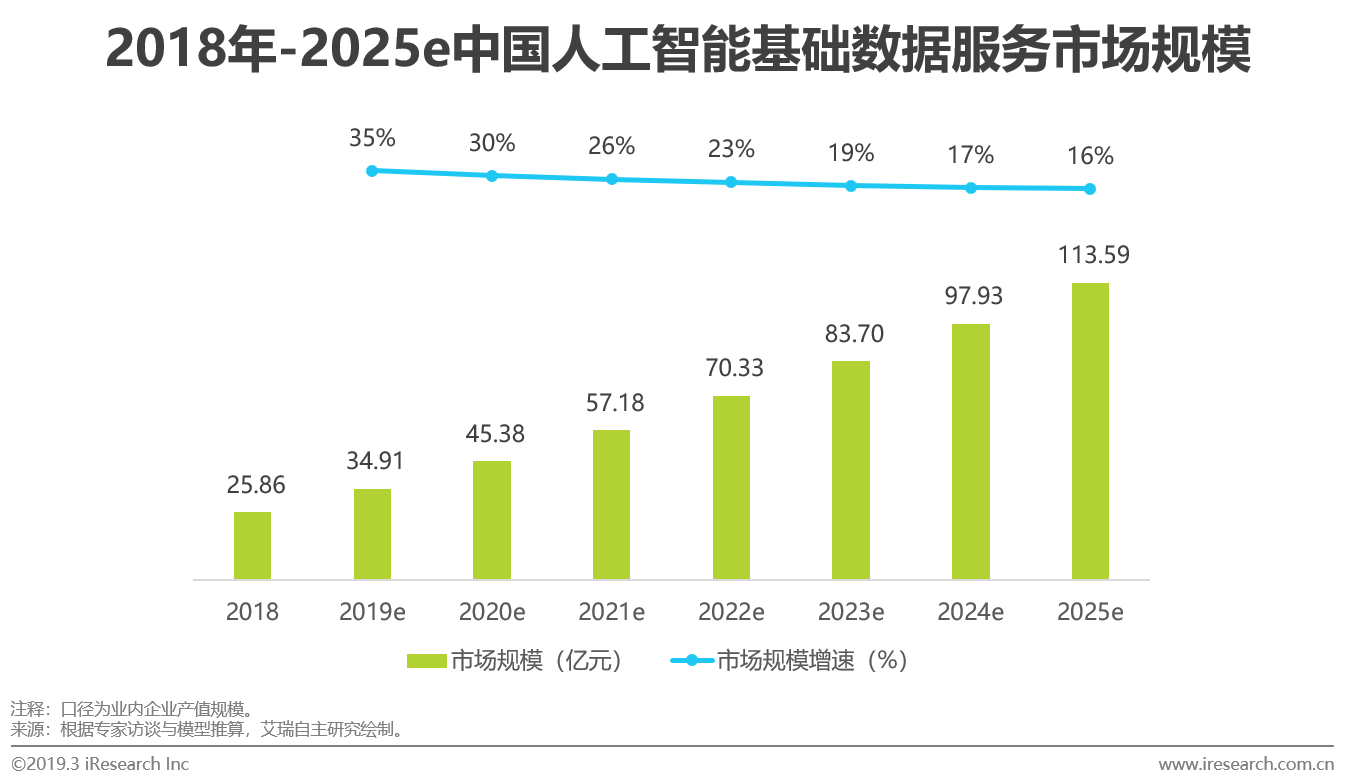
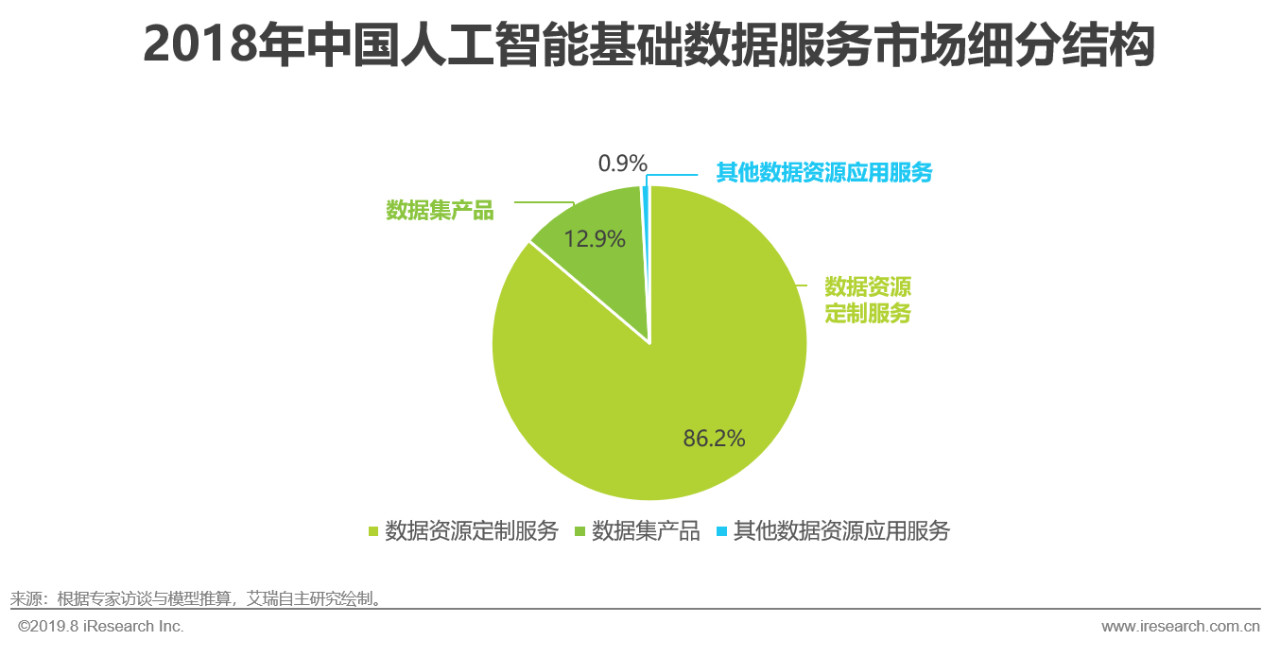
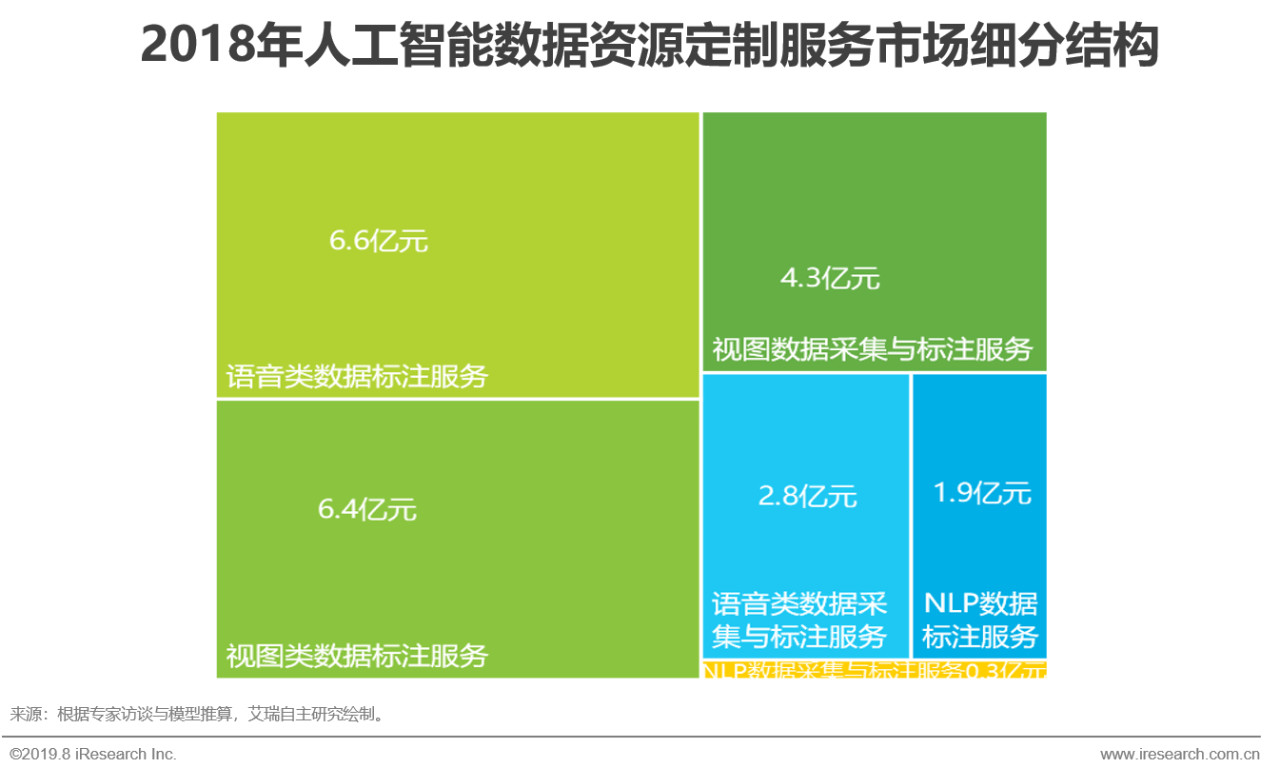
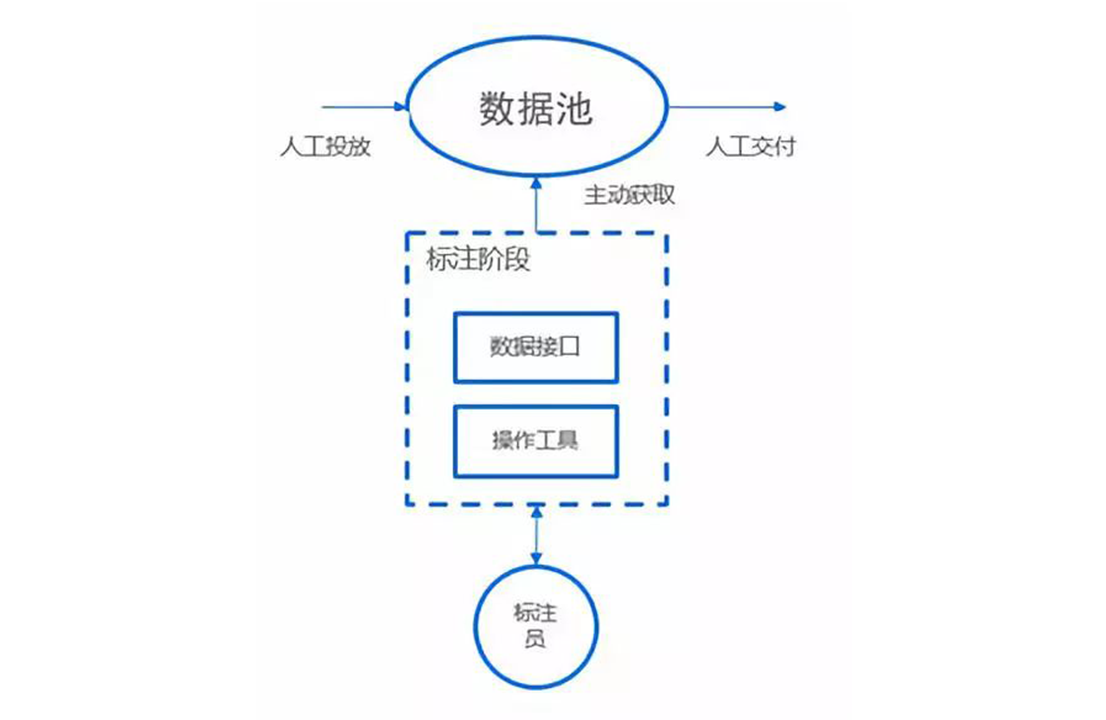
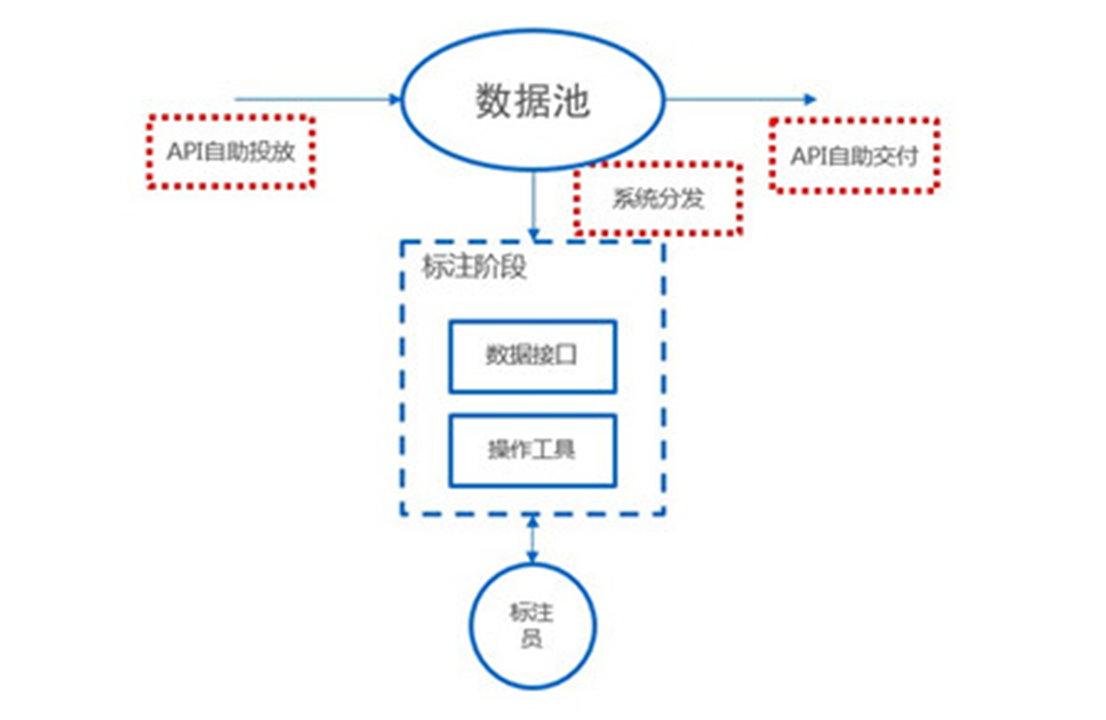
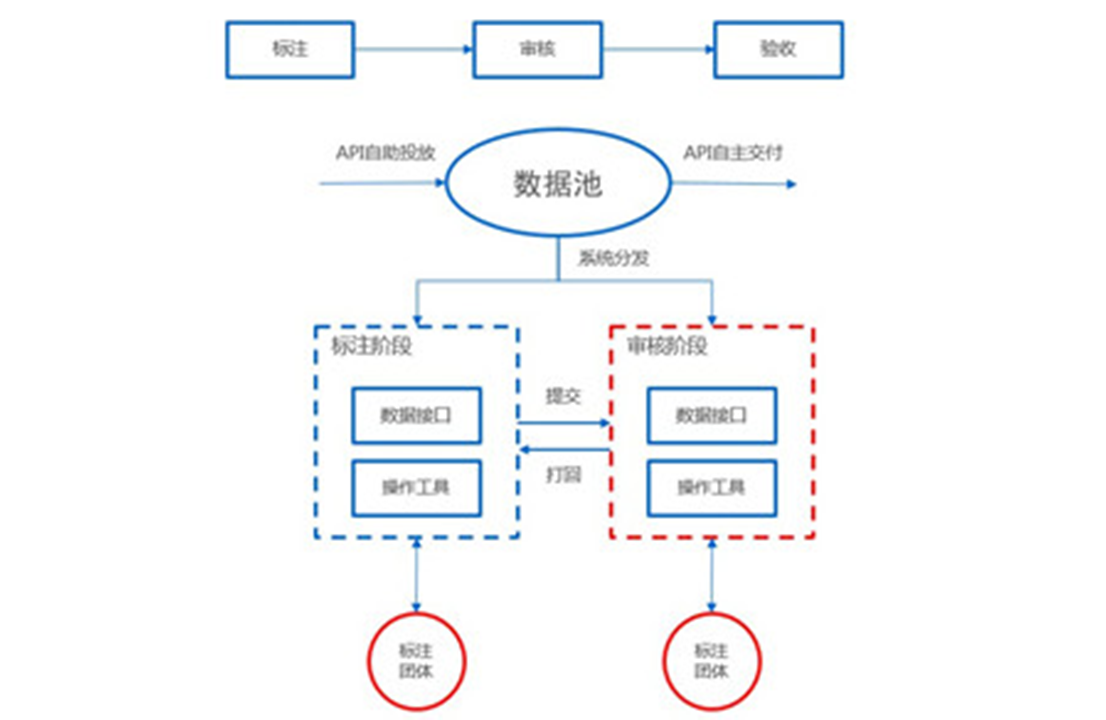
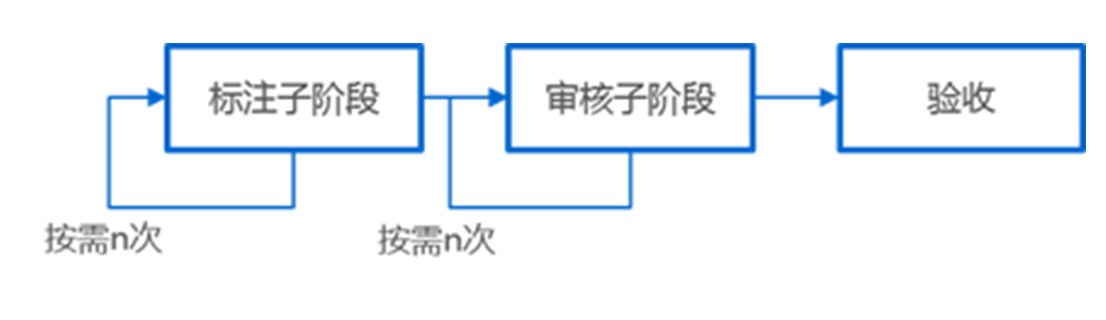
overview
Baidu public beta( http://zhongbao.baidu.com/ )As the largest AI data annotation platform in China, it has been established for 8 years since 2011. With the continuous development and expansion of the business, the entire site architecture has also undergone earth shaking changes. Based on some experience and accumulation over the years, this paper describes in detail the history of architecture changes that belong to mass testing.
Only by constantly summarizing can we find the way forward. This article is down to earth, looking back at the long history and looking up at the stars.
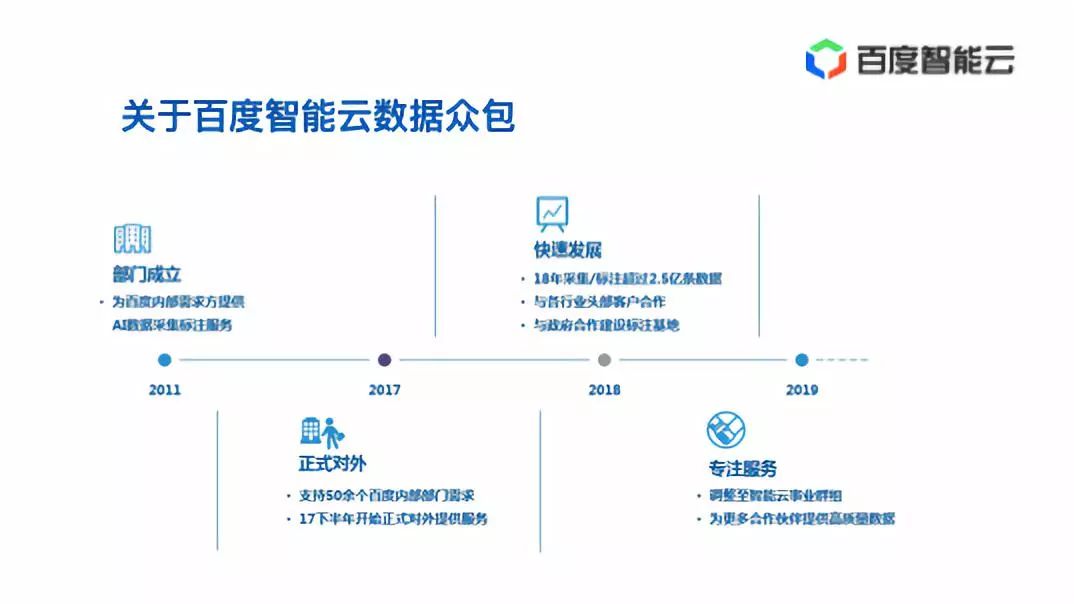
Stage 1 Single point based website architecture
In the early days of general websites, it is common for a single computer to include all applications and databases. To be honest, this kind of environment configuration is not recommended if conditions permit. Of course, sometimes when our machines are relatively tight, applications and databases are deployed on the same machine. What is the cost?
That is the inevitable fate of downtime!
Common applications need to execute scripts, and some scripts may have memory leaks or large memory usage. Databases themselves are large memory users. Once the machine's memory is overloaded, Linux will be smart to kill the database, leaving you at a loss.
Therefore, in consideration of disaster recovery of machines, it is recommended to deploy the database and applications separately at least.
As for deployment, the classic LAMP mode has been mentioned before. The containerized docker in the early stage of crowd test station building is not very mature, so the machine building is done through script. Now there is no doubt that Docker building is very convenient, fast, and easy to manage. It is also not easy to cause compilation and debugging crashes due to system version problems. However, it is recommended to reinstall the various web components used if possible, and simply understand the effects of various compilation configurations for emergencies.
The current overall architecture can be shown as follows:
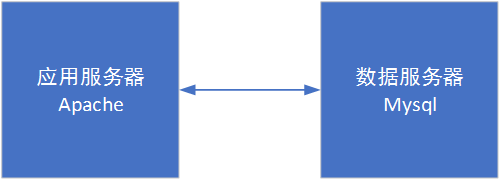
Stage 2: Database read/write separation
Applications that can run are good applications, but the machine will inevitably have problems, so disaster recovery of the database itself is particularly important.
With the development of business, the database will inevitably encounter data errors, even physical downtime and other problems caused by error codes or misoperations. Therefore, database disaster recovery is the most important.
The mysqldump provided with MySQL can easily export data for data recovery. If possible, you can further back up the binlog, so that you can achieve second level data recovery. However, it should be noted that the database lock table will appear when mysqldump. If a single database is used, your service will be goodbye.
At this time, it's MySQL's own master+slave!
What are the benefits of slave libraries?
In a brief summary, there are two points:
The slave database is mainly used for reading services, which can greatly reduce the service pressure of the master database.
The specially deployed backup slave database can safely back up data.
However, after the introduction of slave, there are a lot of fidgety problems:
First, you need to set up a read/write agent service in front of the database. We used the self developed dbproxy component in the factory, which was completely unaware of its existence. If it is open source, you can use mycat. Some frameworks even support the configuration of masters and slaves.
Secondly, after the introduction of master-slave, the inconsistency between master-slave must become a problem to be considered in business code. A common error scenario is to read the data directly after writing it to the master database. Due to the inconsistency between the master and slave instantaneously, the case cannot be read. Of course, it is recommended to minimize the implementation of business code in this way, but some special scenarios may not be avoided. It is recommended to handle this case by adding transactions to operations or forcing access to the master database connection.
With the slave database, I feel more and more stable:
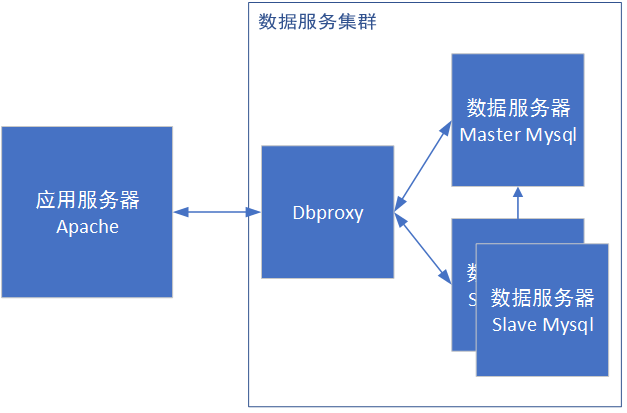
Phase 3 Load balancing+multi application servers
As the number of visits continues to increase, a single server can hardly meet the demand. Generally, you will choose to increase the machine to exchange money for stability. However, adding machines can not be added simply because of the following problems:
1. The first question is what technology is used for load balancing:
The reverse proxy server is preferred. The request is forwarded to a specific server by the reverse proxy server according to the algorithm. Common Apache and nginx can configure forwarding rules to other machines. The deployment is quite simple, but the proxy server may become a performance bottleneck, and there are also single points of problems.
Another more low-level solution is to use IP layer load balancing. After the request arrives at the load balancer, the load balancer implements the request forwarding and load balancing by modifying the destination IP address of the request. The overall performance is better than reverse proxy, but there is also a single problem.
Of course, in more complex cases, DNS and other methods will be selected for load balancing, rather than expansion.
2. The second problem is to choose the cluster scheduling algorithm.
First, the most common rr polling scheduling algorithm and wrr weighted scheduling algorithm are simple and practical.
Secondly, forward in hash mode. The user IP and other information are commonly used as hash values to ensure that each time the user accesses the same server.
Finally, the data is distributed based on the number of connections. The basic one is the least lc connection, that is, the server with fewer connection requests. Wlc weighted least connections, on the basis of lc, add weights to each server. The algorithm is: (number of active connections * 256+number of inactive connections) ÷ weight. Servers with small calculated values are preferred.
Of course, there are more complex algorithms that can be applied. I will not introduce them here.
3. Finally, unlike a single server, session sharing needs to be considered.
General frameworks provide session sharing configuration based on Redis or database, which can be used after simple configuration. However, it should be noted that in the case of large traffic, there is a risk that the number of connections between a single Redis and a single database will be full, and further capacity expansion is required.
In our actual use, we usually directly use the BLB of the open cloud architecture. It provides two types of load balancing methods: http layer and tcp layer. The wrr method can be used for load balancing. At the same time, it has heartbeat detection, effectively eliminating invalid services.
So far, a cluster has begun to take shape:
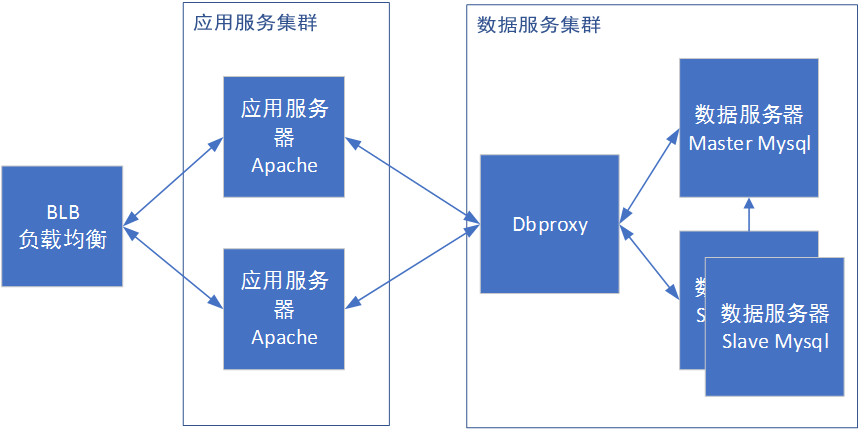
Phase 4 Database Split
At this stage, there are two possible problems: a single database has maintained hundreds of tables, which is very big; The data of a single table has reached the level of 10 million, and the query has performance problems. For these two situations, horizontal splitting and vertical splitting need to be introduced:
Vertical splitting means to split different business data in the database into different databases. For example, we will split different scenarios such as labels and questionnaires, and open the database separately. Therefore, we can avoid single database performance dragging down the whole station.
The new problem is how to handle cross database transactions. At present, we generally use code control, and some important logic supports its own independent rollback in each library.
Horizontal data splitting is to split the data in the same table into two or more databases. It is generally used to solve the performance problem of a single table that is too large, and to facilitate capacity expansion.
However, how to split is a point that needs careful design. At present, for example, the mycat module can forward sql to the database according to the configuration, so as to achieve the goal of splitting the database.
At the beginning of our business, these components were just starting. We initially used a simple monthly library disassembly design. Simply put, the task is placed in different month databases according to the release month of the task. According to the expiration time, the cold data is poured into the read-only database to compress the storage capacity.
However, with the increase of business volume index level, the capacity of a single database is gradually out of control. We further adjusted the strategy of sub databases. At present, we have designed a more fine-grained sub database strategy, which is based on the task database mapping table. At the beginning of task creation, there is a sub database algorithm to allocate the corresponding database, and then the life cycle of the task will be based on the assigned database for CURD.
With sub databases and sub tables, our business framework is as follows:
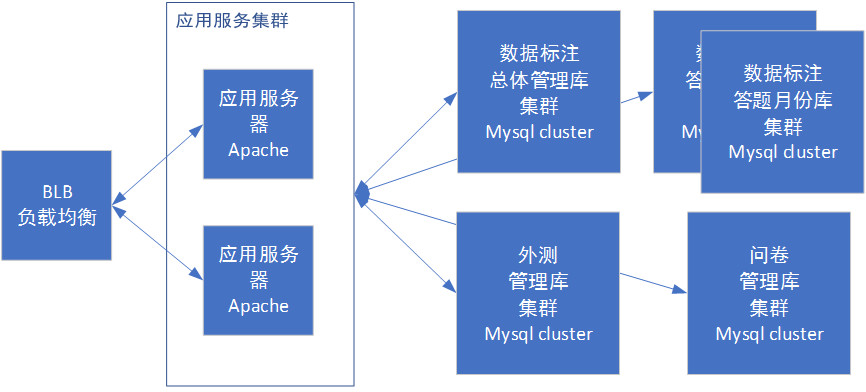
Phase 5 Application and module splitting
In the last stage, we have split the database. In fact, the splitting of business code should be carried out simultaneously with the splitting of the database.
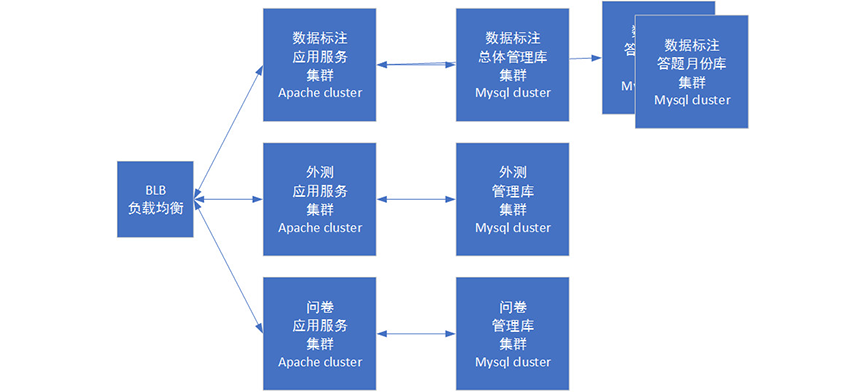
Similar to the database, we split several modules, including questionnaires and annotations, according to the business module. The business code itself is different, and this split is quite logical, but the pain is that the business code will need a lot of common logic, such as some common string and array processing. One suggestion is to put these general logic into the component of the framework to achieve the purpose of public use.
In addition, some public service modules (such as user information) may need to be deployed and maintained independently in the ideal situation. However, as a transitional phase, considering the workload of development, we will copy the common modules to each cluster during deployment, and plan to split them independently in the subsequent phase.
After business splitting, we have multiple subsystems:
Phase 6 Data Cache
With the increasing complexity of the system, it will gradually be difficult to use MySQL to process many application scenarios, such as the following cases:
Users often submit some verification codes and other information. If they use the database to store these short-term large amounts of data, it seems that they have killed the chickens with a knife;
Some complex paging information is difficult to calculate directly with the database, and needs to be calculated by combining data in memory. However, for this case, the paging operation is also inevitable, so a large number of database values need to be read frequently in memory.
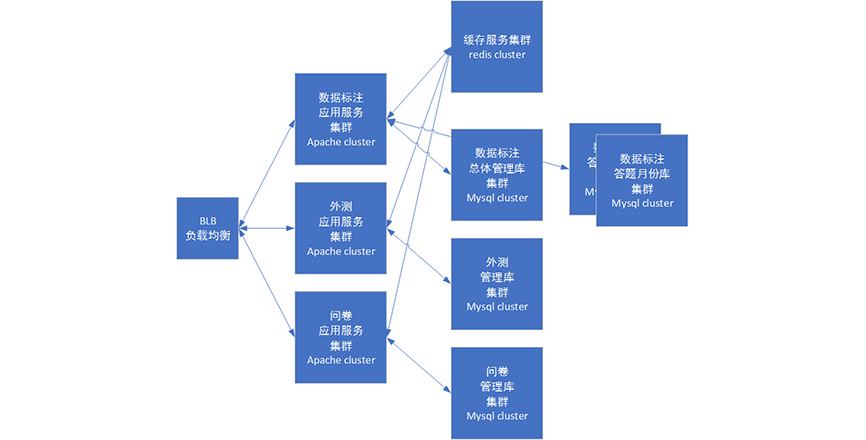
For these problems, it will be more comfortable to introduce caching NOSql. At present, Redis is commonly used.
The verification code information can be directly stored in Redis using the key value method, and the expiration time of the key can be set to prevent Redis from storing too much cold data.
For complex paging information, the page ID information can be stored in Redis. The paging information in Redis can be taken directly when changing pages, without further calculation.
Redis can also be used for some message queue, session storage and data cache functions. It is an essential layer of data storage scheme.
After the introduction of Redis, the modules are roughly as follows:
Stage 7 Micro service
With the process of business splitting, we will find that the organizational segmentation of modules is particularly advanced, which is also the stage we are currently facing and solving. A common design idea is the microservice architecture: each service in the system has its own processing and lightweight communication mechanism, which can be deployed on a single or multiple machines to achieve rapid capacity expansion.
An excellent microservice system will have the following characteristics:
Loose coupling: due to service autonomy, there is a certain encapsulation boundary, and service invocation interaction is through publishing interfaces. This means that applications are not interested in how services are implemented.
How to build a microservice system is not a simple sentence. If necessary, please read it in depth. The microservice architecture we are currently implementing is shown below:
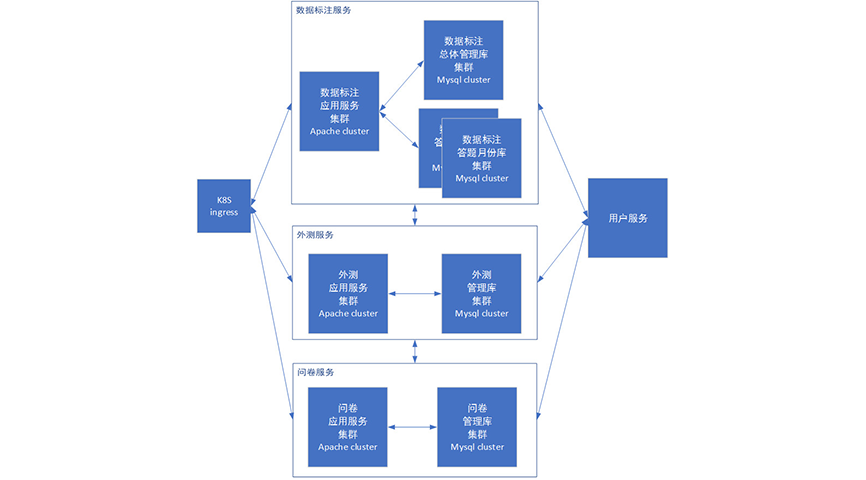
It looks very similar to the previous phase, but the main difference is that in the previous phase, all clusters actually deploy a full amount of code, just by distinguishing routing methods to ensure that requests enter different clusters. For example, the external test service needs to call the function of the annotation service, and only needs to directly call its code to work.
In the microservice stage, the code of each service itself should be as simple as possible, and almost never cross each other. The call between each other needs to use the interface for communication.
summary
The website architecture has been developing for a long time, and today's advanced technology will inevitably be outdated sooner or later. So when building the architecture, we should be down-to-earth and understand the causes and consequences of each design, so as to consolidate the foundation and look up to the stars.
Never upgrade for the sake of advanced architecture. If you don't think clearly about how to split and design, you will be beaten to pieces by a burst of courage.
reference resources:
On the Evolution of Web Site Architecture:
https://www.cnblogs.com/xiaoMzjm/p/5223799.html
Technical Architecture of Large Websites: Core Principles and Case Analysis by Li Zhizhi
Mycat Authoritative Guide